Processes hope that they can occupy the CPU for work, so this involves the process context switching mentioned earlier.
Once the operating system switches the process to the running state, it means that the process is occupying the CPU for execution, but when the operating system switches the process to another state, it cannot be executed in the CPU, so the operating system will choose the next one. running process.
The function of selecting a process to run is done in the operating system, usually called the scheduler .
Scheduling timing
In the life cycle of a process, when the process changes from one running state to another, a scheduling is actually triggered.
for example:
- From ready state -> running state : when a process is created, it will enter the ready queue, and the operating system will select a process from the ready queue to run
- From running state -> blocking state : when a process is blocked by an I/O event, the operating system must choose another process to run
- From running state -> end state : when the process exits, the operating system has to select another process from the ready queue to run
Because, when these states change, the operating system needs to consider whether to let the new process run on the CPU, or whether to let the current process exit from the CPU and switch to another process to run.
In addition, if the hardware clock provides periodic interrupts of a certain frequency, scheduling algorithms can be divided into two categories according to how to handle clock interrupts:
- The non-preemptive scheduling algorithm picks a process, and then lets the process run until it is blocked, or until the process exits, it will not call another process, that is to say, it will not care about the clock interruption.
- The preemptive scheduling algorithm picks a process, then allows that process only for a certain period of time, if at the end of that period of time, the process is still running, it is suspended, and then the scheduler picks another process from the ready queue . This preemptive scheduling process requires a clock interrupt at the end of the time interval in order to return CPU control to the scheduler for scheduling, that is, the time slice mechanism
Scheduling principle
Principle 1 : If the running program has an I/O event request, the CPU usage must be very low, because the process is blocked waiting for the data from the hard disk to return. Such a process is bound to cause a sudden idleness of the CPU. Therefore, in order to improve CPU utilization, the scheduler needs to select a process from the ready queue to run when the CPU is idle due to sending I/O events .
Principle 2 : Some programs take a long time to execute a certain task. If this program keeps occupying the CPU, it will reduce the system throughput (the number of processes completed per CPU unit time). Therefore, in order to improve the throughput of the system, the scheduler must weigh the number of running completions of long-task and short-task processes .
Principle 3 : The process from the beginning to the end of the process actually includes two times, namely the process running time and the process waiting time. The sum of these two times is called the turnaround time. The shorter the turnaround time of the process, the better. If the process waits for a long time and runs for a short time, the turnaround time will be very long . This is not what we want, and the scheduler should avoid this situation.
Principle 4 : The process in the ready queue cannot wait too long. Of course, it is hoped that the waiting time is as short as possible, so that the process can be executed in the CPU faster. Therefore, the waiting time of the process in the ready queue is also a principle that the scheduler needs to consider .
Principle 5 : For highly interactive applications such as mouse and keyboard, we certainly hope that their response time should be as fast as possible, otherwise it will affect the user experience. Therefore, for more interactive applications, the response time is also a principle that the scheduler needs to consider .
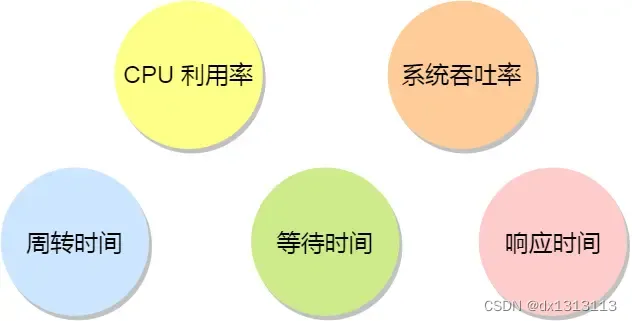
For the above five scheduling principles, they are summarized as follows:
- CPU Utilization : The scheduler should ensure that the CPU is always in a state of rush, which can improve CPU utilization
- System throughput : Throughput represents the number of processes completed by the CPU per unit time. Long-term processes will occupy longer CPU resources, thus reducing throughput. On the contrary, short-job processes will increase system throughput.
- Turnaround time : Turnaround time is the sum of process running + blocking time + waiting time. The smaller the turnaround time of a process, the better
- Waiting time : This waiting time is not the time in the blocking state, but the time the process is in the ready queue. The longer the waiting time, the more dissatisfied the user
- Response time : the time it takes for the user to submit a request to the system for the first time to generate a response. In an interactive system, response time is the main criterion for measuring the quality of a scheduling algorithm.
Scheduling Algorithm
Different scheduling algorithms are applicable to different scenarios.
Common scheduling algorithms in single-core CPU systems:
First come first serve scheduling algorithm
The simplest scheduling algorithm is the non-preemptive first-come-first-serve algorithm (FCFS) :

Each time the process that enters the queue first is selected from the ready queue, and then runs until the process exits or is blocked, then the first process will continue to be selected from the queue and then run .
This seems reasonable, but when a job runs first, the waiting time for the following short jobs will be very long, which is not conducive to short jobs.
FCFS is good for long jobs and is suitable for systems with CPU-heavy jobs, but not for I/O-heavy jobs.
Shortest Job First Scheduling Algorithm
Shortest Job First (SJF) scheduling algorithm , which will give priority to the process with the shortest running time to run , which helps to improve the throughput of the system.
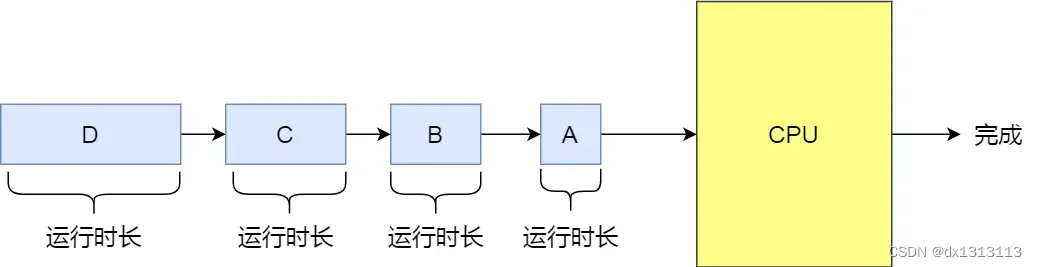
This is obviously not good for long jobs, and it is easy to cause an extreme phenomenon.
For example, if a long job is waiting to run in the ready queue, and there are many short jobs in the ready queue, the long job will be pushed back continuously, and the turnaround time will be longer, so that the long job will not be run for a long time.
High Response Ratio Priority Scheduling Algorithm
Both the previous [First Come First Serve Scheduling Algorithm] and [Shortest Job First Scheduling Algorithm] did not balance short and long jobs well.
Then, the High Response Ratio Priority (HRRN) scheduling algorithm mainly weighs short jobs and long jobs.
Every time a process is scheduled, the [response ratio priority] is calculated first, and then the process with the highest [response ratio priority] is put into operation. The calculation formula of [response ratio priority] is:

From the above formula it can be found that:
- If the [waiting time] of two processes is the same, the shorter the [required service time], the higher the [response ratio], so that the process with a short job is easy to be selected to run
- If the [required service time] of two processes is the same, the longer the [wait time], the higher the [response ratio], which takes into account the process of long jobs, because the response ratio of the process can increase with the increase of waiting time , when its waiting time is long enough, its response ratio can be raised to a high level, thus gaining a chance to run;
However, the service time required by the process is unknown, so the high response ratio priority scheduling algorithm is an ideal scheduling algorithm, which cannot be realized in reality.
Time slice round-robin scheduling algorithm
The oldest, simplest, fairest and most widespread algorithm is the time slice round-robin (RR) scheduling algorithm.
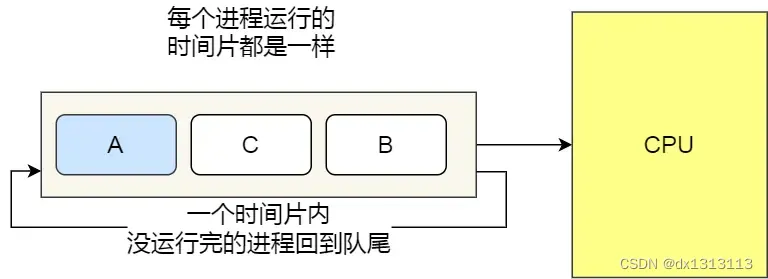
Each process is assigned a period of time, called a time slice, which allows the process to run during that time period.
- If the time slice is exhausted and the process is still running, the process will be released from the CPU and the CPU will be allocated to another process
- If the process blocks or ends before the time slice ends, the CPU switches immediately
In addition, the length of the time slice is a very critical point:
- If the time slice is set too short, it will cause too many process context switches, reducing CPU efficiency
- If it is set too long, it may cause longer response time for short job processes
Generally speaking, setting the time slice to 20ms~50ms is usually a reasonable compromise value
Highest Priority Scheduling Algorithm
The previous [Time Slice Rotation Algorithm] made an assumption, that is, to make all processes equally important, and everyone's running time is the same.
However, for user computer systems, they hope that the scheduling is prioritized, that is, they hope that the scheduler can select the highest priority process from ready queue to run, which is called the highest priority (HPF) algorithm .
Process priority can be divided into static priority and dynamic priority:
- Static priority: When the process is created, it has been determined, and then the priority of the entire runtime will not change
- Dynamic priority: Adjust the priority according to the dynamic change of the process. For example, if the process running time increases, its priority will be reduced. If the process waiting time (the waiting time of the ready queue) increases, its priority will be increased, that is, as Increase the priority of waiting processes over time
The algorithm also has two methods for handling priorities, non-preemptive and preemptive:
- Non-preemptive: When a high-priority process appears in the ready queue, the current process is finished running, and then the high-priority process is selected
- Preemptive: When a process with high priority appears in the ready queue, the current process is suspended, and the process with high priority is scheduled to run
But there are still downsides, which may cause low-priority processes to never run.
Multilevel Feedback Queue Scheduling Algorithm
The multi-level feedback queue (MFQ) scheduling algorithm is the synthesis and development of [Time Slice Round Robin Algorithm] and [Highest Priority Algorithm].
- [Multi-level] means that there are multiple queues, and the priority of each queue is from high to low, and the higher the priority, the shorter the time slice
- [Feedback] It means that if a new process joins a high-priority queue, immediately stop the currently running process and switch to the high-priority queue
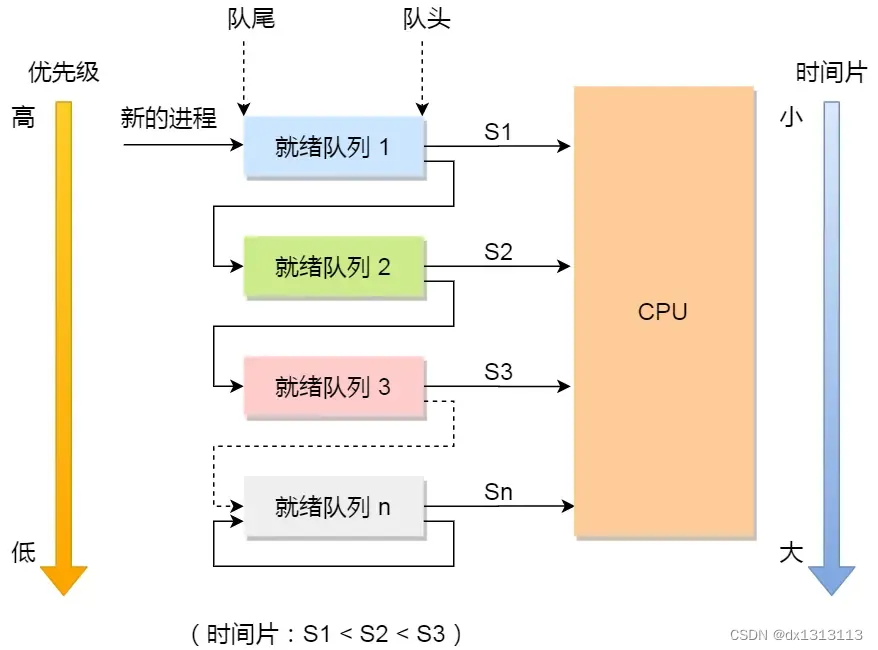
Way of working:
- Set multiple queues and give each queue a different priority. The priority of each queue is from high to low . At the same time, the higher the priority, the shorter the time slice
- The new process will be placed at the end of the first-level queue, and queued for scheduling according to the principle of first-come-first-served. If the time slice stipulated in the first-level queue is not completed, it will be transferred to the second-level queue at the end of the , and so on, until the completion of the
- When the higher priority queue is empty, the processes in the lower priority queue are scheduled to run. If a new process enters a higher-priority queue while the process is running, stop the currently running process and move it to the end of the original queue, and then let the higher-priority process run.
It can be found that short jobs may be processed quickly in the first-level queue. For long jobs, if they cannot be processed in the first-level queue, they can be moved to the next queue to wait for execution. Although the waiting time becomes longer, the running time also becomes longer, so this algorithm takes both long and short jobs into consideration . Have a better response time .