The first type: configuration problem
This is someone else’s picture. According to the landlord’s investigation, the solution is due to hostsa configuration problem...
Phenomenon : Various failures to run, start
the solution:
1. Modify the log level
export HADOOP_ROOT_LOGGER=DEBUG,
check the detailed information in the console, and locate the specific problem to solve
Type 2: server problem

**Phenomenon: **Stuck when running to job
**Reason: **The server configuration is low, the memory or disk is small
**Solution: **Modify the yarn.site.xml configuration
<!--每个磁盘的磁盘利用率百分比-->
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>95.0</value>
</property>
<!--集群内存-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<!--调度程序最小值-分配-->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<!--比率,具体是啥比率还没查...-->
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
In addition to the low configuration of the server cluster, it is also possible that the server is attacked or a malicious program occupies memory. Hadoop's MapReduce process is stuck. The job/cloud server is mined by miners.
The dramatic thing is that I also encountered a situation today... The phenomenon is also stuck in the Job after Mapping. The reason is: I ran the program to calculate the pi. At the beginning of the test, there was no problem, and then I executed it 1,000 times and threw it 10,000 times...The Map process is still Well, the job doesn't work right from the start...
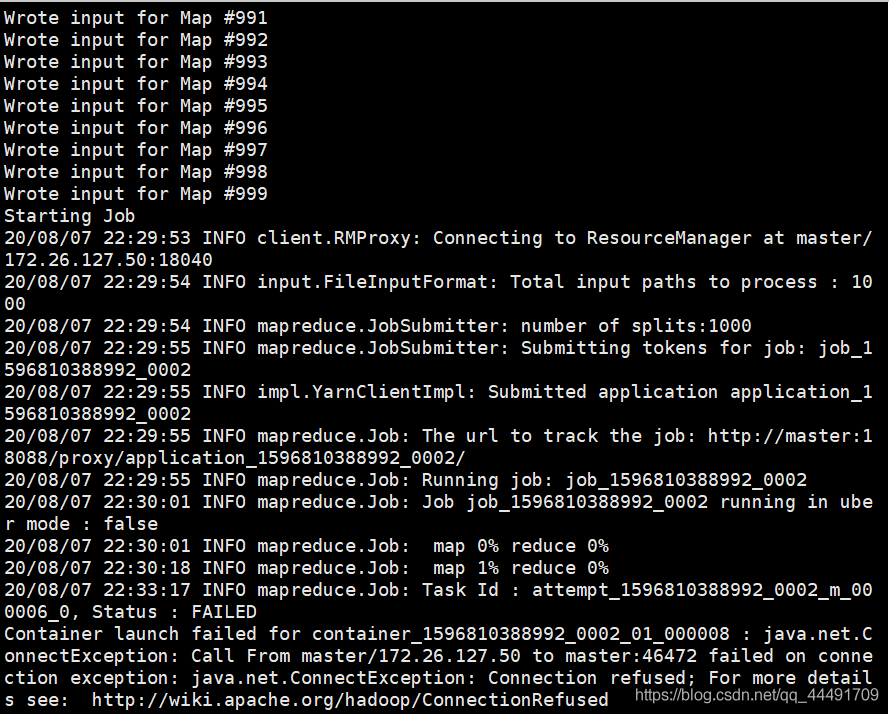
It may be that the task is too large, you can try to change it to a smaller one
hadoop jar ./hadoop-mapreduce-examples-2.7.3.jar pi 20 20