3 Talk about your understanding of TCP flow control and congestion control (oppo)
What is this question trying to investigate?
Network programming, TCP principle
Knowledge points of inspection
TCP flow control and congestion control
How should candidates answer
Although the actions taken by TCP congestion control and flow control are very similar, congestion control is related to the congestion of the network, while flow control is related to the buffer status of the receiver, which are measures taken for completely different problems. The two guarantee the reliability of the TCP protocol from different aspects.
flow control
When the two parties communicate, the speed of the sender is not necessarily equal to the speed of the receiver. If the sending speed of the sender is too fast, the receiver will not be able to process it. At this time, the receiver can only save the data that cannot be processed. in the cache.
If the buffer is full and the sender is still sending data crazily, the receiver can only discard the received data packets, and flow control is to control the sending speed of the sender so that the receiver can receive in time to prevent loss of data packets.
Assuming there is no flow control, the sending end sends data according to its actual situation. If the sending speed is too fast, the receiving buffer of the receiving end will be filled up quickly. If the sending end continues to send data at this time, the receiving end cannot handle it. At this time, the receiving end will discard the data that should have been received, which will trigger the retransmission mechanism of the sending end, resulting in unnecessary waste of network traffic.
sliding window
There is a Window field in the TCP header, which represents the receiving end telling the sending end how much space is left in its buffer to receive data. TCP utilizes the sliding window to realize the flow control mechanism, and the size of the sliding window is notified to the sender through the Window field of the TCP header.
The receiving end will fill in its own immediate window size when confirming and sending the ACK message, and send it along with the ACK message. The sender changes its sending speed according to the value of the window size in the ACK message.
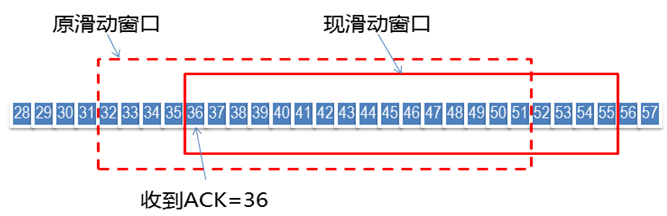
Suppose our window size is 20 (32-51), after the sender sends 32-51 sequence packets, it receives ACK=36, which means that the receiver only received 32-35, and the next time the receiver expects to receive 36 sequence numbers package. If the window size in the ACK given by the receiver is still 20, the sender's window slides, and 36-55 is the packet that the sender can send.
This is the working mechanism of the sliding window. The sender always maintains a sending window during the sending process, and only frames that fall within the sending window are allowed to be sent; after the sender receives the ACK and calculates the size of the receiver's window, it will adjust it Your own sending rate, that is, adjusting the size of your own sending window to achieve flow control. But when the sender receives that the size of the receiving window is 0, the sender will stop sending data!
zero window
When the sender stops sending data, how can he know that he can continue sending data?
We can adopt this strategy: when the receiver processes the data and accepts the window win > 0, the receiver sends a notification message to notify the sender that he can continue to send data. When the sender receives a message with a window greater than 0, it continues to send data.
However, a problem may be encountered at this time. If the sender does not receive the window update notification or the window update package is lost within the retransmission timeout time, a problem will arise at this time: the receiver sends a notification message. After the message, continue to wait for the sender to send data, while the sender is waiting for the receiver's notification message, at this time the two parties will fall into a deadlock.
In order to solve this problem, TCP has a persistent timer for each connection : when the sender receives the acceptance window win = 0, the sender stops sending messages at this time, and starts a timer at the same time, every once in a while Just send a test message to ask the receiver whether it is possible to continue sending data. If yes, the receiver will tell him the size of the acceptance window at this time; if the size of the acceptance window is still 0, the sender will refresh the start timer again .
congestion control
Flow control means that the receiver is afraid that the sender will send too fast, making it too late for processing. The object of congestion control is the network. It is a global process for fear that the sender will send too fast, causing network congestion and making the network too late to process.
Congestion control is to prevent too much data from being injected into the network, so that routers or links in the network will not be overloaded. Congestion is a dynamic problem, and we have no way to solve it with a static solution. In this sense, congestion is inevitable. It’s as if traffic jams often occur during rush hour. In order not to paralyze the traffic, the traffic police will go to the scene to command, restrict the vehicles in a dynamic way, and slowly release them according to the actual situation.
For example, host A transmits data to host B.
When the two hosts are transmitting data packets, if the sender has not received the ACK from the receiver for a long time, the sender will think that the data packet it sent is lost, and then retransmit the lost data packet.
However, the actual situation may be that too many hosts are using channel resources at this time, resulting in network congestion, and the data packets sent by A are blocked halfway, and have not reached B for a long time. At this time, A mistakenly believes that a packet loss has occurred, and will retransmit the data packet.
The result is not only wasting channel resources, but also making the network more congested. Therefore, we need congestion control. The congestion control of TCP is completed through: slow start, congestion avoidance, fast retransmission and fast recovery.
slow start
The slow start algorithm is a new congestion window (cwnd) for the TCP sender. Corresponding to flow control, the sender will use the minimum value of the congestion window and the sliding window as the upper limit for sending.
When creating a new connection, the sender does not understand the network situation, and the cwnd (congestion window) is initialized to a relatively small value. RFC recommends 2-4 MSS, depending on the size of the MSS.
MSS: Maximum Segment Size, the maximum data segment length sent by TCP in one transmission.
Assume that the initial cwnd is 1 MSS. The sender starts to send data according to the size of the congestion window. If it is ACKed, it will send 2 data next time. If the ACK is still received, send 4, then 8.... In this way, the value of cwnd increases exponentially with the network round trip time (Round Trip Time, RTT). In fact, the speed of slow start is not slow at all, but its starting point is relatively low.
congestion avoidance
It can be seen from the slow start that cwnd can grow up quickly to maximize the use of network bandwidth resources, but cwnd cannot continue to grow indefinitely like this, and a certain limit must be required. TCP uses a variable called slow start threshold (ssthresh). When cwnd exceeds this value, the slow start process ends and enters the congestion avoidance phase. The main idea of congestion avoidance is additive increase, that is, the value of cwnd no longer rises exponentially, and starts to increase additively. At this time, when all the message segments in the window are confirmed, the size of cwnd is increased by 1 (adding 1 here refers to adding 1 MSS, the same applies below), and the value of cwnd increases linearly with RTT, so It can avoid network congestion caused by excessive growth, and slowly increase and adjust to the optimal value of the network.
Fast retransmission and fast recovery
After entering congestion avoidance, it will eventually encounter a congestion point, and the sender has not been confirmed by the receiver at this time. Therefore, after TCP sends a piece of data, it starts a timer. If the ACK message for sending the datagram is not obtained within a certain period of time, then the data is resent until the sending is successful. This is timeout retransmission.
The fast retransmission algorithm first requires the receiver to send a duplicate acknowledgment immediately every time it receives an out-of-sequence segment. For example, A sends M1, M2, M3, M4, M5 to B. If B receives M1, M2, M4, M5; M3 does not receive it, then when B receives M4, it will send an ACK of M2. M5 will send M2's ACK again, so that the repeated confirmation of M2 is intended to tell A that M3 has not received it yet, and it may be lost.
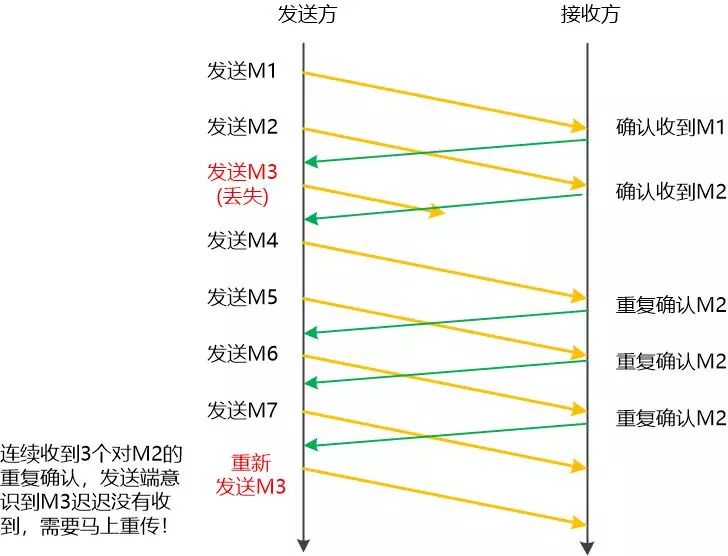
When A receives three consecutive ACKs confirming M2, if the M3 timeout event has not yet occurred, A will also assume that M3 is lost at this time. At this time, A does not have to wait for the timer set by M3 to expire, but performs a fast reset . pass .
The fast recovery is added after the above fast retransmission , the fast retransmission and fast recovery algorithms will be used at the same time, and the fast recovery will:
1. When receiving 3 repeated ACKs of M2, in order to prevent network congestion, set ssthresh to half of cwnd, set cwnd to the value of ssthresh plus 3, and retransmit M3
The idea of fast recovery is the principle of "data packet conservation", that is, the number of data packets in the network at the same time is constant, and only when the "old" data packets leave the network can a "new" data be sent to the network packet, if the sender receives a duplicate ACK, then according to the TCP ACK mechanism, it indicates that a data packet has left the network, and receiving 3 duplicate ACKs indicates that 3 "old" data packets have left the network, So add 3 here.
2. When a repeated ACK is received, cwnd increases by 1.
3. When the ACK of M4 (new data packet) is received, set cwnd to the value of ssthresh in the first step
New data has been confirmed by the ACK (M4) of the new data packet, indicating that the data (M3) from the repeated ACK has been received, the recovery process ends, and the congestion avoidance state before recovery can be returned.
4 Talk about your understanding of the relationship between Http and Https
What is this question trying to investigate?
- Do you understand Internet network protocols?
Knowledge points of inspection
- Knowledge of the Http protocol
- Knowledge of Https protocol
How should candidates answer
Http protocol
HTTP (HyperText Transfer Protocol: Hypertext Transfer Protocol) is an application layer protocol for distributed, collaborative and hypermedia information systems. Simply put, it is a method of publishing and receiving HTML pages, which is used to transfer information between web browsers and web servers.
HTTP works on port 80 of the TCP protocol by default, and users access websites starting with http:// are standard HTTP services.
The HTTP protocol sends content in plain text and does not provide any form of data encryption. If an attacker intercepts the transmission message between the web browser and the website server, he can directly read the information in it. Therefore, the HTTP protocol is not suitable for transmission Some sensitive information, such as credit card numbers, passwords and other payment information.
Https protocol
HTTPS (Hypertext Transfer Protocol Secure: Hypertext Transfer Security Protocol) is a transmission protocol for secure communication over a computer network. HTTPS communicates over HTTP, but utilizes SSL/TLS to encrypt packets. The main purpose of HTTPS development is to provide identity authentication for web servers and protect the privacy and integrity of exchanged data.
HTTPS works on port 443 of the TCP protocol by default, and its working process is generally as follows:
1. TCP three-way synchronous handshake
2. The client verifies the server digital certificate
3. The DH algorithm negotiates the key of the symmetric encryption algorithm and the key of the hash algorithm
4. SSL secure encrypted tunnel negotiation is completed
5. The webpage is transmitted in an encrypted manner, encrypted with the negotiated symmetric encryption algorithm and key to ensure data confidentiality; the negotiated hash algorithm is used to protect the integrity of the data to ensure that the data is not tampered with.
encryption
The HTTPS solution to data transmission security issues is to use encryption algorithms, specifically hybrid encryption algorithms, that is, the mixed use of symmetric encryption and asymmetric encryption. Here, it is necessary to understand the differences, advantages and disadvantages of these two encryption algorithms.
-
Symmetric encryption, as the name implies, uses the same key for both encryption and decryption. Common symmetric encryption algorithms include DES, 3DES, and AES. Their advantages and disadvantages are as follows:
Advantages: open algorithm, small amount of calculation, fast encryption speed, high encryption efficiency, suitable for encrypting relatively large data.
Disadvantages:
1. Both parties to the transaction need to use the same key, so the transmission of the key cannot be avoided, and the key cannot be guaranteed not to be intercepted during the transmission process, so the security of symmetric encryption cannot be guaranteed.2. Every time a pair of users uses a symmetric encryption algorithm, they need to use a unique key unknown to others, which will increase the number of keys owned by both sender and receiver, and key management will become a burden for both parties. Symmetric encryption algorithms are difficult to use in distributed network systems, mainly because key management is difficult and the cost of use is high.
-
Asymmetric encryption An
asymmetric encryption algorithm requires two keys: a public key (publickey: referred to as the public key) and a private key (privatekey: referred to as the private key). The public key and the private key are a pair. If the data is encrypted with the public key, it can only be decrypted with the corresponding private key. Because encryption and decryption use two different keys, this algorithm is called an asymmetric encryption algorithm. The basic process of asymmetric encryption algorithm to realize the exchange of confidential information is: Party A generates a pair of keys and discloses the public key, and other roles (Party B) that need to send information to Party A use the key (Party A’s public key) to pair The confidential information is encrypted and then sent to Party A; Party A then uses its own private key to decrypt the encrypted information. When Party A wants to reply to Party B, the opposite is true. Party B's public key is used to encrypt the data. Similarly, Party B uses its own private key to decrypt.
process
HTTPS can encrypt information to prevent sensitive information from being obtained by third parties, so many services with high security levels such as banking websites or e-mails will use the HTTPS protocol.

1. The client initiates an HTTPS request
The user enters an https URL in the browser, and then connects to the port of the server.
2. Server configuration
The server using the HTTPS protocol must have a set of digital certificates, which can be made by itself or applied to the organization. The difference is that the certificate issued by itself needs to be verified by the client before it can continue to access, and use a trusted company The application certificate will not pop up a prompt page (startssl is a good choice, with 1 year of free service).
3. Transmission certificate
This certificate is actually a public key, but it contains a lot of information, such as the issuing authority of the certificate, expiration time and so on.
4. The client parses the certificate
This part of the work is done by the client's TLS. First, it will verify whether the public key is valid, such as the issuing authority, expiration time, etc. If an exception is found, a warning box will pop up, indicating that there is a problem with the certificate.
If there is no problem with the certificate, then generate a random value, and then encrypt the random value with the certificate, as mentioned above, lock the random value with a lock, so that unless there is a key, the locked value cannot be seen content.
5. Send encrypted information
This part transmits the random value encrypted with the certificate. The purpose is to let the server get this random value. In the future, the communication between the client and the server can be encrypted and decrypted through this random value.
6. The server decrypts the information
After the server decrypts with the private key, it obtains the random value (private key) sent by the client, and then encrypts the content symmetrically through this value. The so-called symmetric encryption is to mix the information and the private key together through a certain algorithm. In this way, unless the private key is known, the content cannot be obtained, and both the client and the server know the private key, so as long as the encryption algorithm is strong enough and the private key is complex enough, the data is safe enough.
7. Transmission of encrypted information
This part of information is the information encrypted by the private key of the service segment, which can be restored on the client.
8. The client decrypts the information
The client uses the previously generated private key to decrypt the information sent by the service segment, and then obtains the decrypted content. Even if the third party monitors the data during the whole process, there is nothing they can do.
shortcoming
- In the same network environment, HTTPS has a significant increase in both response time and power consumption compared to HTTP.
- The security of HTTPS is limited, and it is almost useless in situations such as hacker attacks and server hijacking.
- Under the existing certificate mechanism, man-in-the-middle attacks are still possible.
- HTTPS requires more server resources, which also leads to higher costs.
The difference between HTTP and HTTPS
- HTTP clear text transmission, the data is not encrypted, the security is poor, HTTPS (SSL+HTTP) data transmission process is encrypted, the security is better.
- To use the HTTPS protocol, you need to apply for a certificate from a CA (Certificate Authority, digital certificate certification authority). Generally, there are few free certificates, so a certain fee is required. Certificate Authorities such as: Symantec, Comodo, GoDaddy, GlobalSign, etc.
- The response speed of HTTP pages is faster than that of HTTPS, mainly because HTTP uses TCP three-way handshake to establish a connection, and the client and server need to exchange 3 packets, while HTTPS adds 9 packets required for ssl handshake in addition to the three packets of TCP. So there are 12 packages in total.
- http and https use completely different connection methods and different ports, the former is 80 and the latter is 443.
HTTPS is actually the HTTP protocol built on top of SSL/TLS, so comparing HTTPS consumes more server resources than HTTP.
at last
This interview question will continue to be updated, please pay attention! ! ! !
Friends who need this interview question can scan the QR code below to get it for free! ! !
At the same time, by scanning the QR code below, you can also enter the group to enjoy the service of the ChatGPT robot! ! !
