1. Basic principles
Data storage is undertaken by HBase. HBase is an open source, column-oriented (Column-Oriented), suitable for storing massive unstructured or semi-structured data, with high reliability, high performance, flexible scalability, and support Distributed storage system for real-time data reading and writing. For more information about HBase, see: https://hbase.apache.org/ .
Typical characteristics of a table stored in HBase:
- Big table (BigTable): a table can have hundreds of millions of rows and millions of columns
- Column-oriented: column (family)-oriented storage, retrieval and access control
- Sparse: empty (null) columns in the table do not occupy storage space
Two, HBase structure
The HBase cluster consists of active and standby Master processes and multiple RegionServer processes. As shown below.
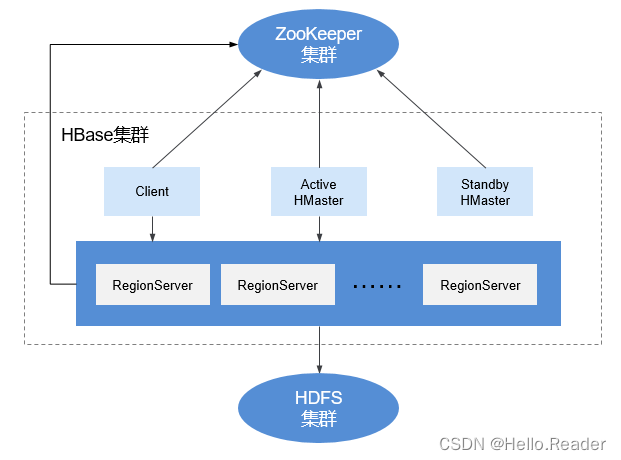
Module descriptions are shown in the table below:
| name | describe |
|---|---|
| Master | Also called HMaster, in HA mode, it includes the active Master and the standby Master. 1. Primary Master: Responsible for the management of RegionServers in HBase, including addition, deletion, modification and query of tables; load balancing of RegionServers, adjustment of Region distribution; splitting of Regions and distribution of Regions after splitting; migration of Regions after the failure of RegionServers, etc. 2. Standby Master: When the active Master fails, the standby Master will replace the active Master to provide external services. After the fault is recovered, the original active master is downgraded to the standby. |
| Client | Client uses HBase's RPC mechanism to communicate with Master and RegionServer. Client communicates with Master for management, and communicates with RegionServer for data operation. |
| RegionServer | RegionServer is responsible for providing services such as table data reading and writing, and is the data processing and computing unit of HBase. RegionServer is generally deployed together with the DataNode of the HDFS cluster to implement the data storage function. |
| ZooKeeper cluster | ZooKeeper provides distributed collaboration services for each process in the HBase cluster. Each RegionServer registers its own information in ZooKeeper, and the master master perceives the health status of each RegionServer based on this. |
| HDFS cluster | HDFS provides highly reliable file storage services for HBase, and all HBase data is stored in HDFS. |
3. Principle of HBase
- HBase data model
HBase stores data in the form of tables, and the data model is shown in the HBase data model in the figure below. The data in the table is divided into multiple Regions, which are assigned by the Master to the corresponding RegionServers for management.
Each Region contains data within a range of RowKey intervals in the table. A HBase data table initially contains only one Region. As the data in the table increases, when the size of a Region reaches the upper limit of capacity, it will be split into two Regions. . You can define the RowKey range of the Region when creating a table, or define the size of the Region in the configuration file.

- concept introduction
| name | describe |
|---|---|
| RowKey | Row key, equivalent to the primary key of a relational table, uniquely identifies each row of data. Strings, integers, and binary strings can all be used as RowKeys. All records are sorted and stored according to RowKey. |
| Timestamp | The timestamp corresponding to each data operation, the data is differentiated by timestamp, and the data of multiple versions of each Cell is stored in reverse chronological order. |
| Cell | HBase's smallest storage unit consists of Key and Value. Key consists of six fields: row, column family, column qualifier, timestamp, type, and MVCC version. Value is the corresponding stored binary data object. |
| Column Family | Column family, a table is composed of one or more Column Family in the horizontal direction. A CF (Column Family) can be composed of any number of Columns. Column is a label under CF, which can be added arbitrarily when writing data, so CF supports dynamic expansion without pre-defining the number and type of Column. The columns in the table in HBase are very sparse, and the number and type of columns in different rows can be different. In addition, each CF has an independent time to live (TTL). You can only lock the row, and the operation on the row is always primitive. |
| Column | Columns, similar to traditional databases, HBase tables also have the concept of columns, which are used to represent the same type of data. |
- RegionServer data storage
RegionServer is mainly responsible for managing the Region allocated by HMaster. The data storage structure of RegionServer is shown in the data storage structure of RegionServer in the figure below .
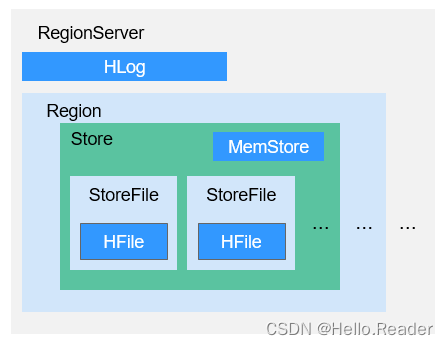
The description of each part of the Region in the data storage structure of the RegionServer in the above figure is shown in the description of the Region structure in the table.
Region structure description
| name | describe |
|---|---|
| Store | A Region consists of one or more Stores, and each Store corresponds to a Column Family in the graph HBase data model. |
| MemStore | A Store contains a MemStore. The MemStore caches the data inserted by the client into the Region. When the size of the MemStore in the RegionServer reaches the configured upper limit, the RegionServer will "flush" the data in the MemStore to HDFS. |
| StoreFile | MemStore data is flushed to HDFS and becomes a StoreFile. As data is inserted, a Store generates multiple StoreFiles. When the number of StoreFiles reaches the configured maximum value, the RegionServer merges multiple StoreFiles into one large StoreFile. |
| HFile | HFile defines the storage format of StoreFile in the file system, which is the specific implementation of StoreFile in the current HBase system. |
| HLog | The HLog log ensures that the data written by the user is not lost when the RegionServer fails, and multiple Regions of the RegionServer share the same HLog. |
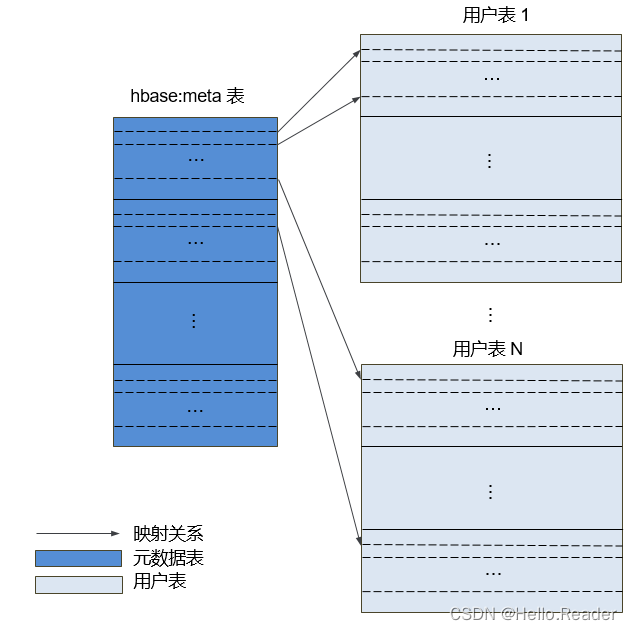
- metadata table
The metadata table is a special table in HBase, which is used to help the client locate a specific Region. The metadata table includes the "hbase:meta" table, which is used to record the Region information of the user table, such as the Region location, start RowKey, and end RowKey.
The mapping relationship between the metadata table and the user table is shown in the following figure: the mapping relationship between the metadata table and the user table.
- Data operation process
The HBase data operation process is shown in the following figure.
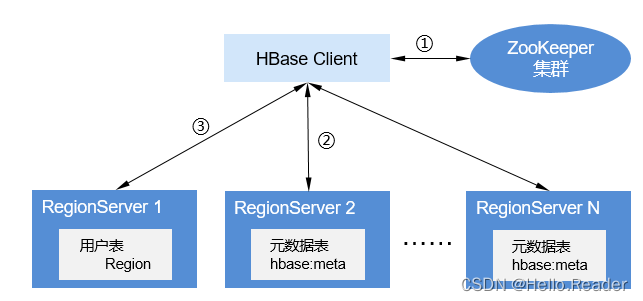
- When adding, deleting, modifying, and querying data on HBase, the HBase Client first connects to ZooKeeper to obtain the information of the RegionServer where the "hbase:meta" table is located (involving namespace-level modifications, such as creating and deleting tables, you need to access HMaster to update meta information ).
- The HBase Client connects to the RegionServer where the Region containing the corresponding "hbase:meta" table resides, and obtains the location information of the RegionServer where the Region of the corresponding user table resides.
- The HBase Client connects to the RegionServer where the corresponding user table Region is located, and sends the data operation command to the RegionServer, and the RegionServer receives and executes the command to complete the data operation.
In order to improve the efficiency of data operations, HBase Client will cache the information of "hbase:meta" and user table Region in memory. When the application initiates the next data operation, HBase Client will first obtain these information from memory; When the corresponding data information is found in the memory cache, HBase Client will repeat the above operations.
4. HBase HA principle and implementation plan
The HMaster in HBase is responsible for region allocation. When the regionserver service stops, the HMaster migrates the corresponding region to other RegionServers. In order to solve the problem that the normal function of HBase is affected due to HMaster single point of failure, the HMaster HA mode is introduced.
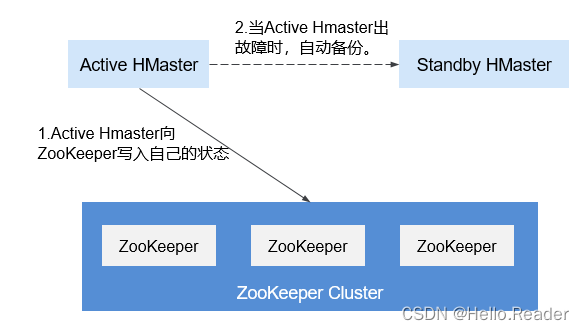
The HMaster high availability architecture is realized by creating an ephemeral zookeeper node in the ZooKeeper cluster.
When the two nodes of HMaster start, they will try to create a znode node master on the ZooKeeper cluster. The one created first becomes the Active HMaster, and the one created later becomes the Standby HMaster.
Standby HMaster will add listening events to the master node. If the master node service stops, it will lose contact with the zooKeeper cluster, and the master node will disappear after the session expires. The Standby node detects the disappearance of the node by listening to the event (watch event), and will create a master node to become the Active HMaster itself, and the master-standby switchover is completed. If the node that stopped the service is restarted later and finds that the master node already exists, it will enter the Standby mode and create a monitoring event for the master znode.
When the client accesses HBase, it will first find the address of the HMaster through the master node information on ZooKeeper, and then connect to the Active HMaster.
Five, the relationship between HBase and HDFS
HDFS is a sub-project of Apache's Hadoop project, and HBase utilizes Hadoop HDFS as its file storage system. HBase is located at the structured storage layer, and Hadoop HDFS provides HBase with highly reliable underlying storage support. Except for some log files generated by HBase, all data files in HBase can be stored on the Hadoop HDFS file system.
Six, the relationship between HBase and ZooKeeper
The relationship between HBase and ZooKeeper is shown in the relationship between ZooKeeper and HBase in the figure below.
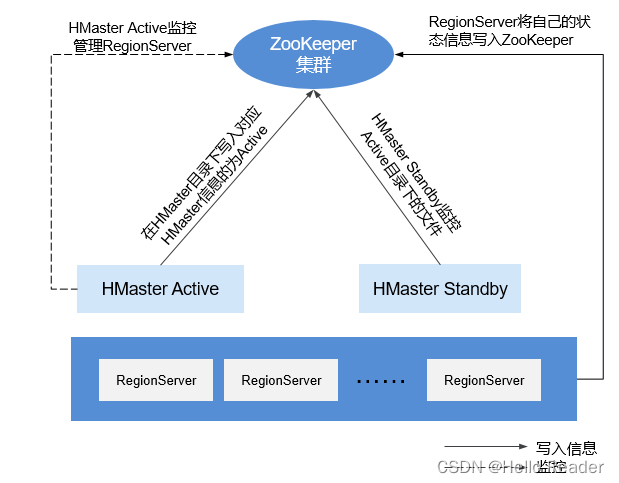
HRegionServer is registered in ZooKeeper as an Ephemeral node. Among them, ZooKeeper stores the following information of HBase: HBase metadata, HMaster address.- HMaster perceives the health status of each HRegionServer at any time through ZooKeeper for control and management.
- HBase can also deploy multiple HMasters, similar to HDFS NameNode. When the HMaster primary node fails, the HMaster standby node will obtain the entire HBase cluster status information stored by the primary HMaster through ZooKeeper. That is, the problem of avoiding the HBase single point of failure problem is implemented through ZooKeeper.