There are two ways to operate es in java
-
By operating the 9300 port of es, 9300 is the tcp port, the communication between the cluster nodes is also through the 9300 port, a long connection will be established through 9300 and es, the following es dependencies can be directly operated
However, with the upgrade of the es version, spring-data needs to package the jar packages of different versions of es. It seems that it has not been packaged to this version (2019). In addition, the official does not recommend operating es through 9300, and this method will be used in the future
es8. abandoned -
Through 9200 operation, send http request
- JestClient, unofficial, slow update
- RestTemplate (springboot), simulates sending http requests, many es operations need to be encapsulated by yourself, which is troublesome
- HttpCLient, ditto
Elasticsearch-Rest-Client, the official RestClient, encapsulates ES operations, has a clear API hierarchy, and is easy to use
When we browsed the official documents, we found that jswe can directly operate es, so why don't we directly use js to operate es?
-
For safety, because the es cluster belongs to the back-end cluster server, the port is generally not exposed to the outside world. If it is exposed to the outside world, it will be maliciously used by others
-
js has a low degree of support for es. If we use js to operate, we don't need to use the api provided by the official website. We can directly send ajax requests and use native es statements
Among them, the java api on the official website is operated through 9300, and the java rest api is operated through 9200
Java Low Level REST ClientThere are and in the official website Java High Level REST Client, the relationship is the same as mybatis and jdbc
Elasticsearch-Rest-Client (official, recommended)
This is not specifically for learning by watching videos. It was typed by the teacher when I was in Guli Mall, so it is actually a summary of what is involved in Guli Mall. Naturally, it is used for the version.
This is an api I summarized. I haven't used it in real comparison, just to clarify my thinking.
maven
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.5</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.atlinxi.gulimall</groupId>
<artifactId>gulimall-search</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>gulimall-search</name>
<description>elasticsearch检索服务</description>
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.4.2</elasticsearch.version>
<spring-cloud.version>2020.0.4</spring-cloud.version>
</properties>
<dependencies>
<dependency>
<groupId>com.atlinxi.gulimall</groupId>
<artifactId>gulimall-common</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.4.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
configuration file
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848
spring.application.name=gulimall-search
es configuration class
package com.atlinxi.gulimall.search.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* es配置类,给容器中注入一个RestHighLevelClient
*/
@Configuration
public class GulimallElasticSearchConfig {
// 后端访问es的时候,出于安全考虑,可以携带一个请求头
// 现在暂时不用
public static final RequestOptions COMMON_OPTIONS;
static {
RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
// builder.addHeader("Authorization", "Bearer " + TOKEN);
// builder.setHttpAsyncResponseConsumerFactory(
// new HttpAsyncResponseConsumerFactory
// .HeapBufferedResponseConsumerFactory(30 * 1024 * 1024 * 1024));
COMMON_OPTIONS = builder.build();
}
@Bean
public RestHighLevelClient esRestClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("192.168.56.10", 9200, "http")
// new HttpHost("localhost", 9201, "http")
));
return client;
}
}
Guide package
package com.atlinxi.gulimall.search;
import com.alibaba.fastjson.JSON;
import com.atlinxi.gulimall.search.config.GulimallElasticSearchConfig;
import lombok.Data;
import lombok.ToString;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.aggregations.bucket.terms.TermsAggregationBuilder;
import org.elasticsearch.search.aggregations.metrics.Avg;
import org.elasticsearch.search.aggregations.metrics.AvgAggregationBuilder;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
@Autowired
RestHighLevelClient restHighLevelClient;
api
Inquire
// 1. 创建检索请求
SearchRequest searchRequest = new SearchRequest();
// 2. 指定索引
searchRequest.indices("bank");
// 3. 指定DSL,检索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 3.1 构造检索条件
// 所有的函数名都对应原生es DSL语句
// searchSourceBuilder.query();
// searchSourceBuilder.from();
// searchSourceBuilder.size();
// searchSourceBuilder.aggregation();
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
boolQuery.must(QueryBuilders.matchQuery("skuTitle", param.getKeyword()));
boolQuery.filter(QueryBuilders.termQuery("catalogId", param.getCatalog3Id()));
boolQuery.filter(QueryBuilders.termsQuery("brandId", param.getBrandId()));
BoolQueryBuilder nestedBoolQuery = QueryBuilders.boolQuery();
QueryBuilders.nestedQuery("attrs", nestedBoolQuery, ScoreMode.None);
boolQuery.filter(nestedQuery);
QueryBuilders.rangeQuery("skuPrice");
boolQuery.filter(rangeQuery);
searchSourceBuilder.query(QueryBuilders.matchQuery("address","mill"));
searchSourceBuilder.query(boolQuery);
searchSourceBuilder.sort(field, order);
sourceBuilder.from(0);
sourceBuilder.size(10);
HighlightBuilder builder = new HighlightBuilder();
builder.field("skuTitle");
builder.preTags("<b style='color:red'>");
builder.postTags("</b>");
sourceBuilder.highlighter(builder);
// 3.2 聚合
// 按照年龄的值分布进行聚合
TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);
// 计算平均薪资
AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg").field("balance");
AggregationBuilders.nested("attr_agg", "attrs");
searchSourceBuilder.aggregation(balanceAvg);
searchSourceBuilder.aggregation(ageAgg);
// 4. 执行检索请求
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
// 5.获取响应结果
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
searchHit.getSourceAsString();
// 3.1 获取聚合结果
Aggregations aggregations = searchResponse.getAggregations();
Terms ageAgg1 = aggregations.get("ageAgg");
// 返回值为List<? extends Terms.Bucket>
ageAgg1.getBuckets()
bucket.getKeyAsString();
aggregations.get("balanceAvg");
save updates
// 添加数据有多种方式,例如hashmap、直接将json粘在这儿
IndexRequest request = new IndexRequest("users");
request.id("1");
// request.source("userName","zhangsan","age",12,"gender","男");
// String jsonString = "{" +
// "\"user\":\"kimchy\"," +
// "\"postDate\":\"2013-01-30\"," +
// "\"message\":\"trying out Elasticsearch\"" +
// "}";
// request.source(jsonString, XContentType.JSON);
User user = new User();
user.setUserName("zs");
user.setAge(12);
user.setGender("man");
String jsonString = JSON.toJSONString(user);
request.source(jsonString, XContentType.JSON);
// 执行保存/更新操作
IndexResponse index = restHighLevelClient.index(request, GulimallElasticSearchConfig.COMMON_OPTIONS);
// 批量保存
// 1. 建立索引 product 建立好映射关系(kibana操作)
// 2. 给es中保存这些数据
BulkRequest bulkRequest = new BulkRequest();
IndexRequest indexRequest = new IndexRequest(EsConstant.Product_INDEX);
indexRequest.id(skuEsModel.getSkuId().toString());
String s = JSON.toJSONString(skuEsModel);
indexRequest.source(s, XContentType.JSON);
bulkRequest.add(indexRequest);
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, GulimallElasticSearchConfig.COMMON_OPTIONS);
// todo 如果批量错误,处理错误
boolean b = bulk.hasFailures();
bulk.getItems()
Spring Data ElasticSearch
Spring Data can greatly simplify the writing method of JPA, and can realize the access and operation of data without writing the implementation. In addition to CRUD, it also includes some commonly used functions such as paging and sorting.
configuration file
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:es="http://www.springframework.org/schema/data/elasticsearch"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/data/elasticsearch
http://www.springframework.org/schema/data/elasticsearch/spring-elasticsearch.xsd
">
<!--
如果你希望 进一步了解 xsd相关的知识 请求百度去 百度不着了 http://www.jk1123.com/?p=124
-->
<!--
配置 client 连上 es
配置 dao层的扫描
配置其他 一个叫做 esTemplate 就是一个简单对应client封装
-->
<es:transport-client id="client" cluster-nodes="127.0.0.1:9300" cluster-name="my-elasticsearch"/>
<es:repositories base-package="com.itheima.dao"></es:repositories>
<bean id="elasticsearchTemplate" class="org.springframework.data.elasticsearch.core.ElasticsearchTemplate">
<constructor-arg name="client" ref="client"></constructor-arg>
</bean>
</beans>
Entity class
The no-argument structure of the entity class must have, otherwise the queried object cannot be mapped to the entity class
-
@Document(indexName="blob3", type="article"):
indexName: the name of the index (required)
type: the type of the index -
@Id: the unique identifier of the primary key
-
@Field(index=true, analyzer="ik_smart", store=true, searchAnalyzer="ik_smart", type = FieldType.text)
analyzer: the tokenizer used for storage
searchAnalyze: the tokenizer used for searching
store: whether to store
type : type of data
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
//@Document 文档对象 (索引信息、文档类型 )
@Document(indexName="test03",type="book")
public class Book {
//@Id 文档主键 唯一标识
@Id
//@Field 每个文档的字段配置(类型、是否分词、是否存储、分词器 )
@Field(store = true, index = false, type = FieldType.Integer)
private Integer id;
@Field(analyzer = "ik_max_word", store = true, type = FieldType.text)
private String title;
@Field(analyzer = "ik_max_word", store = true, type = FieldType.text)
private String content;
@Field(index = false, store = true, type = FieldType.Long)
private Long sales;
dao
import com.itheima.domain.Book;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
public interface BookDao extends ElasticsearchRepository<Book, Integer> {
// 除了系统自带的方法,还可以自定义命名
List<Book> findByContent(String content);
List<Book> findByContentAndTitle(String content, String title);
Page<Book> findByContent(String content, Pageable pageable);
}
crud
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import javax.annotation.Resource;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations = "classpath:beans.xml")
public class AppTest {
@Resource
private BookDao bookDao;
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
// 创建索引库
@Test
public void testCreatIndex(){
elasticsearchTemplate.createIndex(Book.class);
elasticsearchTemplate.putMapping(Book.class);
}
// 新增或者更新
@Test
public void save(){
Book book = new Book(20,"20","20",20L);
bookDao.save(book);
}
// 删除
@Test
public void testDelete(){
bookDao.deleteById(20);
}
@Test
public void testFindById(){
Book book = bookDao.findById(20).get();
System.out.println(book);
}
@Test
public void testFindByPageAndSort() throws IOException {
// PageRequest.of() 构建的是一个Pageable对象,此对象是在spring-data-commons包下
// 所以凡是spring data 系列,都可以用该对象来进行分页
Page<Book> books = bookDao.findAll(PageRequest.of(0, 10,Sort.Direction.ASC,"sales"));
// 总条数
long totalElements = books.getTotalElements();
// 总页数
int totalPages = books.getTotalPages();
System.out.println(totalElements);
System.out.println(totalPages);
books.forEach(book -> System.out.println(book));
}
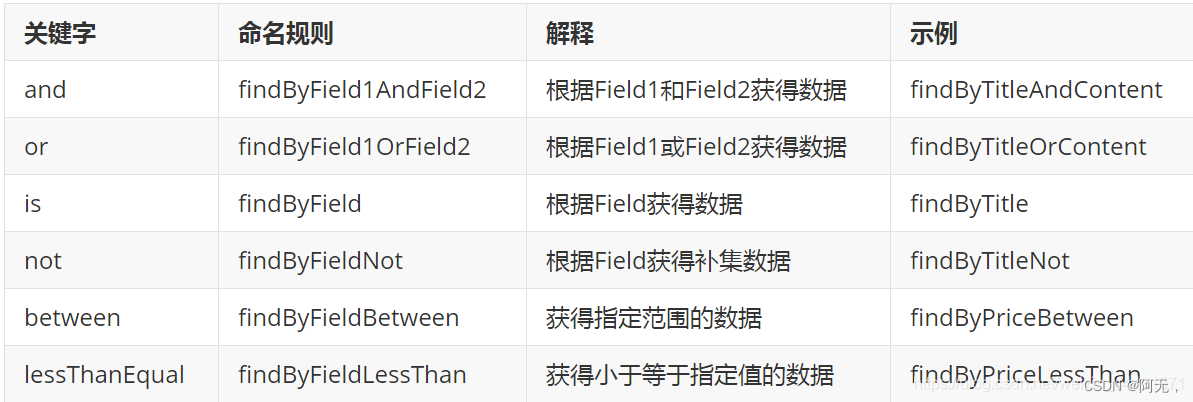
Method Naming Rules Query
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository
public interface BookDao extends ElasticsearchRepository<Book, Integer> {
List<Book> findByContent(String content);
List<Book> findByContentAndTitle(String content, String title);
Page<Book> findByContent(String content, Pageable pageable);
}
@Test
public void testMethodName(){
List<Book> byContentAndTitle = bookDao.findByContentAndTitle("程序", "程序");
byContentAndTitle.forEach(book -> System.out.println(book));
}
springdata has no encapsulation method for es
For example, term, query_string, highlighting, etc., use native api
@Test
public void findQueryString(){
//没有封装 的方法
SearchQuery searchQuery=new NativeSearchQueryBuilder()
//依旧传递的查询方式 查询参数
.withQuery(QueryBuilders.queryStringQuery("我是程序员"))
.build();
Page<Book> page = bookDao.search(searchQuery);
long totalElements = page.getTotalElements();
System.out.println("总条数:"+totalElements);
int totalPages = page.getTotalPages();
System.out.println("总页数:"+totalPages);
List<Book> books = page.getContent();
books.forEach(b-> System.out.println(b));
}
@Test
public void findTerm2(){
//没有封装 的方法
SearchQuery searchQuery=new NativeSearchQueryBuilder()
//依旧传递的查询方式 查询参数
.withQuery(QueryBuilders.termQuery("content","程序"))
.build();
Page<Book> page = bookDao.search(searchQuery);
long totalElements = page.getTotalElements();
System.out.println("总条数:"+totalElements);
int totalPages = page.getTotalPages();
System.out.println("总页数:"+totalPages);
List<Book> books = page.getContent();
books.forEach(b-> System.out.println(b));
}
Highlight
@Test
public void testHighLight() {
SearchQuery searchQuery = new NativeSearchQueryBuilder()
//依旧传递的查询方式 查询参数
.withQuery(QueryBuilders.termQuery("content", "程序"))
.withHighlightFields(new HighlightBuilder.Field("content").preTags("<xh style='color:red'>").postTags("</xh>"))
.build();
AggregatedPage<Book> page = elasticsearchTemplate.queryForPage(searchQuery, Book.class, new SearchResultMapper() {
//自定义结果映射器 核心 将高亮字段取出 设置对象 返回数据就有高亮显示 而spring-data-es 默认实现
//DefaultResultMapper 它 不会取出高亮字段 不用
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse searchResponse, Class<T> aClass, Pageable pageable) {
List<Book> books = new ArrayList<>();
// 总条数
long totalHits = searchResponse.getHits().getTotalHits();
//System.out.println(totalHits);
// 数据,包含高亮显示的字段
SearchHits hits = searchResponse.getHits();
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit sh = iterator.next();
// 每一条数据{id=17, title=程序员的自我修养—链接、装载与库, content=俯瞰程序前世今生参透代码如何变成程序在系统中运行 透过系统软件底层形成机制走进程序世界探索深层次的自己, sales=6856}
//高亮字段{content=[content], fragments[[俯瞰<xh style='color:red'>程序</xh>前世今生参透代码如何变成<xh style='color:red'>程序</xh>在系统中运行 透过系统软件底层形成机制走进<xh style='color:red'>程序</xh>世界探索深层次的自己]]}
Map<String, Object> source = sh.getSource();
System.out.println("每一条数据" + source);
Map<String, HighlightField> highlightFields = sh.getHighlightFields();
System.out.println("高亮字段" + highlightFields);
//开始封装book对象
Book book = new Book();
Integer id = (Integer) source.get("id");
book.setId(id);
String title = (String) source.get("title");
book.setTitle(title);
HighlightField content = highlightFields.get("content");
book.setContent(content.getFragments()[0].toString());
Integer sales = (Integer) source.get("sales");
book.setSales(Long.valueOf(sales));
books.add(book);
}
return new AggregatedPageImpl(books, pageable, totalHits);
}
});
long totalElements = page.getTotalElements();
System.out.println("总条数:" + totalElements);
int totalPages = page.getTotalPages();
System.out.println("总页数:" + totalPages);
List<Book> books = page.getContent();
books.forEach(b -> System.out.println(b));
}
elasticsearch transport operates through 9300
maven
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.24</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.12</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.8.1</version>
</dependency>
</dependencies>
// 创建客户端对象
private TransportClient client;
// 创建客户端对象
@Before
public void init() {
try {
//创建一个客户端对象
Settings settings = Settings.builder()
.put("cluster.name", "my-elasticsearch")
.build();
client = new PreBuiltTransportClient(settings)
//少服务器的地址
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
// .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9301))
// .addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"),9302));
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
// 创建type和mapping
client.admin().indices().preparePutMapping("test02")
.setType("book")
.setSource("{\n" +
" \"book\": {\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \t\"type\": \"long\",\n" +
" \"store\": true,\n" +
" \"index\":\"not_analyzed\"\n" +
" },\n" +
" \"title\": {\n" +
" \t\"type\": \"text\",\n" +
" \"store\": true,\n" +
" \"index\":\"analyzed\",\n" +
" \"analyzer\":\"ik_max_word\"\n" +
" },\n" +
" \"content\": {\n" +
" \t\"type\": \"text\",\n" +
" \"store\": true,\n" +
" \"index\":\"analyzed\",\n" +
" \"analyzer\":\"ik_max_word\"\n" +
" },\n" +
" \"sales\":{\n" +
" \"type\": \"long\",\n" +
" \"store\": true,\n" +
" \"index\":\"not_analyzed\"\n" +
" }\n" +
" }\n" +
" }\n" +
" }", XContentType.JSON)
.get();
// 文档的crud
@Test
public void testAdd(){
client.prepareIndex("test02", "book", "1")
.setSource(
"{\n" +
"\t\"id\":1,\n" +
"\t\"title\":\"测试添加\",\n" +
"\t\"content\":\"测试添加数据\",\n" +
"\t\"sales\":666\n" +
"}",XContentType.JSON
)
.get();
}
// 实体类进行存储
@Test
public void testAdd() throws JsonProcessingException {
Book book = new Book();
book.setId(2L);
book.setTitle("对象测试");
book.setContent("对象测试内容");
book.setSales(1000L);
// 使用json转换工具
ObjectMapper mappers = new ObjectMapper();
String string = mappers.writeValueAsString(book);
client.prepareIndex("test02", "book", "2")
.setSource(
string,XContentType.JSON
)
.get();
}
@Test
public void deleteDocument(){
client.prepareDelete("test02", "book", "1").get();
}
// 批量导入
@Test
public void bulkAdd() throws IOException {
BulkRequestBuilder bulkRequest = client.prepareBulk();
// 数据在本地中,进行读取
File file = new File("F:\\darkHorse\\darkHorsePool\\springbootSeries\\dailyQuest\\day90_elasticSearch\\resource\\esData.txt");
BufferedReader bufferedReader = new BufferedReader(new FileReader(file));
String line = null;
int i = 1000;
while ((line = bufferedReader.readLine()) != null){
bulkRequest.add(client.prepareIndex("test02", "book",i++ + "")
.setSource(line,XContentType.JSON)
);
}
BulkResponse bulkResponse = bulkRequest.get();
if (bulkResponse.hasFailures()) {
// process failures by iterating through each bulk response item
}
}
@Test
public void testFindIds(){
SearchRequestBuilder searchRequestBuilder = client.prepareSearch("test02")
.setTypes("book")
//这个地方 告诉构建器 使用什么类型查询方式
//查询方式 使用 QueryBuilders.term...matchall....queryString
.setQuery(QueryBuilders.idsQuery().addIds("1000","1002","1003"))
.setFrom(0)
.setSize(20);
//返回了一个 SearchResponse 响应对象
SearchResponse searchResponse = searchRequestBuilder.get();
SearchHits hits = searchResponse.getHits();
long totalHits = hits.getTotalHits();
System.out.println("一共多少条记录:"+totalHits);
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()){
SearchHit searchHit = iterator.next();
Map<String, Object> source = searchHit.getSource();
System.out.println(source);
}
}
SearchRequestBuilder searchRequestBuilder = client.prepareSearch("test02")
.setTypes("book")
//这个地方 告诉构建器 使用什么类型查询方式
//查询方式 使用 QueryBuilders.term...matchall....queryString
.setQuery(QueryBuilders.termQuery("content","程序"))
.setFrom(0)
.setSize(20);
@Test
public void highLight() {
HighlightBuilder highlightBuilder = new HighlightBuilder()
.preTags("<font style='color:red'>")
.postTags("</font>")
.field("content");
SearchRequestBuilder searchRequestBuilder = client.prepareSearch("test02")
.setTypes("book")
//这个地方 告诉构建器 使用什么类型查询方式
//查询方式 使用 QueryBuilders.term...matchall....queryString
.setQuery(QueryBuilders.termQuery("content", "程序"))
.setFrom(0)
.setSize(20)
.highlighter(highlightBuilder);
//返回了一个 SearchResponse 响应对象
SearchResponse searchResponse = searchRequestBuilder.get();
SearchHits hits = searchResponse.getHits();
long totalHits = hits.getTotalHits();
System.out.println("一共多少条记录:" + totalHits);
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit searchHit = iterator.next();
Map<String, Object> source = searchHit.getSource();
System.out.println(source);
//获取高亮显示的内容 这是一个map集合
Map<String, HighlightField> highlightFields = searchHit.getHighlightFields();
HighlightField content = highlightFields.get("content");
Text[] fragments = content.getFragments();
System.out.println(fragments[0].toString());
}
}