From: Heart of the Machine
Enter the NLP group —> join the NLP exchange group
The success of large language models (LLM) such as GPT is inseparable from the Softmax attention mechanism, but this mechanism also has some shortcomings such as high cost.
Recently, a research team from Shanghai Artificial Intelligence Laboratory and OpenNLPLab proposed a new large-scale language model TransNormerLLM, which completely abandoned the Softmax-based attention mechanism and used the newly proposed linear attention instead. According to reports, TransNormerLLM is the first large-scale language model (LLM) based on linear attention, which outperforms traditional Softmax attention-based models in terms of accuracy and efficiency. The researchers will also release an open-source version of their pretrained model.

Paper: https://arxiv.org/abs/2307.14995
Model: https://github.com/OpenNLPLab/TransnormerLLM
Large language models have revolutionized the field of natural language processing (NLP). They excel at many different types of tasks, advancing the ability to understand, generate, and interact using human language in a computational framework. The previous development of language modeling mainly revolved around the Transformer architecture, among which the pillar models include the basic Transformer, GPT series, BERT and BART and other groundbreaking models. The success of the Transformer architecture is based on the softmax attention mechanism, which can identify the dependencies between the input tokens in the data-driven model scheme, and it can also perceive the global position, so that the model can effectively deal with the long-range dynamics of natural language.
Even so, traditional Transformers still have limitations. First and foremost, they suffer from quadratic time complexity with respect to sequence length, which limits their scalability and drags down computational resources and time efficiency during training and inference phases. In order to simplify this quadratic time complexity to linear complexity, many researchers have proposed a variety of different sequence modeling methods. However, these methods are difficult to use for LLM for two reasons: 1) they often perform unsatisfactorily on language modeling tasks; 2) they do not exhibit speed advantages in real-world scenarios.
The TransNormerLLM proposed in this paper is the first LLM based on linear attention, which outperforms traditional softmax attention in both accuracy and efficiency. The construction of TransNormerLLM is based on the previous linear attention architecture TransNormer, and some modifications have been made to improve performance. Key improvements in TransNormerLLM include position embedding, linear attention speedup, gating mechanism, tensor normalization, and inference speedup.
One of the improvements that deserves special attention is to replace TransNormer's DiagAttention with linear attention, which can improve the overall interactive performance. The researchers also introduced LRPE with exponential decay to solve the dilution problem. In addition, the researchers also introduced a new technology called Lightning Attention (Lightning Attention), and said that it can double the speed of linear attention during training, and it can also reduce memory usage by 4 times through perception IO. Not only that, but they also simplified the GLU and normalization methods, and the latter increased the overall speed by 20%. They also proposed a robust inference algorithm that can guarantee numerical stability and constant inference speed under different sequence lengths, thereby improving the efficiency of the model in the training and inference phases.
In order to verify the effect of TransNormerLLM, the researchers carefully collected a large corpus with a size of more than 6TB and more than 2 trillion tokens. To ensure the quality of the data, they also developed a self-cleaning strategy for filtering the collected corpus. As shown in Table 1, the researchers extended the original TransNormer model and obtained multiple TransNormerLLM models with parameters ranging from 385 million to 175 billion. Then they conduct comprehensive experiments and control variable studies based on the new large-scale corpus, and the results show that the new method outperforms the method based on softmax attention and also has faster training and inference speed.
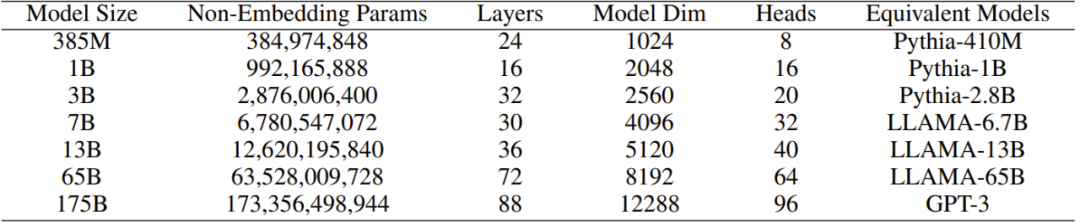
Table 1: Variations of the TransNormerLLM model
In order to promote research in the field of LLM, these researchers from the Shanghai Artificial Intelligence Lab and OpenNLPLab will also open source their own pre-training models. efficient transformer structure".
TransNormerLLM
Architecture Improvement
The following will briefly introduce the various modules of TransNormerLLM and some improvement measures proposed by the researchers.
Improvement 1: Position encoding
The lower layers in TransNormer use DiagAttention to avoid the dilution problem. However, this results in a lack of global interaction between tokens. To address this issue, the researchers used LRPE (Linearized Relative Position Encoding) with exponential decay for TransNormerLLM, which preserves full attention at lower layers. The researchers called this approach LRPE-d.
Improvement 2: Gating mechanism
Gating can enhance the performance of the model and smooth the training process. The researchers used the Flash method from the paper "Transformer quality in linear time" for TransNormerLLM and used the structure of gated linear attention (GLA) in the token mixture.
In order to further improve the speed of the model, they also proposed Simple GLU (SGLU), which removes the activation function of the original GLU structure, because the gate itself can introduce nonlinearity.
Improvement 3: tensor normalization
The researchers used the NormAttention introduced in TransNormer. In TransNormerLLM, they replaced RMSNorm with a new simple normalization function, SimpleRMSNorm (abbreviated as SRMSNorm).
the whole frame
Figure 1 shows the overall structure of TransNormerLLM.
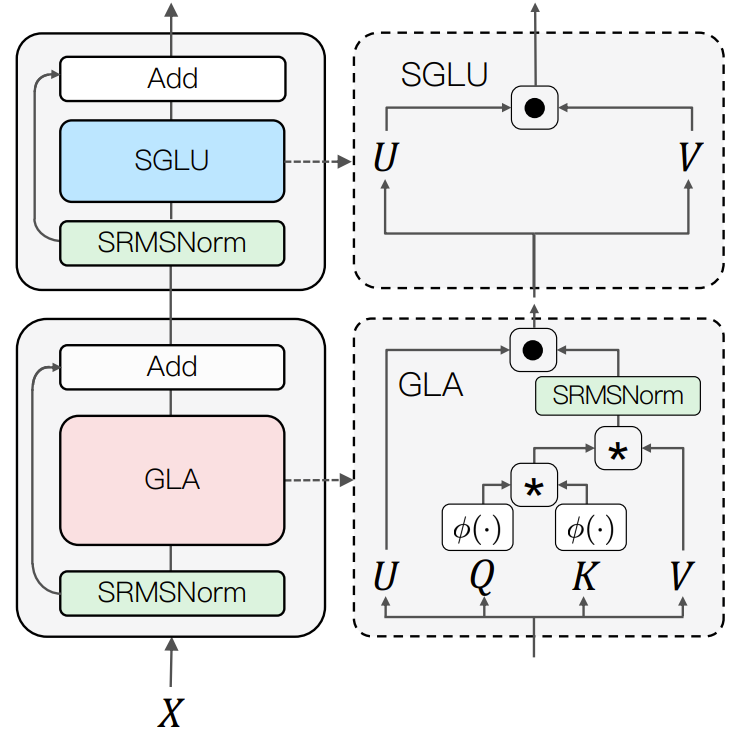
Figure 1: The overall architecture of the newly proposed model
In this architecture, the update of the input X is done in two sequential steps: first, it passes through a Gated Linear Attention (GLA) module using SRMSNorm normalization. Then, again through the simple gated linear unit (SGLU) module using SRMSNorm normalization. This overall architecture helps to improve the performance of the model. The pseudocode of this overall process is given below:
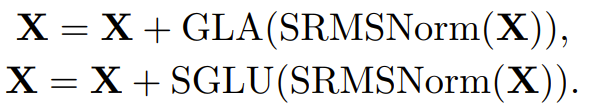
training optimization
lightning attention
In order to speed up the calculation of attention, the researchers introduced the Lightning Attention algorithm, which makes the newly proposed linear attention more suitable for IO (input and output) processing.
Algorithm 1 shows the implementation details of the forward pass of lightning attention, and Algorithm 2 is the backward pass. The researchers said that they also have an implementation version that can calculate gradients faster, which will be released in the future.
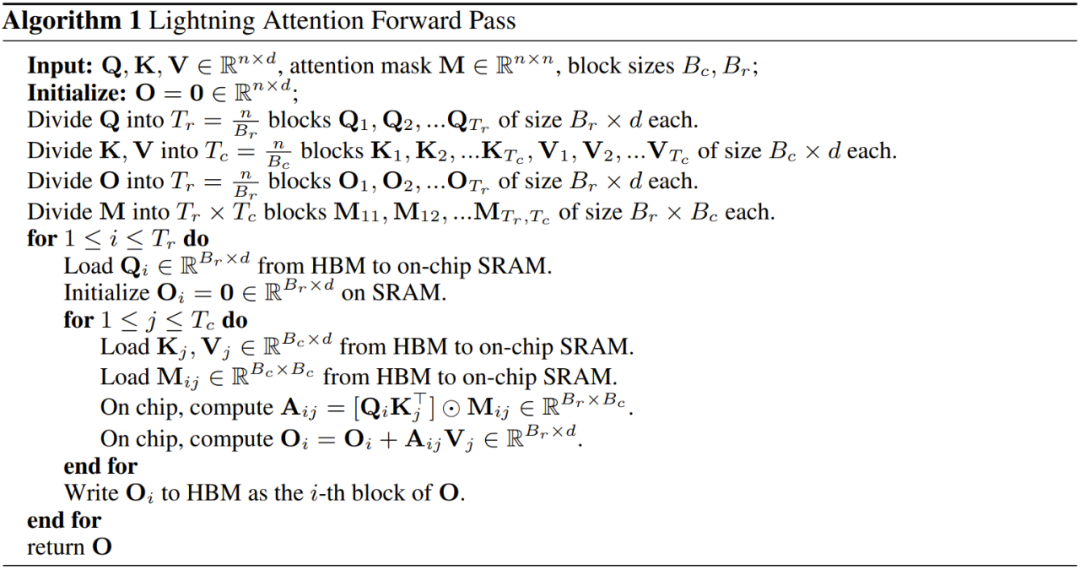

Model Parallelization
To distribute all model parameters, gradients, and optimizer state tensors across a computer cluster, the researchers used Fully Sharded Data Parallel (FSDP/Fully Sharded Data Parallel). This strategic partitioning approach optimizes memory utilization by reducing the memory footprint of each GPU. To further improve efficiency, they used Activation Checkpointing, which reduces the number of activations cached in memory during the backward pass. Instead, these gradients are removed and recomputed when computing them. This technology helps to improve computing efficiency and save resources. In addition, to speed up calculations while reducing GPU memory consumption, the researchers also used Automatic Mixed Precision (AMP).
In addition to the above achievements, the researchers further optimized the system engineering by parallelizing the linear transformer execution model, which was largely inspired by the parallelization of Nvidia's Megatron-LM model. In the traditional Transformer model, each Each transformer layer has a self-attention module followed by a two-layer multilayer perceptron (MLP) module. When using Megatron-LM model parallelism is used independently on these two modules. Similarly, the TransNormerLLM structure is also composed of two main modules: SGLU and GLA; the model parallelization of these two is performed separately.
robust reasoning
This allows TransNormerLLM to perform inference in the form of an RNN. Algorithm 3 gives the details of this process. But therein lies the issue of numerical precision.

To avoid these problems, the researchers proposed a robust inference algorithm, see Algorithm 4.

The results obtained by the original inference algorithm and the robust inference algorithm are the same.
corpus
The researchers collected a large amount of publicly available text from the Internet, with a total size of more than 700TB. The collected data was processed through their data preprocessing procedure, as shown in Figure 2, leaving a 6TB clean corpus containing approximately 2 trillion tokens. In order to provide better transparency and help users better understand, they categorized the data sources. Table 2 gives the specific categories.
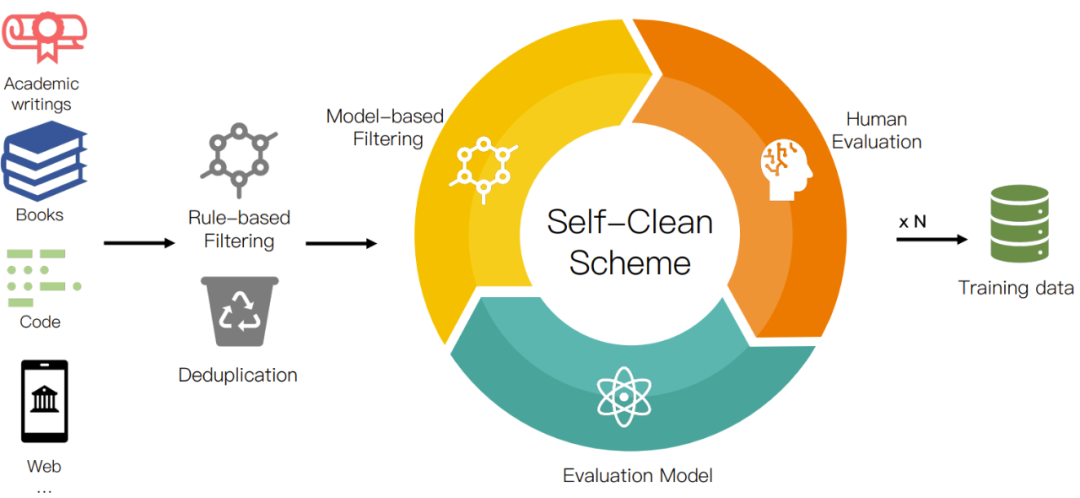
Figure 2: Data preprocessing flow
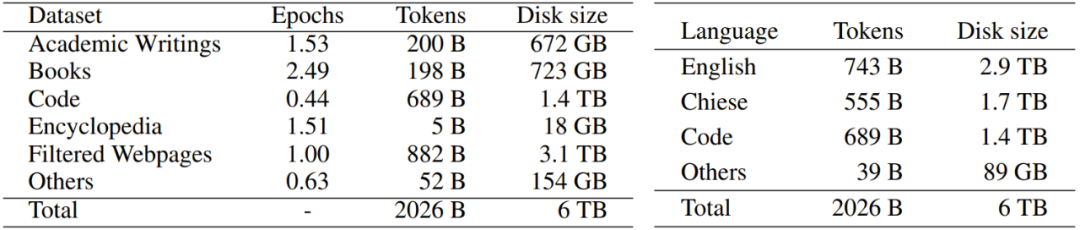
Table 2: Corpus Statistics
experiment
The researchers implemented TransNormerLLM using PyTorch and Trition in the Metaseq framework. The model is trained using the Adam optimizer, and FSDP is also used to efficiently scale the model to an NVIDIA A100 80G cluster. They also appropriately use model parallelism to optimize performance.
Architecture Ablation Experiment

Table 3: Transformer vs TransNormerLLM. Under the same configuration, TransNormerLLM outperforms Transformer by 5% and 9% when the number of model parameters is 385M and 1B, respectively.
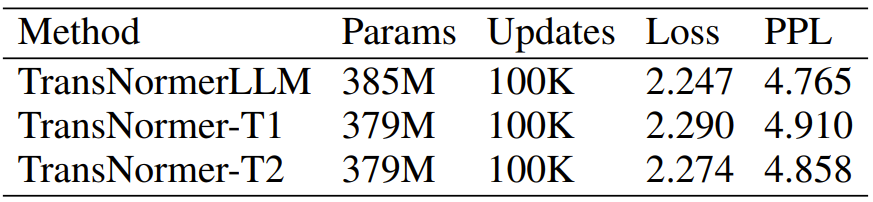
Table 4: TransNormer vs TransNormerLLM. The experimental results of TransNormerLLM are the best.
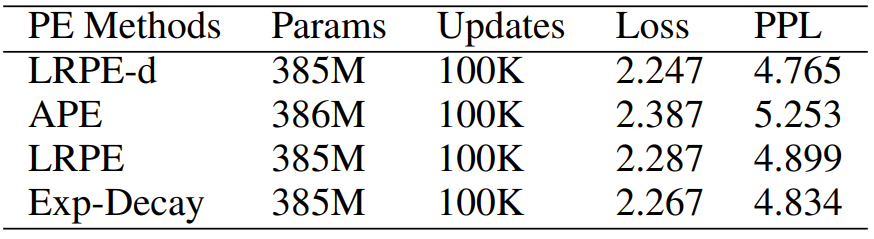
Table 5: The combination of positional encoding using LRPE+LRPE-d gives the best results.

Table 6: Results of ablation experiments in terms of decay temperature. The results show that the new method is better.

Table 7: Results of ablation experiments in terms of gating mechanism. Models using this gating mechanism perform better.
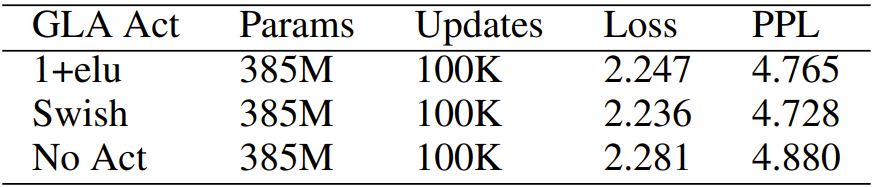
Table 8: Results of ablation experiments for the GLA activation function. The results obtained with different activation functions are similar.

Table 9: Results of ablation experiments with the GLU activation function. Removing the activation function has no negative impact on the results.
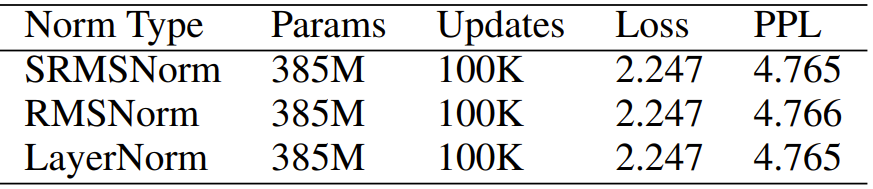
Table 10: Normalization functions. The results using the following normalization functions are not much different.
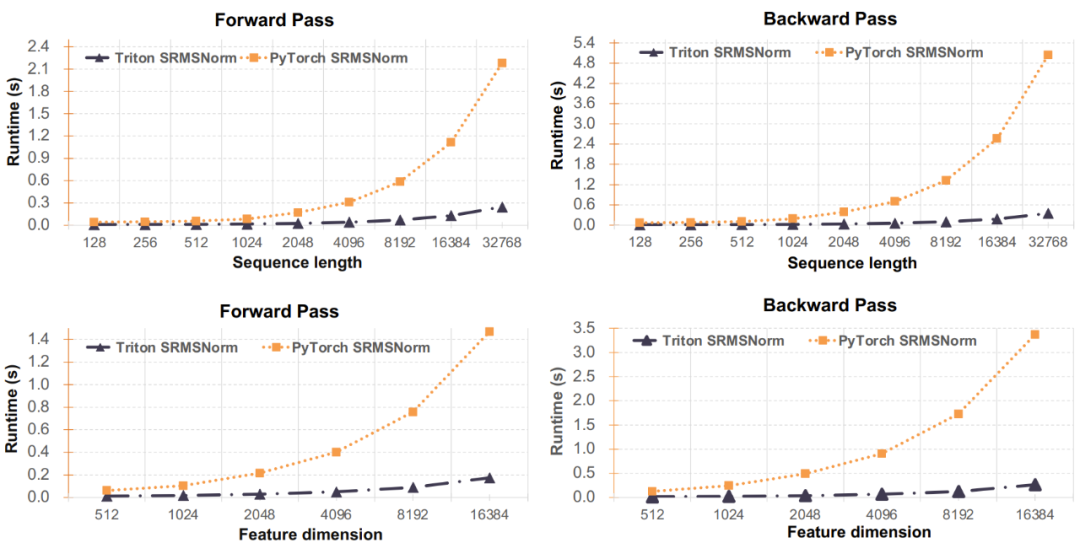
Figure 3: Performance evaluation of the SRMSNorm implementation
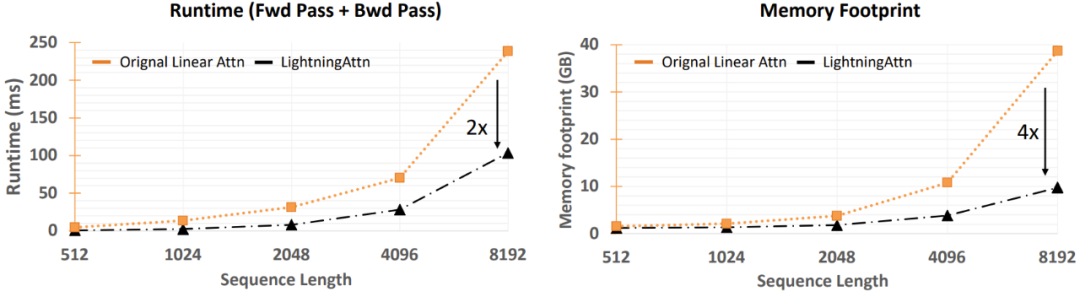
Figure 4: Memory and speed comparison between linear attention and lightning attention
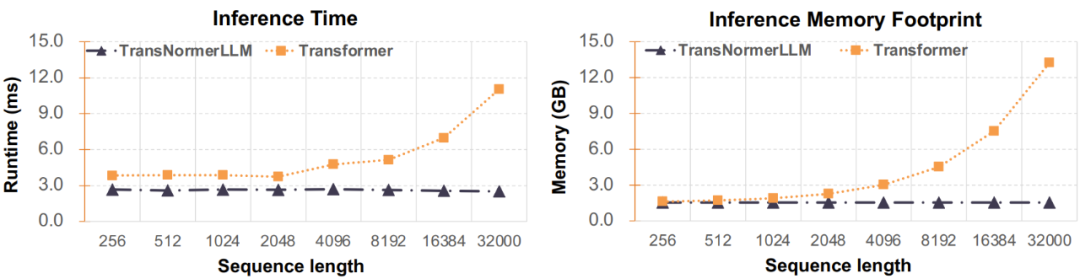
Figure 5: Inference time and memory usage
System Optimization
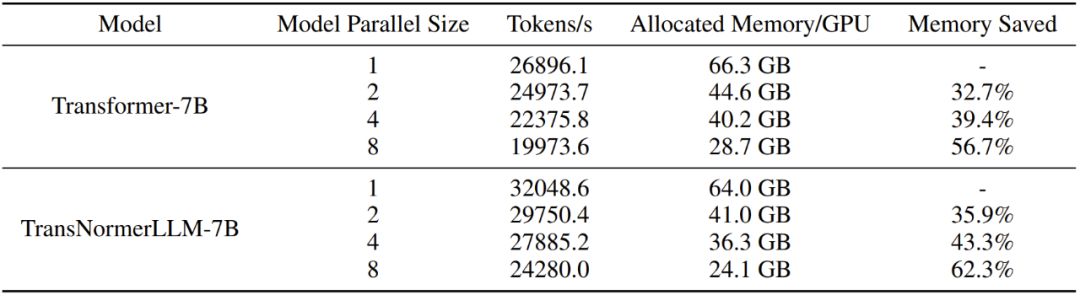
Table 11: Model Parallelism Performance
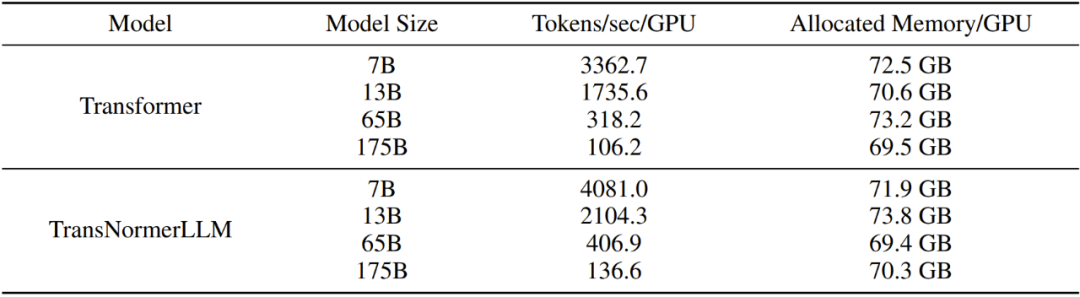
Table 12: Efficiency of training models of different sizes
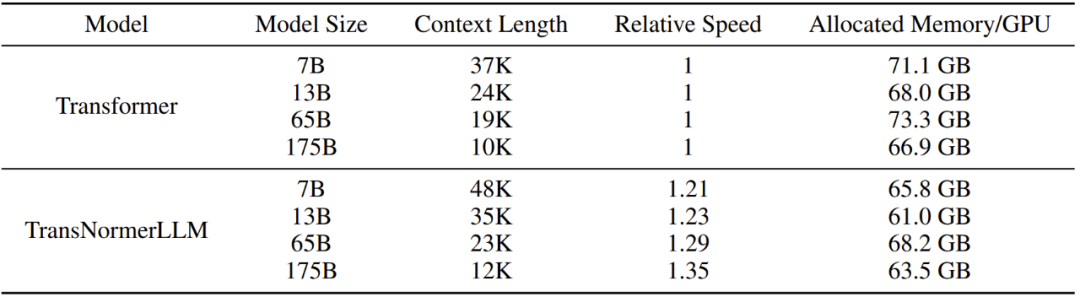
Table 13: Maximum context length for training Transformer and TransNormerLLM
Enter the NLP group —> join the NLP exchange group