
The SadTalker model is an open source model that uses pictures and audio files to automatically synthesize character animations. We give the model a picture and an audio file, and the model will perform corresponding actions on the face of the transferred picture according to the audio file, such as opening the mouth and blinking. , move the head and other actions.
SadTalker, which generates 3DMM's 3D motion coefficients (head pose, expression) from audio and implicitly modulates a novel 3D-aware facial rendering for generating talking head motion videos.
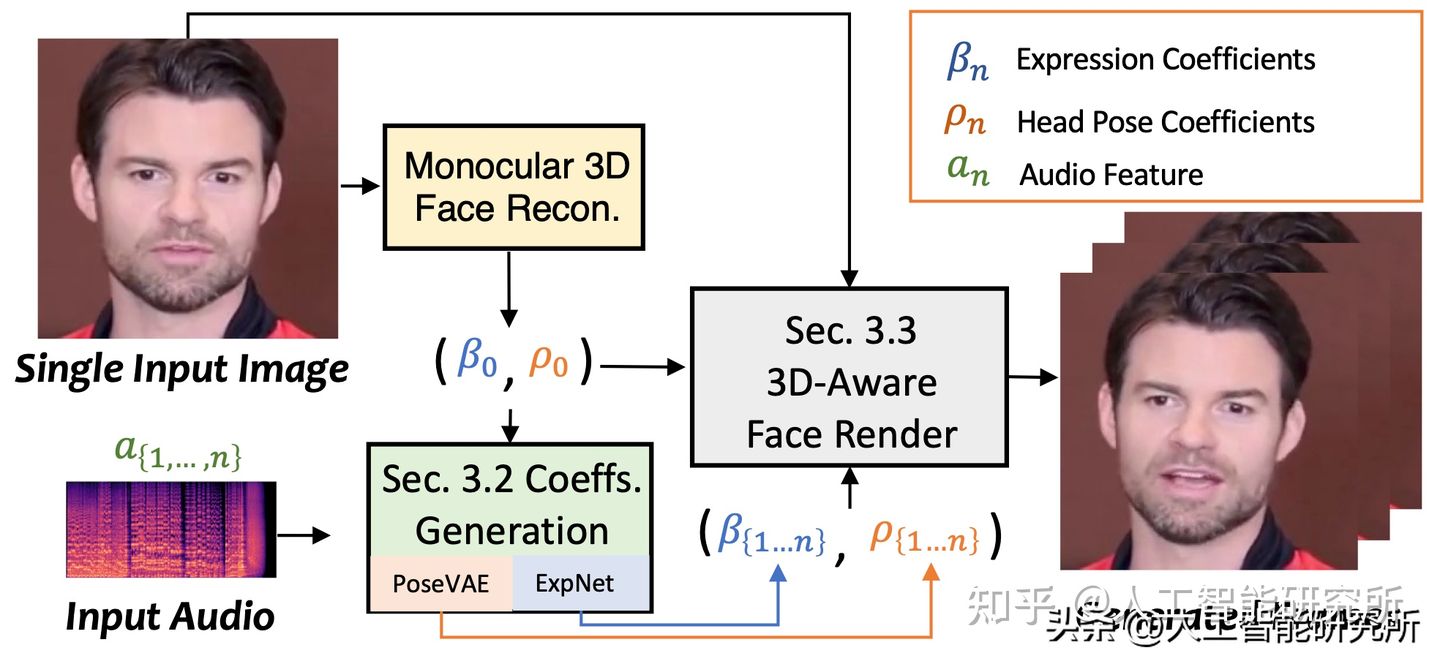
To learn realistic motion, SadTalker explicitly models the connections between audio and different types of motion coefficients, respectively. To be precise, SadTalker proposes the ExpNet model to learn accurate facial expressions from audio by extracting motion coefficients and 3D rendered facial movements. As for the head pose, SadTalker uses PoseVAE to synthesize different styles of head movements.
The model not only supports English, but also supports Chinese, we can experience it directly on the hugging face
https://huggingface.co/spaces/vinthony/SadTalkerOf course, the official open source code, we can run this model directly on our own computer
https://github.com/OpenTalker/SadTalkerOf course, if we want to run this program, we need to install python3.8 or above, and download the pre-trained modelÿ