Introduction: ClickHouse is an open source high-performance columnar database management system, OLAP scene design. Columnar storage, vectorized execution engine, data compression, rich function support, indexing and pre-computing capabilities are the cornerstones of ClickHouse as a high-performance big data real-time analysis engine. In the field of semi-structured data processing, ClickHouse seems powerless. Tencent Cloud Data Warehouse takes another approach to integrate the flexibility of Schema-less database, making the big data real-time analysis system both high-performance and flexible.
Author: Peng Jian, Big Data Expert Engineer, Tencent Cloud
Background: Big Data Analytics and Semi-Structured Data
Semi-structured data refers to data types between structured data (such as tabular data in relational databases) and unstructured data (such as text, images, audio, etc.). Common semi-structured data include JSON, XML, YAML, etc. In the field of big data, semi-structured data plays an increasingly important role. Its importance is self-evident.
-
Wide range of data sources: Internet, Internet of Things, social media, mobile applications, APM and other fields are important sources of semi-structured data;
-
The potential of data value is huge: semi-structured data usually contains a large amount of valuable information, through the analysis and mining of these data, it can provide enterprises with key insights and predictions.
-
Wide range of application scenarios: semi-structured data has good flexibility, can well represent hierarchical structures and complex data relationships, and facilitates data exchange and sharing, making semi-structured data suitable for processing businesses with diverse and irregular data structures Scenes.
With the surge in data volume, semi-structured data will play an increasingly important role in enterprise data analysis. Therefore, big data analysis systems need to be continuously optimized and developed to better deal with the challenges of semi-structured data processing.
With the development of big data technology, Schema-less databases are widely used in storage and analysis scenarios of semi-structured data. Schema-less databases do not need to pre-define the data structure, and allow the data structure to be dynamically expanded at runtime. This feature better adapts to the diversity and potential variability of semi-structured data.
Existing Schema-less databases have the flexibility, scalability, and targeted storage discount capabilities required to process semi-structured data, but lack excellent data analysis capabilities. In big data OLAP scenarios, Schema-less databases with powerful analysis capabilities are even rarer.
As a big data real-time interactive analysis system, ClickHouse is very popular due to its powerful performance advantages. If ClickHouse also has the Schema-less capability, the real-time analysis capability of big data will be even more powerful!
ClickHouse's existing solution for processing semi-structured data
Community ClickHouse before version 22.3, the core solution for processing semi-structured data (take JSON as an example) is to store JSON data as STRING type, and use tool functions to obtain JSON field information to assist query analysis.
-
Advantages: Utilize existing ClickHouse capabilities, easy to implement.
-
Disadvantages: All fields are stored in a mixed manner, and the efficiency of query analysis is low.
Community ClickHouse introduced the OBJECT data type after version 22.3, which supports dynamic sub-column capabilities. The engine performs dynamic type deduction for each written JSON object value, and the JSON attribute will be represented as a dynamic sub-column of the OBJECT(JSON) column. The support of dynamic sub-columns greatly improves the analysis efficiency and scalability support of unstructured data.
-
Advantages: Compared with earlier versions, there has been a qualitative improvement in data modeling and writing flexibility.
-
Disadvantages: This solution still does not unify structured and semi-structured data at the system level of data storage and analysis, and the resulting problems are:
1) The attributes of JSON data are stored as OBJECT (JSON) type dynamic sub-columns. Due to the difference between sub-columns and ordinary columns, users cannot create materialized views, PROJECTION, and add, delete, and modify columns based on dynamic sub-column secondary indexes. and other core functions.
2) Due to the existence of dynamic sub-columns, building a distributed query plan is complicated and the performance is low;
Due to these limitations, it is difficult for customers to use ClickHouse to process semi-structured data. ClickHouse has a strong performance advantage in processing structured data, and Schema-less has unparalleled flexibility and scalability in processing semi-structured data, allowing ClickHouse to have Schema-less capabilities, which can greatly improve the real-time processing/analysis capacity of ClickHouse. The ability to scale semi-structured data will make ClickHouse more competitive in the field of big data real-time analysis.
Tencent Cloud Data Warehouse ClickHouse's innovative solution for processing semi-structured data
Tencent Cloud Data Warehouse ClickHouse implements real-time analysis of semi-structured data solutions. The system design follows the principles of ease of use, high performance, flexibility, and scalability, mainly including the following:
-
Compatible with client protocols, reducing the cost of customer cluster migration;
-
The kernel level supports Schema-less capabilities, making big data analysis both high-performance and flexible;
-
Broadcast metadata information in the cluster to improve the horizontal expansion capability of the system;
If the agreement is newly introduced, it will increase the cost of customer business migration and limit the application scenarios of the cloud data warehouse ClickHouse. At the beginning of the program design, it was clearly reduced the customer's business migration cost to achieve seamless upgrades.
Supports Schema-less capabilities at the kernel level. In short, the business does not need to specify the structure of the table before writing data, and focuses on business logic. After the kernel receives the written data, it dynamically adds columns. The background task dynamically folds or expands the nested structure of semi-structured data according to the query analysis situation to achieve a balance between storage efficiency and query performance.
The cloud data warehouse ClickHouse adopts a decentralized architecture design, there is no shared data between computing nodes, and there is no management node in the cluster. After supporting the Schema-less capability, nodes need to maintain consistent table metadata information. Otherwise, some dynamic columns may not appear on other nodes due to unbalanced data writing, further causing distributed query failures. In order to keep the structure simple, the cloud data warehouse ClickHouse uses the GOSSIP protocol to broadcast metadata information between nodes.
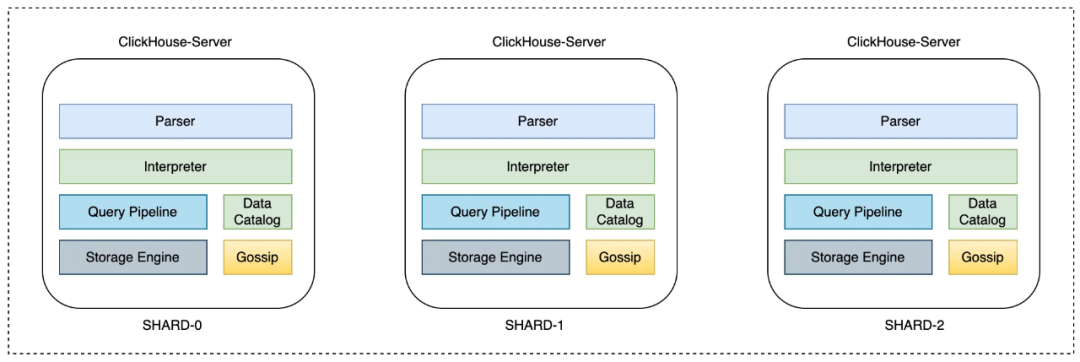
ClickHouse is flexible and extensible in the code framework, and can realize the above functions with less code intrusion.
The kernel supports the Schema-less function
Reducing the cost of business migration is an important consideration in the solution design process. ClickHouse provides rich client interfaces to facilitate business to interact with the system in different ways. These clients have been widely used in business systems.
Taking the Native Protocol as an example, the data writing process requires the client to shake hands with the server to obtain table structure information from the server, including field names and types. Based on the above information, the client serializes the input data and table structure information and sends them to the server. After receiving the request, the server parses out the data in turn, and builds and executes the Query Pipeline.
In order to be compatible with existing protocols, the protocol specifications are not modified, nor are new data types added. Instead, the existing protocols and fields are used. For the Schema-less of the cloud data warehouse ClickHouse, the existing OBJECT or String types are used, and the existing client protocols are used. in particular:
-
In the data writing process, the table engine that supports Schema-less will send an "anonymous" field, which is of type OBJECT or String;
-
The client writes data in JSON format, stores it in an OBJECT or String type field, and sends it to the server;
The server does not publish new data types, and existing business codes can be seamlessly upgraded.
For a table engine that supports Schema-less, after the server receives the data written by the client, it will be parsed into TUPLE type data. Expand the TUPLE type data and wrap it into the common BlockHouse data structure inside ClickHouse. Construct the Query Pipeline for data writing and execute it. Specific process:
-
Parse the data sent by the client;
-
Extend the pipeline for data writing, check whether there is a type conflict before writing data;
-
Separate the JSON data into columns according to its internal fields, and persist it on the secondary disk;
-
After the data is placed, update the dynamic column during the PART submission process;
-
Return the necessary data to the client;
Schematic diagram of data flow, as shown below, where CheckDynamicColumnsTransform will check whether there is a field type conflict.
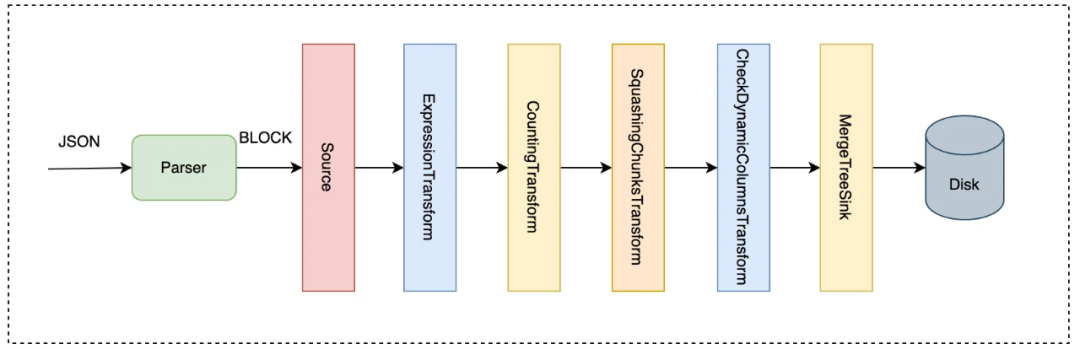
Since the storage layer has already stored JSON internal fields in columns, the query engine layer needs to do some adaptation work. These adaptations include:
-
Support modifying JSON internal fields through ALTER TABLE ADD/MODIFY/DROP COLUMN ...;
-
Support building materialized views based on JSON internal fields, and PROJECTION to speed up queries;
-
Supports unique query methods for semi-structured data, such as querying the nested structure of JSON through wildcards in the SELECT clause.
Broadcast metadata information in the cluster
The cloud data warehouse ClickHouse adopts a centerless architecture design, and the cluster has no unified management node. After the Schema-less function is supported, the dynamic column information needs to be broadcast between nodes, and the dynamic column information of the nodes in the cluster must be kept eventually consistent. Otherwise, there will be a distributed query execution failure problem.
To solve this problem in the future, the GOSSIP protocol is used to broadcast information within the cluster. The main reasons for adopting this protocol include:
-
Scalability: The cloud data warehouse ClickHouse is a decentralized architecture, and it is easy to expand large-scale clusters. The GOSSIP protocol has good scalability and meets the elastic scaling requirements of elastic clusters;
-
Fault tolerance: Failure of any node in the cluster does not affect the correct operation of the GOSSIP algorithm and does not affect the availability of the Cloud Data Warehouse ClickHouse cluster;
-
Final Consistency: Under the decentralized architecture, the algorithm converges quickly and can realize the exponential dissemination of information, so that the time for metadata inconsistency is short;
-
Robustness: The GOSSIP protocol is a decentralized protocol, and the failure to receive orders for any calculation will not affect the information synchronization of other nodes;
Specifically, for a table engine that supports Schema-less, the corresponding version information will be incremented each time a dynamic column is updated. Dynamic column information will be broadcast to other nodes in the cluster through the GOSSIP protocol. Each node maintains a background task that periodically executes message broadcasting actions.
The cluster nodes are divided into two types: the set of connected nodes and the set of nodes not kept connected. Periodic tasks in the background, select a node in each of the above two sets each time, and complete a message broadcast (the local node is marked as local, and the randomly selected node is marked as remote):
-
The local node sends SYNC type information to the remote node: including dynamic column information and version;
-
After receiving the message, the remote node compares it with the local dynamic column, updates its dynamic column information if necessary, and returns ACK type information to the local node. And this type of information includes incremental difference information;
-
After receiving the ACK type information sent by the remote node, the local node updates the local dynamic column information if necessary, and returns an ACK_AGAIN type message to the remote node.
When data is written, or the ALTER command triggers the SCHEMA information of the table to be changed, the corresponding Version will be updated synchronously. The background task of the GOSSIP module will periodically exchange information between local data and random nodes, and update it if necessary.
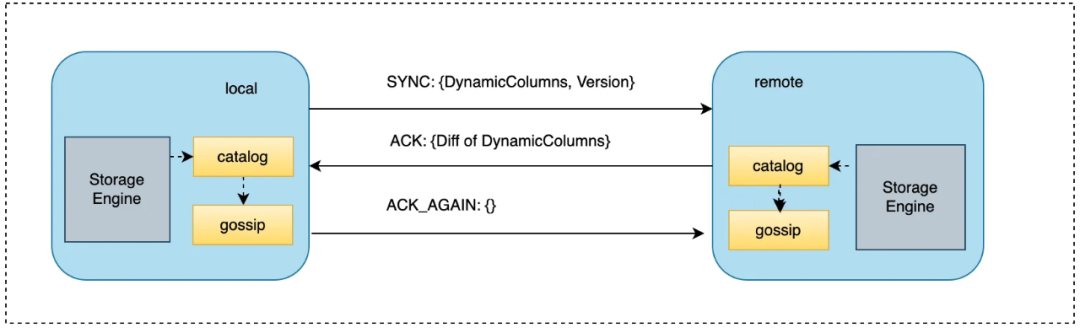
In actual business, dynamic column information does not change frequently. Usually, when a new service is connected, there is a relatively high frequency change, and then tends to a stable state.
Application examples
When semi-structured data is written to a ClickHouse cluster that supports Schema-less, only simple steps are required:
-
When creating a table, you need to set a parameter to identify that the table supports the Schema-less function. The parameter is enable_dynamic_columns=1;
-
When creating a table, you only need to specify the partition key, primary key, and field name and type referenced by the sort key;
For example, create a table:
CREATE TABLE r
(
`@timestamp` DateTime,
`clientip` IPv4
)
ENGINE = MergeTree
PARTITION BY toDate(`@timestamp`)
ORDER BY clientip
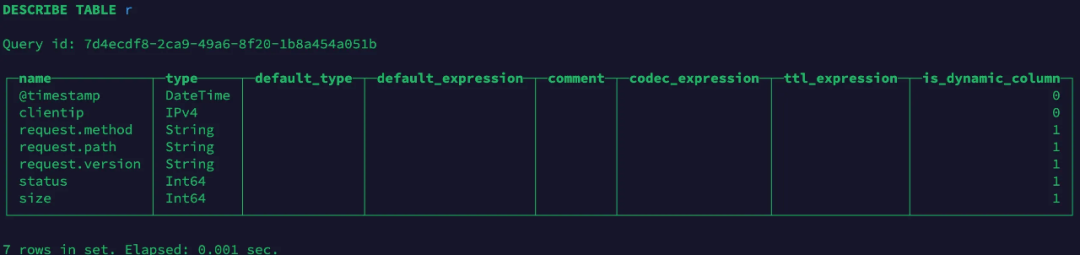
SETTINGS enable_dynamic_columns = 1When creating a table, only a small number of necessary field definitions are required, and at the same time, specifying parameters indicates that the table supports Schema-less functions. It should be noted that, except for supporting the Schema-less function, the other behaviors of the table engine are fully compatible.
When writing data, the semi-structured data needs to be placed behind the defined fields in the form of JSON:
INSERT INTO r SELECT
toDateTime(JSONExtractUInt(json, '@timestamp')) AS timestamp,
toIPv4(JSONExtractString(json, 'clientip')) AS clientip,
json
FROM s3('https://schema-less-testing-1301087413.cos.ap-hongkong.myqcloud.com/documents-01.ndjson.gz', 'JSONAsString')After the JSON data is written, the table will dynamically expand the fields, viewed through DESC r:
View data:
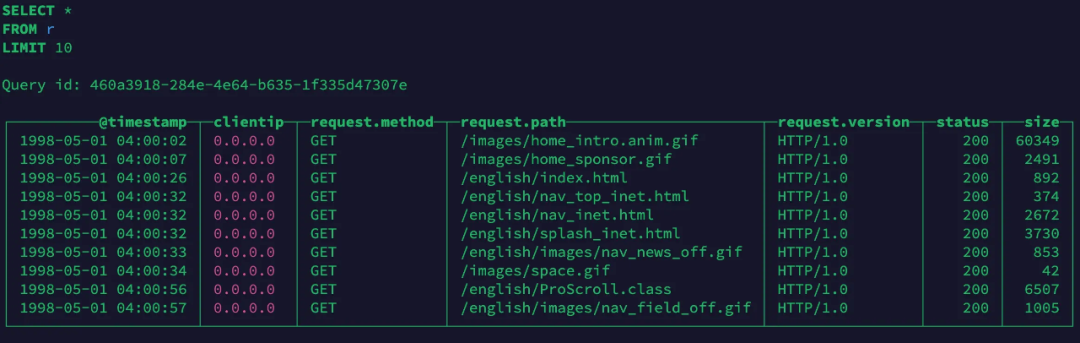
After the data is written into the engine, use wildcards to query the nested structure inside the JSON:
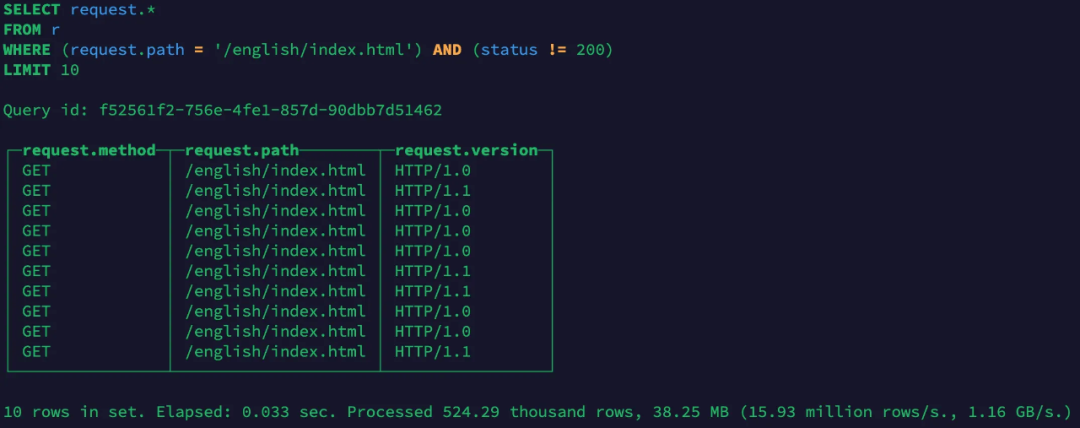
Of course, you can also directly use JSON internal fields for various queries:

The precomputing acceleration query mechanism inside ClickHouse can also be supported:
ALTER TABLE r
ADD PROJECTION p1
(
SELECT
request.path,
count()
GROUP BY request.path
)It can be seen that users can use ClickHouse to analyze and query unstructured data very conveniently.
performance
ClickHouse, a cloud data warehouse, has good performance in processing semi-structured data. In the customer's production link (in the log analysis scenario, the total data size is 300TB, the cluster size is 50 nodes, and the total number of cores is 1600) the performance comparison between the existing ClickHouse solution and the cloud data warehouse ClickHouse:
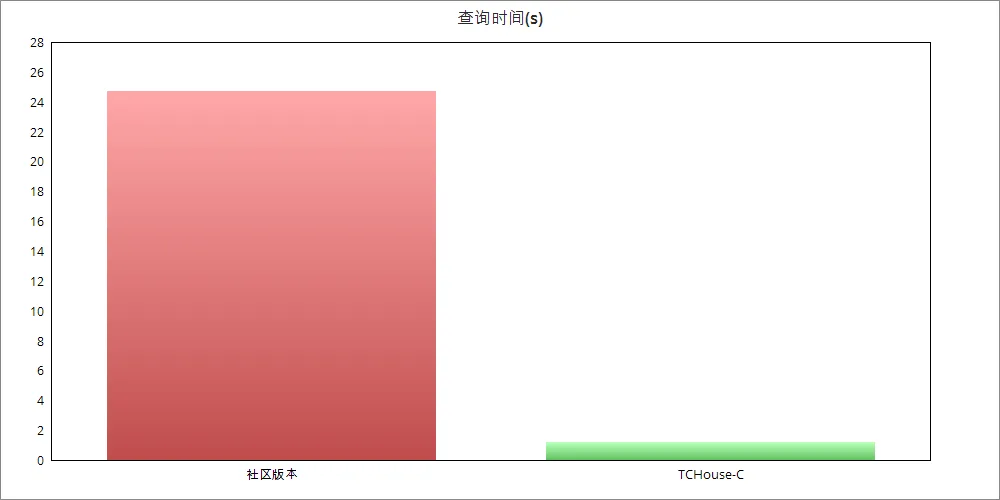
The reason for the performance improvement: store the frequently queried fields as ordinary columns, make full use of the performance advantages of vectorized computing, and perform secondary indexing and precomputing processing on them, thereby improving query performance.
Summarize
At present, ClickHouse, a cloud data warehouse, improves the real-time analysis performance of semi-structured data by 20 times in log retrieval and APM scenarios. It saves a lot of hardware costs for public cloud customers and returns query results in seconds.