A Comprehensive Guide to Hyperparameter Optimization with GridSearchCV
Overview of hyperparameter tuning
Hyper parameters are parameters set before the learning process of the learning machine, and will not be directly learned from the data during the learning process of model training. Unlike model parameters, which are not learned from data, hyperparameters are determined by data scientists or machine learning experts based on their knowledge and intuition.
The significance of hyperparameter tuning on model performance: Proper selection of hyperparameters can improve the performance of machine learning models. By tuning hyperparameters, you can identify areas where you can improve accuracy, precision, or other performance measures, thereby improving speed and modeling precision. Well-tuned models are more robust and stable because they are less sensitive to small changes in the input and small changes in the training set.
Introduction to Grid Search Resume
GridSearchCV (Cross Validation) is a hyperparameter optimization technique used to search for the best combination of hyperparameter values for a machine learning model. It is part of the sci-kit-learn library in Python and is widely used for hyperparameter optimization.
Example of using GridsearchCV on a decision tree:
Without using GridsearchCV:
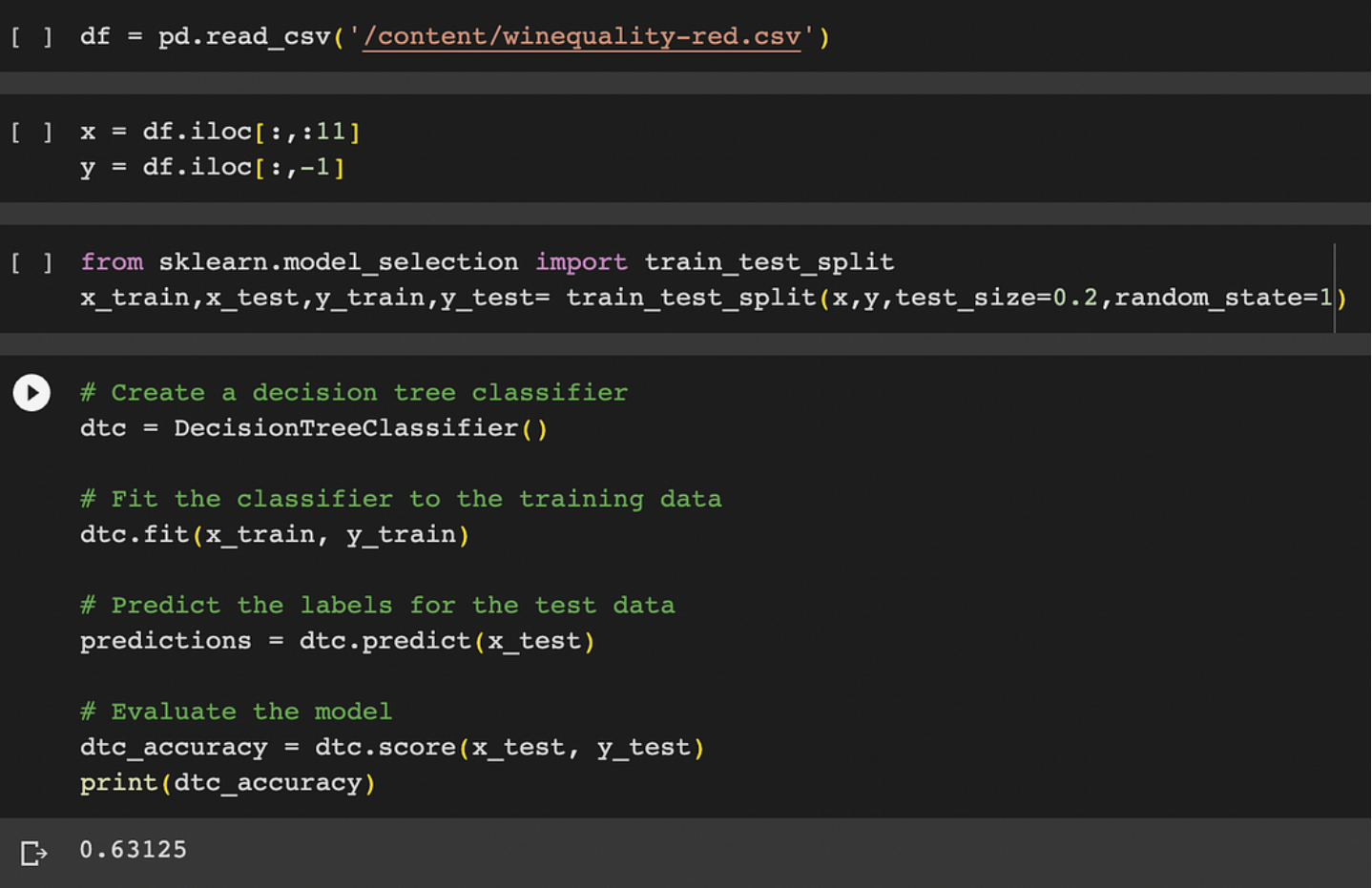
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test= train_test_split(x,y,test_size=0.2,random_state=1)
#decision tree classifier
dtc = DecisionTreeClassifier()
# Fit the classifier to the training data
dtc.fit(x_train, y_train)
# Predict the labels for the test data
predictions = dtc.predict(x_test)
# Evaluate the model
dtc_accuracy = dtc.score(x_test, y_test)
print(dtc_accuracy)After using GridSearchCV:
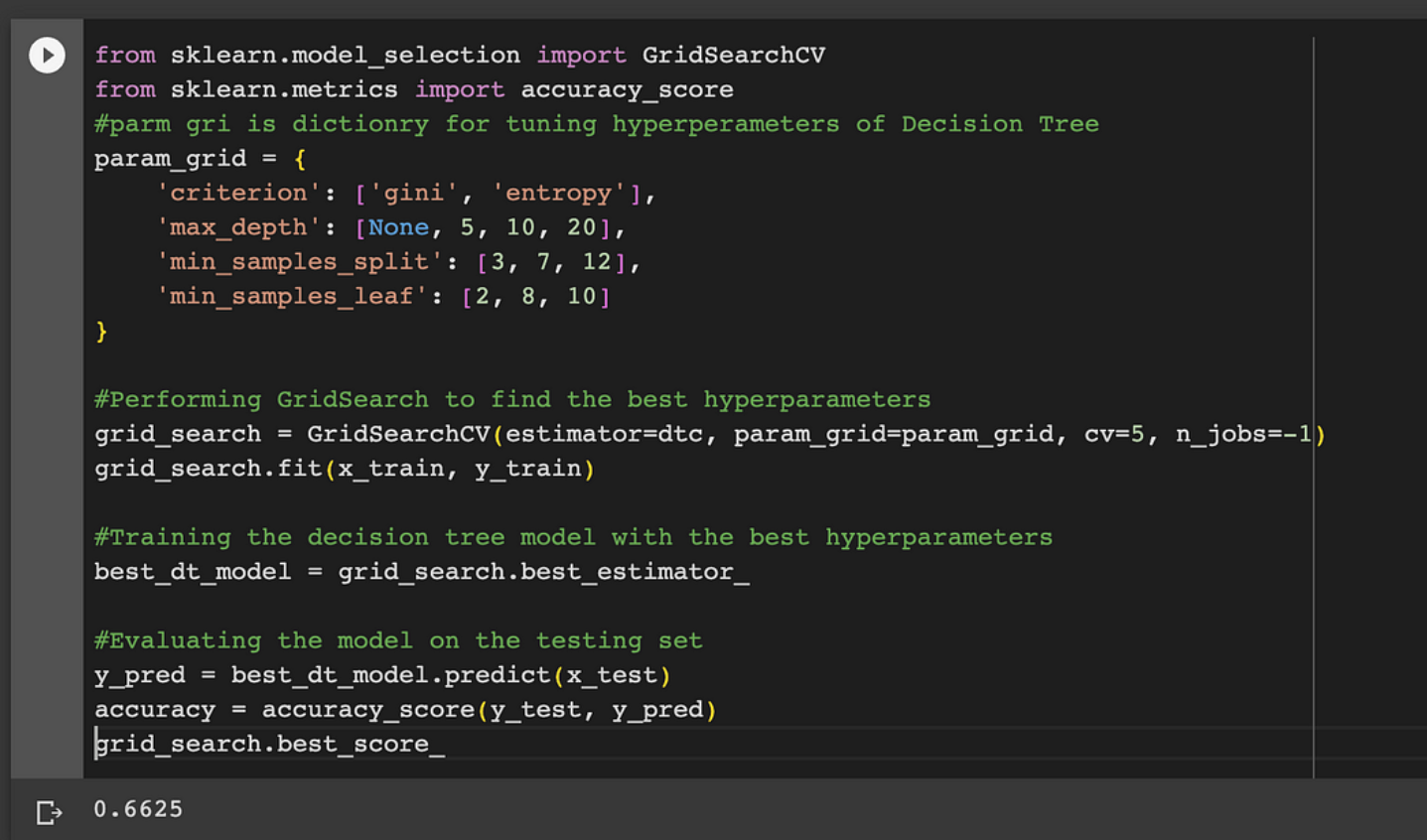
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score
#parm grid is dictionry for tuning hyperperameters of Decision Tree
param_grid = {
'criterion': ['gini', 'entropy'],
'max_depth': [None, 5, 10, 20],
'min_samples_split': [3, 7, 12],
'min_samples_leaf': [2, 8, 10]
}
#Performing GridSearch to find the best hyperparameters
grid_search = GridSearchCV(estimator=dtc, param_grid=param_grid, cv=5, n_jobs=-1)
grid_search.fit(x_train, y_train)
#Training the decision tree model with the best hyperparameters
best_dt_model = grid_search.best_estimator_
#Evaluating the model on the testing set
y_pred = best_dt_model.predict(x_test)
accuracy = accuracy_score(y_test, y_pred)
grid_search.best_score_Random Search CV: There are some special cases where grid searcCV or RandomgridSearcgCV are not suitable, these cases are:
When the data is restricted to use grid search in an efficient manner, there should be an appropriate amount of data, since gridsearchCV uses K-fold cross-validation. In such cases, more advanced techniques such as Bayesian optimization can be used as an alternative to efficiently search the space of hyperparameters. This situation is: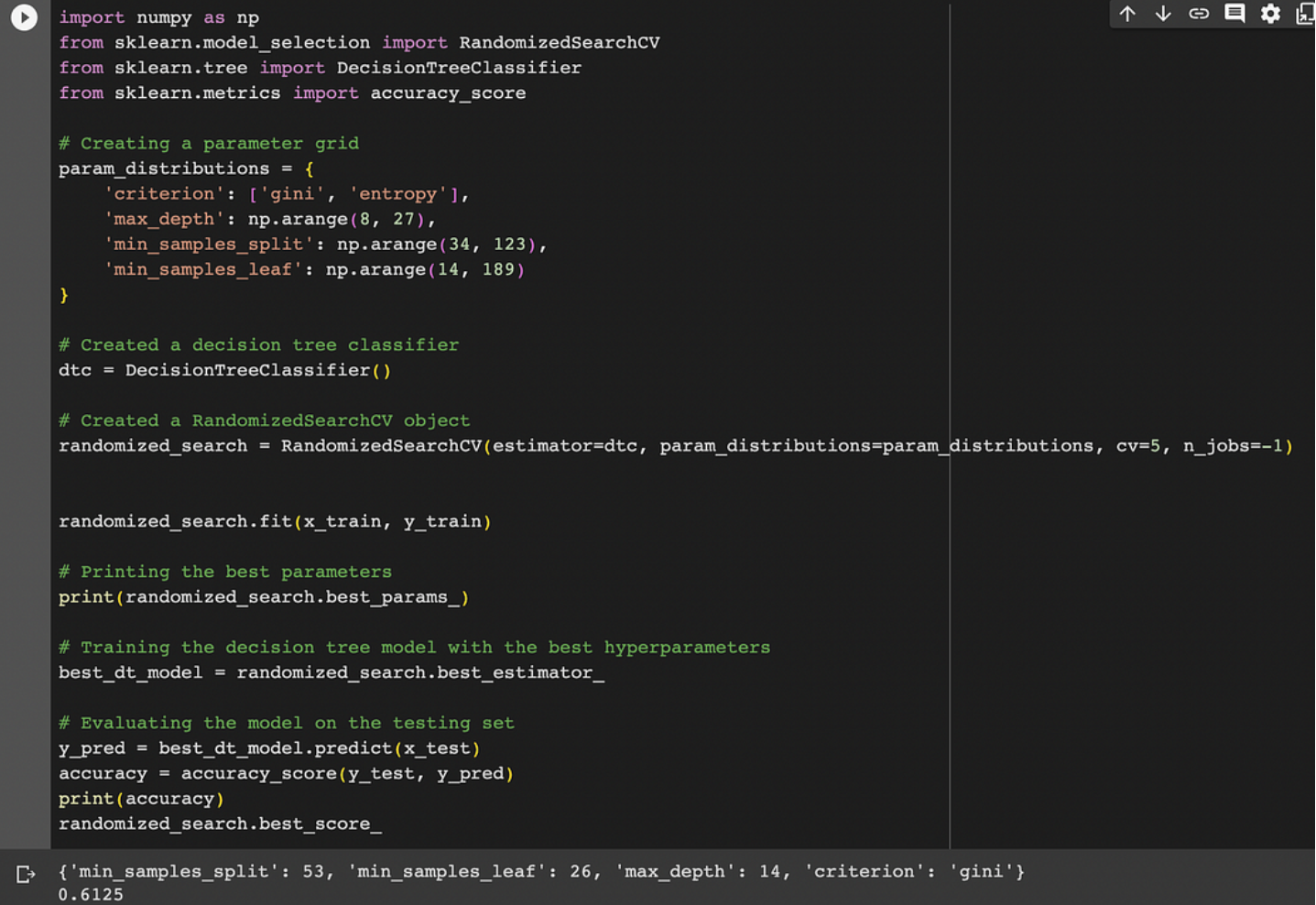
import numpy as np
from sklearn.model_selection import RandomizedSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# Creating a parameter grid
param_distributions = {
'criterion': ['gini', 'entropy'],
'max_depth': np.arange(8, 27),
'min_samples_split': np.arange(34, 123),
'min_samples_leaf': np.arange(14, 189)
}
# Created a decision tree classifier
dtc = DecisionTreeClassifier()
# Created a RandomizedSearchCV object
randomized_search = RandomizedSearchCV(estimator=dtc, param_distributions=param_distributions, cv=5, n_jobs=-1)
randomized_search.fit(x_train, y_train)
# Printing the best parameters
print(randomized_search.best_params_)
# Training the decision tree model with the best hyperparameters
best_dt_model = randomized_search.best_estimator_
# Evaluating the model on the testing set
y_pred = best_dt_model.predict(x_test)
accuracy = accuracy_score(y_test, y_pred)
print(accuracy)
randomized_search.best_score_Learn about grid search CV:
Use the GridSearchCV() method, available in the scikit-learn class model_selection. It can be started by creating an object of GridSearchCV() which takes 4 parameter estimators, param_grid, cv and n-jobs. These parameters are explained as follows: 1. estimator — a scikit-learn model 2. param_grid -: a dictionary containing parameter names and a list of parameter values. 3. Scoring: Performance measures. For example, "dtc" indicates a decision tree model, and "precision" indicates a classification model. 4. cv : It stands for many k-fold cross-validation.
Grid search CV works:
It works efficiently by searching a network of possible hyperparameter values and evaluating the model function for each hyperparameter combination. The final model is then trained with hyperparameters that make the model perform well.
After testing all possible pairs of hyperparameters and evaluating their performance, GridSearchCV selects the combination of hyperparameters that provides the best performance based on the evaluation criteria.
Determine the best hyperparameters, and GridSearchCV will use the entire training dataset to retrain the model, this time with the best hyperparameters.
Finally, the model with the best hyperparameters is tested on unseen test data to predict its performance on new, unseen data.
in conclusion:
The main advantage of using GridSearchCV is that it automates the hyperparameter optimization process and saves you from trying many connections manually. It increases the risk of finding optimal or near-optimal hyperparameters for a model by exploring the hyperparameter space to improve performance on new data.
GridSearchCV can be computationally expensive, especially if you have large datasets or complex multivariate models. In this case, it is better to consider RandomizedSearchCV, which explores different hyperparameter domains and provides a good trade-off between performance and budget.
However, in some cases other hyper-permeability techniques are more useful, for example when data is limited, Bayesian optimization can be used as an alternative to efficiently search the hyperparameter space.