Preface: This article has a lot of content (1w words), not only contains theoretical knowledge, but also has a comprehensive practice. This article gives a rough explanation of the theoretical content of the first three chapters. It is recommended to go to station b to watch the chapters related to virtual storage in the operating system of Harbin Institute of Technology and Wang Daoyan, and then it will be easy to design and implement.
The blogger wrote this article mainly to implement the CacheSim simulator, the purpose is to enrich the CPU simulator, to study the meltdown vulnerability caused by the cpu out-of-order execution mechanism and the rollback mechanism.
Article Directory
- I. Overview
- 2. Cache - address mapping of main memory
- 3. Replacement Algorithm
- 4. Design
- Five, detailed implementation
-
- 5.1 Program entry
- 5.2 Initialization
- 5.3 load_trace load trace file function
- 5.4 check_cache_hit Check whether the cache is hit
- 5.5 Actions after a hit
- 5.6 Actions after a miss
- 5.7 get_cache_free_line to get the currently available line function
- 5.8 set_cache_line writes the data in the cache line back to the memory function
I. Overview
1.1 Introduction
In a computer system, a CPU cache (English: CPU Cache, referred to as a cache in this article) is a component used to reduce the average time required for a processor to access memory. In the pyramid storage system, it is located at the second level from top to bottom, second only to CPU registers. Its capacity is much smaller than memory, but its speed can approach the frequency of the processor. When the processor issues a memory access request, it first checks whether there is requested data in the cache. If it exists (hit), the data is returned directly without accessing the memory; if it does not exist (failure), the corresponding data in the memory must be loaded into the cache first, and then returned to the processor. The reason why the cache is effective is mainly because of the locality (Locality) characteristic of memory access when the program is running. This locality includes both spatial locality and temporal locality. Using this locality effectively, caches can achieve extremely high hit rates. From the processor's point of view, the cache is a transparent component. Therefore, programmers usually cannot directly intervene in the operation of the cache. However, it is true that specific optimizations can be made to the program code based on the characteristics of the cache to make better use of the cache.
1.2 The relationship between cache and main memory
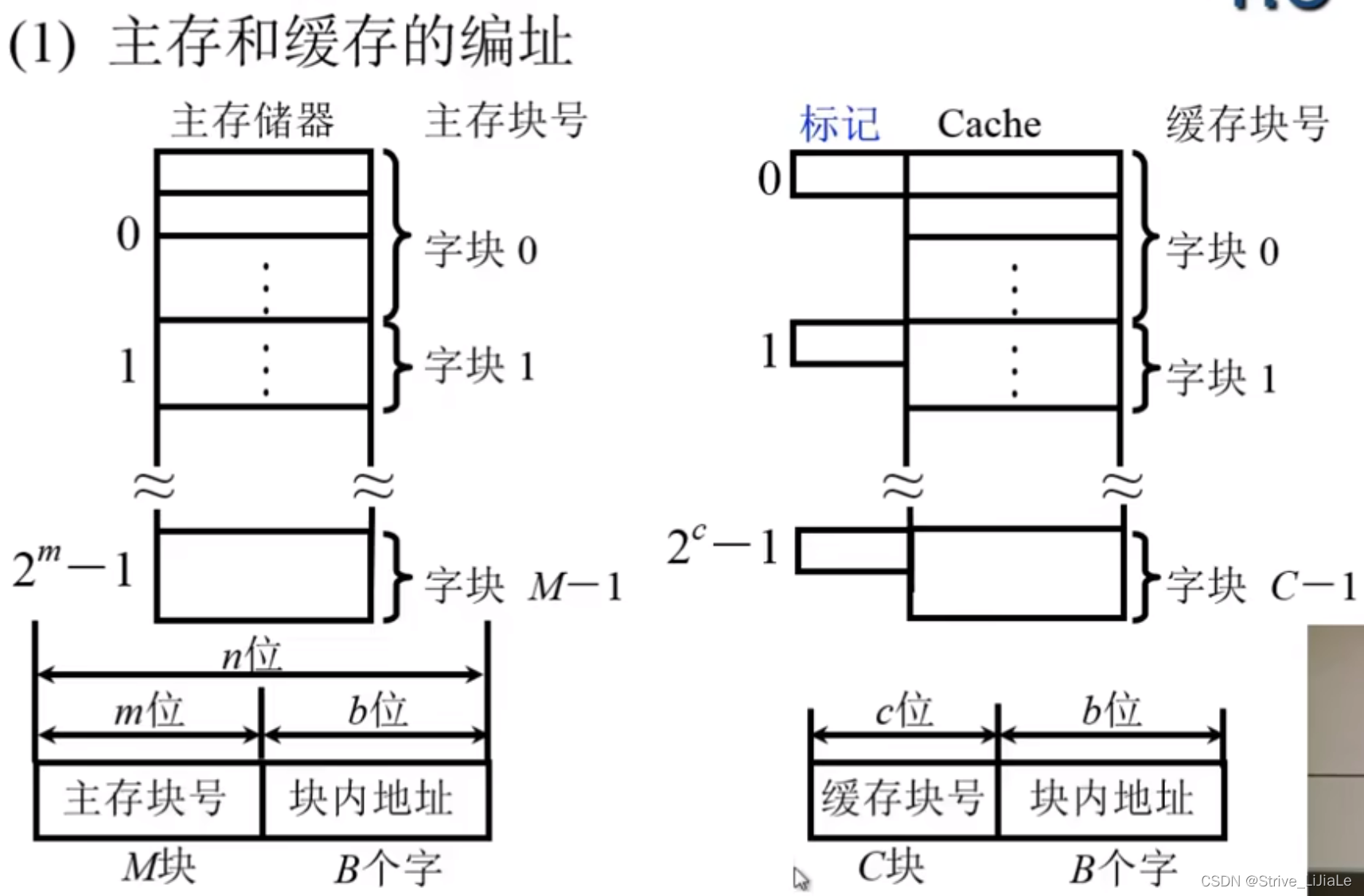
A block contains 16 bytes, and the organization unit of memory is byte, then the address in the block is 4 bits, and the remaining part is the serial number of the storage block.
1. Why is there no need to calculate the cache address?
Since the size of the main memory block and the cache block are the same, the number of address bits in the block is exactly the same. When a certain block is transferred between the memory and the cache, it is carried out as a whole, and there is no change in the block. The address part of the two block, the value is exactly the same.
2. What is the mark on the cache to mark?
The corresponding relationship between the main memory block and the cache block is marked. If the block in the main memory is transferred to the cache, the main memory block number can be written into this tag. When receiving the memory access address given by the cpu, it can be determined whether it is in the cache, and the address in the Just compare the block number with the tag. If they are equal and the cache block is valid, you can directly get the information from the cache.
3. The relationship between the hit rate and the block length?
If the block is too small, the principle of locality will not be fully used; if the block is too large, the number of blocks will be too small. If only a small part of the information in the block is
useful for the CPU, other information will not be used. , will also affect the hit rate.
1.3 Basic structure of Cache
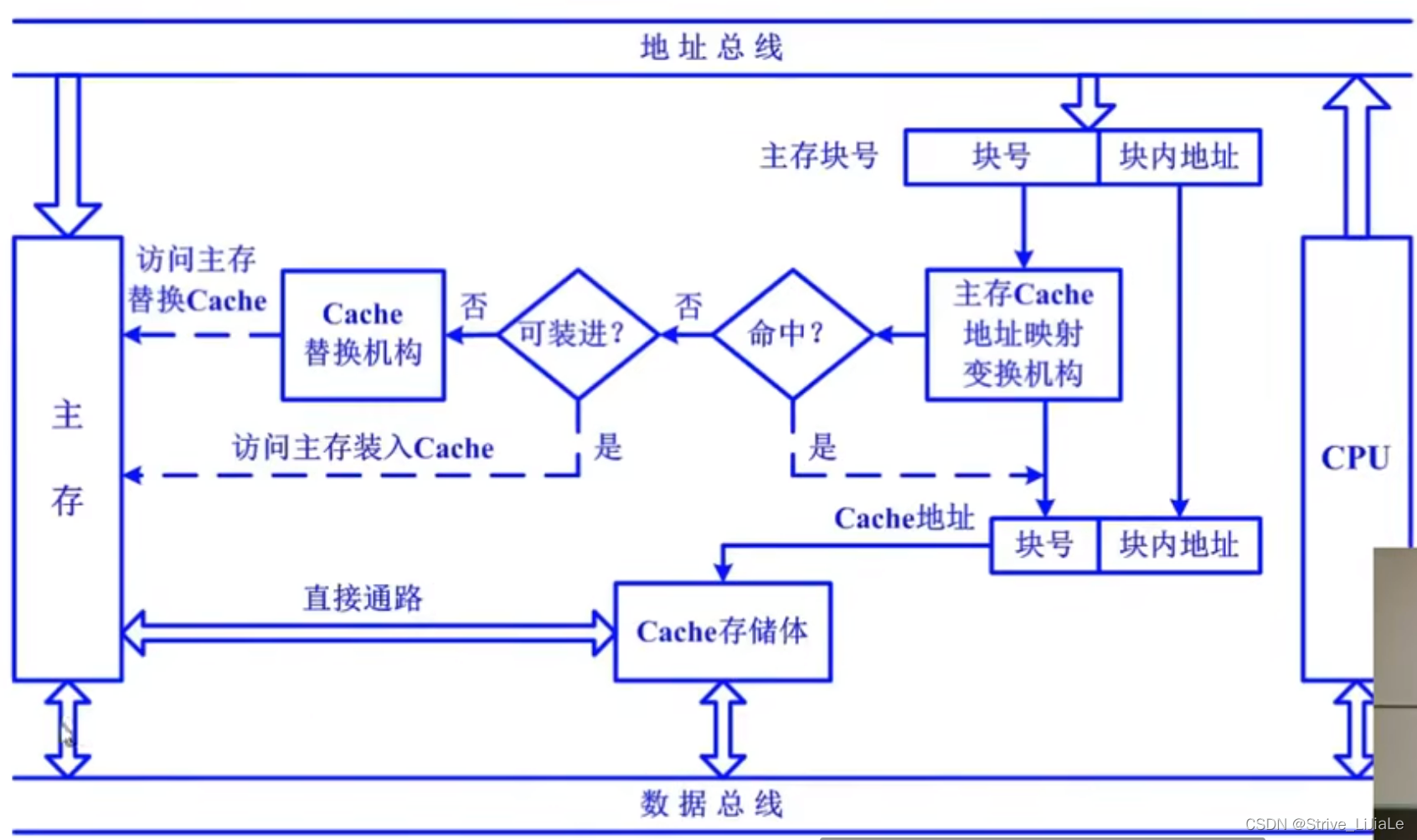
1. Address mapping (storage: loading):
map, a block in the main memory, if it is to be placed in the cache, which block or blocks of the cache it can be placed in, this is the mapping rule.
2. Transform structure (take: search):
Convert the block number of the main memory to the corresponding block number of the cache, or convert the address of the main memory to the address of the cache, and find the corresponding main memory block in the cache for access .
3. Replacement Algorithm
1.4 Cache read operation
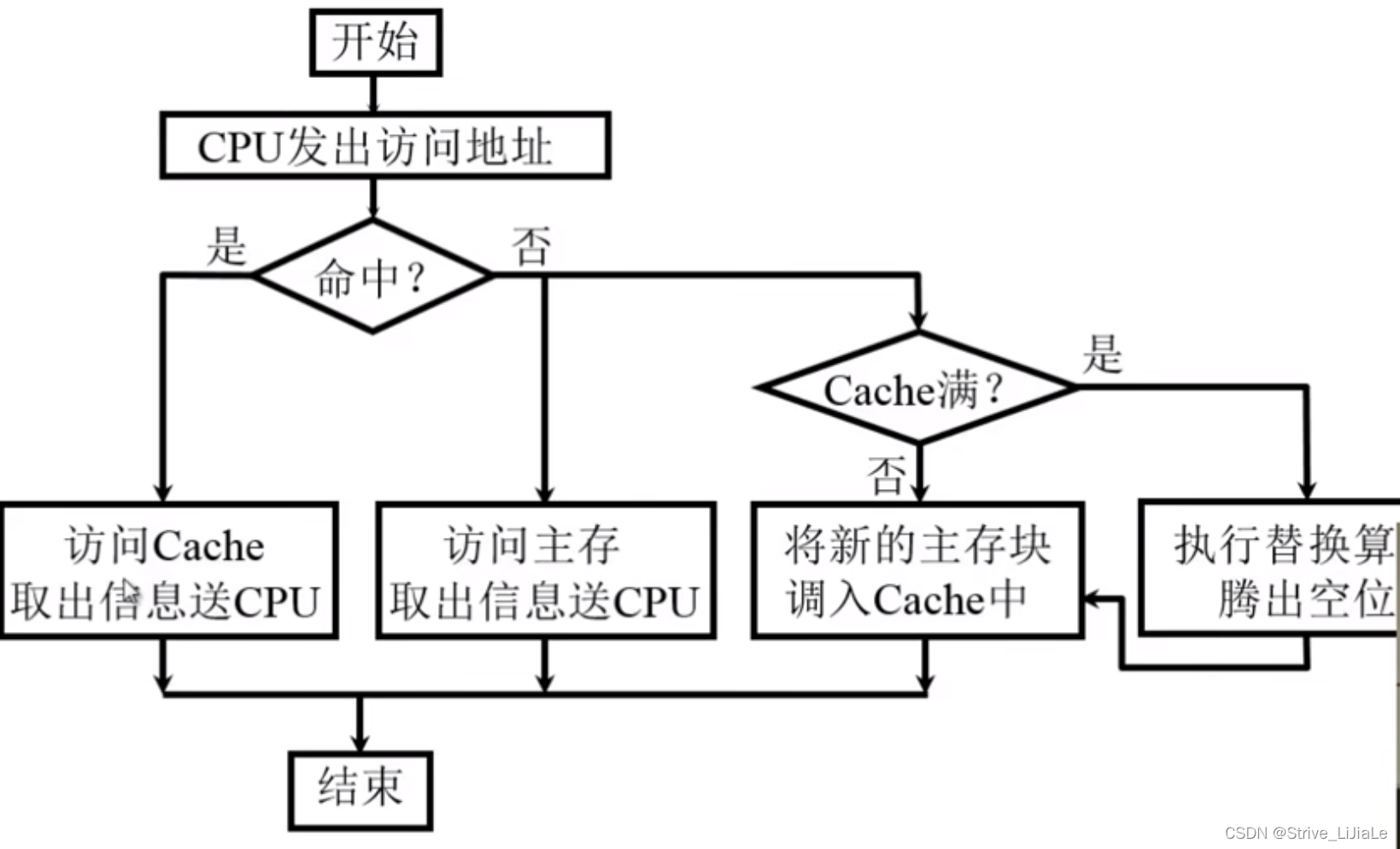
1.5 Cache write operation
Consistency issues between Cache and main memory:
- Direct write method: the time
when data is written to both the main memory and the cache during the write operation is the time to access the main memory . When the cache block exits, there is no need to perform a write operation to the main memory. The update strategy is relatively easy to implement, but for the accumulation and summation programs that require repeated memory access - Write-back method
Only write data into the cache and not into the main memory during the write operation.
When the Cache data is replaced, it is written back to the main memory
, but the consistency cannot be maintained (parallel computer system)
1.6 Cache improvement
(1) Increase the number of stages,
on-chip cache,
off-chip cache
(2) Unified cache and separate
cache, instruction cache
, data cache
(related to the control method of instruction execution: whether it is pipelined)
2. Cache - address mapping of main memory
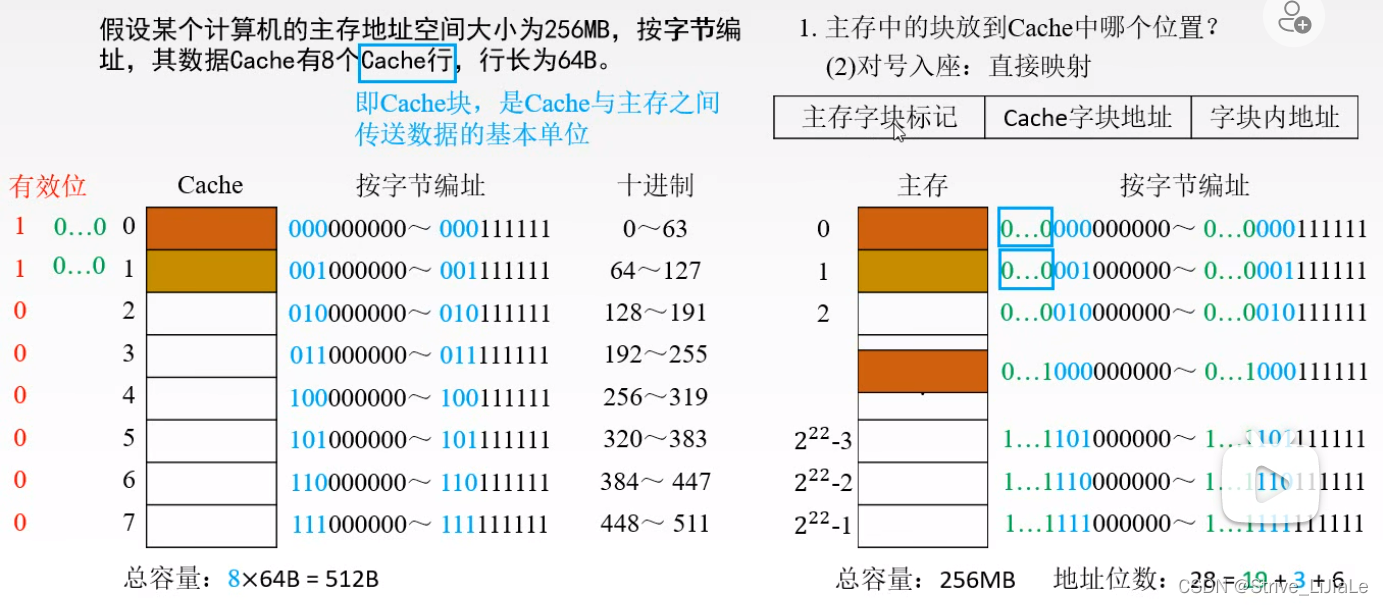
2.1, direct mapping
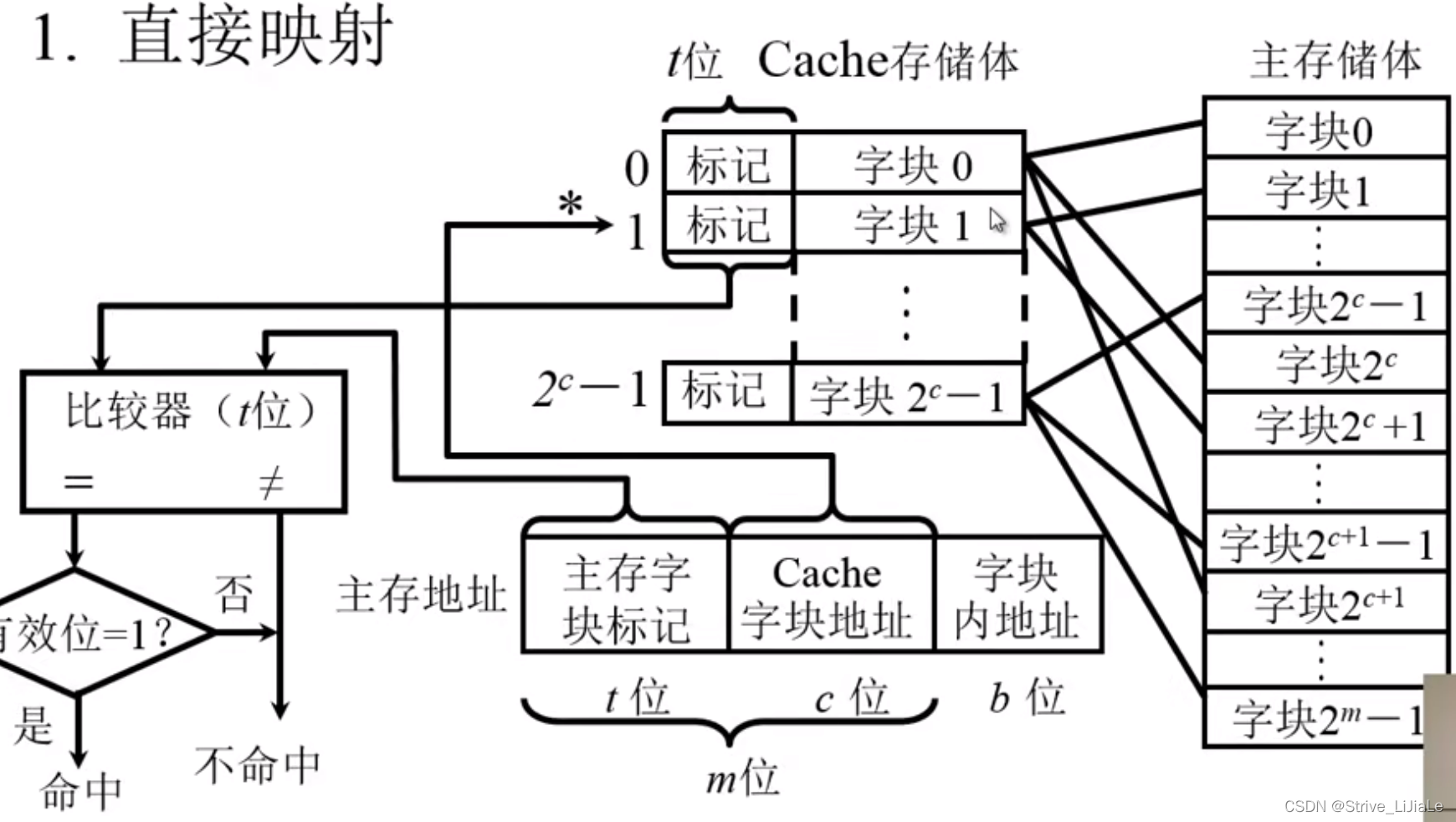
Definition: A specified block in the main memory can only be mapped to or loaded into a specified Cache block, and the first block of any area can only be placed in block 0 of the Cache bank. Right now
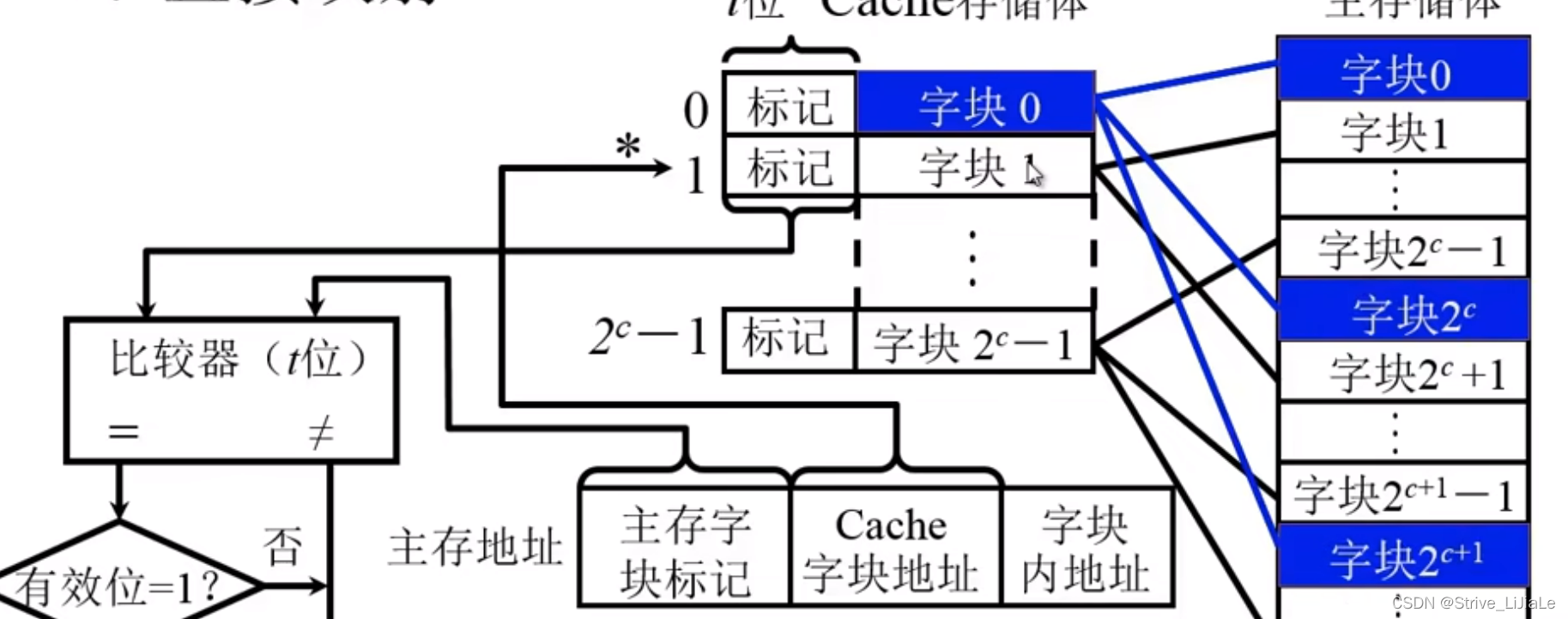
If the cpu gives an address, divide it into three parts: area code | block number | block offset address
area code: main memory word block mark (same t digits as "mark")
block number: Cache word block address
offset Shift address: the address in the block
Since block 0 (the zeroth block) in the cache may load the first block of any area in the main memory, which area is the zeroth block in? It is necessary to write the area code into the "tag" of the Cache storage body. That is, "mark" to record the area code of the main memory.
According to the address of the Cache word block, the block number can be found from the Cache. As for whether this block is the specified block in the specified area to be found, it is necessary to match the area code given by the address with the current area code in Cashe (Mark) to compare.
Disadvantage: When the content of the cth power of the main memory 2 needs to be used for the second time, the content needs to be replaced by the zeroth block and the following blocks of the Cache, because the rule of direct mapping is that the first block of a certain area can only be placed In the zeroth block of the cache.
Each cache block i can correspond to several main memory blocks
, but each main memory block j can only correspond to one cache block
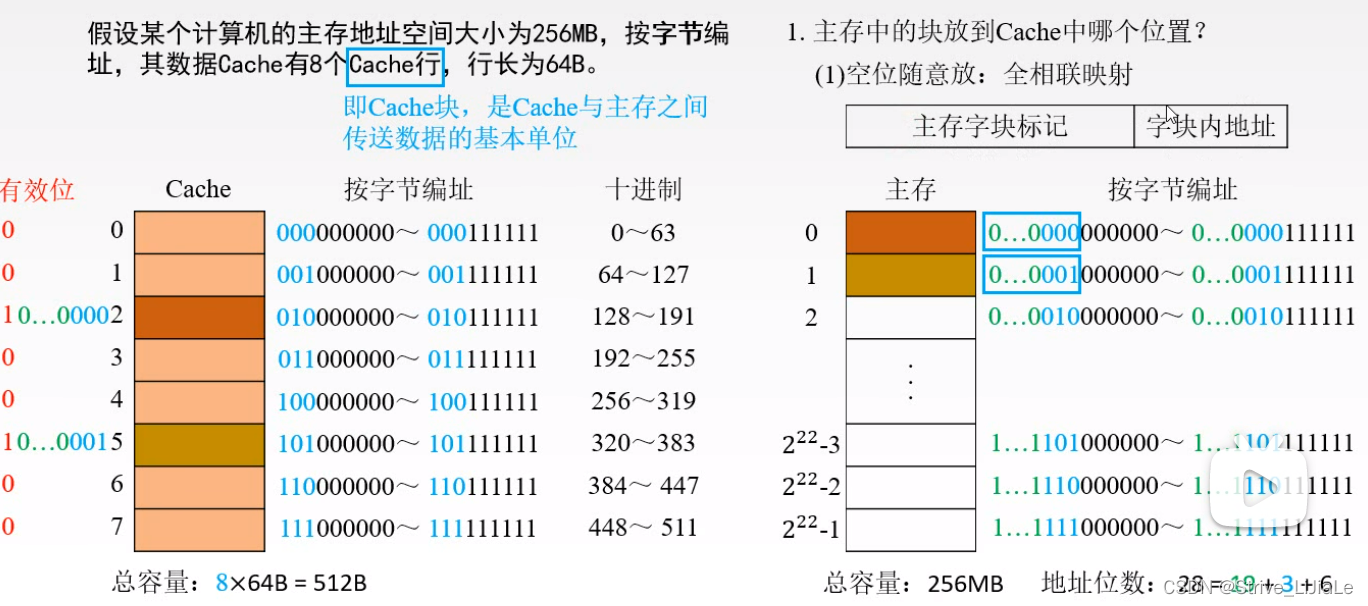
2.2, fully associative mapping
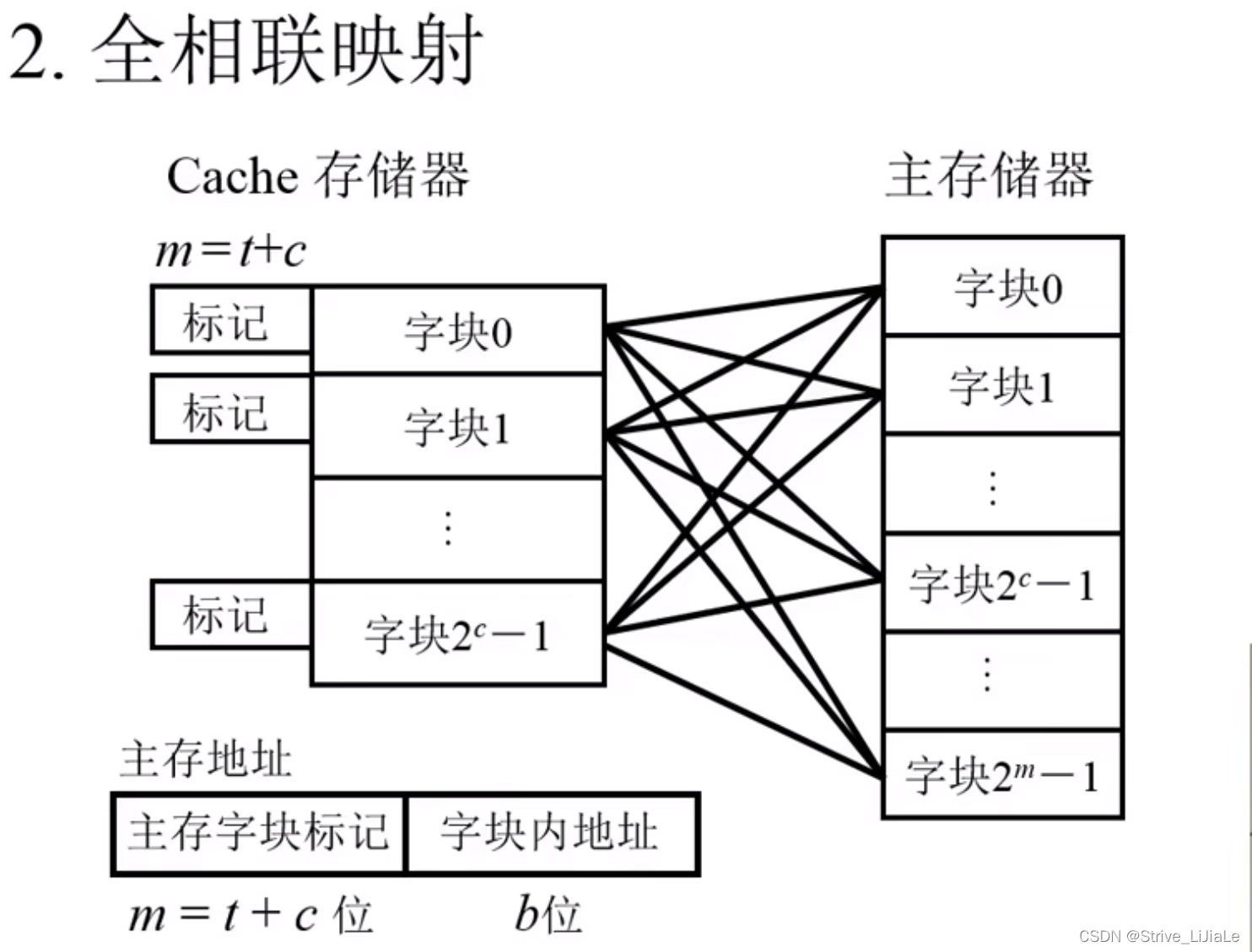
Any block in the main memory can be placed in any block in the Cache. As long as there is a free block in the Cache, the main memory block can be transferred in, which improves the Cache utilization. But if a block in the main memory is transferred into the Cache, it may be in any block of the Cache, so it is necessary to compare the main memory block number tag of the main memory address with the tags of all blocks in the Cache (direct mapping is direct mapping). Find a block from the Cache, and then only need one comparison, that is, compare the block number mark of the main memory with the mark of the block in the Cache), and the length of the comparator will also be longer (t+c).
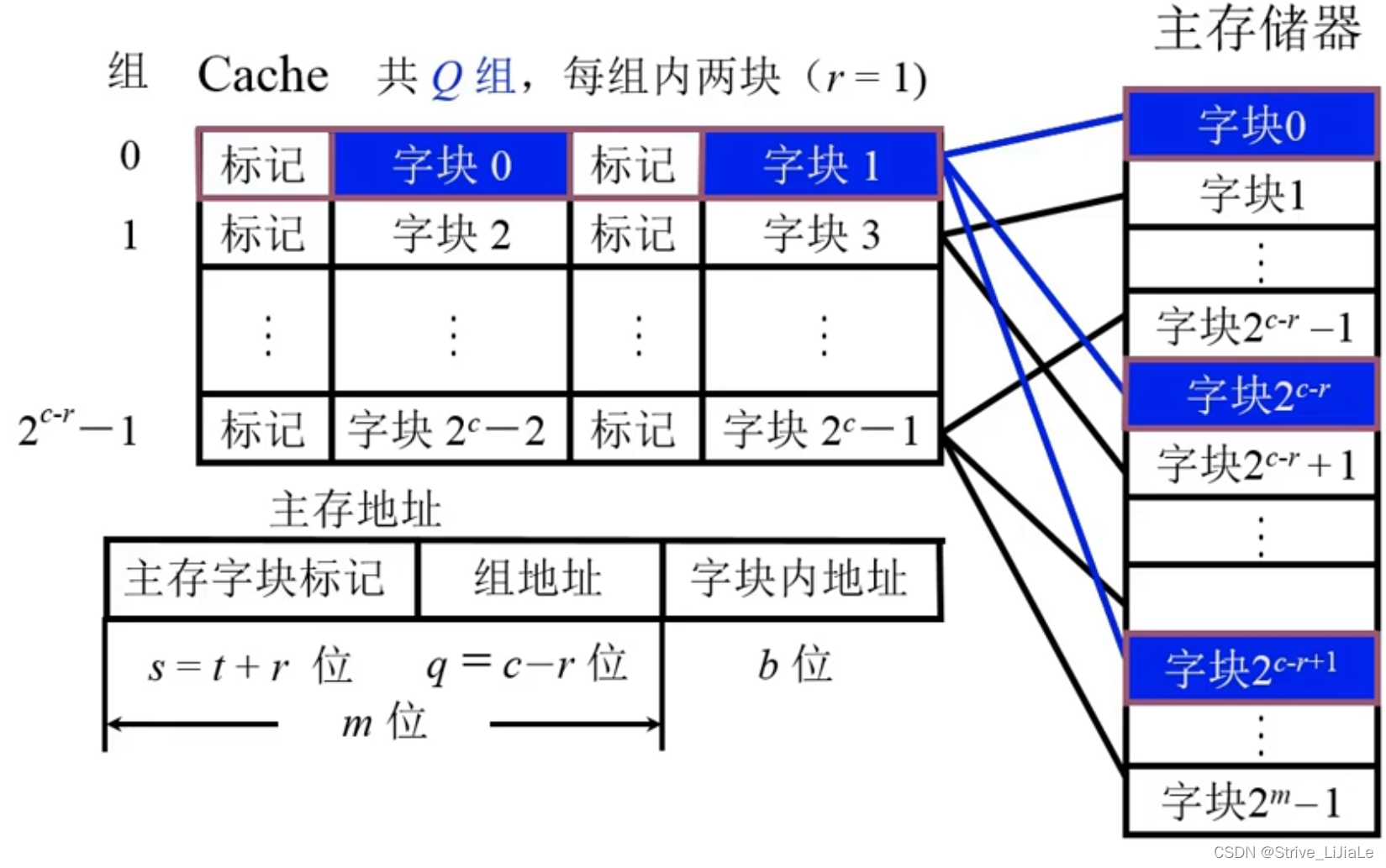
2.3, group associative mapping
A compromise solution: neither random placement nor designated placement, but random placement at designated locations.
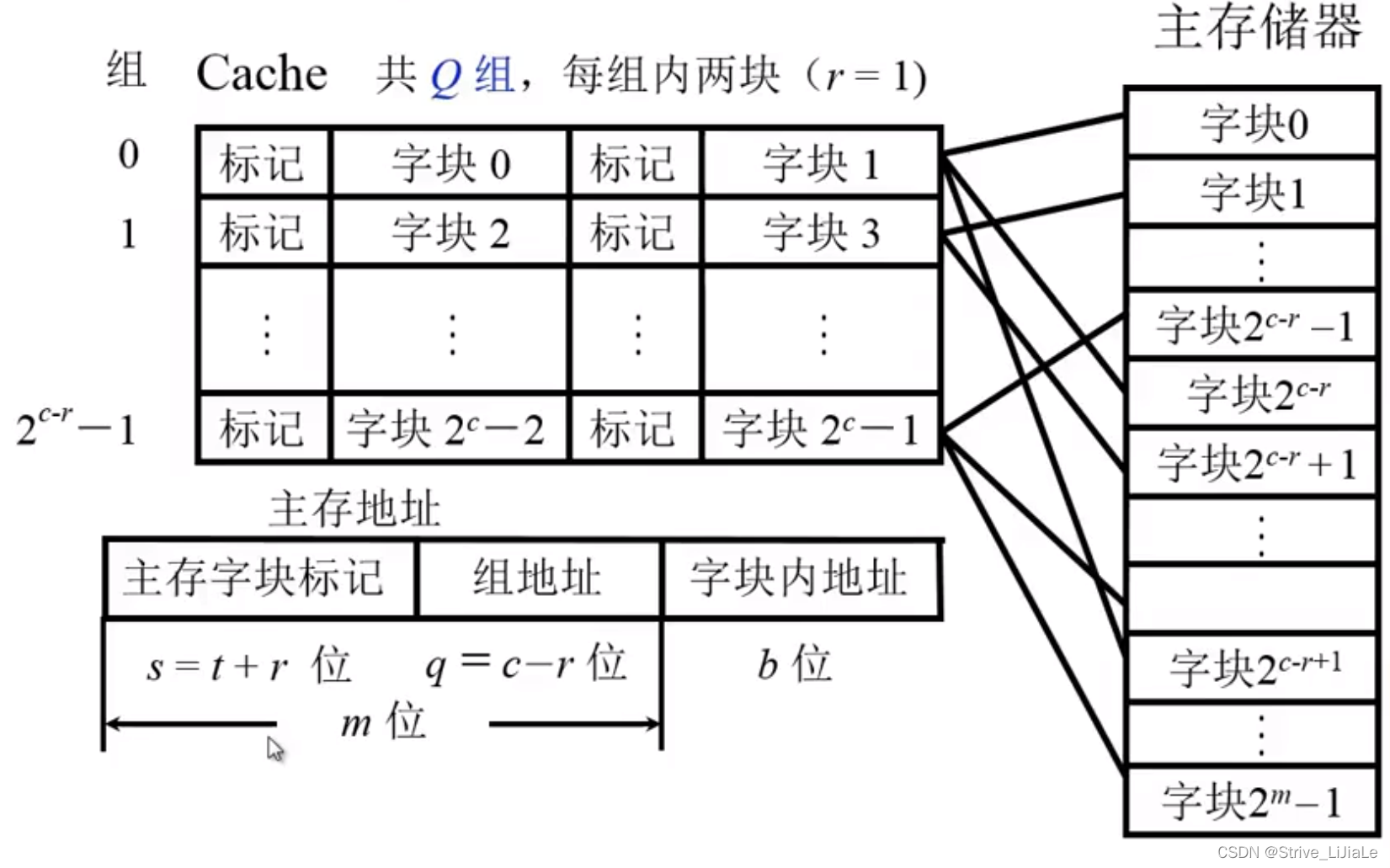
1. First divide the Cache into blocks, and these blocks are then divided into several groups.
Each set contains two pieces.
2. Then divide the main memory into blocks, and these blocks are divided into areas,The size of each area is the same as the number of groups in the Cache (the number of blocks in each area = the number of groups).
The zeroth block of the main memory can be placed anywhere in the zeroth group of the Cache (the characteristic of full association), and the area code specifies the corresponding mark (the characteristic of direct mapping).
This ensures that the blocks in the same area can be transferred as long as there is a position in the corresponding group (full associative feature).
When you need to check whether it already exists in the Cache, you only need to give the area number and the block number in the area, and after giving the block label (j), you can find (map Q) the given group (i), and the given The marks of several blocks in the group can be compared with the area code, and there is no need to compare with each Cache block (direct mapping feature).
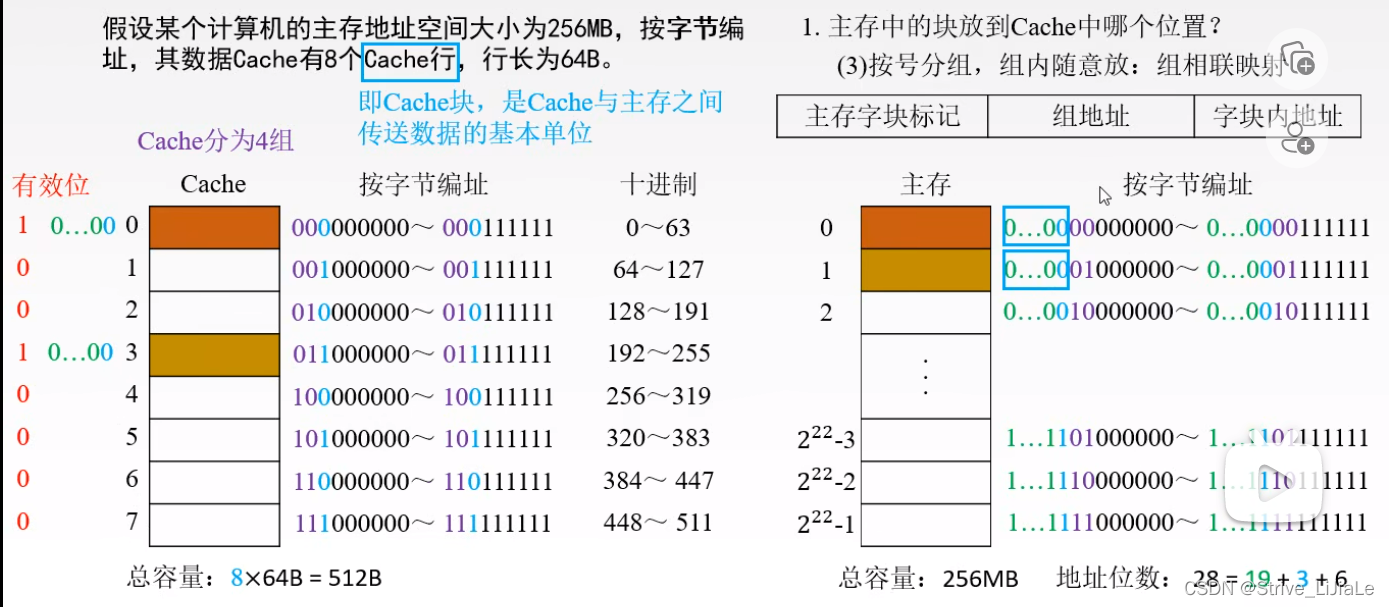
3. Replacement Algorithm
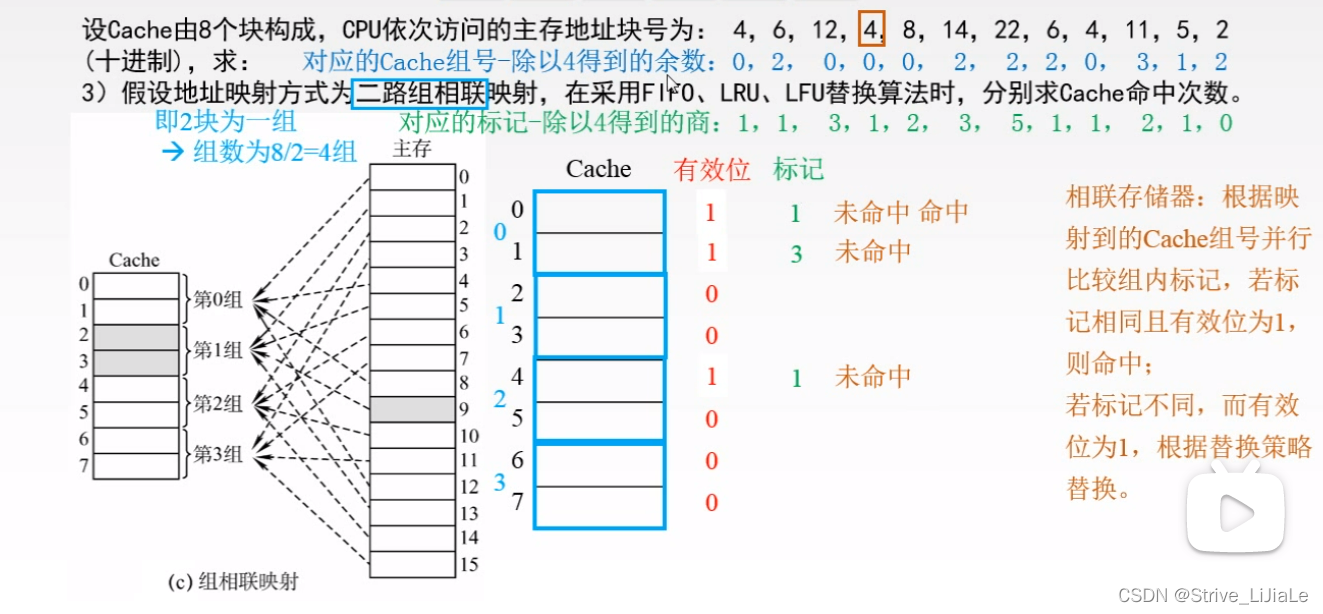
4. Design
4.1 Design process
- 1 command read
Since the main memory access trace is given in the form of a file, the trace file download needs to read the memory access trace from the file. The format of the trace is as follows:
s 0x1fffff50 1
The first character of each line is the type of the instruction, s is write (store), r is read (read). The middle hexadecimal number is the memory address, and the last integer refers to the number of interval instructions between memory access instructions. For example, the 5th instruction and the 10th instruction are memory access instructions, and there is no other memory access instruction in between, then the number of interval instructions is 4. The use of the last parameter is not considered in the simulator we wrote.
- 2 Analyze an instruction
After reading an instruction from the trace file, analyze the instruction, transform the address, check whether the data in the address is in the cache, and obtain the result of hit or not.
- 3 Check for a hit
Check for a hit by operating on the address
- 4 Find a free line
If it is a read hit, you only need to update the timestamp, if it is a write operation, mark the dirty bit. If there is no hit before, you need to find a block that can be used from the current Cache, giving priority to the line that is currently in the invalid state. Otherwise, execute the replacement algorithm to find the block that needs to be replaced. At the same time, if the original data in the block to be replaced is dirty , written back to memory.
- 5 Load data into the cache line
If miss, find the cache line where the data can be placed through 1.4, and the next step is to load the data from the main memory to the cache line.
4.2 Document writing
4.2.1 Cache_line class
Cache_Line is a separate class, and the tag uses unsigned 32 bits
class Cache_Line {
public:
_u32 tag;
/**计数,FIFO里记录最一开始的访问时间,LRU里记录上一次访问的时间*/
union {
_u32 count;
_u32 lru_count;
_u32 fifo_count;
};
_u8 flag;
_u8 *buf;
};
The count is used to record the access time and adopts the union data structure. When updating the count later, it only needs to perform special assignments for different replacement algorithms, and it will not lead to the confusion of thinking when using the count all the time. The change of this value will be explained later in the replacement algorithm. The original intention of buf is to store data in the memory, refer to the bank in the structure description in the previous chapter. Flag is the storage of some flag bits:
| number of digits | 7~3 | 2 | 1 | 0 |
|---|---|---|---|---|
| effect | reserve | Locking bit | dirty bit | Significant bit |
4.2.2 Variables
| variable | significance |
|---|---|
| cache_size | The total cache size, unit byte |
| cache_line_size | The size of a cache line, unit byte |
| cache_line_num | How many lines does the cache have in total? |
| cache_mapping_ways | group associative |
| cache_set_size | How many groups (set) the entire cache has |
| cache_set_shifts | The number of bits in the memory address division, log2(cache_set_size) |
| cache_line_shifts | The number of bits in the memory address division, log2(cache_line_num) |
| caches | real cache array |
| tick_count | instruction counter |
| cache_buf | cache bank, where memory data is stored |
| cache_free_num | The current number of free cache lines |
| cache_r_count, cache_w_count | The total amount of data read and written by the cache |
| cache_hit_count, cache_miss_count | hit and miss counts |
| swap_style | replacement algorithm |
4.2.3 Functions
| function | Function |
|---|---|
| check_cache_hit | check for a hit |
| get_cache_free_line | Get the current free cache line, if there is no free one, execute the replacement algorithm, and return a block that can be replaced |
| set_cache_line | Load the data in memory to the cache line obtained by get_cache_free_line |
| do_cache_op | Analyze an instruction |
| load_trace | Load the trace file and start the analysis |
| set_swap_style | Set the cache replacement algorithm for this time |
4.2.4 Constants
const unsigned char CACHE_FLAG_VAILD = 0x01; //有效位
const unsigned char CACHE_FLAG_DIRTY = 0x02; //脏位
const unsigned char CACHE_FLAG_LOCK = 0x04; //Lock位
const unsigned char CACHE_FLAG_MASK = 0xff; //初始化
Corresponding to the first table in this article, the lock bit is reserved for later cache locking. Later, the project will be modified to achieve this function. CACHE_FLAG_MASK is mainly used to initialize the flag when writing to the cache line. Others use the & operation with the flag in the cache line to determine whether it is valid or dirty.
Five, detailed implementation
5.1 Program entry
main.cpp is mainly for a test file, configured with different cache line sizes, different group associative ways, and different replacement strategies. The writeback method is used by default. The default cache size is 32KB (0x8000 Bytes). In each cycle, first initialize the cache configuration, then set the replacement strategy, and finally read the trace file and start simulating the memory read and write process.
5.2 Initialization
In the constructor of the CacheSim class, it is mainly initialized according to the meaning of some variables in the previous chapter. The main thing is to pay attention to the two variables of shifts, and use the library function log2() to calculate the number of digits. The cache line is actually stored in the caches variable, and memset is filled with 0, so the flag of the cache line is also filled with 0 by default. Pay attention to remember the release of caches and cache_buf in the destructor.
5.3 load_trace load trace file function
fgetsRead the file into the buf character array through the function, and then sscanfformat and read a line of instructions from buf. Note that the format in the original file is the s 0x1fffff50 1format. We don’t consider the last parameter, so only the instruction type (store or read) is read. and memory address. Determine whether to read or write by judging style. Every time one is read (executed), ours tick_countis ++, and the counter used to record whether it is read or written is also ++ accordingly. rcount/wcountIt is to count the number of read and write instructions, cache_r_count/cache_w_countbut to count the number of data reads and writes performed by memory and cache. When a cache miss finds a replacement line, if the found line contains dirty data, it needs to be written back to the memory. At this time, data communication occurs, and data communication is also performed when data is loaded from the memory to the replacement line. After the trace file is processed, the result is printed. There are currently three main areas of focus:
- instruction count
- miss rate/hit rate
- Read and write data communication
5.4 check_cache_hit Check whether the cache is hit
do_cache_opanalyze an instruction
The incoming parameters are an address and a flag for reading or writing (s or r). For load and store instructions, there are only two cases: hit or miss. Then there are mainly three parts involved in the middle: checking whether it hits, the operation after the hit, and the operation after the miss.
int CacheSim::check_cache_hit(_u32 set_base, _u32 addr) {
/**循环查找当前set的所有way(line),通过tag匹配,查看当前地址是否在cache中*/
_u32 i;
for (i = 0; i < cache_mapping_ways; ++i) {
if ((caches[set_base + i].flag & CACHE_FLAG_VAILD) && (caches[set_base + i].tag == ((addr >> (cache_set_shifts + cache_line_shifts))))) {
return set_base + i;
}
}
return -1;
}
int CacheSim::check_cache_hit(_u32 set_base, _u32 addr)
There are two passed parameters for checking the hit, one is the base address of the set, and the other is the memory address in the current trace.
set = (addr >>cache_line_shifts) % cache_set_size;
set_base = set * cache_mapping_ways;
According to the area division of the address in the group associativity, we can obtain which set of the cache the current address is mapped to. (The number of digits occupied by the line is the offset address in the block, and the number of digits occupied by the set is the group index, so remove the digits occupied by the line, take the remaining high digits, that is, tag+set, directly take the remainder, or remove the digits occupied by the tag carry out modulus after high bit maybe)
The cache is treated as a one-dimensional array in the simulator, so it is also necessary to obtain the first address of the set. (Know the first group, then the first address = number of groups * size of the group)
The decision of whether to hit or not is based on the matching of the tag. If the tag of the current address addr is the same as a certain line tag in the mapping set in our cache, (caches[set_base + i].tag == ((addr >> (cache_set_shifts + cache_line_shifts))))and this line is valid (caches[set_base + i].flag & CACHE_FLAG_VAILD), then return this line in this one-dimensional array cache index(that is, which cache line/block number). If it is not found in the current set, it means that the data in this addr has not been loaded into the cache, and returns -1.
5.5 Actions after a hit
if (index >= 0) {
cache_hit_count++;
//只有在LRU的时候才更新时间戳,第一次设置时间戳是在被放入数据的时候。所以符合FIFO
if (CACHE_SWAP_LRU == swap_style)
caches[index].lru_count = tick_count;
//直接默认配置为写回法,即要替换或者数据脏了的时候才写回。
//命中了,如果是改数据,不直接写回,而是等下次,即没有命中,但是恰好匹配到了当前line的时候,这时的标记就起作用了,将数据写回内存
if (!is_read)
caches[index].flag |= CACHE_FLAG_DIRTY;
}
If it hits, everyone is happy, hit count ++, if the replacement algorithm is LRU, then update the timestamp (the things about the timestamp will be explained in detail later). If it is an operation to write memory, you need to set the hit cache line flag to dirty, because the instruction means to write data to this memory address, and there is a copy of data in the cache, because our default cache write method is Write back method (write back method, write back, that is, when writing the cache, it is not written into the main memory, and when the cache data is replaced, it is written back to the main memory), so here it is only marked as dirty data first, and the line is to be When replacing, write the data in the line back to the memory.
5.6 Actions after a miss
index = get_cache_free_line(set_base);
set_cache_line((_u32)index, addr);
if (is_read) {
cache_r_count++;
} else {
cache_w_count++;
}
cache_miss_count++;
If it misses, first obtain the available line (5.7) (maybe the current set is just not full and there is free, or it may be a replaceable line obtained through the replacement algorithm), and then write the data in the memory address of addr into the cache line , the corresponding number of read and write communications must also be ++, cache_r_count has been introduced in the load_trace function section in 5.3.
5.7 get_cache_free_line to get the currently available line function
_u32 CacheSim::get_cache_free_line(_u32 set_base)
Of course, the available line is found from the currently mapped set, and the index mapped to the set in the "one-dimensional array" cache is passed in.
for (i = 0; i < cache_mapping_ways; ++i) {
if (!(caches[set_base + i].flag & CACHE_FLAG_VAILD)) {
if (cache_free_num > 0)
cache_free_num--;
return set_base + i;
}
}
Loop through the current set once, and judge the valid bits in the flag bits. If there is an invalid cache line, it means that this line is "idle". Just return its index directly. If no one is found at the end of the loop, and the current cache set is full, then the replacement algorithm is executed:
free_index = 0;
if(CACHE_SWAP_RAND == swap_style){
free_index = rand() % cache_mapping_ways;
}else{
//FIFO
min_count = caches[set_base].count;
for (j = 1; j < cache_mapping_ways; ++j) {
if(caches[set_base + j].count < min_count ){
min_count = caches[set_base + j].count;
free_index = j;
}
}
}
if (CACHE_SWAP_LRU == swap_style)
caches[index].lru_count = tick_count;
The seed of the random replacement algorithm CacheSimis initialized in the constructor. For the FIFO (First in, first out) first-in-first-out replacement algorithm, the timestamp of the cache line records the time when the line is filled with data, that is, the time when it enters the "use queue", so FIFO finds the first entry The line of this queue, replace it. LRU (Least Recently Used) is the least recently used replacement algorithm. When the line is accessed, its timestamp needs to be updated. Therefore, in the function, do_cache_opwhen the cache hits, its timestamp needs to be updated.
The min_count obtained in FIFO is the line that enters the queue first, while in LRU, it is the line that has not been accessed for a long time in this queue.
If the original data in this line obtained by the replacement algorithm is dirty data, then mark its dirty bit
if (caches[free_index].flag & CACHE_FLAG_DIRTY) {
caches[free_index].flag &= ~CACHE_FLAG_DIRTY;
cache_w_count++;
}
5.8 set_cache_line writes the data in the cache line back to the memory function
void CacheSim::set_cache_line(_u32 index, _u32 addr) {
Cache_Line *line = caches + index;
// 这里每个line的buf和整个cache类的buf是重复的而且并没有填充内容。
line->buf = cache_buf + cache_line_size * index;
// 更新这个line的tag位
line->tag = addr >> (cache_set_shifts + cache_line_shifts );
line->flag = (_u8)~CACHE_FLAG_MASK;
line->flag |= CACHE_FLAG_VAILD;
line->count = tick_count;
}
The input is the index of the line to be written back in the "one-dimensional array" cache and the memory address to be written to the line. The buf here has no effect, it just means that the data in the memory is written into the current line, but in our cache simulator, there is no real data flow. To update the tag, just perform a shift operation on addr according to the content of the address division in Chapter 1. The flag is cleared first, if CACHE_FLAG_MASK = 0xff then ~CACHE_FLAG_MASK = 0x00, then the last valid bit is valid, and the timestamp is updated.
After completion, the code will be placed in the comment area