- 1. Characters that appear only once
- 2. Remove extra spaces
- Writing method one:
- Writing method two:
- 3. Information encryption
- 4. Word replacement
- Five, inverted word
- Six, the string shift contains the problem
- Seven, string power
- Eight, the maximum span of the string
- 9. The longest public string suffix
I have already completed part of the topic of strings. In the previous article, I thought this part should be regarded as the basic part, but in fact, I feel that there are many usages in strings that I am not very good at, so I am doing a special section.
1. Characters that appear only once
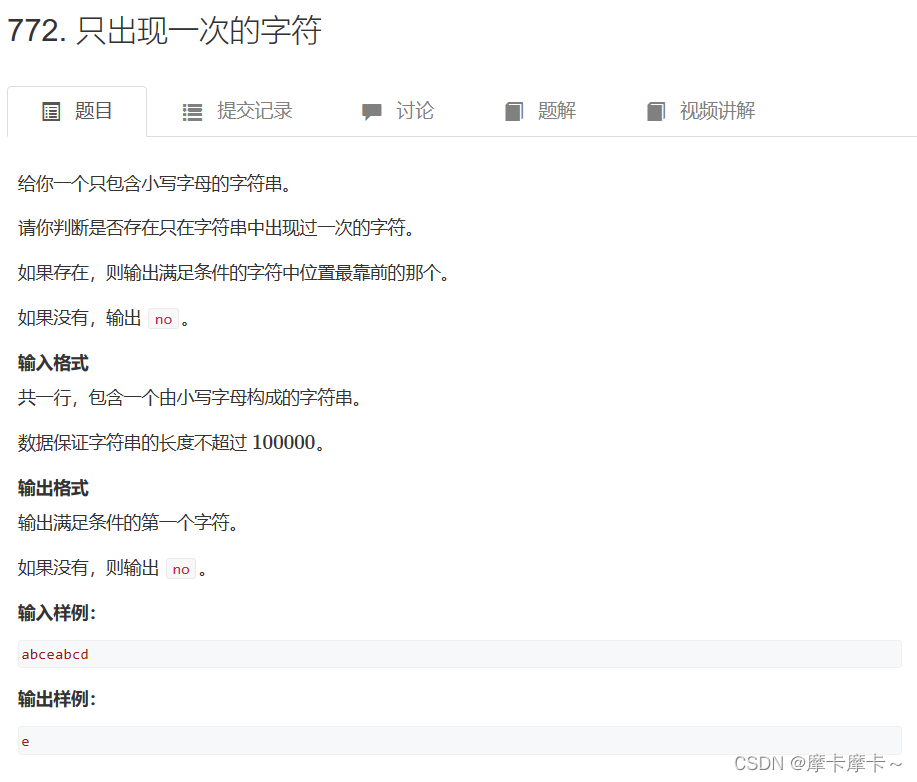
res.get(i, False) is to look up the value of key i in the dictionary res, and return the corresponding value if found, otherwise return False
s=input()
res={
}
for i in s:
if res.get(i,False):
res[i]=res[i]+1
else:
res[i]=1
for i in res:
if res[i]==1:
print(i)
exit()
print("no")
Other: round(XXX,1)
The function of this line of code is to round XXX to one decimal place.
Compare string sizes ignoring case

String several functions that can be used
str = "www.runoob.com"
print(str.upper()) # 把所有字符中的小写字母转换成大写字母
print(str.lower()) # 把所有字符中的大写字母转换成小写字母
print(str.capitalize()) # 把第一个字母转化为大写字母,其余小写
print(str.title()) # 把每个单词的第一个字母转化为大写,其余小写
s1,s2=input().lower(),input().lower()
if s1==s2:
print("=")
elif s1>s2:
print(">")
elif s1<s2:
print("<")
2. Remove extra spaces
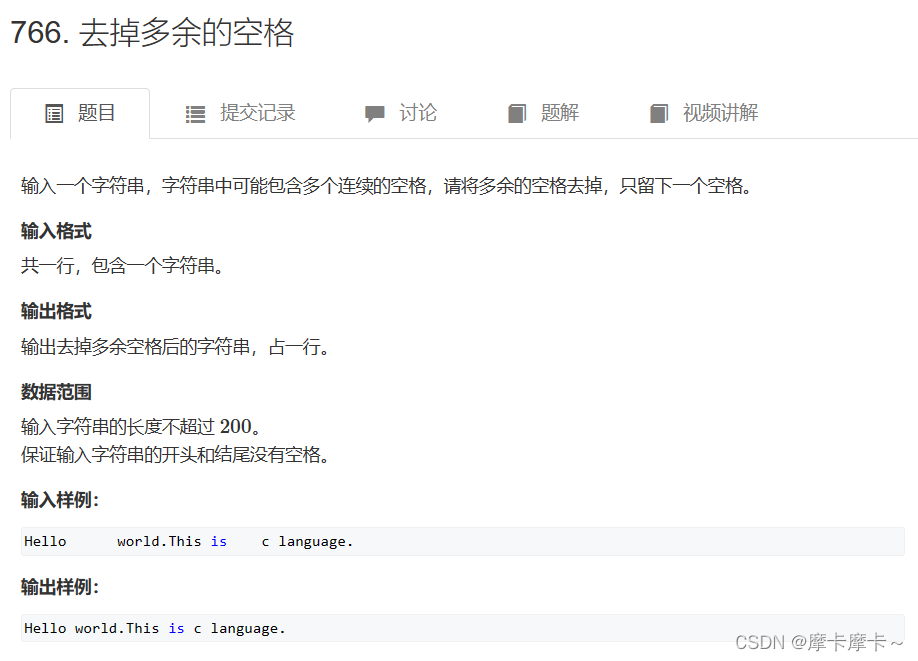
Writing method one:
print(" ".join(input().split()))
Writing method two:
for s in input().split():
print(s, end = ' ')
3. Information encryption
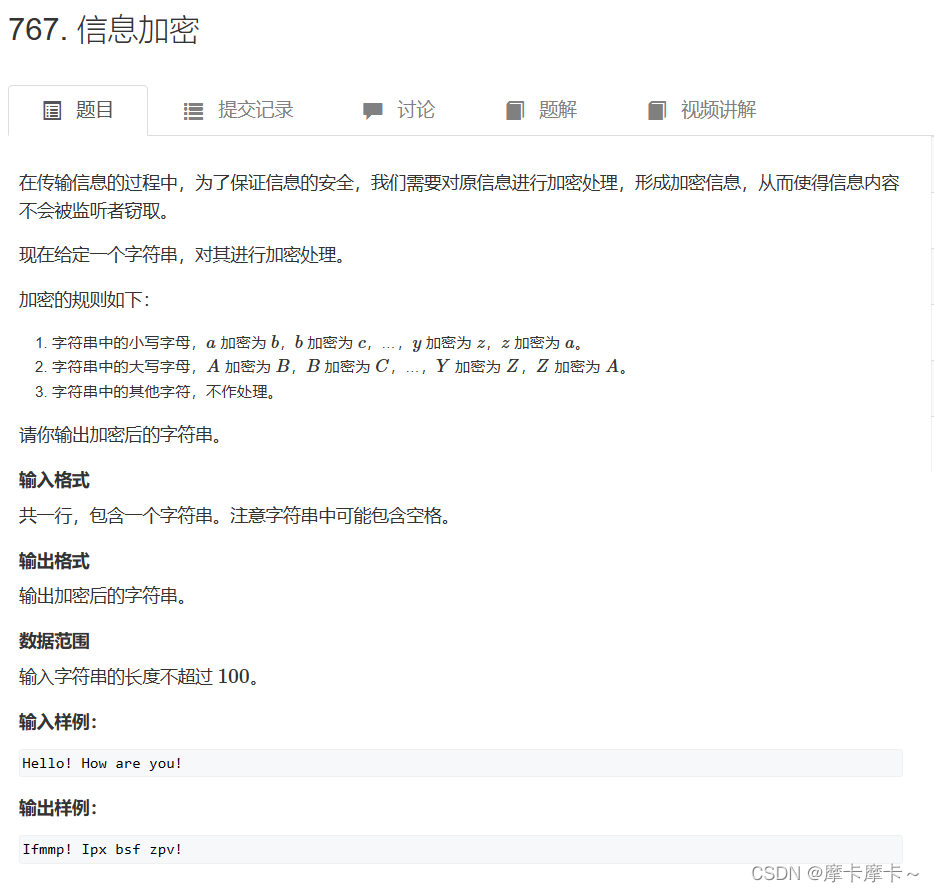
Writing method one:
chr() is a Python built-in function that takes an integer as an argument and returns the ASCII/Unicode character corresponding to that integer.
for c in input():
if c >= 'a' and c <= 'z' or c >= 'A' and c <= 'Z':
if ord(c) + 1 == ord('z') + 1 or ord(c) + 1 == ord('Z') + 1:
c = chr(ord(c) - 25)
else:
c = chr(ord(c) + 1)
print(c, end = '')
for c in input():
if c.isalpha():#判断是不是字母
if ord(c) + 1 == ord('z') + 1 or ord(c) + 1 == ord('Z') + 1:
c = chr(ord(c) - 25)
else:
c = chr(ord(c) + 1)
print(c, end = '')
Writing method two:
data = {
}
t = [chr(97+i) for i in range(26)]
for i in range(len(t)-1):
data[t[i]] = t[i+1]
data['z'] = 'a'
# print(data)
res = ''
for i in input():
if data.get(i,False):
res += data[i]
elif data.get(i.lower(),False):
res += data[i.lower()].upper()
else:
res+= i
print(res)
Writing method 3: Own writing method
Am I in control? Hahaha
s=input()
for i in s:
if i=="z":i="a"
elif i=='Z':i="A"
elif i.isalpha():
i=chr(ord(i)+1)
print(i,end='')
4. Word replacement
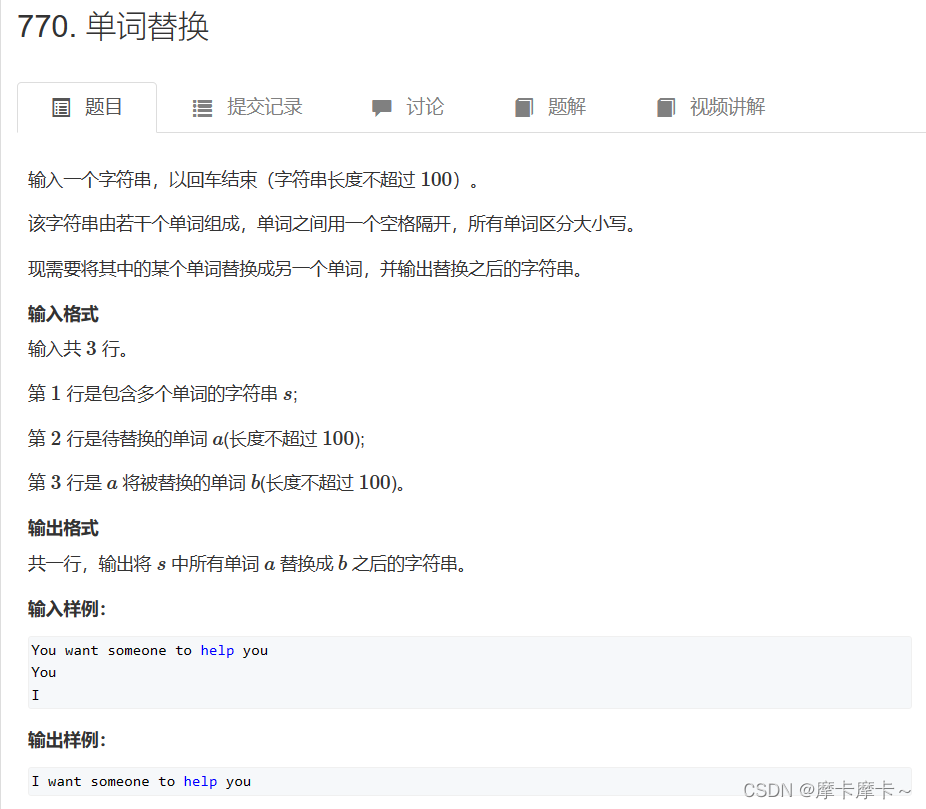
s,a,b=input(),input(),input()
for t in s.split():
if t==a:
print(b,end=" ")
else: print(t,end=" ")
Five, inverted word
Writing method one:
l=list(input().split())
l.reverse()
for i in l:
print(i,end=' ')
Writing method two:
*
The '*' sign is Python's syntax for unpacking a list or tuple, splitting it into individual variables. Here, all the elements in the list are unpacked into independent strings, which are passed to the print() function.
print(*reversed(input().split()))
Writing method three:
[::-1]
[::-1] is a special syntax of the list, which is used to output the list in reverse order, that is, from the last element to the first element, with a step size of -1.
print(*input().split()[::-1])
Six, the string shift contains the problem
Writing method 1: My own writing method hahaha
a,b=input().split()
if len(a)<len(b):
a,b=b,a
s=a+a
if b in s:
print("true")
else:
print("false")
Writing method two:
s, t = input().split()
if len(s) < len(t):
s, t = t, s
for i in range(len(s)):
str = s[i:] + s[:i]
if str.find(t) != -1:
print('true')
break
else:
print('false')
Writing method three:
s, t = input().split()
if len(s) < len(t):
s, t = t, s
s *= 2
if s.find(t) == -1:
print('false')
else:
print('true')
Seven, string power
This is to find the smallest repeated substring, and this substring can be repeated multiple times to form a parent string
Writing method one:
def check(l, s):
p = s[:l]
for i in range(l, len(s), l):
cur = s[i: i + l]
if p != cur:
return False
return True
while 1:
s = input()
if s == '.':
break
l = len(s)
maxl = 1
for curl in range(1, l):
if check(curl, s):
maxl = max(maxl, int(l / curl))
print(maxl)
Writing method two:
The smallest string must be the one with the most repetitions, so we can break out of the loop as long as we find one that meets the requirements
while True:
s = input()
if s == '.':
break
n = len(s)
for i in range(1, n + 1):
if n % i == 0:
cs = s[:i]
res = int(n / i)
cs *= res#将求出的字符串和原来的字符串对比,如果是那就说明这个方案可行
if cs == s:
print(res)
break
Writing method three:
from collections import Counter
Count how many times each number occurs
from collections import Counter
while True:
s = input()
if s == '.':
break
c = Counter(s)
print(min(c.values()))
Eight, the maximum span of the string

Writing method one:
s, a, b = map(str, input().split(','))
if s.find(a) != -1 and s.find(b) != -1:
ai = s.find(a) + len(a)
s = s[::-1]
b = b[::-1]
bi = len(s) - s.find(b) - len(b)
if ai <= bi:
print(bi - ai)
else:
print(-1)
else:
print(-1)
Writing method two:
rfind
query forward
s,s1,s2 = input().split(",")
a = s.find(s1)
b = s.rfind(s2)
if(a == -1 or b == -1 or a+len(s1) >= b):
print("-1")
else:
print(b-a-len(s1))
9. The longest public string suffix
while True:
n = int(input())
if n == 0:
break
ls = []
for i in range(n):
ls.append(input().strip()[::-1])
s1 = min(ls)#获取ls中最小的元素
s2 = max(ls)
res = ''
for i in range(len(s1)):
if s1[i] == s2[i]:
res += s1[i]
else:
break
print(res[::-1])