Introduction to Deep Learning (60) Recurrent Neural Network - Gated Recurrent Unit GRU
foreword
The core content comes from blog link 1 blog link 2 I hope you can support the author a lot
This article is used for records to prevent forgetting
Recurrent Neural Network - Gated Recurrent Unit GRU
courseware
focus on a sequence
Not every observation is equally important.

Wanting to remember only relevant observations requires:
- Mechanisms that can be followed (update gate)
- Forgetting Mechanism (Reset Gate)
Door
candidate hidden state
hidden state
Summarize
R t = σ ( X t W xr + H t − 1 W hr + br ) , Z t = σ ( X t W xz + H t − 1 W hz + bz ) , tanh ( X t W xh + ( R t ⊙ H t − 1 ) W hh + bh ) , H t = Z t ⊙ H t − 1 + ( 1 − Z t ) ⊙ H ~ t \begin{aligned}\begin{aligned} \mathbf{R}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xr} + \mathbf{H}_{t-1} \mathbf{ W}_{hr} + \mathbf{b}_r),\\ \mathbf{Z}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xz} + \mathbf{H}_{ t-1} \mathbf{W}_{hz} + \mathbf{b}_z),\\ \tanh(\mathbf{X}_t \mathbf{W}_{xh} + \left(\mathbf{R }_t \odot \mathbf{H}_{t-1}\right) \mathbf{W}_{hh} + \mathbf{b}_h),\\\mathbf{H}_t = \mathbf{Z} _t \odot \mathbf{H}_{t-1} + (1 - \mathbf{Z}_t) \odot \assignment{\mathbf{H}}_t. \end{aligned}\end{aligned}Rt=s ( XtWxr+Ht−1Whr+br),Zt=s ( XtWxz+Ht−1Whz+bz),fishy ( X .)tWxh+(Rt⊙Ht−1)Whh+bh),Ht=Zt⊙Ht−1+(1−Zt)⊙H~t.
Textbook
In the section Backpropagation through Time, we discussed how gradients are computed in recurrent neural networks, and the problem that successive matrix products can lead to vanishing or exploding gradients. Let's briefly think about the significance of this gradient anomaly in practice:
-
We may come across situations where early observations are very important for predicting all future observations. Consider an extreme case where the first observation contains a checksum and the goal is to discern at the end of the sequence whether the checksum is correct. In this case, the influence of the first lemma is crucial. We would like to have some mechanism for storing important early information in a memory cell. Without such a mechanism, we would have to assign a very large gradient to this observation, since it would affect all subsequent observations.
-
We may encounter situations where some tokens have no associated observations. For example, when sentiment analysis is performed on webpage content, there may be some auxiliary HTML codes that have nothing to do with the sentiment conveyed by the webpage. We would like to have some mechanism to skip such tokens in the hidden state representation.
-
We may encounter situations where there are logical breaks between parts of the sequence. For example, there may be transitions between chapters of a book, or between bear and bull markets in a security. In this case, it would be nice to have a way to reset our internal representation of state.
Many methods have been proposed in academia to solve such problems. One of the earliest methods is "long-short-term memory" (long-short-term memory, LSTM). A gated recurrent unit (GRU) is a slightly simplified variant that generally provides equivalent performance and is significantly faster to compute. Since the gated recurrent unit is simpler, we start with it.
1 Gated hidden state
The key difference between Gated Recurrent Units and ordinary RNNs is: The former supports gating of hidden states. This means that the model has specialized mechanisms for determining when the hidden state should be updated, and when the hidden state should be reset. These mechanisms are learnable and address the problems listed above. For example, if the first token is very important, the model will learn not to update the hidden state after the first observation. Likewise, the model can also learn to skip irrelevant casual observations. Finally, the model will also learn to reset the hidden state when needed. Below we discuss the various types of gating in detail.
1.1 Reset Gate and Update Gate
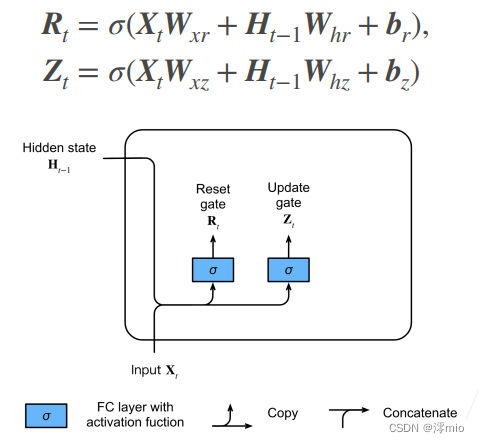
We first introduce 重置门(reset gate)and update the gate (update gate). We design them as ( 0 , 1 ) (0, 1)(0,1 ) vectors in the interval so that we can do convex combinations. The reset gate allows us to control how much of the past state we "might still want to remember"; the update gate will allow us to control how many of the new state are copies of the old state.
We start by constructing these gates. The figure below describes the input of the reset gate and update gate in the gated recurrent unit. The input is given by the input of the current time step and the hidden state of the previous time step. The outputs of the two gates are given by two fully connected layers using the sigmoid activation function.
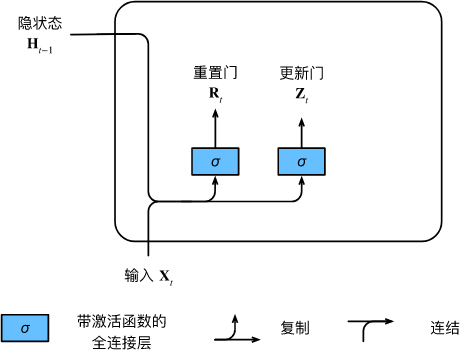
Let's look at the mathematical representation of a gated recurrent unit. For a given time step ttt , assuming the input is a mini-batchX t ∈ R n × d \mathbf{X}_t \in \mathbb{R}^{n \times d}Xt∈Rn × d (number of samplesnnn , input numberddd ), the hidden state of the last time step isH t − 1 ∈ R n × h \mathbf{H}_{t-1} \in \mathbb{R}^{n \times h}Ht−1∈Rn × h (number of hidden units). Then, the reset gateR t ∈ R n × h \mathbf{R}_t \in \mathbb{R}^{n \times h}Rt∈Rn × h and update gateZ t ∈ R n × h \mathbf{Z}_t \in \mathbb{R}^{n \times h}Zt∈RDetermine the function of n × h
: R t = σ ( X t W xr + H t − 1 W hr + br ), Z t = σ ( X t W xz + H t − 1 W hz + bz ) , \ begin{split}\begin{align} \mathbf{R}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xr} + \mathbf{H}_{t-1} \mathbf{W }_{hr} + \mathbf{b}_r),\\ \mathbf{Z}_t = \sigma(\mathbf{X}_t \mathbf{W}_{xz} + \mathbf{H}_{t -1} \mathbf{W}_{hz} + \mathbf{b}_z), \end{aligned}\end{split}Rt=s ( XtWxr+Ht−1Whr+br),Zt=s ( XtWxz+Ht−1Whz+bz),
For W xr , W xz ∈ R d × h \mathbf{W}_{xr}, \mathbf{W}_{xz} \mathbb{R}^{d \times h}Wxr,Wxz∈Rd×h和 W h r , W h z ∈ R h × h \mathbf{W}_{hr}, \mathbf{W}_{hz} \in \mathbb{R}^{h \times h} Whr,Whz∈Rh × h is the weight parameter,br , bz ∈ R 1 × h \mathbf{b}_r, \mathbf{b}_z \in \mathbb{R}^{1 \times h}br,bz∈R1 × h is the bias parameter. Note that a broadcast mechanism is triggered during the summation. We use the sigmoid function to convert the input value to the interval( 0 , 1 ) (0, 1)(0,1)。
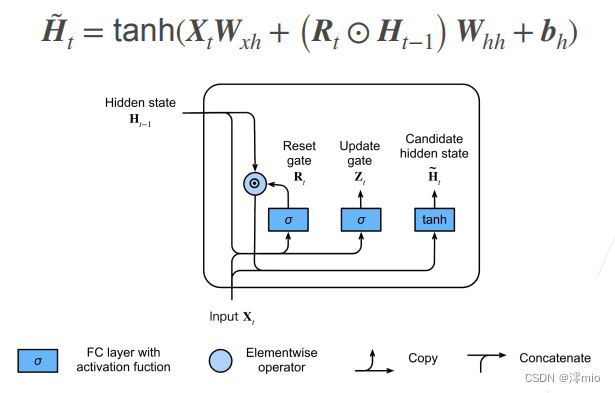
1.2 Candidate Hidden States
Next, let's reset the gate R t \mathbf{R}_tRt与RNN中 H t = ϕ ( X t W x h + H t − 1 W h h + b h ) . \mathbf{H}_t = \phi(\mathbf{X}_t \mathbf{W}_{xh} + \mathbf{H}_{t-1} \mathbf{W}_{hh} + \mathbf{b}_h). Ht=ϕ ( XtWxh+Ht−1Whh+bh) . Integrating the regular hidden state update mechanism in ., get at time stepttt的候选隐状态(candidate hidden state) H ~ t ∈ R n × h \tilde{\mathbf{H}}_t \in \mathbb{R}^{n \times h} H~t∈Rn×h
H ~ t = tanh ( X t W x h + ( R t ⊙ H t − 1 ) W h h + b h ) , \tilde{\mathbf{H}}_t = \tanh(\mathbf{X}_t \mathbf{W}_{xh} + \left(\mathbf{R}_t \odot \mathbf{H}_{t-1}\right) \mathbf{W}_{hh} + \mathbf{b}_h), H~t=fishy ( X .)tWxh+(Rt⊙Ht−1)Whh+bh),
其中 W x h ∈ R d × h \mathbf{W}_{xh} \in \mathbb{R}^{d \times h} Wxh∈Rd×h和 W h h ∈ R h × h \mathbf{W}_{hh} \in \mathbb{R}^{h \times h} Whh∈Rh × h is the weight parameter,bh ∈ R 1 × h \mathbf{b}_h \in \mathbb{R}^{1 \times h}bh∈R1 × h is a bias item, symbol⊙ \odot⊙ is the Hadamard product (element-wise product) operator. Here, we use the tanh non-linear activation function to ensure that the values in the candidate hidden states remain in the interval( − 1 , 1 ) (-1, 1)(−1,1 ) .
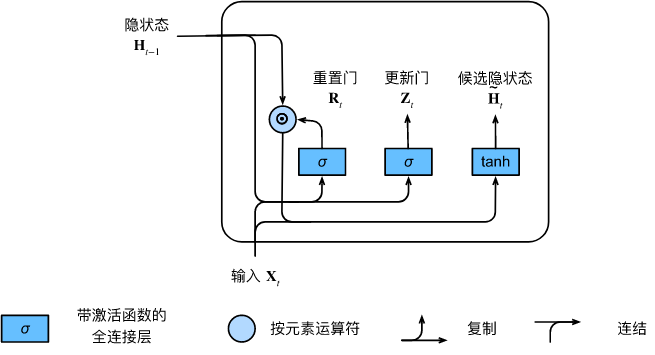
与 H t = ϕ ( X t W x h + H t − 1 W h h + b h ) . \mathbf{H}_t = \phi(\mathbf{X}_t \mathbf{W}_{xh} + \mathbf{H}_{t-1} \mathbf{W}_{hh} + \mathbf{b}_h). Ht=ϕ ( XtWxh+Ht−1Whh+bh) . Compared with the R t \mathbf{R}_tin the above formulaRt和 H t − 1 \mathbf{H}_{t-1} Ht−1Multiplying the elements of can reduce the influence of previous states. Whenever the reset gate R t \mathbf{R}_tRtWhen the term in is close to 1, we restore a normal recurrent neural network as in a normal RNN. For the reset gate R t \mathbf{R}_tRtAll close items in 0, the candidate hidden state is X t \mathbf{X}_tXtThe result of the multilayer perceptron as input. Therefore, any pre-existing hidden state is ** 重置** ** the default value.
The figure below illustrates the computation flow after applying the reset gate.
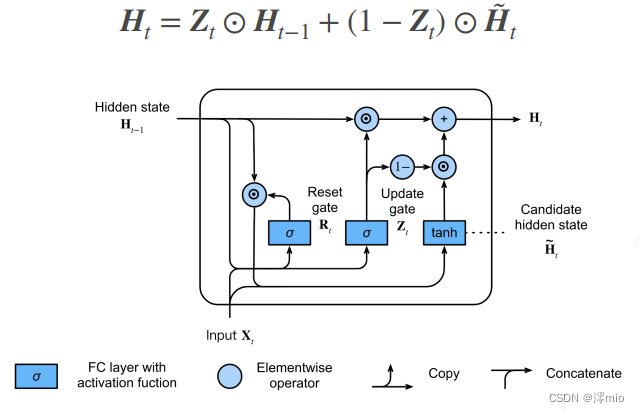
1.4 Hidden state
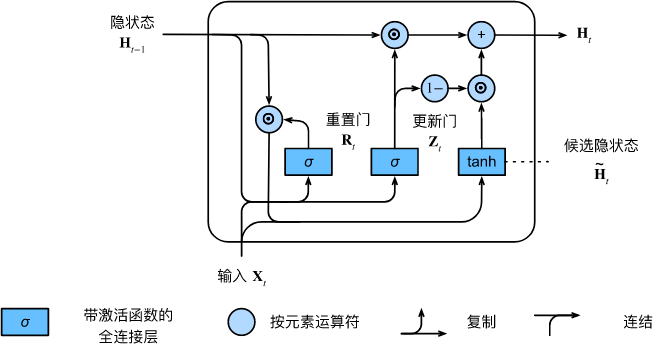
The above calculation results are only candidate hidden states, we still need to combine the update gate Z t \mathbf{Z}_tZtEffect. This step determines the new hidden state H t ∈ R n × h \mathbf{H}_t \in \mathbb{R}^{n \times h}Ht∈RTo what extent n × h comes from the old stateH t − 1 \mathbf{H}_{t-1}Ht−1and a new candidate state H ~ t \tilde{\mathbf{H}}_tH~t. Update gate Z t \mathbf{Z}_tZtOnly need in H t − 1 \mathbf{H}_{t-1}Ht−1和H ~ t \tilde{\mathbf{H}}_tH~tThis goal can be achieved by performing an element-wise convex combination between them. This leads to the final update formula for the gated recurrent unit: H t = Z t ⊙ H t − 1 + ( 1 − Z t ) ⊙ H ~ t . \mathbf{H}_t = \mathbf{Z}_t \ odot \mathbf{H}_{t-1} + (1 - \mathbf{Z}_t) \odot \tilde{\mathbf{H}}_t.Ht=Zt⊙Ht−1+(1−Zt)⊙H~t.
Whenever update gateZ t \mathbf{Z}_tZtWhen it is close to 1, the model tends to keep only the old state. At this point, from X t \mathbf{X}_tXtThe information of is essentially ignored, effectively skipping time step t in the dependency chain. On the contrary, when Z t \mathbf{Z}_tZtWhen close to 0, the new hidden state H t \mathbf{H}_tHtIt will be close to the candidate hidden state H ~ t \tilde{\mathbf{H}}_tH~t. These designs can help us deal with the vanishing gradient problem in recurrent neural networks and better capture the dependencies of sequences with long time step distances. For example, if the update gate is close to 1 for all time steps of the entire subsequence, the old hidden state at the beginning time step of the sequence will be easily retained and passed to the end of the sequence, regardless of the length of the sequence.
The figure below illustrates the computation flow after the update gate is in effect.
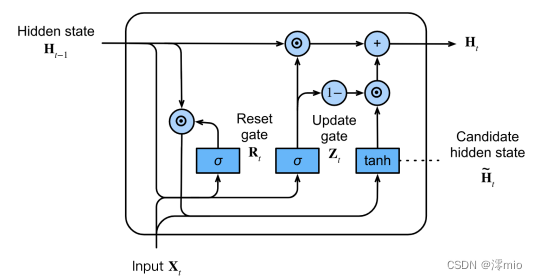
In summary, gated recurrent units have the following two salient features:
-
Reset gates help capture short-term dependencies in sequences;
-
Update gates help capture long-term dependencies in sequences.
2 Implementation from scratch
To better understand the gated recurrent unit model, we implement it from scratch. First, we read the Medium Time Machine dataset:
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
2.1 Initialize model parameters
The next step is to initialize the model parameters. We draw weights from a Gaussian distribution with a standard deviation of 0.01 and set the bias term to 0, hyperparameters num_hiddensdefine the number of hidden units, instantiate all weights related to update gate, reset gate, candidate hidden state and output layer and bias.
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数
W_xh, W_hh, b_h = three() # 候选隐状态参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
2.2 Define the model
Now we will define the initialization function for the hidden state init_gru_state. Like the function defined in section RNN Implementation from Zero init_rnn_state, this function returns a (批量大小,隐藏单元个数)tensor of shape , whose values are all zeros.
def init_gru_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device), )
Now we are ready to define the Gated Recurrent Unit model. The architecture of the model is the same as the basic RNN unit, except that the weight update formula is more complicated.
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
H, = state
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z)
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h)
H = Z * H + (1 - Z) * H_tilda
Y = H @ W_hq + b_q
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,)
2.3 Training and Prediction
Training and prediction work exactly the same as before. After training, we print out the perplexity on the training set and the perplexity on the predicted sequences prefixed with "time traveler" and "traveler", respectively.
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params,
init_gru_state, gru)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
output:
perplexity 1.3, 28030.1 tokens/sec on cuda:0
time traveller wetheving of my investian of the fromaticalllesp
travellery celaner betareabreart of the three dimensions an
3 Concise implementation
The high-level API contains all the configuration details introduced earlier, so we can directly instantiate the gated recurrent unit model. This code runs much faster because it uses compiled operators instead of Python to handle many of the details explained earlier.
num_inputs = vocab_size
gru_layer = nn.GRU(num_inputs, num_hiddens)
model = d2l.RNNModel(gru_layer, len(vocab))
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
output:
perplexity 1.1, 334788.1 tokens/sec on cuda:0
time traveller with a slight accession ofcheerfulness really thi
travelleryou can show black is white by argument said filby
4 Summary
-
Gated recurrent neural networks can better capture dependencies on sequences with long time step distances.
-
Reset gates help capture short-term dependencies in sequences.
-
Update gates help capture long-term dependencies in sequences.
-
When the reset gate is open, the gated recurrent unit contains the basic recurrent neural network; when the update gate is open, the gated recurrent unit can skip subsequences.
references
[1] Cho, K., Van Merriënboer, B., Bahdanau, D., & Bengio, Y. (2014). On the properties of neural machine translation: Encoder-decoder approaches. arXiv preprint arXiv:1409.1259.
[2] Chung, J., Gulcehre, C., Cho, K., & Bengio, Y. (2014). Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555.