Vegetarian Feng, who is constantly learning the principles, read some basic networks, personal understanding, for reference only
In the next issue, I will summarize some modified networks, learn about the ideas of modifying the network, or learn about the latest network structure and related modified networks.
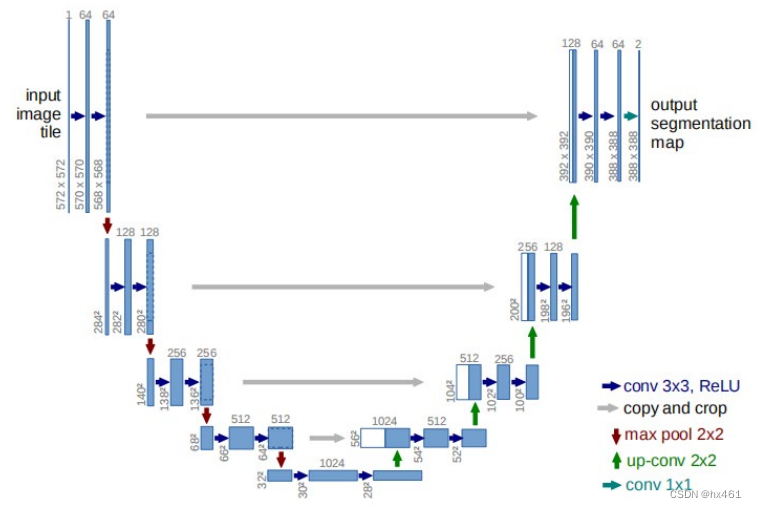
1. Unet (2015)
The Unet network has five layers, and the network contains convolutional layers, pooling layers, deconvolutional layers, and ReLU activation functions. The encoding consists of 4 blocks, and each block uses two 3*3 convolutions and ReLU (one of the activation functions) and 1 Max Pooling (maximum pooling) for downsampling, reducing the dimension and reducing the amount of calculation. The number of channels is multiplied by 2. The skip connection in the decoder stage no longer uses addition, but performs feature map splicing, and then uses convolution to halve the number of channels of the feature map.
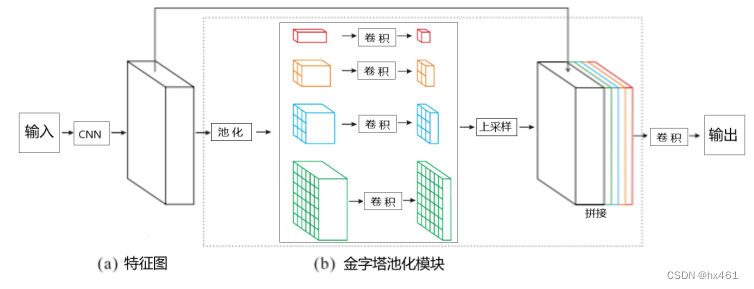
2. PSPNet (2017)
Summary: Operation steps and purpose: CNN (extract global feature map), pooling (obtain feature maps of different sizes), convolution (dimension reduction, reduce calculation amount), upsampling (guarantee the same size as the input feature), splicing ( Fusion of global features and detail features), convolution (output size)
(a) Use the pre-trained ResNet model with extended network strategy (hole convolution) to extract feature maps. The function of hole convolution is mainly to increase the receptive field, and the final feature map size is 1/8 of the input image ( stride=8). The short-circuit connection structure of ResNet can ensure that the network will not explode with the depth, which stabilizes the learning performance of the network.
(b) Use 1×1, 2×2, 3×3, 6×6 convolution kernels to perform global pooling on the feature map to obtain feature maps of different sizes, and then combine 1×1 convolution for dimensionality reduction.
Upsampling to the same size as the input feature, and then splicing with the input feature to achieve the purpose of fusing the target's detailed features (shallow features) and global features (deep features, that is, context information), making up for the receptive field of traditional convolutional neural networks For the limitation of the size of the input image, the network loses the global information of the input image by concatenating the features at four different pyramid scales.
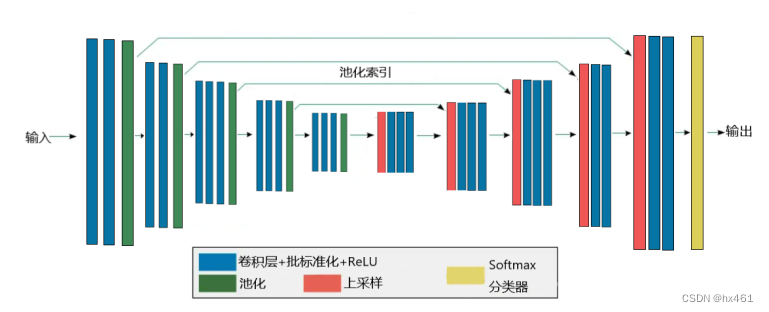
3. SegNet ( 2017)
Convolutional layer + batch normalization (BN) + ReLU . Convolution operation extracts features, batch normalization (BN) solves the problem of network overfitting, and ReLU is an activation function, which can improve the network's fault tolerance rate and the ability to deal with nonlinear problems.
pooling . Increase the receptive field of the network.
Instead of convolution with stride 2 for downsampling at the encoder stage, max pooling with positional encoding is used for downsampling. In each maximum pooling process, the pooling index is retained, the image size is compressed, and mapped to the pixel-level prediction. In the convolution operation, SegNet uses the same convolution to ensure that the image size before and after the operation remains unchanged. During the decoding process Use deconvolution to reproduce the features after image classification, use the pooling index obtained in the encoding network to perform upsampling, restore the image size to the original size, and finally use the Softmax classifier to classify the high-dimensional features of each pixel And recognition, output the maximum value of different classifications, get the final segmentation result, and realize image semantic segmentation.
( Extended knowledge, has nothing to do with the network. Specific reference paper based on the improved U-Net model UAV image building extraction research. ashx (wanfangdata.com.cn) : (1) Using Dropout after the BN layer can significantly avoid variance offset (2) When the input value is greater than 0, the derivative value of the ReLU function is always 1, which does not affect the receptive field and does not have the problem of gradient disappearance, and because the function is linear, both forward propagation and back propagation are relatively fast, when When the input value is less than 0, the ReLU function can truncate the input value, the derivative and the output result are both zero, and the network sparsity is increased, but at this time the function gradient is 0, resulting in the inactivation of neurons, and the parameter stops updating, which may cause the gradient to disappear The phenomenon occurs. The ReLU function produces some variant functions, such as the PReLU function and the Leaky ReLU function . PReLU can make the output of negative input values non-zero, which solves the problem of neuron inactivation. Leaky ReLU can assign all negative input values A non-zero slope also solves the problem of unresponsive neurons.)
4. DLinkNet (2018)
Encoding (left): 7×7 convolution is used to increase the number of channels of the original feature map from 3 to 64 to extract semantic features. Then after a maximum pooling downsampling layer, the encoder stage passes through 3, 4, 6, and 3 ResNet structures respectively to extract semantic information.
Middle: Dblock hollow convolution structure, increasing the receptive field.
Decoding (right): The original features are kept by skipping and adding, thus reducing a lot of training time. Similarly, upsampling-skipping and adding are performed sequentially, and finally 1 × 1 convolution is used to reduce the number of channels to the number of classifications .
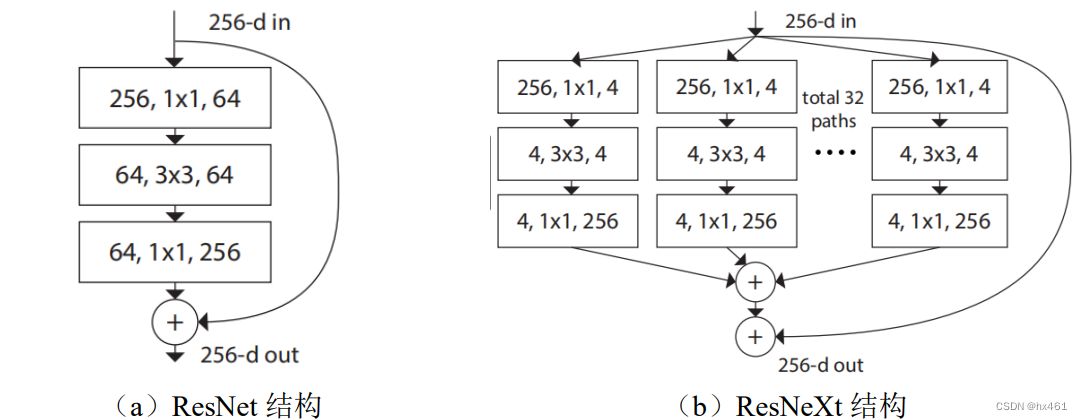
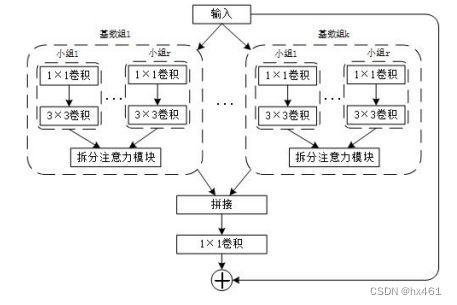
Expanding knowledge, has nothing to do with the network : ResNet, ResNeXt, ResNeSt (for details, refer to the paper P14 Research on Cloud Detection Algorithm for Remote Sensing Imagery Based on Deep Learning.ashx (wanfangdata.com.cn)

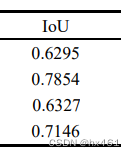
Accuracy comparison results of each article