Introduction
Paddle-based OCR tool library, the project is called PaddleOCR, which is a branch of Paddle; PaddleOCR is implemented based on deep learning technology, so a trained weight file is required when using it, but we don’t need to worry about this, because the official ones are provided . Contains an ultra-lightweight Chinese OCR with a total model of only 8.6M. A single model supports Chinese and English number combination recognition, vertical text recognition, and long text recognition. At the same time, it supports a variety of text detection and text recognition training algorithms.
Official website address:
After testing, the recognition effect of PaddleOCR is very good. The following two pictures are some pictures taken from the introduction of the official website.
PP-OCRv3 Chinese model

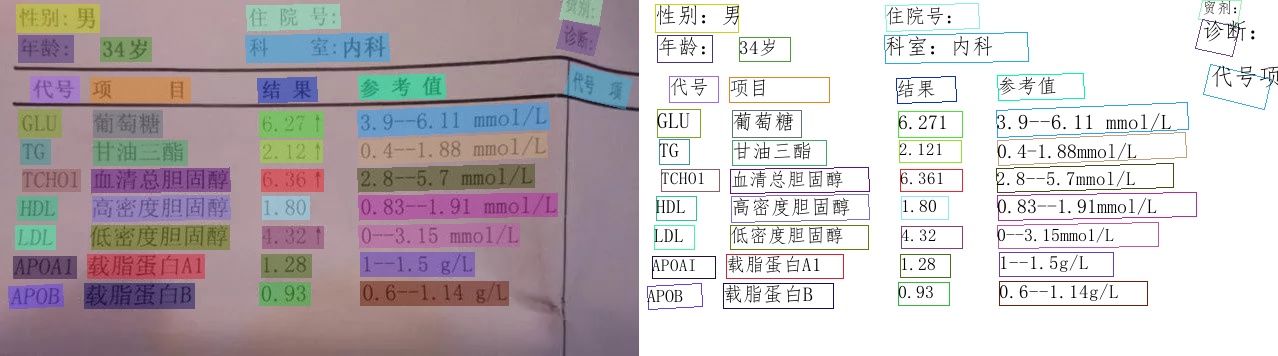
PP-OCRv3 English model

PP-OCRv3 Multilingual Model


PP-Structure Document Analysis
Regarding the PaddleOCR model, there are the following characteristics
- PaddleOCR was released on 2020.5.14, and the project has been iterated until now, and the function has been in the process of continuous improvement;
- In PaddleOCR recognition, three tasks will be completed in sequence: detection, direction classification and text recognition;
- Regarding the pre-training weights, the PaddleOCR official website is divided into two categories according to the size of the weight files provided:
- One is lightweight, (detection + classification + recognition) the total weight of the three categories is only 9.4 M, suitable for mobile phone and server deployment;
- The other type (detection + classification + recognition) has a total of 143.4 MB of memory for three types of weights, which is suitable for server deployment;
- Regardless of whether the model is lightweight, the recognition effect can be compared with the commercial effect. In this tutorial, lightweight weights will be selected for testing;
- Support multi-language recognition, currently able to support more than 80 languages;
- In addition to being able to recognize Chinese, English, and numbers, it can also deal with complex situations such as font tilting and decimal characters in the text
- Provides a wealth of OCR field-related tools for us to use, so that we can make our own data sets for training
- Semi-automatic data labeling tool;
- data synthesis tools;
PaddleOCR use
After a brief introduction, the following will teach you how to use PaddleOCR step by step.
This article mainly introduces the quick use of the PaddleOCR wheel package for the PP-OCR series models
1 Environment Introduction
Introduce the test environment used this time
- os:Win10;
- Python:3.7.11;
2 Install PaddlePaddle
-
pip3 install --upgrade pip - If you do not have a basic Python operating environment, please refer to Operating Environment Preparation .
python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple - Your machine is a CPU, please run the following command to install
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
3 Clone the PaddleOCR repository
Use (1) or (2) below, choose one of the two
(1) Use the command or download the project warehouse directly to the local git clone Download
git clone https://github.com/PaddlePaddle/PaddleOCR(2) Install the PaddleOCR whl package (you can skip step 5 after using this command)
pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本- For Windows environment users: The shapely library installed directly through pip may appear
[winRrror 126] 找不到指定模块的问题. It is recommended to download the shapely installation package from here to complete the installation.
Here I use the git command
4 Install PaddleOCR third-party dependency package
Enter PaddleOCR the folder under the command line
cd PaddleOCRInstall third-party dependencies
pip3 install -r requirements.txtIf an error is reported in this step, it is recommended to place the modified project in a virtual environment and then install it. If you use a virtual environment, remember to install the PaddlePaddle package
python3 -m pip install paddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simple5 Download the weights file
The weight link addresses are pasted below, which need to be downloaded to the local one by one; check the weight
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tardirection classification weight
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tarIdentification weight
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tarAfter downloading to the local, decompress them separately, create a inference folder, put the three folders decompressed into inference, and then inference put the folder into PaddleOCR. The final tree directory structure effect is as follows:

6 PaddleOCR use (command line)
After the above environment is configured, you can use PaddleOCR for recognition. Open the terminal in the PaddleOCR project environment, and according to your own situation, enter one of the following three types to complete text recognition
1. Use gpu to identify a single image
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True2. Use gpu to recognize multiple pictures
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True3. Recognize a single image without using gpu
python3 tools/infer/predict_system.py --image_dir="./doc/imgs/11.jpg" --det_model_dir="./inference/ch_ppocr_mobile_v2.0_det_infer/" --rec_model_dir="./inference/ch_ppocr_mobile_v2.0_rec_infer/" --cls_model_dir="./inference/ch_ppocr_mobile_v2.0_cls_infer/" --use_angle_cls=True --use_space_char=True --use_gpu=FalseThere are two parameters that need to be configured by yourself. The parameter description:
image_dir-> To identify the image path or folder;det_model_dir-> Store the recognized image path or folder;
The result is a list, each item contains a text box, text and recognition confidence
[[[28.0, 37.0], [302.0, 39.0], [302.0, 72.0], [27.0, 70.0]], ('Pure Nutrition Conditioner', 0.9658738374710083)]
......
7 Python scripts use
Using the PaddleOCR whl package through a Python script, the whl package will automatically download the ppocr lightweight model as the default model.
Detection + direction classifier + recognition whole process
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = './imgs/11.jpg'
result = ocr.ocr(img_path, cls=True)
for idx in range(len(result)):
res = result[idx]
for line in res:
print(line)
# 显示结果
# 如果本地没有simfang.ttf,可以在doc/fonts目录下下载
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')The result is a list, each item contains a text box, text and recognition confidence
Results visualization

Summarize
Paddle-OCR is one of the applications of the Paddle framework. Besides OCR, Paddle has many other interesting models. The key developers provide trained pre-weighted files, which lowers the threshold for use.
In the next issue, I will talk about the table recognition ppstructure algorithm