NVMe™ technology was built from the ground up for SSDs, and the original NVMe specification included a standard SMART (Self-Monitoring, Analysis, and Reporting Technology) log for monitoring errors, device health, and endurance.
Since then, many features have been built into NVMe technology, including enhanced error reporting, logging, management, debugging, and telemetry. These capabilities can be built into everything from open source management tools to OEM management consoles to help monitor the status and health of SSDs (such as notifying users when an SSD fails). More importantly, customers want to ensure that their SSDs are running smoothly and properly, with the ability to understand where and why failures occur and when they occur.
Management tools, log pages, durability monitoring, and more can help identify and pinpoint device failures, error numbers, and error types. These errors can include hardware failures, integrity errors, media errors, temperature issues, and more. Before we delve into the specific capabilities of NVMe technology, it's important to understand how SSDs fail, and then we can use these tools to help predict and prevent them, and when failures occur, use tools to troubleshoot problems and remedy the situation.
SSD failures generally fall into the following categories:
System incompatibility - In this case, there is nothing wrong with the SSD, but a compatibility error prevents normal operation. An example would be a system hang or no SSD enumeration. If this happens, the customer will usually return the SSD to the manufacturer.
SSD Endurance - SSD endurance is limited and writing data will eventually wear out the SSD. The good news is that this can be accurately predicted and modeled by understanding workloads and SSDs, and NVMe technology can report statistics to monitor this in real time.
Firmware errors - SSD firmware is complex and must handle many workload and state corner cases in order to transfer data. SSD vendors try to eliminate as many firmware issues as possible before going into production, but perfect validation and validation doesn't catch all firmware issues. Firmware failures account for most SSD failures!
Media Errors - There are many different classes of SSDs, some with end-to-end data protection, power loss protection, and redundancy within the SSD media via RAID, XOR, or other techniques. But NAND flash and other storage and memory classes do have faults, too many of which can cause an SSD to stop working.
Hardware errors - Capacitors, resistors, and power management circuits may fail. This situation is relatively rare, but when it happens, the consequences can be more serious.
1 How to use log analysis to analyze the problem?
The log pages are maintained in the SSD and can be read by the host software at any time. Below are the various log pages used by NVMe technology:
1.1 Error log page
The error log page is used to record all errors so that no errors are unreported or lost. NVMe drives maintain an error log page that records all errors that occur. This log page holds important information about the number of errors, which queue the errors came from, and which data and namespaces were affected. This is critical for identifying problematic drives and possible sources of errors in your system.
sudo nvme error-log /dev/nvme0n1
Error Log Entries for device:nvme2n1 entries:64
Entry[ 0]
error_count : 500
sqid : 0
cmdid : 0x1008
status_field : 0x6002(Invalid Field in Command: A reserved coded value or an unsupported value in a defined field)
phase_tag : 0
parm_err_loc : 0x28
lba : 0
nsid : 0
vs : 0
trtype : The transport type is not indicated or the error is not transport related.
cs : 0
trtype_spec_info: 01.2 SMART log page
The SMART log page is used to report general health information about the drive. Its main health indicator is called a critical warning, which warns of problems in the drive. The NVMe drive will then notify the host of the type of problem. Problems could mean that the drive is in degraded or read-only mode due to a media error, that the drive is currently exceeding a temperature threshold, or that there may be a hardware failure. The SMART log page can also summarize error log pages for media or data integrity errors and list the number of unsafe shutdowns due to power loss events. Finally, the SMART page is used to monitor stamina. By looking at the SMART Percentage Used field, system integrators can see the percentage of SSD life remaining as a percentage of the total life used/available, which is an easy-to-read percentage. To best utilize this feature, vendors can set an Available Spares field to send a notification to the host when spares fall below a certain threshold.
sudo nvme smart-log /dev/nvme0n1 -H
Smart Log for NVME device:nvme2n1 namespace-id:ffffffff
critical_warning : 0
Available Spare[0] : 0
Temp. Threshold[1] : 0
NVM subsystem Reliability[2] : 0
...Extending NVMe Cli -- Perspective of Nvme SSD from Linux - Programmer Sought
1.3 Persistent Event Log
A persistent event log was added in the NVMe 1.4 specification, which can be likened to an SSD's black box recorder. This is used to log events happening on the SSD such as errors, firmware updates, formatting etc so that people can see them clearly and with a time stamp. This is useful for OEMs or OS vendors who wish to identify and manage their devices and determine when specific events or failures occur. Those interested in learning more about the persistent event log can visit the "Changes in NVMe Revision 1.4" web page.
1.4 Telemetry technology - adding debugging capabilities to NVMe technology
Telemetry enables SSD vendors/manufacturers to collect internal logs when a device fails. Due to customers' IP and internal data collection sensitivities, standard human-readable logs are encouraged here. This command can be initiated by either the host or the controller, but usually it is for the host (in this case the customer) to read the telemetry logs and send them to the SSD vendor or OEM when the device fails. It is meaningful to conduct further analysis. As we saw from the introduction, firmware issues are the leading cause of SSD failures, and telemetry logs allow vendors to find the root cause when failures occur in the field.
1.5 Event and Error Reporting
In addition to the log page, many NVMe specifications provide functionality for reporting errors and operation failures. These reports help identify each specific type of error and how to recover controllers, drives, and the operating system.
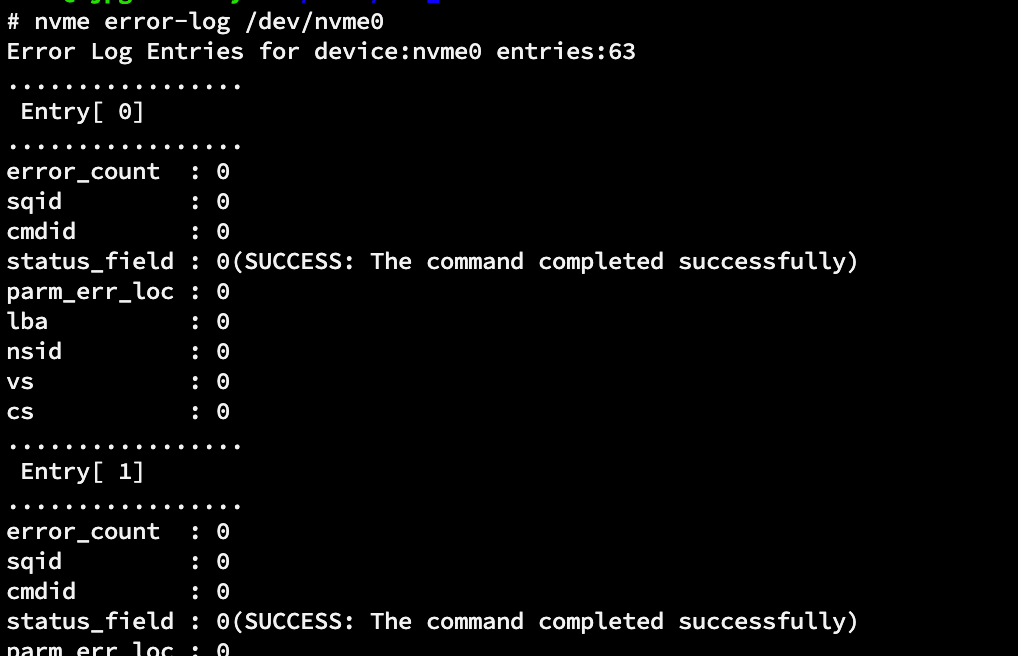
Image source [ NVME CLI -- nvme command to view the internal status of NVME devices ]
1.6 Asynchronous event request
Asynchronous events are used to notify host software of status, error, and health information for various events. An NVMe controller or drive will report an event to the host software when an error, drive attribute change, SMART change, or complete management event occurs. The most important feature here is that the NVMe controller (and in most cases the drive) can asynchronously notify the host when a critical warning occurs, and the operating system or system console can immediately report this to the user. To learn more details about the event types defined, visit page 96 of the NVMe 1.4 specification.
1.6 Operation failed
The NVMe specification includes a section dedicated to error reporting and recovery for controller/drivers, drivers, and operating system usage. This is primarily used by device drivers and host software systems to identify critical faults in NVM subsystems and NVMe controllers. This section can be found on page 400 of the NVMe 1.4 specification.
1.7 Rebuild Help
Rebuild Assist was added as an option in the NVMe 1.4 specification. Rebuild Assist defines a new Get LBA Status function for identifying potentially unrecoverable LBAs on a host. This state is used to determine which LBAs on the device the host needs to restore from elsewhere and rewrite. A major use case for rebuild assist is to help with background data wiping of replacement SSDs, since SSD firmware typically already performs this analysis internally and now has a way to report this to the host. The host usually has redundant copies of the data and now has the opportunity to restore the data from the valid copy.
1.8 Management
The management capabilities of NVMe Management Interface™ (NVMe-mi™) technology are critical to enterprise, cloud, and data center deployments. This is especially useful for OEMs that support multiple operating systems and benefit from a single management console, which is a value-add for end customers.
NVMe-MI specification
The NVMe-mi specification manages NVMe SSDs outside the operating system through SMBUS/MCTP and PCIe/vdm interfaces. The NVMe-MI architecture uses the baseboard management controller to check inventory, monitor errors, track SMART logs and endurance, and report these conditions through the management console. To learn more about the NVMe-MI specification, we invite you to read our NVMe-MI technical blog for a more in-depth explanation of its capabilities and benefits. NVMe-mi really sets the NVMe standard apart from other storage interfaces by providing a complete specification dedicated to managing storage devices.
2. Self-diagnosis problems
The test feature is useful for diagnostics and ensuring proper implementation of NVMe technology.
Device self-test command
The Device Self-Test command feature, defined on page 107 of the NVMe 1.4 specification, allows the host to initiate a short-term or long-term self-test to run offline diagnostics. OEMs, ODMS, and system integrators often use this command feature when integrating new NVMe SSDs into larger systems. An example would be at a system integrator or factory where they take SSDs from an SSD vendor and put them into a larger server, then proceed to run self-test commands to make sure the drives are all working. The NVMe specification includes an infographic with example device self-tests.

forward from
How SSDs Fail – NVMe™ SSD Management, Error Reporting, and Logging Capabilities - NVM Express
Author: Jonmichael Hands, NVMe MWG Co-Chair, Intel
