1 Introduction
Opencv is a cool computer vision library. As a lover of CV technology, I highly recommend Opencv and pay tribute to the industry predecessors. This article will introduce the entire process and code principles of poker recognition in as much detail as possible. On the one hand, I will practice my writing ability, and on the other hand, I hope to help some interested beginners understand the process of image recognition more intuitively (one).
This small demo is also one of the many small projects I did during the learning process. It is relatively perfect and can be run independently without Opencv Manager. It can only be used to identify the pages of specific software on the computer at present, but if you understand the principle, you can do a more general image recognition processing app. The final effect of the code running and the github address will be posted below. Fork and star are welcome. I will continue to learn about CV in the future, and you are welcome to leave a message to exchange ideas.

GitHub address: https://github.com/woshiwzy/opencv_android
2. Development environment
AndroidStudio: 3.3.2
Opencv:3.4.2
Gradle :4.4
3. Project Structure Introduction
This project mainly includes opencv module and poker_rec module. The other modules are used for testing. You can ignore them. The important source code for poker recognition is in the poker_rec model, and this module is also run when running. good_data.zip is a pre-classified sample file. When running, the code will copy the zip package to the SD card and automatically decompress it. When the recognition starts, these sample images will be converted into feature values for recognition. In theory, these original sample files are not needed, only the features need to be preserved. This is to demonstrate the algorithm very well and also to see the matching process of the KNN algorithm intuitively (use the picture pointed by the red arrow in the project to test, otherwise it will not work ) .
4. Knowledge literacy
What is machine learning?
I think most of the people who read this article have a certain understanding of machine learning. I don’t think it is necessary to interpret this meaning in very academic terms. Isn’t the purpose of human learning just to know more things? The same is true for machine learning, which is to let computers know more things by learning analogies.
Here we let the computer recognize images. To make the computer recognize things, we must first teach it, and he will recognize it naturally after learning, so we prepared a lot of samples to tell the computer what is a square, what is a plum blossom, etc. When there are enough samples, the computer can naturally distinguish what it sees through analogy.
There are many kinds of machine learning algorithms, such as KNN, K-means, decision tree, SVM, Bayesian, etc. We extract the characteristic data of samples and targets, and then apply these classification algorithms to achieve the purpose of object classification, thus simply completing a machine learning process. Of course, machine learning is not only used for classification, but also for more and more complicated things. The ever-changing applications of machine learning in the field of image recognition are actually used for classification. Therefore, image classification is still one of the most basic and important tasks of image recognition.
How to classify in the field of image recognition?
In any case, classification of anything requires a classification target. For example, what kind of family a plant is, then the classification target is this plant, and the samples are naturally the various plants and plant categories that we have defined. Who is a person, we can use his facial features to classify, and the human face is a target that needs to be classified. In the same image classification, we first need to find the classification target. For example, we need to know whether there is an apple in a certain picture. Usually, we need to deduct the place where there may be an apple and compare it with the apple picture. When the matching degree reaches a certain level through comparison, we think that the deducted picture area is an apple. This kind of processing process is usually called image segmentation, which is an indispensable process in image recognition. The effect of image segmentation directly affects the final effect of image recognition. In order to solve this process, many algorithms have been proposed to solve this problem. In my opinion, image segmentation is still a technology that needs continuous improvement. It happens that the image segmentation used in this open source project is very simple, and you don't need to know too much about the principles to complete this task well.
There are currently two main types of image recognition methods in the field of image recognition; single-step method and candidate region-based recognition. One-step methods such as the yolo algorithm, which directly pass unknown pictures to the neural network, can identify target objects without searching for candidate areas. Based on the candidate area method, there is an additional process. First, find the candidate areas where an object may exist. The second step compares these candidate areas with known samples. If the match reaches a certain level, it is considered that an object has been recognized.
The single-step method and the method based on the candidate area have their own advantages and disadvantages. A simple analogy is as follows
The advantages and disadvantages of the algorithm based on the candidate area are as follows:
Fewer samples, more efficient running speed, easier-to-understand algorithm, and cheaper equipment, but some cases cannot be solved by single-step method or the effect is very poor. This open source project uses the method based on the candidate area to solve the problem.
Advantages and disadvantages of single-step method:
With more samples, the single-step method uses more neural networks, which requires high equipment performance and can solve more complex problems.
5. Application of KNN algorithm in this example
The KNN algorithm is a simple, intuitive and easy-to-understand classification method. To give a very popular example, if you want to determine whether a person is a rich person, an ordinary person, or a poor person, you can see who he often hangs out with (and who is closer to him). He is that type of person. The so-called flocking of like attracts people into groups, which can well explain the original idea of this KNN, and we will not introduce very academic concepts here.
In this example we will divide all sample data into the following categories
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, diamonds, spades, clubs, spades, A, J, K, Q, and X are 19 categories. We collected dozens of samples for each category. When we capture an unknown picture and want to know which category it belongs to, we only need to compare it with the samples of these categories. The unknown picture is more similar to the picture of which category, then which category it belongs to. Algorithm, for an unknown image, we only need to find a sample that is closest to it, and the category of this sample is defined as the category of the unknown image.
Why is there an X folder here?
Think about it, if you capture an image and he doesn’t want any kind of picture, then it is very likely that he is not the target we are looking for. We don’t care about this kind of thing, so we divide it into a separate category, which we can call negative samples. Anything that is not what we want is classified into this category, and it does not affect us to get the correct data.
6. How to get the candidate area
Talking about the one-step method and the two-step method again
We said earlier that there are usually two types of methods in the field of image recognition: one is a one-step method, and the other is a two-step method based on candidate areas. Most of the commonly used one-step methods are based on DNN, which can solve more complex problems, but requires higher equipment and more samples. In many natural scenarios, the sample data requirements for a single category may reach thousands. The typical algorithm is YOLO. Typical algorithms based on candidate areas, such as faster rcnn, are relatively successful at present, but relatively speaking, YOLO has greater advantages, fast speed, wide application, and relatively simple application.
The two commonly used algorithms mentioned above are both based on the implementation of deep neural networks. This has many advantages, such as more accurate, stronger generalization ability, and so on. But once deep learning is used, it means that your program will be more complex and require higher hardware equipment, otherwise it will not make much sense in some real-time applications, so deep learning frameworks generally support GPU operations to improve speed. However, there is usually no GPU acceleration on embedded devices, and it is the same in this example. We still use traditional algorithms to solve this relatively simple and practical problem, rather than building a neural network to solve this problem.
This has many advantages: 1. For the image recognition processing in this single environment, we only need to use traditional algorithms to solve the problem, and there is no need to complicate it. 2. In this environment, the samples we get are of high quality, and only a small number of samples are needed to solve the problem. Recognition can be done without too strong generalization ability. Facts have proved that doing so is very sensible, especially on embedded devices, the effect is excellent.
Whether to use a deep learning network or not, I see it this way: If you can use traditional algorithms to solve problems, you don’t need DNN. The advantages and disadvantages have been mentioned above. In some cases, it is understandable that DNN must be used (image recognition using DNN is definitely not necessary, but many off-the-shelf implementations are based on DNN). I think many papers in the field of CV are piling up networks to achieve image recognition. To be honest, I don’t think this is a wise method. I think image segmentation technology is more important than piling up networks. Only good image segmentation technology can solve problems more elegantly. Is imitating neural networks the ultimate method for image recognition? Deep learning seems to be a fashionable product of academia and everyone is studying it.
Use Opencv to extract candidate regions
This section will combine the example source code and the Opencv API to discuss the extraction of candidate regions in the first step of the two-step method.
Here we will use the Imgproc.findContours function. This function is often called when doing image recognition. It is mainly used to find connected areas (or contours). It will divide the input image into small areas of different sizes according to the grayscale of the color. In most cases, these areas are the candidate areas we want. For example, in this example, the small area obtained through the findContours function may be the number or suit on the poker card we want to recognize. Let's take a look at the C++ prototype of this function (it would be better to look directly at the Demo code):
cv2.findContours(image, mode, method[, contours[, hierarchy[, offset ]]])
Returns two values: contours: hierarchy.
parameter
The first parameter is the image to find the contours;
The second parameter indicates the retrieval mode of the contour, and there are four types (this article introduces the new cv2 interface):
cv2.RETR_EXTERNAL表示只检测外轮廓
cv2.RETR_LIST检测的轮廓不建立等级关系
cv2.RETR_CCOMP建立两个等级的轮廓,上面的一层为外边界,里面的一层为内孔的边界信息。如果内孔内还有一个连通物体,这个物体的边界也在顶层。
cv2.RETR_TREE建立一个等级树结构的轮廓。
The third parameter method is the approximation method of the contour
**cv2.CHAIN_APPROX_NONE存储所有的轮廓点,相邻的两个点的像素位置差不超过1**,即max(abs(x1-x2),abs(y2-y1))==1
cv2.CHAIN_APPROX_SIMPLE压缩水平方向,垂直方向,对角线方向的元素,只保留该方向的终点坐标,例如一个矩形轮廓只需4个点来保存轮廓信息
cv2.CHAIN_APPROX_TC89_L1,CV_CHAIN_APPROX_TC89_KCOS使用teh-Chinl chain 近似算法
The cv2.findContours() function returns two values, one is the contour itself, and the other is the attribute corresponding to each contour.
Here I want to focus on the second parameter, the first two cv2.RETR_EXTERNAL and cv2.RETR_LIST. In my practice, I found that only when cv2.RETR_LIST is passed in, can I get enough contours. From the perspective of parameter explanation, this is also reasonable. The third parameter selection is not so important. In this example, I chose CHAIN_APPROX_SIMPLE, and initially selected other parameters. For this example, there is almost no difference in effect.
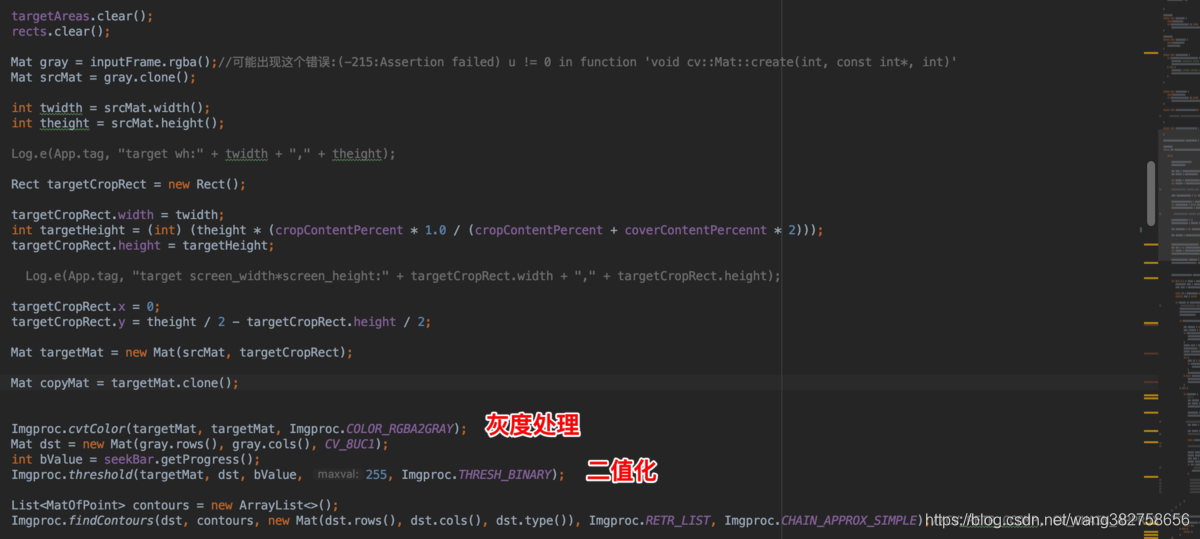
It should be noted that before executing the findContours function, some other processing has been done, the most important ones are grayscale processing and binarization. Binarization is a requirement of the findContours function, and the binary image must be passed in. Grayscale processing is a means to reduce image interference. For detailed codes, see
com.myopencvdemo.PokerRecActivity
Screening Candidates
In the previous section we mentioned the function Imgproc class
public static void findContours(Mat image, List<MatOfPoint> contours, Mat hierarchy, int mode, int method)
Function, this function is to extract the Unicom area from the image. Simply put, its function is to connect some areas that may be a whole and return it to the caller. Whether it is in the powerful deep learning network or in the simple two-stage traditional machine learning algorithm, it is a very important step. If this step is perfect, the image recognition will be 80% successful.
As an example:
If you want to identify a car in a picture: you pass in a picture containing a car, and there will be many connected areas obtained by calling findContours. There may be wheels, lights, hoods, and of course the entire vehicle area (this is an ideal situation). The countless fragmented areas obtained in this way may or may not have the area you want. For example, you only get the hood area in this way, but this area cannot accurately predict that this is a car, let alone predict the accuracy of the car. Location, the reason is that the Unicom area you find in this way is not perfect. The most perfect area is the circumscribed rectangle of the vehicle. Of course, 90% of this is impossible in actual processing, or you need to improve this algorithm. In this case, you need to use a deep learning algorithm framework such as YOLO. By providing a large number of data sets, the algorithm can automatically adapt to learning and find the perfect circumscribed rectangle of the vehicle. Of course, this is another topic.
Back to this example:
Fortunately, we can get a perfect rectangular frame. The biggest reason is that the application scenario here is very special. First of all, the suits and numbers of poker are separated, and their circumscribed rectangles will not be connected together (the white background of poker plays a role of division). Secondly, the images captured by the camera are not much different each time (the angle and brightness are not much different, and the character features are fixed), and we can also guide the customer on the software to guide the customer to align the red rectangle frame of the camera with the playing cards, which can greatly reduce the amount of calculation, improve the speed, and reduce recognition interference. The scenarios we are discussing so far are very simple, but they are limited to identifying such a single scenario. If you want to recognize more complex scenarios, you need to modify the algorithm according to the actual situation, or even use the DNN algorithm framework. My consistent view is that if you can use the two-step method of traditional machine learning algorithms to solve problems, try not to use the DNN framework. Although the DNN framework can solve many problems perfectly, it is difficult to operate, the hardware is expensive, and the application scenarios are greatly restricted. Moreover, to make the DNN framework work, a lot of preparation work (collecting samples) is also required, and the coding work will not be less.
The two paragraphs mentioned above are a simple foundation of knowledge:
Let's study the findContours function now. Its most useful calculation results are placed in the contours parameter, which is a List of MatOfPoint types. A MatOfPoint contains many points, and the connection of these points can be regarded as a connected area.
List<MatOfPoint> contours = new ArrayList<>();
Imgproc.findContours(dst, contours, new Mat(dst.rows(), dst.cols(), dst.type()), Imgproc.RETR_LIST, Imgproc.CHAIN_APPROX_SIMPLE);//CV_RETR_CCOMP, CV_CHAIN_APPROX_NONE
Another very important point is the parameter selection of the findContours function. The most important thing is the selection of the mode parameter. It is best to choose Imgproc.RETR_LIST, which can return the number of Unicom areas to the greatest extent. Without missing some areas that were originally the target.
In the following text, specific codes will be combined to discuss specific screening issues:
Step 1:
Use the boundingRect function to convert the connected area into a rectangular area, which is convenient for us to calculate the height, width, proportion, area and other characteristic information of this area. For our current application scenario, neither too small area nor too large area is required, because they are not the area we are looking for. Too small area may be some small gaps, and too large area may be a large color area. The height-to-width ratio is too small or too large, and it is not the area we are looking for, because the color number and number of the playing cards are generally close to a square, and generally speaking, the height is greater than the width. We can appropriately enlarge this limitation. For example, if the height is 1-3 times the width, it can be used as a candidate area and saved to the disk for the second step.
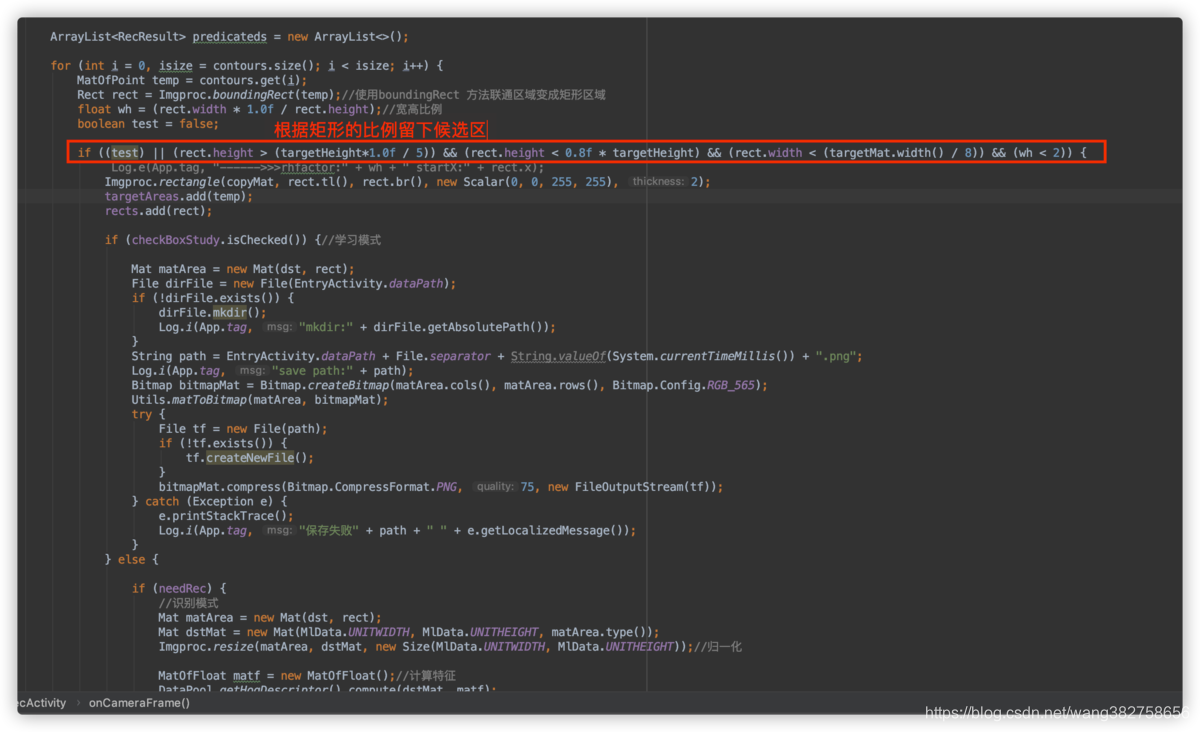
The second step is
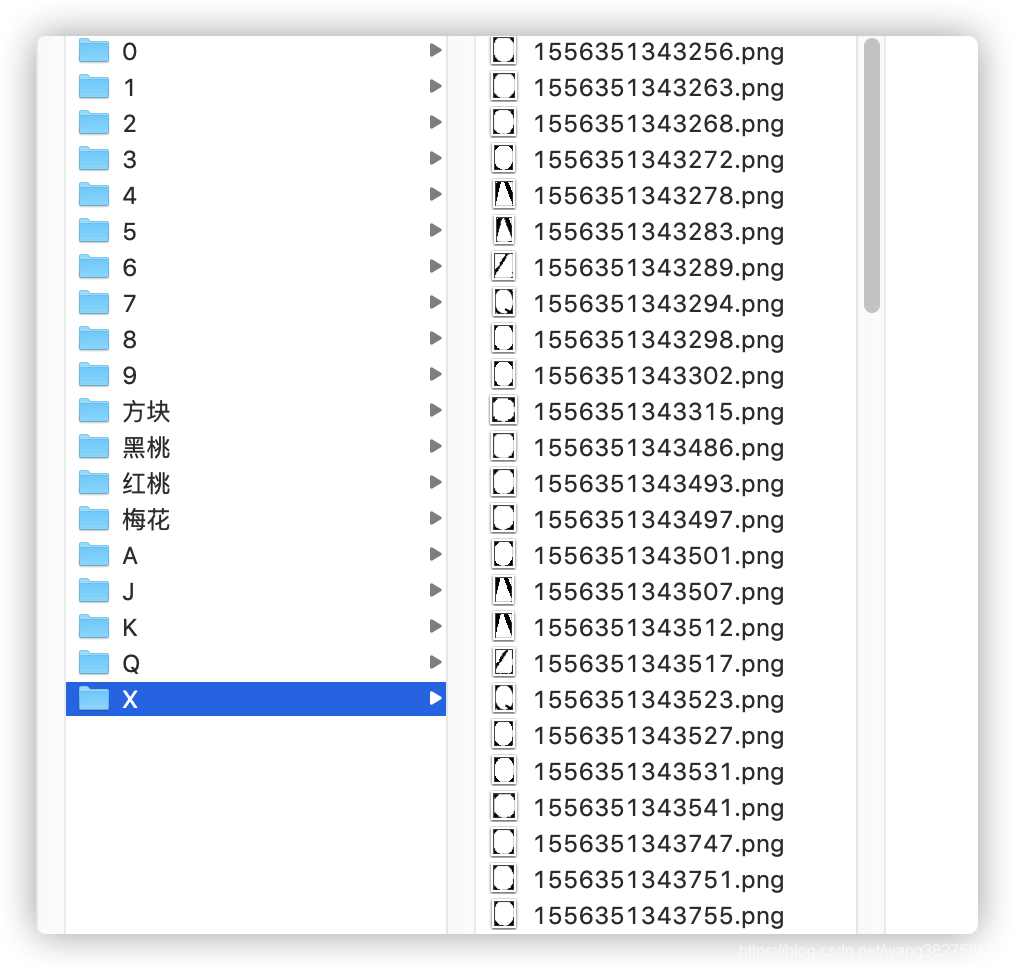
manual screening, the so-called artificial intelligence, which is impossible without human participation. Manually classify the files saved in the candidate area selected in the first step. For example, here we need to identify 18 cases of numbers and color numbers (0, 1, 2, 3, 4, 5, 6, 8, 9, diamonds, spades, hearts, clubs, A, J, K, Q). Then we need to create 19 folders as follows. Why do we create a folder called X here

?
The candidate area files we got are all called candidate areas because they are not 100% accurate. We classify the accurate parts, not the areas we want (not any of the 18 types) and put them in the X folder
separately
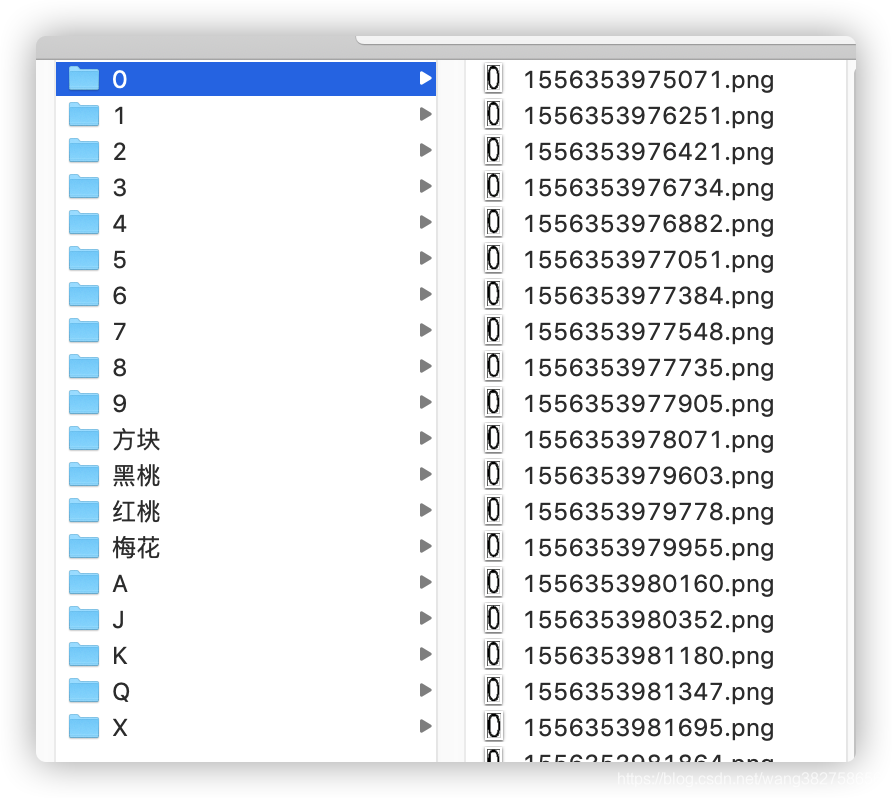
.
This is because when we are dealing with candidate areas, we cannot completely filter out non-candidate areas, because some non-candidate areas exhibit characteristics very similar to candidate areas. It cannot be simply deleted, it needs to be used in the following algorithm. Let me put it simply: in the recognition process, we also get the candidate area first, and then compare the characteristics of each candidate area with the known classification. We will classify it as whose features it is more similar to. close to a sample). To put it bluntly, each candidate area is compared with all samples for a feature (to be discussed later), to find the sample with the smallest feature distance, which class this sample belongs to, and we consider this candidate area to belong to this class.
So far, the role of the X folder is very clear. If the characteristics of the candidate area are very close to the characteristics of a sample in the X folder (the feature distance is the smallest), then this sample belongs to X. This candidate area is not one of our 18 types, so we don’t care about it. On many occasions, we call the samples in the X folder negative samples, while the samples in the other 18 folders are called positive samples. If there is no negative template, then there may be such a situation: According to the calculation results of some algorithms (such as KNN), for a candidate area, it does not belong to one of the 18 types, but the result needs to take the most similar result, so that one of the 18 types will be selected. The similarity will be very low, so the result itself is wrong or extremely inaccurate (this is unscientific, unless a similarity threshold is added. , as the result, otherwise there is no result for this comparison).
In a word: With negative samples, the accuracy of recognition results is increased.
7. Processing screening area
First look at the source code picture.
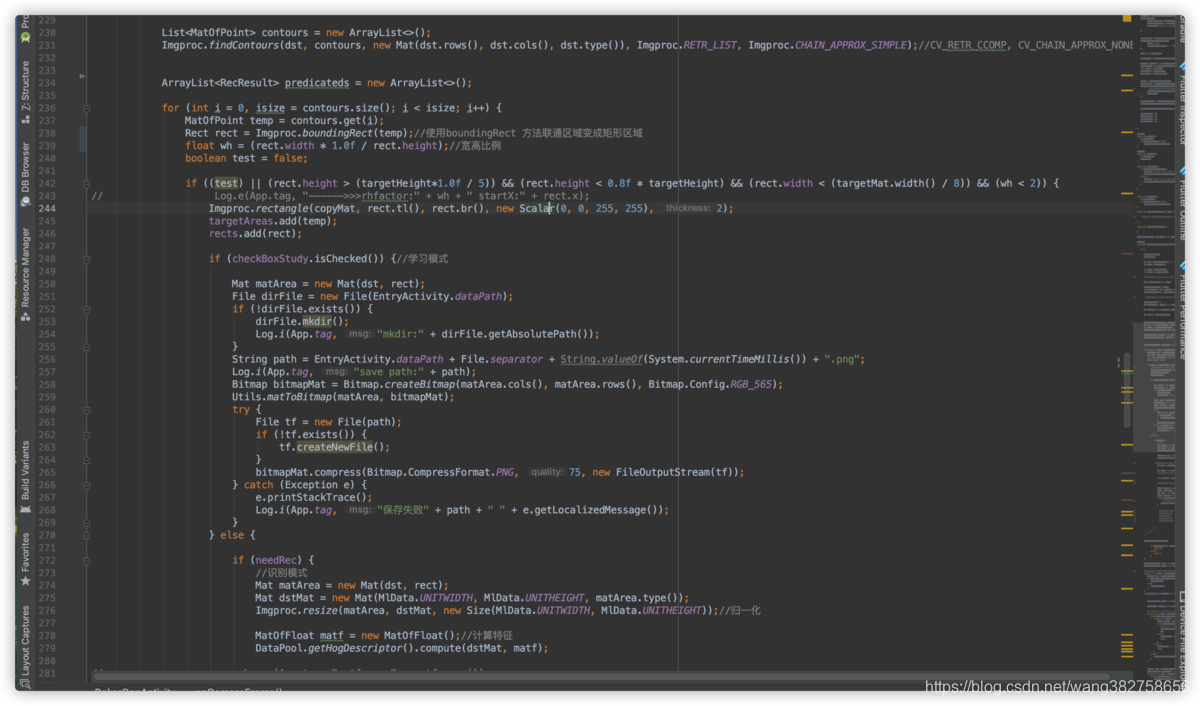
In line 242, the possible candidate areas are screened out by width, height, and aspect ratio, and stored in rects. Where needed, they are cut out according to the rectangular frame saved in rects. If the Checkbox of the learning mode is selected, the seat pictures of these candidate areas are saved to the SD card, and these pictures need to be manually classified and put into 19 folders, which are the final samples. The more samples, the more accurate the samples, and the more accurate the recognition results, but more samples will also lead to slower speed.
Starting at line 273, it is the real entry into the identification process

The identification process has the following steps
1. Initialize the machine learning engine (do this when the App starts)
This initialization first converts the sample image into vector features according to the set parameters. The recognition process is not a comparison image but a comparison feature. This needs to be kept in mind. If it is a comparison image, it is another algorithm. So in fact, we sort out the recognized pictures and save their features. Features take up much less storage space than pictures. In the production environment of machine learning, the process of converting samples into features will not be put into the final program. The final program is only responsible for loading features into the machine learning engine for calculation. The reason why I have to convert from pictures to features every time is to add sample files to the folder for my convenience. After adding, just restart the App, and then go through the initialization process, without the need to process feature files separately (in fact, the whole process does not involve feature files).
2. Convert each image of all candidate areas into feature values, and put them in the machine learning engine in turn to get the best match
Only KNN does this, most other learning algorithms do not
3. Organize the results
For this example, it is necessary to organize the result set, such as sorting the order, calculating the suit, and determining the position of 10 on the playing card
All the recognition results are saved in line 297, and then they need to be sorted out. The sorting algorithm is as follows
Step 1: Sort according to the starting position of cropping (suits and numbers are divided into two groups), and sort all the results to get the correct order
Step 2: Deal with the result that the poker card is 10, because 10 is separated from 1 and 0, and there are 2 results during recognition. If it is found after sorting that 1 is followed by 0, it will be combined into one result to be 10
Step 3: In this example, only 18 situations are considered, and the situation of king and king is not considered. After being divided into 2 groups, they are (A, 2, 3, 4, 5, 6, 7, 8, 9, 10, J, Q, K), and the suit group is (hearts, spades, diamonds, clubs).
Step 4: Determine whether the recognition result is successful.
The condition for successful recognition is to recognize all suits and character combinations. In this example, 13 cards are recognized, so 13 cards must be recognized to be considered successful. Due to the recognition light, angle and other reasons, it is impossible to recognize successfully every time, so the red box should be used to guide the user to align the recognition area. In this way, it can help to align the recognition area, and secondly, it can reduce the size of the calculated image and improve the speed.
So: the result of this example is that the character grouping and suit grouping are all 13 elements to be considered successful, because they are sorted according to the starting position. When 13 characters and 13 suits are determined, then the two sets of data are the correct results of one-to-one correspondence.
8. Process combing
I just started to practice writing, and my experience and writing skills are relatively poor. Here I will review the whole process from collecting samples to image recognition results again.
1. Demand
Recognizing playing cards: Recognizing characters and suits, the big and small kings are not considered here.
2. Collection of samples
2.1. Use Opencv to find Unicom areas
2.2. Convert these Unicom areas into rectangles
2.3. Screen out candidate areas by the size, length and width of the rectangle
2.4. Manual classification, divided into positive samples and negative samples
3. Data collation and identification
3.1 Normalization
Before calculating features, it is necessary to ensure that all samples are of the same size, so that the obtained feature latitudes are the same. This process can be done when collecting samples, that is, resize all samples into pictures of the same size, or when calculating features, first resize to the same size and then calculate features.
3.2 Characterization
Calculate all the samples into feature values and wait for them to be passed into the AI engine
3.3 Recognition
Resize all the candidate areas to a normalized size, then calculate the features, and then apply them to the feature engine for recognition.
Note:
1. The feature algorithm used in this example is the HOG feature, which is not detailed here. Interested students will automatically search and learn
9. End
It takes a lot of time to write an article, but I haven't written it yet, sorry, I turned around and found that many details were not clearly written...
Using deep learning algorithm frameworks, such as Darknet, can also solve problems very well, and is more flexible, but it is absolutely impossible to do real-time on mobile phones, and it is also difficult to recognize such small targets. The important thing is that using DNN for such small things is simply overkill...
It's over...
thank you readers...