Kafka and RocketMQ are currently very popular distributed messaging systems, both of which can efficiently process massive amounts of message data. In this article, we will make a technical comparison between Kafka and RocketMQ, and analyze their advantages and disadvantages in various aspects, so that readers can make more informed decisions when choosing a messaging system.
1. Architecture design
Both Kafka and RocketMQ are message systems based on the publish/subscribe model, but their architectural designs are different.
The architectural design of Kafka is relatively simple, mainly composed of three components: producers, consumers and Kafka clusters. The producer publishes the message to the Broker node in the Kafka cluster, and then the consumer obtains the message from the Broker node for consumption. Kafka's data model is based on Topic and Partition. Each Topic can have multiple Partitions, and each Partition can be replicated on multiple Broker nodes to ensure high data availability.
The architecture design of RocketMQ is relatively complex, mainly composed of three roles: Namesrv, Broker and Producer/Consumer. Namesrv is mainly responsible for service registration and discovery, Broker nodes are responsible for storing and transmitting messages, Producer and Consumer send messages to and obtain messages from Broker nodes respectively. RocketMQ is also a data model based on Topic and Partition, but it uses a master-slave replication mechanism to ensure high availability and fault tolerance of data.
2. Performance comparison
Both Kafka and RocketMQ are high-throughput, low-latency messaging systems, but their performance is also different.
In terms of throughput, Kafka performs even better. Kafka stores messages by sequentially writing to disk, so it can achieve very high write throughput, and it can also achieve very high performance in read. Although RocketMQ also uses sequential writing to disk to store messages, its read performance is slightly inferior to Kafka, especially when pulling messages in batches.
In terms of latency, RocketMQ performs even better. RocketMQ reduces latency by using Zero Copy technology and buffer pool technology, while Kafka improves throughput by batch sending and asynchronous processing, but correspondingly increases a certain delay.
3. Reliability comparison
Both Kafka and RocketMQ are high-reliability messaging systems, but their reliability is also different.
In terms of data reliability, Kafka performs even better. Kafka adopts a multi-copy mechanism. Each Partition has multiple copies. When a Broker node fails, other copies can be used to ensure data availability. RocketMQ uses a master-slave replication mechanism. When the master node fails, master node election is required to ensure data availability, which may cause a certain delay.
In terms of data consistency, Kafka also has better performance. Kafka adopts a distributed coordination mechanism based on Zookeeper, which can ensure the order of data between Producer and Consumer. However, RocketMQ needs to sort the messages on the Producer side before sending them to the Broker node, which may have a certain impact on performance.
In terms of message transactions, RocketMQ performs better than Kafka. RocketMQ provides a complete message transaction mechanism, which can ensure the consistency and reliability of messages in the process of sending and receiving. However, Kafka does not provide official transaction support and needs to be handled by developers themselves.
In terms of failure recovery, Kafka has better performance. Kafka supports automatic failover and data replication mechanisms, which can quickly restore node availability and ensure data continuity. However, RocketMQ requires manual master-slave switching, which may require some manual intervention.
To sum up, both Kafka and RocketMQ have their advantages and disadvantages in terms of reliability. Which one is more suitable needs to be evaluated according to specific application scenarios and needs. ———————————————————————————— Copyright statement: This article is the original article of CSDN blogger "hb13262736769", and follows the CC 4.0 BY-SA copyright agreement. For reprinting, please attach the original source link and this
statement
.
Original link: https://blog.csdn.net/hb13262736769/article/details/130114126
Why kafka latency is higher than rocketmq latency
There is a premise that the delay of Kafka is higher than that of rocketmq. When there are many topics, this is related to the data storage structure of these two MQs. When there are few topics, the delay is basically the same.
Kafka's data storage structure designers try to ensure the throughput as much as possible, so the log log is kept as small as possible during design. Its data structure is as follows, where topic is a logical concept, and the corresponding partition is a physical folder:
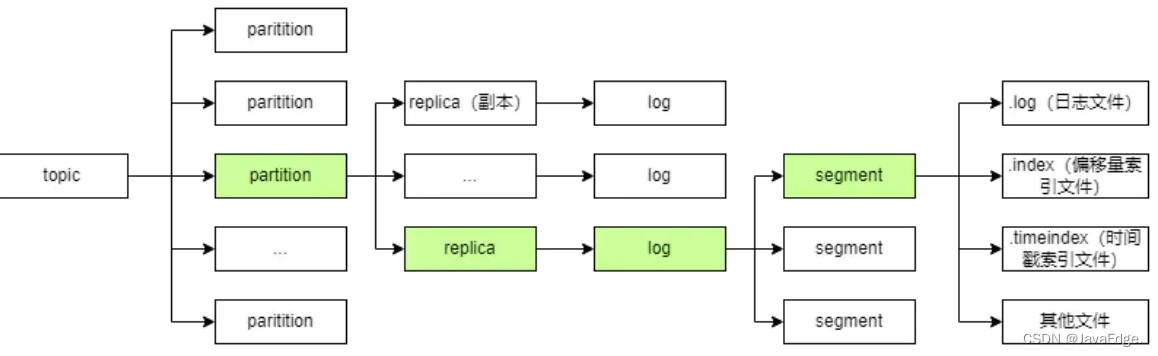
Therefore, when there are many topics, the number of partition files will be very large, and the efficiency of disk sequential read is not as good as that of random read. When there are many topics, sequential disk read will change to random read, and the delay will be high.
That is, kafka performance has a threshold (20) for topic.
Taobao business is more complicated, and there will be more topics. In order to solve this pain point, rockertmq was born and its data storage structure has been optimized. There is only one commit log in the log directory, and the structure is as follows:
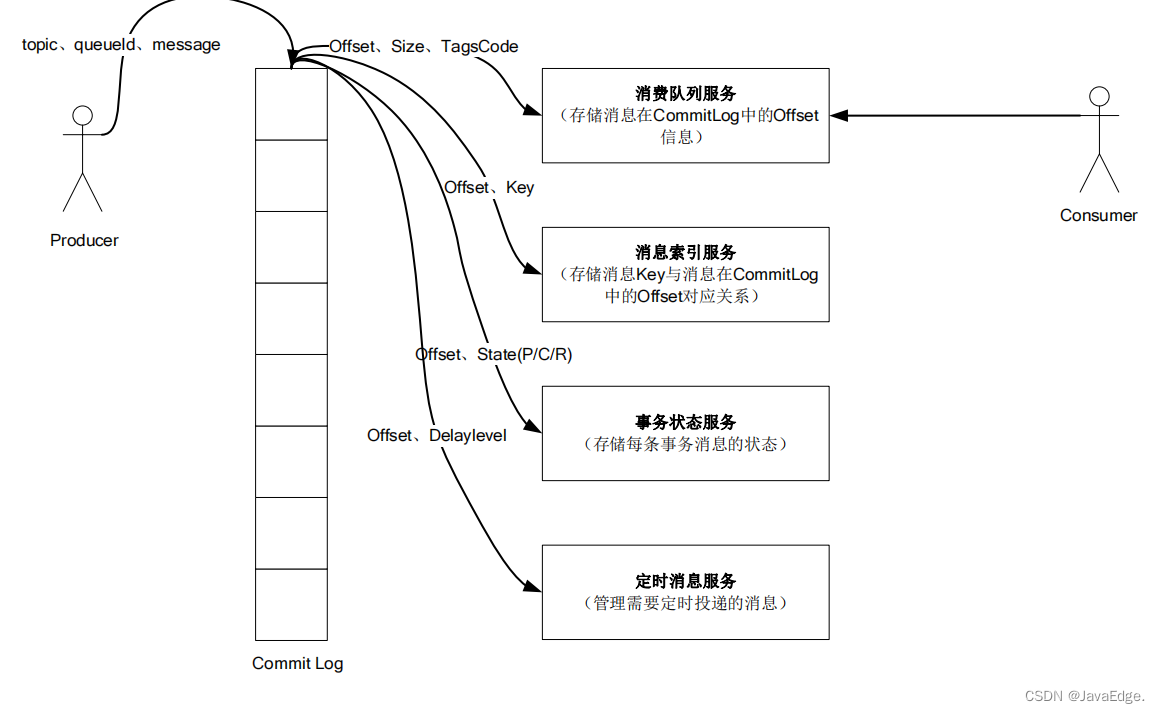
The starting point is different. Kafka's positioning is to process logs and big data . In these business fields, there will not be too many topics, and naturally there will be no delay problems.
The data storage structure is the main reason, and kafka only supports pull mode. And rocketmq has two modes of pull and push (although this push mode is fake push), the delay of push mode is definitely lower than that of pull mode.
The push mode is based on the pull mode. There is a local scheduled thread to pull the broker's message, cache it locally, and then push it to the consumer thread.
The push mode of rabbit is real push, so the one with the lowest delay is the rabbit. Rabbit does not support distributed, but only supports master-slave mode. The design itself is a small and beautiful stand-alone version. CPU consumption is much lower than kafka and the like.