ref
《OpenCL in Action》
"OpenCL Programming Guide"
"OpenCl Heterogeneous Parallel Computing Principle Mechanism and Optimization Practice"
Using OpenCL™ 2.0 Read-Write Images
General introduction





image object
On GPUs, image data is stored in special global memory called texture memory.
Unlike regular global memory, texture memory is cached for rapid access.
Image objects serve as the storage mechanism that host applications use to transfer pixel data to and from a device.
When the device receives the image data, samplers tell it how to read color values.
On the host, image objects are represented by cl_mem structures, and samplers are represented by cl_sampler structures.
On the device, image objects are image2d_t or image3d_t structures, and samplers are sampler_t structures.
All memory objects are represented by the cl_mem data type, and there are no separate
types to distinguish buffer objects from image objects. Instead, to create a buffer object,
you can call clCreateBuffer or clCreateSubBuffer. To create an image object, you can
call clCreateImage2d or clCreateImage3d.

cl_mem clCreateImage2D(
cl_context context,
cl_mem_flags flags,
const cl_image_format* image_format,
size_t image_width,
size_t image_height,
size_t image_row_pitch,
void* host_ptr,
cl_int* errcode_ret);
cl_mem clCreateImage3D(
cl_context context,
cl_mem_flags flags,
const cl_image_format* image_format,
size_t image_width,
size_t image_height,
size_t image_depth,
size_t image_row_pitch,
size_t image_slice_pitch,
void* host_ptr,
cl_int* errcode_ret);
clReleaseMemObject(image).'clCreateImage2D': was declared deprecated".
>=1.2 version becomes clCreateImage
A 1D image, 1D image buffer, 1D image array, 2D image, 2D image array and 3D image object can be created using the following function
cl_mem clCreateImage(
cl_context context,
cl_mem_flags flags,
const cl_image_format* image_format,
const cl_image_desc* image_desc,
void* host_ptr,
cl_int* errcode_ret);
clReleaseMemObject(image).
typedef struct _cl_image_format {
cl_channel_order image_channel_order;
cl_channel_type image_channel_data_type;
} cl_image_format;
typedef struct cl_image_desc {
cl_mem_object_type image_type;
size_t image_width;
size_t image_height;
size_t image_depth;
size_t image_array_size;
size_t image_row_pitch;
size_t image_slice_pitch;
cl_uint num_mip_levels;
cl_uint num_samples;
#ifdef __GNUC__
__extension__ /* Prevents warnings about anonymous union in -pedantic builds */
#endif
union {
cl_mem buffer;
cl_mem mem_object;
};
} cl_image_desc;image_channel_order与image_channel_data_type :
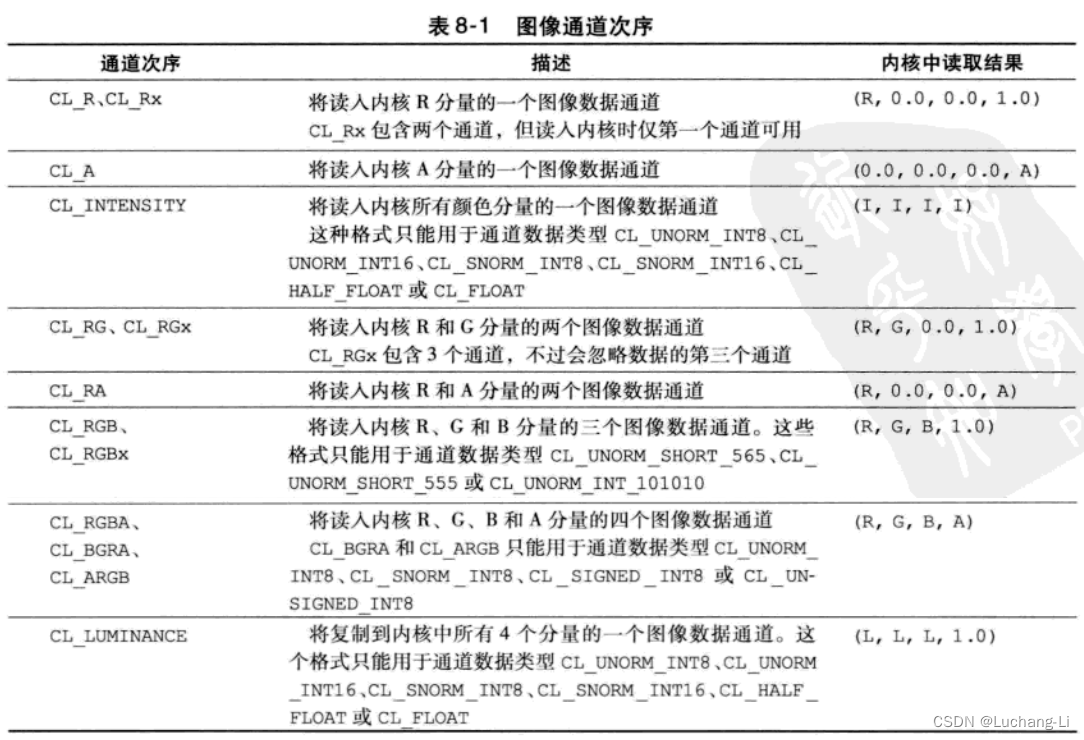

Query image format support


As an example, the following code initializes a cl_image_format structure whose
pixels are formatted according to the 24-bit RGB format:
cl_image_format rgb_format;
rgb_format.image_channel_order = CL_RGB;
rgb_format.image_channel_data_type = CL_UNSIGNED_INT8;The final arguments in clCreateImage2D and clCreateImage3D relate to the dimensions of the image object and the number of bytes per dimension, also called pitch. Each dimension is given in pixels, and figure 3.2 presents the dimensions of a three-dimensional image object. The individual two-dimensional components are called slices.
In most images, you can determine how many bytes are in a row by multiplying bytes-per-pixel by pixels-per-row. But this won’t work if the rows contain trailing bits or if the rows need to be aligned on memory boundaries. For this reason, both clCreateImage2D and clCreateImage3D accept a row_pitch argument that identifies how many bytes are in each row. Similarly, clCreateImage3D accepts a slice_pitch argument that identifies the number of bytes in each two-dimensional image, or slice.
If row_pitch is set to 0, OpenCL will assume its value equals width * (pixel size). If slice_pitch is set to 0, its value will be set to row_pitch * height.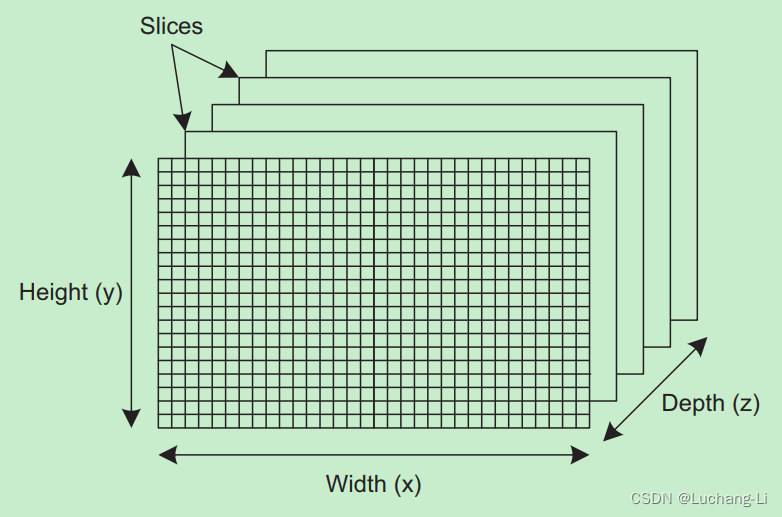
copy data between memory objects
clEnqueueReadBuffer // Reads data from a buffer object to host memory
clEnqueueWriteBuffer // Writes data from host memory to a buffer object
clEnqueueReadImage // Reads data from an image object to host memory
clEnqueueWriteImage // Writes data from host memory to an image object
void* clEnqueueMapBuffer // Maps a region of a buffer object to host memory
void* clEnqueueMapImage // Maps a rectangular region of an image object to host memory
int clEnqueueUnmapMemObject // Unmaps an existing memory object from host memory
clEnqueueCopyBuffer // Copies data from a source buffer object to a destination buffer object
clEnqueueCopyImage // Copies data from a source image object to a destination image object
clEnqueueCopyBufferToImage // Copies data from a source buffer object to a destination image object
clEnqueueCopyImageToBuffer // Copies data from a source image object to a destination buffer object
Sampler Sampler


Samplers can be created by the host application or within the kernel. Host applications create cl_sampler objects by calling clCreateSampler, whose signature is as follows:
cl_sampler clCreateSampler(cl_context context, cl_bool normalized_coords,
cl_addressing_mode addressing_mode, cl_filter_mode filter_mode, cl_int *errcode_ret)Numerical operations rather than image processing should use
cl_sampler clCreateSampler(context, /*normalized_coords*/ false,
/*addressing_mode*/ CL_ADDRESS_CLAMP, /*filter_mode*/ CL_FILTER_NEAREST, &errcode)
clReleaseSampler()Set the kernel image parameter
clSetKernelArg(image_knl, 0, sizeof(cl_mem), &image);
clSetKernelArg(kernel, 0, sizeof(cl_sampler), &ex_sampler);
Create a sampler example in the device kernel:
__constant sampler_t sampler = CLK_NORMALIZED_COORDS_FALSE | CLK_ADDRESS_CLAMP | CLK_FILTER_NEAREST;
CL Kernel's operation on images
In OpenCL 1.2 and earlier, images were qualified with the “__read_only” and __write_only” qualifiers. In the OpenCL 2.0, images can be qualified with a “__read_write” qualifier, and copy the output to the input buffer. This reduces the number of resources that are needed.
OpenCL provides a number of image processing functions that can be run inside kernels, and they fall into three categories:
■ Read functions—Return color values at a given coordinate
■ Write functions—Set color values at a given coordinate
■ Information functions—Provide data about the image object, such as its dimensions and pixel properties
half4 read_imageh(image2d_t image, sampler_t sampler, int2 coord);
half4 read_imageh(image2d_t image, sampler_t sampler, float2 coord);
void write_imageh(image2d_t image, int2 coord, half4 color);For the forms that take an image3d_t, use the coordinate (coord.x, coord.y, coord.z) to do an element lookup in the 3D image object specified by image. coord.w is ignored.
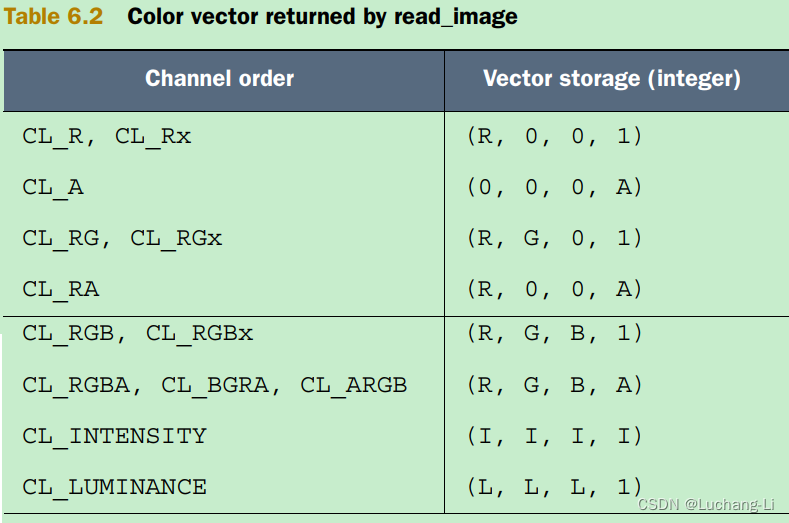
read_imagef returns floating-point values for image objects created with image_channel_data_type set to CL_HALF_FLOAT or CL_FLOAT.
The read_imagef calls that take integer coordinates must use a sampler with filter mode set to CLK_FILTER_NEAREST, normalized coordinates set to CLK_NORMALIZED_COORDS_FALSE and addressing mode set to CLK_ADDRESS_CLAMP_TO_EDGE, CLK_ADDRESS_CLAMP or CLK_ADDRESS_NONE; otherwise the values returned are undefined.

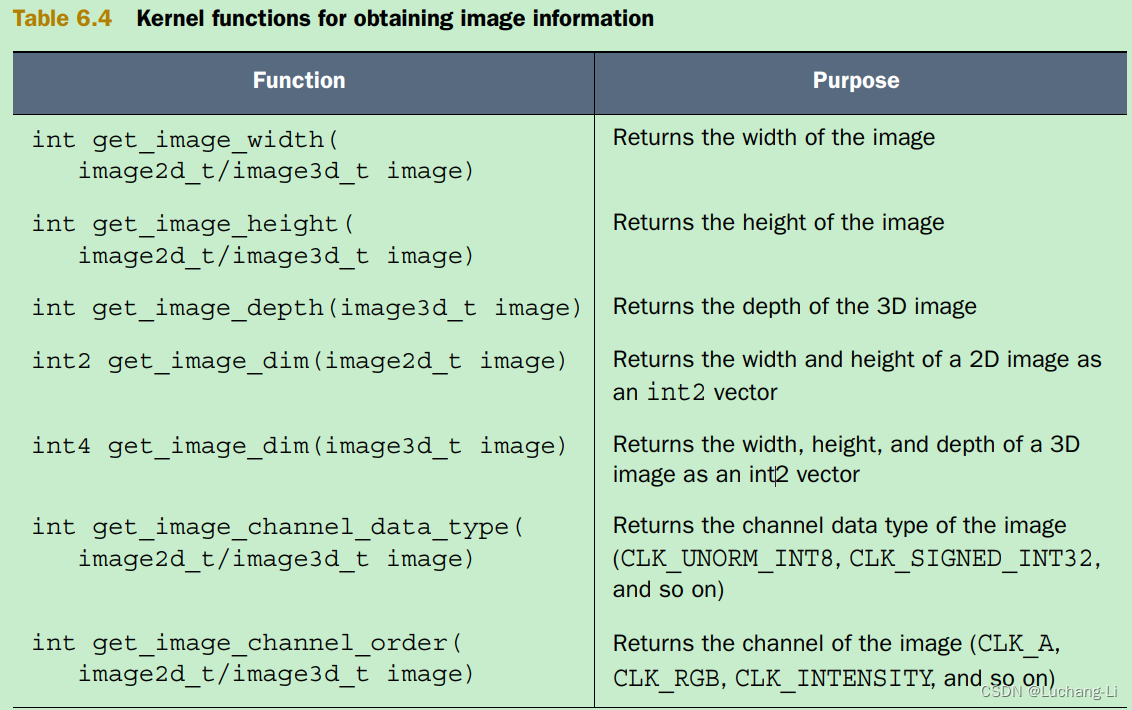
Gaussian Blur Kernel in OpenCL 2.0
__kernel void GaussianBlurDualPass(__read_only image2d_t inputImage, __read_write image2d_t tempRW,
__write_only image2d_t outputImage, __constant float* mask, int maskSize) {
int2 currentPosition = (int2)(get_global_id(0), get_global_id(1));
float4 currentPixel = (float4)(0, 0, 0, 0);
float4 calculatedPixel = (float4)(0, 0, 0, 0);
currentPixel = read_imagef(inputImage, currentPosition);
for (int maskIndex = -maskSize; maskIndex < maskSize + 1; ++maskIndex) {
currentPixel = read_imagef(inputImage, currentPosition + (int2)(maskIndex, 0));
calculatedPixel += currentPixel * mask[maskSize + maskIndex];
}
write_imagef(tempRW, currentPosition, calculatedPixel);
barrier(CLK_GLOBAL_MEM_FENCE);
for (int maskIndex = -maskSize; maskIndex < maskSize + 1; ++maskIndex) {
currentPixel = read_imagef(tempRW, currentPosition + (int2)(0, maskIndex));
calculatedPixel += currentPixel * mask[maskSize + maskIndex];
}
write_imagef(outputImage, currentPosition, calculatedPixel);
}
opencl image deep learning operator development
The difference between opencl's use of images and buffers for numerical calculations and the development of deep learning operators:
The buffer is consistent with the linear memory in the conventional understanding, and the development method is very close to the NV GPU CUDA development method, making operator development easier. The image is obviously more complicated and has many restrictions. For example, there are only 1D, 2D, and 3D images, because different operators have different dimensions and indexing methods, and even the same operator has different dimensions and indexing methods. This requires us to separate Use a different image for processing, not even image processing. In addition, the image needs to process four components at the same time, which also brings some complexity to the operator development dimension processing.
In addition, it is often said that the performance of image on arm gpu is worse than that of buffer, so image has poor compatibility with different devices.
A better solution is to use buffer as the main memory model, and then use image to accelerate specific operators on Qualcomm adreno gpu, such as matrix multiplication and convolution. For arm mali gpu, buffer memory is used uniformly.
Use image2d to do two [1024,1024] matrix addition cases:
#include <iostream>
#include <memory>
#include <string>
#include <vector>
#include "mem_helper.h"
#define CL_HPP_TARGET_OPENCL_VERSION 300
#include <CL/opencl.hpp>
using DTYPE = half;
std::string kernel_source{R"(
#pragma OPENCL EXTENSION cl_khr_fp16 : enable
__constant sampler_t sampler = CLK_NORMALIZED_COORDS_FALSE | CLK_ADDRESS_CLAMP | CLK_FILTER_NEAREST;
kernel void vecAdd(read_only image2d_t img_a, read_only image2d_t img_b, __write_only image2d_t img_c,
const unsigned int n) {
int gid_x = get_global_id(0);
int gid_y = get_global_id(1);
int2 coord = (int2)(gid_x, gid_y);
half4 data_a = read_imageh(img_a, sampler, coord);
half4 data_b = read_imageh(img_b, sampler, coord);
half4 data_c = data_a + data_b;
write_imageh(img_c, coord, data_c);
}
)"};
int main() {
std::vector<cl::Platform> platforms;
cl::Platform::get(&platforms);
std::cout << "get platform num:" << platforms.size() << std::endl;
cl::Platform plat;
for (auto& p : platforms) {
std::string platver = p.getInfo<CL_PLATFORM_VERSION>();
if (platver.find("OpenCL 2.") != std::string::npos || platver.find("OpenCL 3.") != std::string::npos) {
// Note: an OpenCL 3.x platform may not support all required features!
plat = p;
}
}
if (plat() == 0) {
std::cout << "No OpenCL 2.0 or newer platform found.\n";
return -1;
}
std::cout << "platform name:" << plat.getInfo<CL_PLATFORM_NAME>() << std::endl;
cl::Platform newP = cl::Platform::setDefault(plat);
if (newP != plat) {
std::cout << "Error setting default platform.\n";
return -1;
}
// get default device (CPUs, GPUs) of the default platform
std::vector<cl::Device> all_devices;
newP.getDevices(CL_DEVICE_TYPE_GPU, &all_devices); // CL_DEVICE_TYPE_ALL
std::cout << "get all_devices num:" << all_devices.size() << std::endl;
if (all_devices.size() == 0) {
std::cout << " No devices found. Check OpenCL installation!\n";
exit(1);
}
// cl::Device default_device = cl::Device::getDefault();
cl::Device default_device = all_devices[0];
std::cout << "device name: " << default_device.getInfo<CL_DEVICE_NAME>() << std::endl;
std::cout << "device CL_DEVICE_LOCAL_MEM_SIZE: " << default_device.getInfo<CL_DEVICE_LOCAL_MEM_SIZE>() << std::endl;
cl::Context context({default_device});
int queue_properties = 0;
queue_properties |= CL_QUEUE_PROFILING_ENABLE;
cl::CommandQueue queue(context, default_device, queue_properties);
const int height = 1024;
const int width = 1024;
const int width_d4 = width / 4;
int img_size = height * width_d4;
vector<int> shape1 = {height, width};
vector<int> shape2 = {height, width};
vector<int> shape3 = {height, width};
MemoryHelper<DTYPE> h_a(shape1);
MemoryHelper<DTYPE> h_b(shape1);
MemoryHelper<DTYPE> h_c(shape3);
h_a.StepInit(0.001f);
h_b.StepInit(0.002f);
memset(h_c.Mem(), 0, h_c.bytes);
cl_int error;
cl_image_format image_format;
image_format.image_channel_order = CL_RGBA;
image_format.image_channel_data_type = CL_HALF_FLOAT;
cl_image_desc image_desc = {0};
image_desc.image_type = CL_MEM_OBJECT_IMAGE2D;
image_desc.image_width = width;
image_desc.image_height = height;
image_desc.image_row_pitch = 0;
cl_mem img_a =
clCreateImage(context.get(), CL_MEM_READ_WRITE | CL_MEM_ALLOC_HOST_PTR, &image_format, &image_desc, NULL, &error);
cl_mem img_b =
clCreateImage(context.get(), CL_MEM_READ_WRITE | CL_MEM_ALLOC_HOST_PTR, &image_format, &image_desc, NULL, &error);
cl_mem img_c =
clCreateImage(context.get(), CL_MEM_READ_WRITE | CL_MEM_ALLOC_HOST_PTR, &image_format, &image_desc, NULL, &error);
if (error != CL_SUCCESS) {
printf("clCreateImage failed\n");
}
array<size_t, 3> region;
array<size_t, 3> origin;
origin[0] = 0;
origin[1] = 0;
origin[2] = 0;
region[0] = width_d4;
region[1] = height;
region[2] = 1;
error |=
clEnqueueWriteImage(queue.get(), img_a, CL_TRUE, origin.data(), region.data(), 0, 0, h_a.Mem(), 0, NULL, NULL);
error |=
clEnqueueWriteImage(queue.get(), img_b, CL_TRUE, origin.data(), region.data(), 0, 0, h_b.Mem(), 0, NULL, NULL);
error |=
clEnqueueWriteImage(queue.get(), img_c, CL_TRUE, origin.data(), region.data(), 0, 0, h_c.Mem(), 0, NULL, NULL);
if (error != CL_SUCCESS) {
printf("clEnqueueWriteImage failed\n");
}
std::vector<std::string> programStrings;
programStrings.push_back(kernel_source);
cl::Program program(context, programStrings);
if (program.build({default_device}, "-cl-std=CL3.0") != CL_SUCCESS) {
std::cout << "Error building: " << program.getBuildInfo<CL_PROGRAM_BUILD_LOG>(default_device) << std::endl;
exit(1);
}
cl::Kernel cl_kernel(program, "vecAdd");
int arg_pos = 0;
error |= cl_kernel.setArg(arg_pos++, sizeof(cl_mem), &img_a);
error |= cl_kernel.setArg(arg_pos++, sizeof(cl_mem), &img_b);
error |= cl_kernel.setArg(arg_pos++, sizeof(cl_mem), &img_c);
error |= cl_kernel.setArg(arg_pos++, sizeof(int), &width_d4);
if (error != CL_SUCCESS) {
printf("setArg failed\n");
}
int local_size_x = std::min(width_d4, 32);
int local_size_y = std::min(height, 16);
cl::NDRange global_size(width_d4, height);
cl::NDRange local_size(local_size_x, local_size_y);
int warmup_num = 50;
int eval_num = 50;
for (int i = 0; i < warmup_num; i++) {
queue.enqueueNDRangeKernel(cl_kernel, cl::NullRange, global_size, local_size, NULL, NULL);
}
queue.finish();
float total_time = 0.0f;
for (int i = 0; i < eval_num; i++) {
cl::Event event;
cl_int err = queue.enqueueNDRangeKernel(cl_kernel, cl::NullRange, global_size, local_size, NULL, &event);
if (err != CL_SUCCESS) {
printf("enqueueNDRangeKernel failed\n");
}
event.wait();
cl_ulong start_time, end_time; // time in ns
cl_int err1 = event.getProfilingInfo(CL_PROFILING_COMMAND_START, &start_time);
cl_int err2 = event.getProfilingInfo(CL_PROFILING_COMMAND_END, &end_time);
float exec_time = (end_time - start_time) / 1000.0f;
total_time += exec_time;
}
queue.finish();
printf("mean exec time: %f us ----------\n", total_time / eval_num);
error |=
clEnqueueReadImage(queue.get(), img_c, CL_TRUE, origin.data(), region.data(), 0, 0, h_c.Mem(), 0, NULL, NULL);
if (error != CL_SUCCESS) {
printf("clEnqueueWriteImage failed\n");
}
h_a.PrintElems(1, 256);
h_c.PrintElems(1, 256);
clReleaseMemObject(img_a);
clReleaseMemObject(img_b);
clReleaseMemObject(img_c);
return 0;
}
Compared with the buffer-based vector add version, the Qualcomm 888 processor image2d version is 10% slower than the buffer version, which shows that not all applications of Qualcomm GPU are faster than image than buffer. The difference between vecadd and image processing here may be that one thread only reads the data of one pixel, and the advantage of image cache is not reflected.
In the scene where each thread needs to read data from multiple adjacent positions when multiplied by the convolution kernel matrix, image may be better than buffer. In fact, this is indeed the case. The author implemented the matrix multiplication of 8x1x1x4 thread tiles based on buffer and image. The image version is 10%-15% faster than the buffer version.
image1d_buffer_t
A 1D image created from a buffer object. See individual Image Functions for more information.
void write_imagef(image1d_buffer_t image, int coord, float4 color);
float4 read_imagef(read_write image1d_buffer_t image, int coord);
Image1DBuffer(
const Context& context,
cl_mem_flags flags,
ImageFormat format,
size_type width,
const Buffer &buffer,
cl_int* err = NULL)