What is a neural network?
Artificial neural network (ANN), referred to as neural network (NN) or neural network, is a subset of machine learning and the core of deep learning algorithms. It is a mathematical model or computational model that imitates the structure and function of biological neural networks, and is used to estimate or approximate functions.
An artificial neural network (ANN) consists of layers of nodes, including an input layer, one or more hidden layers, and an output layer. Each node is also called an artificial neuron and they are connected to another node with associated weights and thresholds. If the output of any single node is above a specified threshold, that node is activated and the data is sent to the next layer of the network. Otherwise, the data is not passed to the next layer of the network.
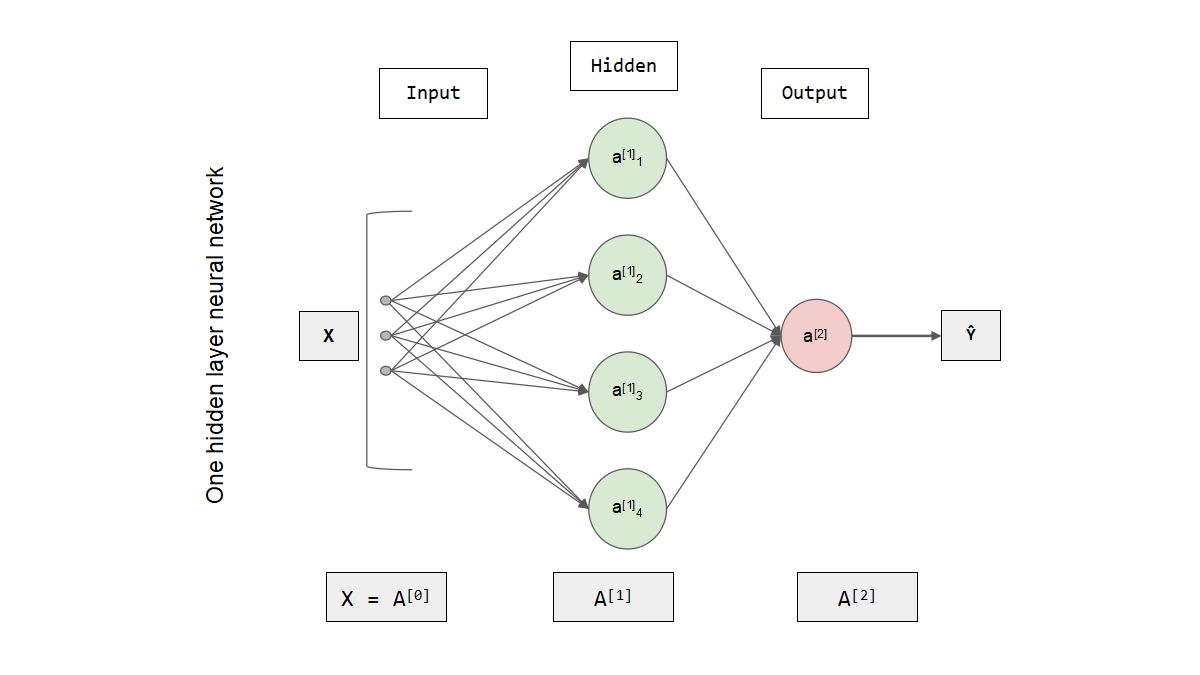
Neural networks rely on training data to learn and improve their accuracy over time. And once these learning algorithms are tuned to improve accuracy, they become powerful tools in computer science and artificial intelligence, allowing us to quickly classify and cluster data. Compared to manual recognition performed by human experts, speech recognition or image recognition tasks may take minutes rather than hours.
Neural Networks and Neurons
A neuron usually has multiple dendrites, which are mainly used to receive incoming information; while there is only one axon, and there are many axon terminals at the end of the axon that can transmit information to other neurons. The axon terminal connects with the dendrites of other neurons to transmit signals. The location of this connection is called a "synapse" in biology.
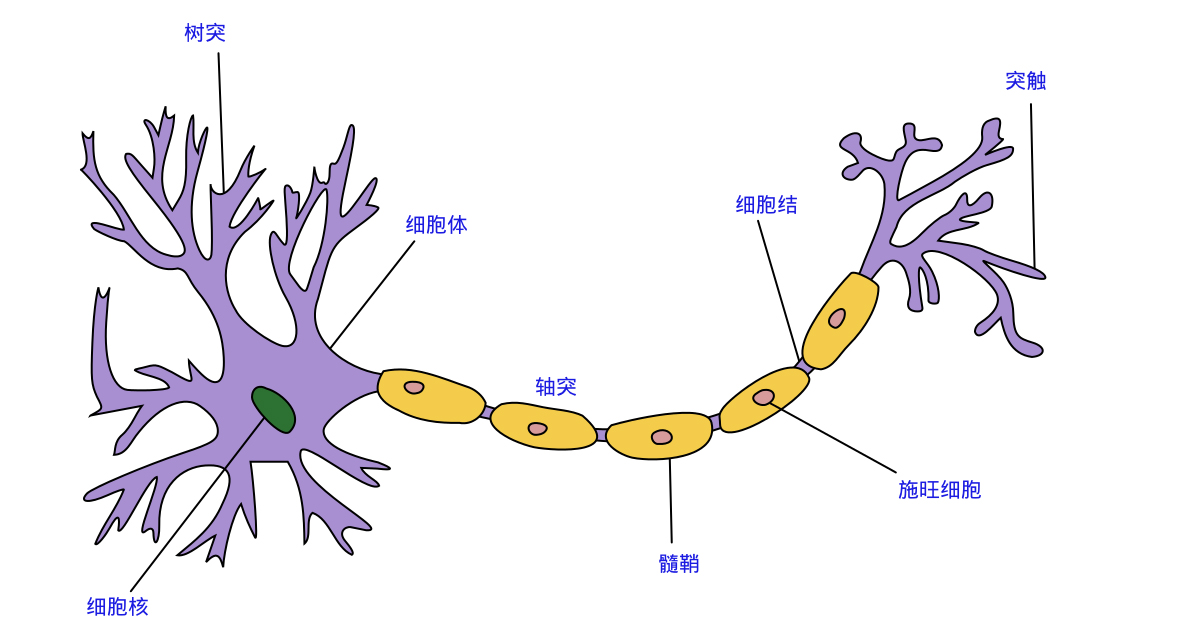
The most basic constituent element of a neural network is a neuron (Neuron), which is a simple unit in Kohonen's definition. If a neuron receives enough neurotransmitter (acetylcholine), its point becomes high enough to exceed a certain threshold (Threshold). After exceeding this threshold, the neuron becomes activated, reaches an excited state, and then sends neurotransmitters to other neurons.
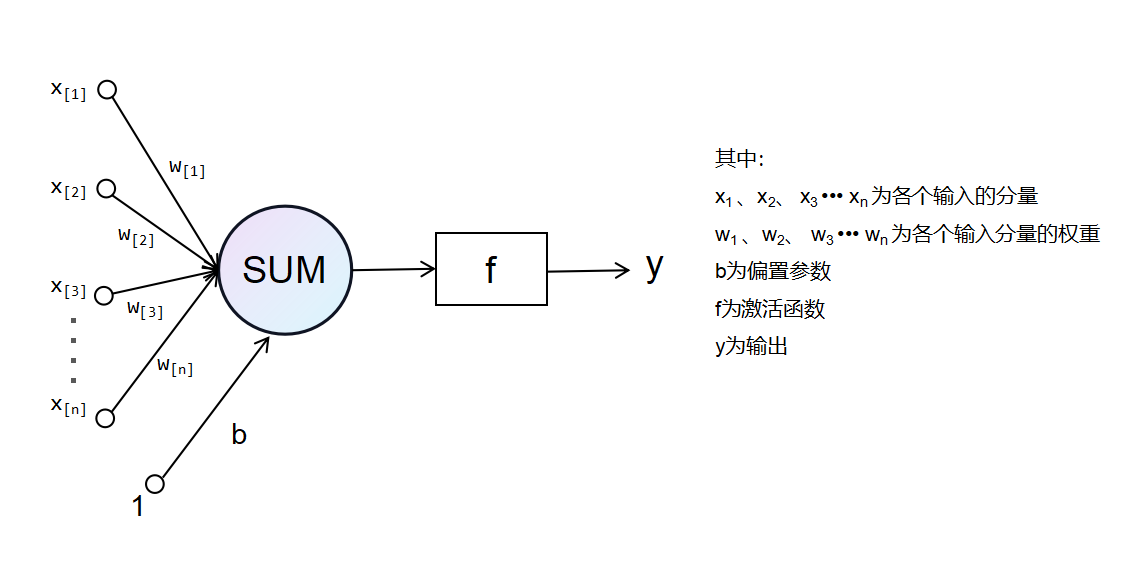
A simple neuron model is shown below:
The mathematical formula is expressed as:
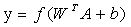
The function of a neuron is to obtain a scalar result through a nonlinear transfer function after obtaining the inner product of the input vector and the weight vector.
Types of Neural Networks
Neural network is an algorithmic model widely used in the fields of machine learning and deep learning. It has many types, each with different structures and applications. Here are some common types of neural networks:
-
Feedforward Neural Network (Feedforward Neural Network): Feedforward neural network is the most basic type of neural network. Information is transmitted in one direction in the network without cyclic connections. It consists of an input layer, several hidden layers, and an output layer to solve classification and regression problems.
-
Convolutional Neural Network (CNN): Convolutional neural networks are mainly used in image and vision tasks, and image features are extracted through convolutional layers and pooling layers. CNNs can effectively process spatially structured data and perform well in tasks such as image classification, object detection, and image generation.
-
Recurrent Neural Network (RNN): Recurrent neural network is a type of neural network with recurrent connections, which is mainly used to process sequence data, such as natural language processing, speech recognition, etc. RNN has the ability of memory to capture the contextual information in the sequence.
-
Long Short-Term Memory (LSTM): LSTM is a special type of recurrent neural network used to solve the gradient disappearance and gradient explosion problems in traditional RNN. It has better long-term dependency modeling capabilities and is widely used in sequence modeling tasks.
-
Generative Adversarial Network (GAN): The Generative Adversarial Network consists of a generator and a discriminator, and learns to generate realistic data samples through confrontation training. GAN has achieved remarkable results in areas such as image generation, image inpainting, and text generation.
-
Autoencoder: Autoencoder is an unsupervised learning neural network for data compression and feature extraction. It consists of an encoder and a decoder to learn a low-dimensional representation of the input data by minimizing the reconstruction error.
The above only lists some common types of neural networks. In fact, there are many other variants and extensions, such as Residual Network (ResNet), Variational Autoencoder (Variational Autoencoder, VAE), etc. Choosing the type of neural network suitable for a specific task requires evaluation and decision-making based on the nature of the problem and the characteristics of the data.
How Artificial Neural Networks Work
An artificial neural network is a computational model inspired by biological nervous systems, which consists of a large number of artificial neurons (also known as nodes or units), and simulates the interaction between neurons by connecting weights. Here is an example of a house price prediction:
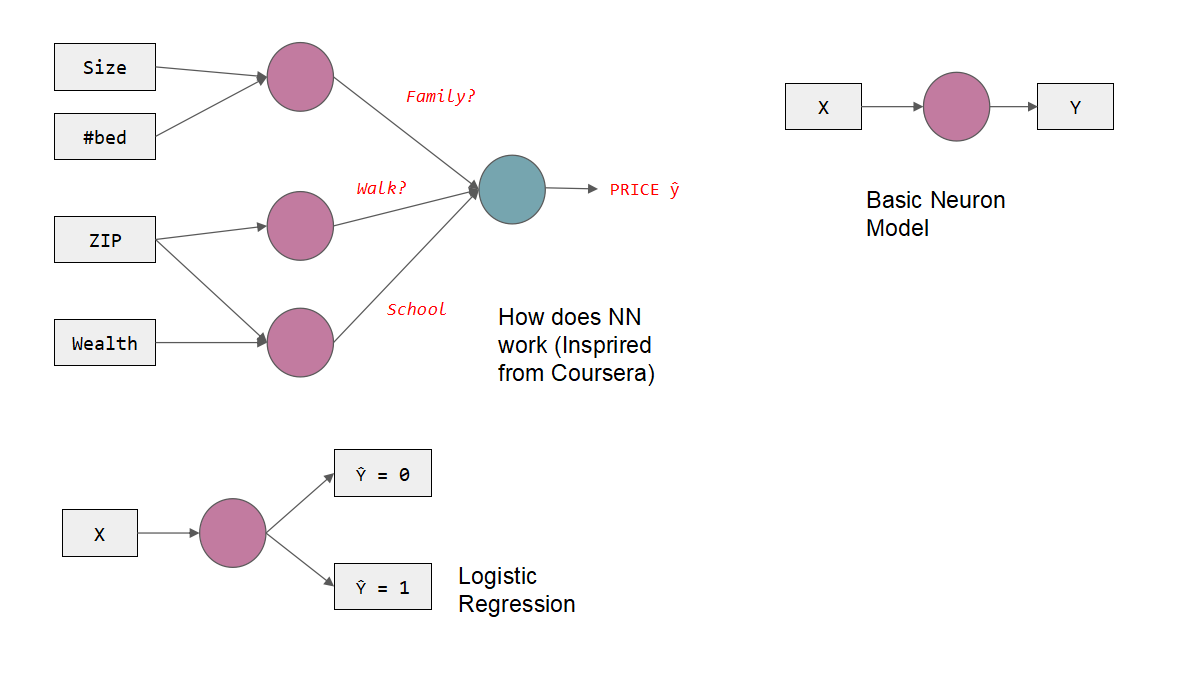
1. Represent the input data as a feature vector
Each house can be represented by a feature vector, where each feature corresponds to a value of an influencing factor. For example, suppose we have a dataset with 100 samples, and the feature vector for each sample is as follows:
size #bed ZIP Wealth
1500 3 12345 80000
2000 4 23456 90000
...
2. Define the structure of the neural network
Suppose we choose a feed-forward neural network with one or more hidden layers. The number of neurons in the input layer depends on the dimension of the feature vector (4 in this example), and the number of neurons in the output layer is 1 because we want to predict a continuous house price.
3. Initialize the weights and biases of the neural network
These parameters are randomly initialized and then optimized through the training process.
4. Forward propagation
We feed the feature vector into the input layer of the neural network. Each neuron computes a weighted sum based on the input, weight, and bias terms, and passes the result through an activation function for nonlinear transformation. In this way, the signal is passed to the output layer layer by layer, and finally a continuous prediction result is obtained, indicating the price of the house.
5. Measuring the difference between the forecast and the real house price
Use a loss function to measure the difference between the predicted value and the real house price For example, you can use mean square error as a loss function to measure the difference between the predicted value and the true value.
6. Back propagation process
We compute the gradient of the loss function for each parameter (weight and bias term) in the network. Then, using an optimization algorithm such as gradient descent, the loss function is minimized by adjusting the values of the parameters. This process will gradually adjust the parameters of the network so that the network can better adapt to the training data.
7. Repeat forward and back propagation
Forward and backpropagation are repeated until a predetermined number of training iterations is reached or a stopping criterion is met. After the training is complete, we can use the trained neural network to predict the price of new houses.
Note: For training and prediction accuracy, it may be necessary to normalize or normalize the input features so that they are in the same scale range.
Here is a simple example showing a neural network in action on a house price prediction problem. Note that there may be more complex network structures and more techniques and tricks in practical applications to improve the performance and generalization ability of the model. The following is a sample code to implement a simple neural network for house price prediction using the Python programming language and the TensoFlow deep learning library:
import tensorflow as tf
import numpy as np
# 定义输入特征的维度
input_dim = 4
# 定义训练数据和标签
train_data = np.array([[1500, 3, 12345, 80000],
[2000, 4, 23456, 90000],
# 其他训练样本...
], dtype=np.float32)
train_labels = np.array([[250000],
[300000],
# 其他训练标签...
], dtype=np.float32)
# 创建模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(8, activation='relu', input_shape=(input_dim,)), # 隐藏层
tf.keras.layers.Dense(1) # 输出层
])
# 定义损失函数和优化器
loss_fn = tf.keras.losses.MeanSquaredError()
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
# 编译模型
model.compile(optimizer=optimizer, loss=loss_fn)
# 训练模型
num_epochs = 1000 # 训练迭代次数
model.fit(train_data, train_labels, epochs=num_epochs, verbose=0)
# 使用模型进行预测
test_data = np.array([[1800, 3, 23456, 85000],
[2200, 4, 34567, 95000],
# 其他测试样本...
], dtype=np.float32)
predictions = model.predict(test_data)
# 打印预测结果
for i, pred in enumerate(predictions):
print('Test sample {}: Predicted price: {:.2f}'.format(i+1, pred[0]))
History of Neural Networks
The history of neural networks dates back to the 1940s and 1950s. The following are some important milestones in the development of neural networks:
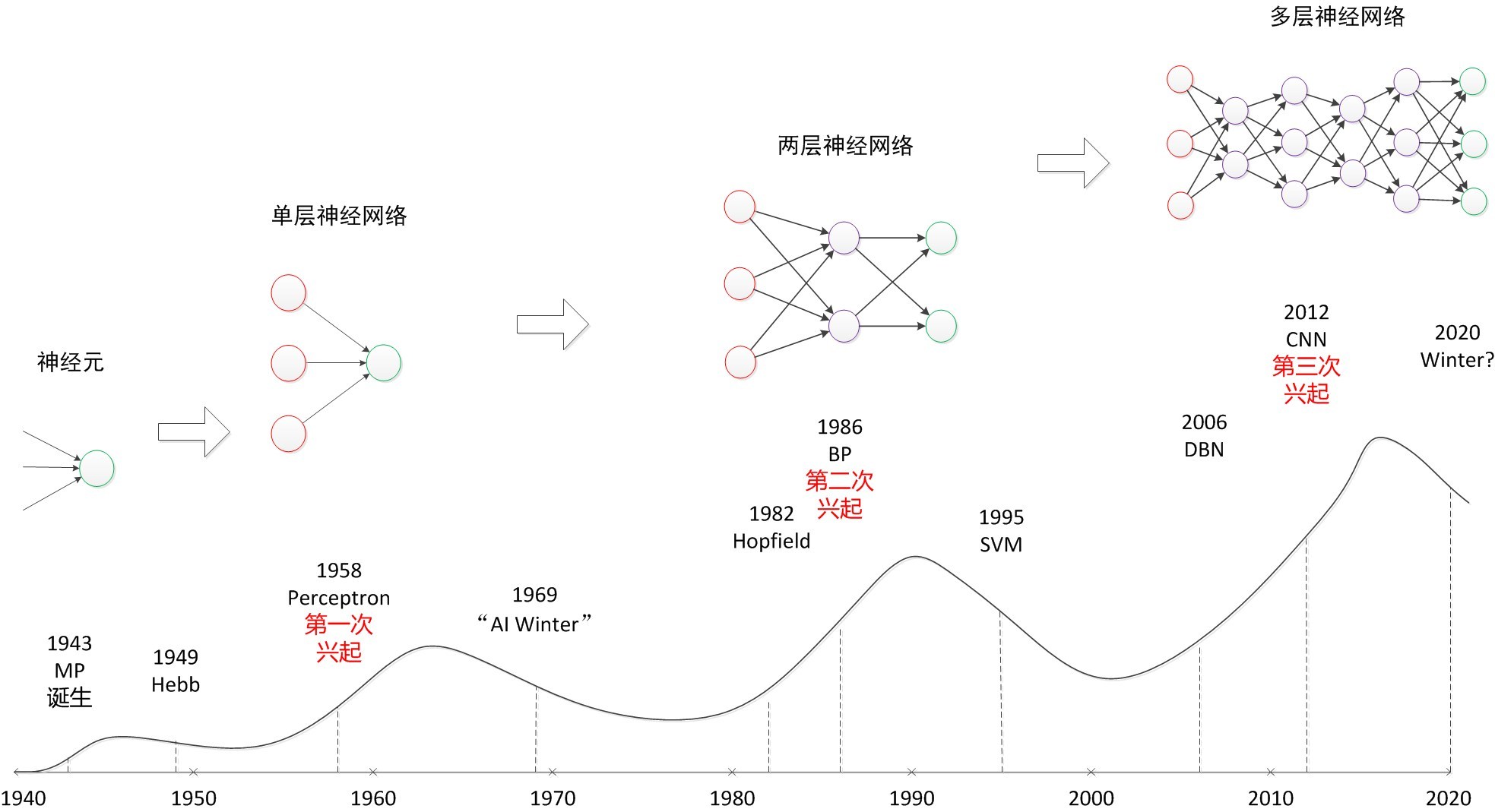
The Perceptron Model (1957)
The perceptron proposed by Frank Rosenblatt is one of the earliest neural network models. It is a binary linear classifier based on a neuron model, capable of classifying samples based on input features.
Multilayer Perceptron (1960s-1970s)
Due to the limitations of single-layer perceptrons, Marvin Minsky and Seymour Papert pointed out the limitations of single-layer perceptrons in the book "Perceptrons". However, before the 1980s, multi-layer perceptron training was not easy due to limitations in computing power and training algorithms.
Backpropagation Algorithm (1986)
David Rumelhart, Geoffrey Hinton, and Ronald Williams et al. proposed the backpropagation algorithm in a paper published in 1986, which made the training of multi-layer perceptrons possible. The backpropagation algorithm adjusts the weights and biases of the network based on the training data by efficiently computing gradients and propagating them back to the network.
The Rise of Support Vector Machines (SVM) (1990s)
In the 1990s, support vector machines (SVM) became a popular method in the field of machine learning. Compared with neural networks, SVM has stronger theoretical support and better generalization ability, and has attracted widespread attention for a period of time.
The renaissance of deep learning (2000s onwards)
Neural networks experienced a renaissance after the 2000s, as computing power increased, data volumes increased, and algorithms improved. The rise of deep learning has enabled neural networks to model at deeper levels and solve more complex problems. Variants such as Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) have been widely used in fields such as computer vision, natural language processing, and speech recognition, and have achieved many breakthrough results.
Application and development of deep learning (after 2010s)
After the 2010s, deep learning has made remarkable progress in various fields. Neural networks are widely used in tasks such as image recognition, speech recognition, natural language processing, and recommendation systems, and surpass traditional machine learning methods in many ways.
In general, the development of neural networks has gone through multiple stages, from the earliest perceptrons to multi-layer perceptrons, and then to the introduction of backpropagation algorithms, these milestones have promoted the development of neural networks. Then, the rise of support vector machines temporarily reduced the popularity of neural networks, but after the 2000s, with the revival of deep learning, neural networks became mainstream again. The development of deep learning enables neural networks to build deeper models and solve more complex problems.
In addition, the availability of large-scale data sets and the improvement of computing power have also promoted the application and development of neural networks. By using more data to train a neural network, the performance and generalization of the model can be improved. At the same time, with the emergence of graphics processing units (GPUs) and dedicated neural network accelerators (such as TPUs), the training and inference process of neural networks has been accelerated.
Today, neural networks are one of the most important technologies in the field of machine learning and artificial intelligence. It has achieved many breakthroughs in the fields of computer vision, natural language processing, speech recognition, recommendation system, etc., and has demonstrated powerful capabilities in many practical applications. As technology continues to advance, the development of neural networks will continue and provide more possibilities for future artificial intelligence.