BlendMask training based on Detectron2 & AdelaiDet BlendMask environment configuration COCO dataset
Blog reference: https://blog.csdn.net/weixin_43796496/article/details/125179243
Blog reference: https://blog.csdn.net/weixin_43823854/article/details/108980188
The training data is: competition data set
The configuration environment is: windows environment pytorch1.10.0 cuda11.3 graphics card GTX 1650S single card
1. Download Detectron2
Search for BlendMask on github, and the interface that appears is AdelaiDet.
AdelaiDet is based on Detectron2 and can contain multiple instance-level recognition tasks. Open source toolbox, so it can also be regarded as an extension plug-in of Detectron2. BlendMask is also one of the tasks belonging to AdelaiDet.
2. Configuration steps
1. Basic environment configuration
Type in terminal
conda create -n detectron2 python=3.8 #创建虚拟环境
conda activate detectron2 #激活虚拟环境
nvcc --sersion #查看cuda版本
For detailed configuration, please refer to Pytorch environment configuration
2. Install Detectron2
Follow the official installation steps to install
the basic requirements
Official document
https://github.com/facebookresearch/detectron2/blob/main/INSTALL.md
Download Detectron2 related code
git clone https://github.com/facebookresearch/detectron2.git #用git下载代码
python -m pip install -e detectron2 #安装detectron2
If there is a problem, refer to the blog https://blog.csdn.net/iracer/article/details/125755029
3. Install AdelaiDet
under windows
git clone https://github.com/aim-uofa/AdelaiDet.git
cd AdelaiDet
python setup.py build develop
If you're using docker, a prebuilt image is available:
docker pull tianzhi0549/adet:latest
If the torch version is greater than 1.11.0
, the following error will occur. The reason is that the new version of pytorch has removed THC/THC.h
fatal error: THC/THC.h: No such file or directory
and changed AdelaiDet/adet/layers/csrc/ml_nms/ml_nms.cu under the path to the following.
Specific reference: https: //github.com/aim-uofa/AdelaiDet/issues/550 & https://github.com/aim-uofa/AdelaiDet/pull/518
// Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
#include <ATen/ATen.h>
#include <ATen/cuda/CUDAContext.h>
// #include <THC/THC.h>
#include <ATen/cuda/DeviceUtils.cuh>
#include <ATen/ceil_div.h>
#include <ATen/cuda/ThrustAllocator.h>
#include <vector>
#include <iostream>
int const threadsPerBlock = sizeof(unsigned long long) * 8;
__device__ inline float devIoU(float const * const a, float const * const b) {
if (a[5] != b[5]) {
return 0.0;
}
float left = max(a[0], b[0]), right = min(a[2], b[2]);
float top = max(a[1], b[1]), bottom = min(a[3], b[3]);
float width = max(right - left + 1, 0.f), height = max(bottom - top + 1, 0.f);
float interS = width * height;
float Sa = (a[2] - a[0] + 1) * (a[3] - a[1] + 1);
float Sb = (b[2] - b[0] + 1) * (b[3] - b[1] + 1);
return interS / (Sa + Sb - interS);
}
__global__ void ml_nms_kernel(const int n_boxes, const float nms_overlap_thresh,
const float *dev_boxes, unsigned long long *dev_mask) {
const int row_start = blockIdx.y;
const int col_start = blockIdx.x;
// if (row_start > col_start) return;
const int row_size =
min(n_boxes - row_start * threadsPerBlock, threadsPerBlock);
const int col_size =
min(n_boxes - col_start * threadsPerBlock, threadsPerBlock);
__shared__ float block_boxes[threadsPerBlock * 6];
if (threadIdx.x < col_size) {
block_boxes[threadIdx.x * 6 + 0] =
dev_boxes[(threadsPerBlock * col_start + threadIdx.x) * 6 + 0];
block_boxes[threadIdx.x * 6 + 1] =
dev_boxes[(threadsPerBlock * col_start + threadIdx.x) * 6 + 1];
block_boxes[threadIdx.x * 6 + 2] =
dev_boxes[(threadsPerBlock * col_start + threadIdx.x) * 6 + 2];
block_boxes[threadIdx.x * 6 + 3] =
dev_boxes[(threadsPerBlock * col_start + threadIdx.x) * 6 + 3];
block_boxes[threadIdx.x * 6 + 4] =
dev_boxes[(threadsPerBlock * col_start + threadIdx.x) * 6 + 4];
block_boxes[threadIdx.x * 6 + 5] =
dev_boxes[(threadsPerBlock * col_start + threadIdx.x) * 6 + 5];
}
__syncthreads();
if (threadIdx.x < row_size) {
const int cur_box_idx = threadsPerBlock * row_start + threadIdx.x;
const float *cur_box = dev_boxes + cur_box_idx * 6;
int i = 0;
unsigned long long t = 0;
int start = 0;
if (row_start == col_start) {
start = threadIdx.x + 1;
}
for (i = start; i < col_size; i++) {
if (devIoU(cur_box, block_boxes + i * 6) > nms_overlap_thresh) {
t |= 1ULL << i;
}
}
const int col_blocks = at::ceil_div(n_boxes, threadsPerBlock);
dev_mask[cur_box_idx * col_blocks + col_start] = t;
}
}
namespace adet {
// boxes is a N x 6 tensor
at::Tensor ml_nms_cuda(const at::Tensor boxes, const float nms_overlap_thresh) {
using scalar_t = float;
AT_ASSERTM(boxes.type().is_cuda(), "boxes must be a CUDA tensor");
auto scores = boxes.select(1, 4);
auto order_t = std::get<1>(scores.sort(0, /* descending=*/true));
auto boxes_sorted = boxes.index_select(0, order_t);
int boxes_num = boxes.size(0);
const int col_blocks = at::ceil_div(boxes_num, threadsPerBlock);
scalar_t* boxes_dev = boxes_sorted.data<scalar_t>();
// THCState *state = at::globalContext().lazyInitCUDA(); // TODO replace with getTHCState
unsigned long long* mask_dev = NULL;
//THCudaCheck(THCudaMalloc(state, (void**) &mask_dev,
// boxes_num * col_blocks * sizeof(unsigned long long)));
mask_dev = (unsigned long long*) c10::cuda::CUDACachingAllocator::raw_alloc(boxes_num * col_blocks * sizeof(unsigned long long));
dim3 blocks(at::ceil_div(boxes_num, threadsPerBlock),
at::ceil_div(boxes_num, threadsPerBlock));
dim3 threads(threadsPerBlock);
ml_nms_kernel<<<blocks, threads>>>(boxes_num,
nms_overlap_thresh,
boxes_dev,
mask_dev);
std::vector<unsigned long long> mask_host(boxes_num * col_blocks);
c10::cuda::CUDACachingAllocator::raw_alloc(cudaMemcpy(&mask_host[0],
mask_dev,
sizeof(unsigned long long) * boxes_num * col_blocks,
cudaMemcpyDeviceToHost));
std::vector<unsigned long long> remv(col_blocks);
memset(&remv[0], 0, sizeof(unsigned long long) * col_blocks);
at::Tensor keep = at::empty({
boxes_num}, boxes.options().dtype(at::kLong).device(at::kCPU));
int64_t* keep_out = keep.data<int64_t>();
int num_to_keep = 0;
for (int i = 0; i < boxes_num; i++) {
int nblock = i / threadsPerBlock;
int inblock = i % threadsPerBlock;
if (!(remv[nblock] & (1ULL << inblock))) {
keep_out[num_to_keep++] = i;
unsigned long long *p = &mask_host[0] + i * col_blocks;
for (int j = nblock; j < col_blocks; j++) {
remv[j] |= p[j];
}
}
}
c10::cuda::CUDACachingAllocator::raw_delete(mask_dev);
// TODO improve this part
return std::get<0>(order_t.index({
keep.narrow(/*dim=*/0, /*start=*/0, /*length=*/num_to_keep).to(
order_t.device(), keep.scalar_type())
}).sort(0, false));
}
} // namespace adet
4. Adjust the demo with the official weight
- Remember to install the requirements that the file depends on, usually in requirements.txt
- Select an officially trained model weight, such as blendmask_r101_dcni3_5x.pth
- Put blendmask_r101_dcni3_5x.pth in the AdelaiDet directory
- run in terminal
python demo/demo.py \
--config-file configs/BlendMask/R_101_dcni3_5x.yaml \
--input input1.jpg \
--confidence-threshold 0.35 \
--opts MODEL.WEIGHTS blendmask_r101_dcni3_5x.pth
python demo/demo.py --config-file configs/BlendMask/R_101_dcni3_5x.yaml --input ./datasets/00000.jpg --confidence-threshold 0.35 --opts MODEL.WEIGHTS ./blendmask_r101_dcni3_5x.pth
input1.jpg is the picture you choose and put it under datasets.
If there is an instance segmentation picture, it is successful.

5. Using the COCO dataset 2017
- First use your own COCO dataset
The directory structure is
/dataset/coco2017/annotations
/dataset/coco2017/train2017
/dataset/coco2017/val2017
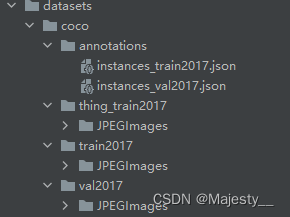
- cd AdelaiDet/datasets, modify the file prepare_thing_sem_from_instance.py, change coco in the file to the location of your own dataset, and change split_name to the folder name of the training set
def get_parser():
parser = argparse.ArgumentParser(description="Keep only model in ckpt")
parser.add_argument(
"--dataset-name",
default="coco2017",
help="dataset to generate",
)
return parser
if __name__ == "__main__":
args = get_parser().parse_args()
dataset_dir = os.path.join(os.path.dirname(__file__), args.dataset_name)
if args.dataset_name == "coco2017":
thing_id_to_contiguous_id = _get_coco_instances_meta()["thing_dataset_id_to_contiguous_id"]
split_name = 'train2017'
annotation_name = "annotations/instances_{}.json"
else:
thing_id_to_contiguous_id = {
1: 0}
split_name = 'train'
annotation_name = "annotations/{}_person.json"
for s in ["train2017"]:
create_coco_semantic_from_instance(
os.path.join(dataset_dir, "annotations/instances_{}.json".format(s)),
os.path.join(dataset_dir, "thing_{}".format(s)),
thing_id_to_contiguous_id
)
- Run (you can skip this step without using AdelaiDet and only use detectron2. This task is instance segmentation, and target detection can be skipped)
python datasets/prepare_thing_sem_from_instance.py #从实例标注中提取语义信息
Error: No such file or directory
If there are folders under train2017, please add a price folder with the same name under the thing_train2017 folder
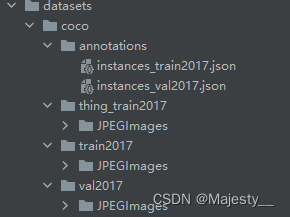
6. Modify the relevant configuration
- cd AdelaiDet/adet/config/defaults.py , change the SynBN in the document to BN, because I am training with a single GPU, Syn said that it needs to be trained at the same time, and there is no need to change this step if there are multiple GPUs
#_C.MODEL.BASIS_MODULE.NORM = "SyncBN"
_C.MODEL.BASIS_MODULE.NORM = "BN"
#_C.MODEL.FCPOSE.BASIS_MODULE.BN_TYPE = "SyncBN"
_C.MODEL.FCPOSE.BASIS_MODULE.BN_TYPE = "BN"
- Registration data set (easy to understand version, not easy to make mistakes)
Before registering the dataset, make it in coco format. The id of categories in coco format starts from 1, excluding the background class.
Add the following in /root/instance_seg/detectron2/detectron2/data/datasets/builtin.py
from detectron2.data import DatasetCatalog, MetadataCatalog
from detectron2.data.datasets.coco import load_coco_json
import pycocotools
#声明类别,尽量保持与自己数据集相同
CLASS_NAMES =['_background_', "pothole", ]
# 数据集路径
# 可以写死绝对路径,如果需要迁移的话,最好写成绝对路径
# 放在detectron2的datasets下一样,主要是看入口路径root是在那里
# DATASET_ROOT = os.path.abspath(os.path.join(os.getcwd(), "../../../../AdelaiDet/datasets"))
DATASET_ROOT = os.path.abspath(os.path.join(os.getcwd(), "../AdelaiDet/datasets"))
# print('DATASET_ROOT' + DATASET_ROOT)
# 注解路径
ANN_ROOT = os.path.join(DATASET_ROOT, 'coco/annotations')
# print('ANN_ROOT' + ANN_ROOT)
TRAIN_PATH = os.path.join(DATASET_ROOT, 'coco/train2017')
VAL_PATH = os.path.join(DATASET_ROOT, 'coco/val2017')
TRAIN_JSON = os.path.join(ANN_ROOT, 'instances_train2017.json')
#VAL_JSON = os.path.join(ANN_ROOT, 'val.json')
VAL_JSON = os.path.join(ANN_ROOT, 'instances_val2017.json')
# 声明数据集的子集
PREDEFINED_SPLITS_DATASET = {
# yaml 文件中自己设置的数据集名称,在这里注册 coco_train coco_val
"coco_train": (TRAIN_PATH, TRAIN_JSON), #coco_my_train 新数据集关键字
"coco_val": (VAL_PATH, VAL_JSON),
}
# 注册自己的数据集
def register_all_udtiri(root):
#训练集
DatasetCatalog.register("coco_train", lambda: load_coco_json(TRAIN_JSON, TRAIN_PATH))
MetadataCatalog.get("coco_train").set(thing_classes=CLASS_NAMES, # 可以选择开启,但是不能显示中文,这里需要注意,中文的话最好关闭
evaluator_type='coco', # 指定评估方式
json_file=TRAIN_JSON,
image_root=TRAIN_PATH)
#DatasetCatalog.register("coco_my_val", lambda: load_coco_json(VAL_JSON, VAL_PATH, "coco_2017_val"))
#验证/测试集
# print(VAL_PATH)
DatasetCatalog.register("coco_val", lambda: load_coco_json(VAL_JSON, VAL_PATH))
MetadataCatalog.get("coco_val").set(thing_classes=CLASS_NAMES, # 可以选择开启,但是不能显示中文,这里需要注意,中文的话最好关闭
evaluator_type='coco', # 指定评估方式
json_file=VAL_JSON,
image_root=VAL_PATH)
Add the following at if name.endswith(“.builtin”): in builtin.py:
if __name__.endswith(".builtin"):
# Assume pre-defined datasets live in `./datasets`.
_root = os.path.expanduser(os.getenv("DETECTRON2_DATASETS", "datasets"))
register_all_coco(_root)
register_all_lvis(_root)
register_all_cityscapes(_root)
register_all_cityscapes_panoptic(_root)
register_all_pascal_voc(_root)
register_all_ade20k(_root)
# 自己定义注册函数名
register_all_udtiri(_root) # 新增
以上的几个内容添加或者修改完后,就可以进行对yaml参数文件的配置了。
**cd AdelaiDet/configs/BlendMask/Base-BlendMask.yaml**
```yaml
DATASETS:
TRAIN: ("coco_2017_train",)
TEST: ("coco_2017_val",)
SOLVER:
IMS_PER_BATCH: 4
BASE_LR: 0.01 # Note that RetinaNet uses a different default learning rate
STEPS: (60000, 80000)
MAX_ITER: 90000
7. Conduct training
- cd AdelaiDet
OMP_NUM_THREADS=1 python tools/train_net.py \
--config-file configs/BlendMask/R_50_1x.yaml \ #配置文档的路径
--num-gpus 1 \ #设置的GPU为1
OUTPUT_DIR training_dir/blendmask_R_50_1x #训练完输出的路径
OMP_NUM_THREADS=1
python tools/train_net.py --config-file configs/BlendMask/R_50_1x.yaml --num-gpus 1 OUTPUT_DIR training_dir/blendmask_R_50_1x