Click the card below to follow the " CVer " official account
AI/CV heavy dry goods, delivered in the first time
Click to enter —> [Image Segmentation and Transformer] Exchange Group
This paper proposes a more efficient synthetic data set VPO and a pixel-level contrastive learning training strategy for the audio-visual segmentation (AVS) problem to more effectively verify the AVS problem and effectively improve the audio-image association. Unit: University of Adelaide, University of Surrey.

A Closer Look at Audio-Visual Semantic Segmentation
Article link: https://arxiv.org/abs/2304.02970
The audio-visual segmentation task (audio-visual segmentation [AVS]) is mainly to match the sound signal and the image at the pixel level . Successful audiovisual learning requires two fundamental components: 1) an unbiased dataset with high-quality pixel-level multiclass labels, and 2) a model that can efficiently link audio information with its corresponding visual object. However, current approaches only partially address these two requirements. We found through validation that existing models do not effectively learn the correlation of visual and acoustic signals. For example, in the example below, although the signal of the sound has changed, the prediction of the model has not changed. Based on this phenomenon, we suspect that 1) a hidden rule of the data set (a specific object is always the source of occurrence in a specific scene) affects the generalization of the model. 2) The model is more inclined to establish the association between moving objects and occurring objects in the video. In addition, the audio-visual segmentation problem requires a large amount of labeled data for model training. Considering that the labeler needs to monitor the audio while labeling for selective labeling, the time cost of labeling will be relatively large. In response to the above problems, we found through experiments that we can match images (COCO) and audio to obtain audio and video data (VGGSound) according to the semantic category of the visual object of the image. Using existing datasets to construct AVS datasets, and this Discrete sound-visual pairings can exclude object movement information. In addition, we again use this sound-image pairing method to provide richer positive and negative sets for supervised contrastive learning to improve representation performance and model performance.

main contribution
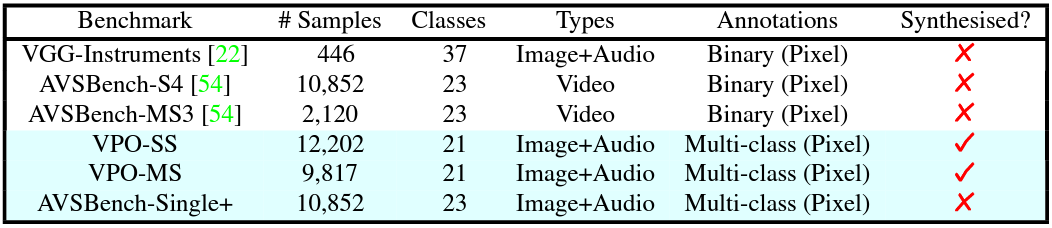
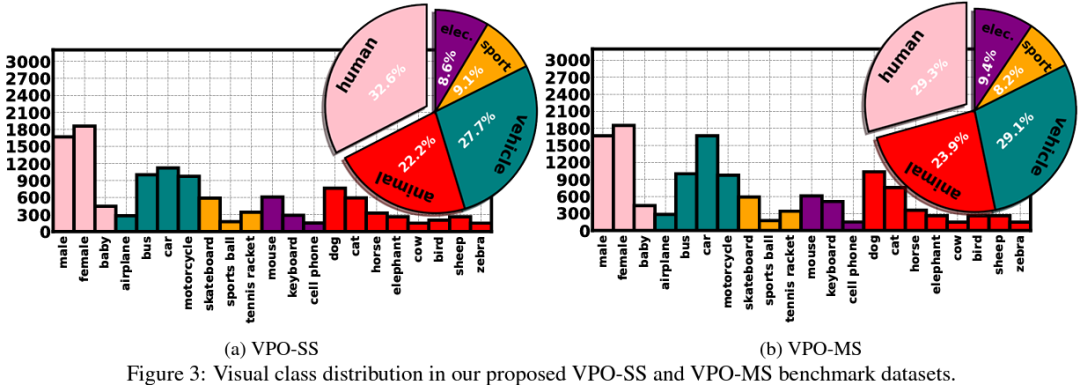
A new strategy to build cost-effective and relatively unbiased semantic segmentation benchmarks, called Visual Post-production (VPO). The VPO benchmark pairs image (from COCO) and audio (from VGGSound) based on the semantic classes of the visual objects of the images. We propose two new VPO benchmarks based on this strategy: the single sound source (VPO-SS) and multiple sound sources (VPO-MS).
An extension of the benchmark AVSBench-Single called AVSBench-Single+, which restores the original image resolution and represents semantic segmentation masks with multi-class annotations.
A new AVS method trained with the new objective function CAVP that randomly matches audio and visual pairs to form rich ``positive'' and ``negative'' contrastive pairs to better constrain the learning of the audio-visual embeddings.
Audiovisual Segmentation Synthesis Dataset Visual Post-production (VPO)
We propose a richer and more efficient synthetic dataset VPO to more effectively verify visual and auditory correspondences. Compared with previous data sets, VPO can obtain a large number of high-quality segmentation ground-truth and more complex scenes at the lowest collection cost.

Experimental Method - Contrastive Audio-Visual Pairing (CAVP)
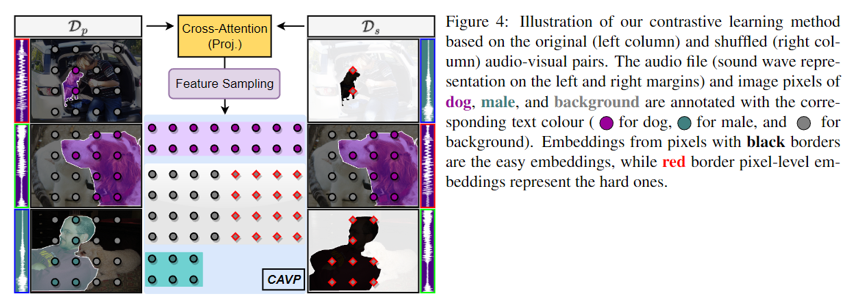
Contrastive learning methods previously designed for audiovisual localization are challenged by two problems:
1) Confirmation bias, since vocalizing objects are automatically defined via pseudo-labels, and 2) false-positive detection rates are high, since the modeling of positive-negative relationships is not explicitly considered pixel-wise. We address the first issue by replacing automatic pseudo-labels with pixel-level multi-class annotations available in semantic segmentation datasets. To address the second point, based on the basic idea of VPO synthesis, we utilize the initial training set as well as an audio-visual randomly assigned shuffle set to form a rich contrastive set containing different positive and negative pairs for supervised contrastive learning.
Experimental results
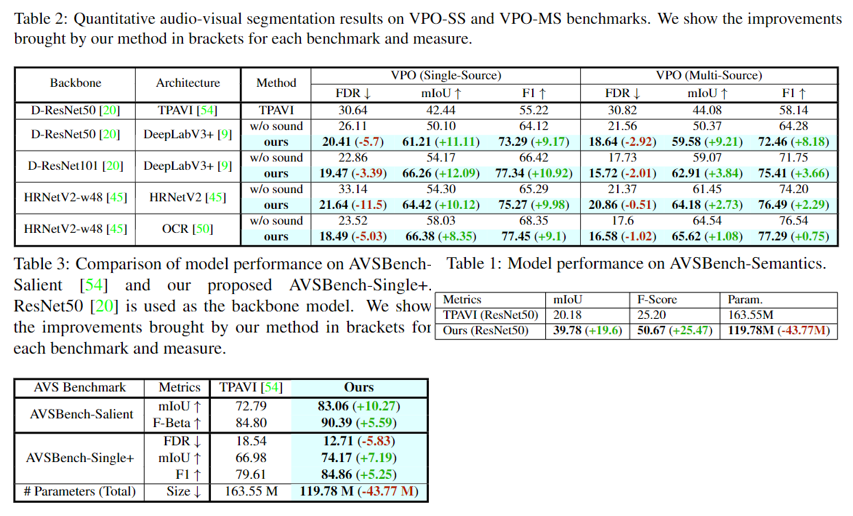
The experiment mainly compares the performance of the models on AVSBench-Object, VPO and AVSBench-Semantic on mIoU, FDR and F1. Experimental results show that our method significantly outperforms existing networks on existing audiovisual segmentation datasets and contains fewer parameters.
Click to enter —> [Target Detection and Transformer] Exchange Group
The latest CVPR 2023 papers and code download
Background reply: CVPR2023, you can download the collection of CVPR 2023 papers and code open source papers
Background reply: Transformer review, you can download the latest 3 Transformer review PDFs
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer333,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信号: CVer333,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉,已汇集数千人!
▲扫码进星球
▲点击上方卡片,关注CVer公众号It's not easy to organize, please like and watch![]()