I. Introduction
This article mainly sorts out regular matching rules and common matching methods, and uses a large number of small examples to assist in the explanation.
Environment description: Anaconda3, Python 3.9, windows11 64-bit
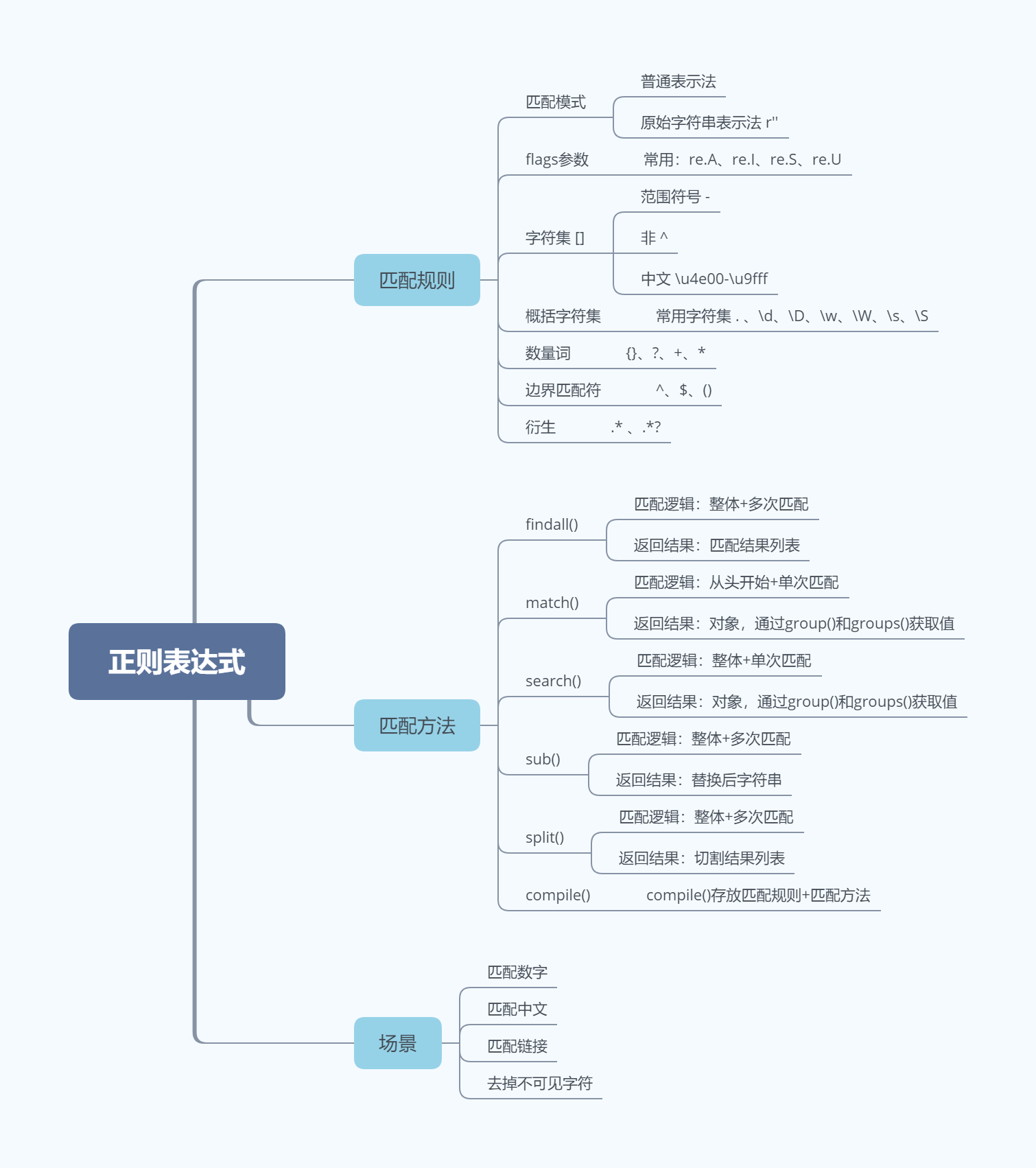
2. Matching rules
2.1 About matching mode
Patterns and searched strings can be either Unicode strings (str) or octet strings (bytes). But the two cannot be mixed: that is, you cannot match Unicode strings with byte string patterns, and vice versa; similarly, when replacing operations, the type of the replacement string must also be consistent with the type of the pattern and search string used .
\Explanation about
the rules: First of all, you need to make it clear that Python is Python, and regular is regular. The two have a set of rules about characters. In fact, the functions are similar. ability".
- Used as an escape symbol in Python
\to represent special functions of characters (such as\nrepresenting newlines) or functions that do not trigger special characters (\\representing backslashes with no special meaning); - Regular expressions use
\special forms to represent characters (such as\dto represent numbers), or allow special characters to be used without evoking their special meaning (such as\\to represent a backslash with no special meaning).
Due to the rules of Python and regular expressions, to match a backslash literal, the user may have to write \\\\as the pattern string, since regular expressions must be \\, and each backslash must be represented in a normal Python string literal for \\. (This representation may cause comprehension obstacles.)
[ Official recommended method ] Of course, you can also use Python's original string representation ( r'', r"\n"representing a string containing \and ntwo characters) to remove \the special meaning of Python, and then pass it to Regular expression patterns.
import re
content = 'Python12\\34中文'
re_1 = re.findall(r'\d',content) # 使用Python的原始字符串表示法
re_2 = re.findall('\\d',content) # 不使用Python的原始字符串表示法
re_3 = re.findall('\d',content) # 该写法也可以,具体逻辑未详,建议使用上面两种方法
print('%s\n%s\n%s'%(re_1,re_2,re_3))
# 结果都是:['1', '2', '3', '4']
re_3Note: Although a single can be used above \, it must be used when contentmatching .\\\\\
2.2 About the flags parameter
In the several methods introduced later, there are flagsparameters, which mainly control the changes in the rules of matching characters. The relevant parameter values and meanings are as follows:
| parameter value | meaning | illustrate |
|---|---|---|
| re.A | ASCII | Let \w, \W, \b, \B, \d, \D, \s and \S only match ASCII characters, only valid for Unicode style, and will be ignored by byte style. |
| re.I | IGNORECASE | ignore case, [A-Z]and [a-z]synonyms |
| re.L | LOCALE | language dependence |
| re.M | MULTILINE | In multi-line mode, the character ^matches the beginning of the string, and the beginning of each line (the symbol immediately following the newline); the pattern character $matches the end of the string, and the end of each line (the symbol preceding the newline). |
| re.S | DOTALL | .matches all characters, including\\n |
| re.U | 0, the default value | Unicode matching, which parses characters according to the Unicode character set. |
| re.X | VERBOSE | Verbose mode, supporting comments and ignoring spaces, such as the following two forms have the same result a = re.compile(r""" \d + # the integral part \. # the decimal point \d * # some fractional digits""", re.X) b = re.compile(r"\d+\.\d*") |
import re
content = 'Python\n12\\34中文'
re_1 = re.findall(r'\w+',content) # 结果为:['Python', '12', '34中文']
re_2 = re.findall(r'\w+',content,flags=re.A) # 结果为:['Python', '12', '34']
re_3 = re.findall(r'.+',content) # 结果为:['Python', '12\\34中文']
re_4 = re.findall(r'.+',content,flags=re.S) # 结果为:['Python\n12\\34中文']
re_5 = re.findall(r'[A-Z]+',content) # 结果为:['P']
re_6 = re.findall(r'[A-Z]+',content,flags=re.I) # 结果为:['Python']
print('%s\n%s\n%s\n%s\n%s\n%s'%(re_1,re_2,re_3,re_4,re_5,re_6))
2.3 Character set[]
The relationship between the characters in the character []set is 或a relationship, as long as one of them is satisfied, it can be defined as a successful match.
| matching rules | paraphrase |
|---|---|
| [abf] | Indicates that the character at this position is a or b or f, that is, the match is successful |
| [a-z] | Indicates that the character at this position is between a~z, that is, the match is successful |
| [A-Z] | Indicates that the character at this position is between A~Z, that is, the match is successful, pay attention to the difference between upper and lower case |
| [a-zA-Z] | Indicates that the character at this position is between a z or A Z, that is, the match is successful |
| [^a-z] | Indicates that the character at this position is not between az, that is, the match is successful, and ^ means not |
| [^1-9] | Indicates that the character at this position is between 1 and 9, that is, the match is successful |
Note: ^Depending on where it is placed, there will be different meanings. Putting it in the character set indicates 非the meaning; placing it at the beginning of the matching character can also mean starting with the following string.
2.4 General character set
Return the result, representing only one character at a time
| matching rules | paraphrase | Equivalent to |
|---|---|---|
| . | In default mode, \\nany character except any character; in re.S mode, any character |
|
| \d | Indicates that the character at this position is a number, that is, the match is successful | [0-9] |
| \D | Indicates that the character at this position 不is a number, that is, the match is successful |
[^0-9] |
| \w | Indicates that the character at this position is a letter (including uppercase and lowercase) or _a number or Chinese, that is, the match is successful. Note: \\u4e00-\\u9fffIt is a utf-8 encoded Chinese character. |
[A-Za-z0-9_\u4e00-\u9fff] |
| \W | Indicates that the character at this position 不is a letter or _a number or Chinese, that is, the match is successful |
[^A-Za-z0-9_\u4e00-\u9fff] |
| \s | Indicates that the position is an invisible character (space, tab character \t, vertical tab character \v, carriage return character \r, line feed character \n, form feed character \f), that is, the match is successful | [\f\n\t\r\v] |
| \S | Indicates that the position 不is an invisible character, that is, the match is successful |
[^\f\n\t\r\v] |
| \b | Matches the empty string, but only at the beginning or end of a word. A word is defined as a sequence of word characters. Note that it is usually \\bdefined as the boundary between \\wand \\Wcharacters, or \\wthe beginning/end of a string. (see 3.5 re.split()-style empty matching) |
|
| \B | No \\b, match an empty string, but 不it can be at the beginning or end of a word, and the boundary is not \\wbetween and \\W, but between multiple \\wor \\Wbetween multiple. (see 3.5 re.split()-style empty matching) |
2.5 Quantifiers
| matching rules | paraphrase |
|---|---|
| {3} | Indicates that {3}the previous character appears 3 times |
| {3,8} | Indicates that {3,8}the previous character appears 3-8 times |
| ? | Indicates that ?the preceding character appears0次或1次 |
| + | Indicates that +the preceding character appears1次或无限多次 |
| * | Indicates that *the preceding character appears0次或无限多次 |
2.6 Boundary matchers
| matching rules | paraphrase |
|---|---|
| ^ | Indicates that as long as it ^starts with the following characters, the match is successful |
| $ | Indicates that as long as it $ends with the previous character, the match is successful |
| () | ()内的内容构成一个组,只要符合匹配规则就匹配成功,返回()内匹配成功的内容,如(\\d)表示匹配一个数字 |
2.7 衍生
普通模式下:
. 表示一个除换行符\n以外的所有字符,表示 . 重复0次或无限多次
. 放在一起就是匹配除换行符以外的任意字符无限多次
| 匹配规则 | 命名 | 释义 |
|---|---|---|
| .* | 贪婪模式 | 表示匹配除换行符以外的任意字符无限多次,一般是匹配后面跟的字符或组直到出现的最后一个。 |
| .*? | 非贪婪模式 | 一般是匹配后面跟的字符或组直到出现的第一个。 |
注:这两种匹配方式需要结合其后接的字符或组。
在进行对字符串进行匹配时,可以先使用replace("\n","")把换行符先去掉,或者改用re.S模式。
示例:
import re
content = '发布时间:2022年10月24日。'
# 贪婪模式 .* 会匹配到最后一个符号要求的值,也就是数字4,所以匹配到:2022年10月24
re_1 = re.findall(r'(\d.*\d)', content) # 结果为:['2022年10月24']
# 非贪婪模式 .*? 从匹配到第一个数字开始,就寻找下一个数字,一找到便返回,所以最小单位是两个数字,也可以是两个数字间夹一些其他的字符
re_2 = re.findall(r'(\d.*?\d)', content) # 结果为:['20', '22', '10', '24']
print('%s\n%s'% (re_1,re_2))
re_3 = re.findall(r'(\d.*?\d)', '9月10日') # 结果为:['9月1'],0之后没有满足要求的数字,所以匹配不成功
print(re_3)
# 混合使用
# .*? 碰到第一个数字2(括号里第一个\d),就停止匹配,接着 .* 一直匹配到最后一个数字4
re_4 = re.findall(r'.*?(\d.*\d)', content) # 结果为:['2022年10月24']
# .* 一直匹配到最后满足括号里要求的24,这里可以倒着看,先看括号里的内容(两个数字,中间可以有其他字符),然后到字符串中倒着看,最后两个数字是24,那匹配结果就是它了
re_5 = re.findall(r'.*(\d.*?\d)', content) # 结果为:['24']
print('%s\n%s'% (re_4,re_5))
三、常用六种方法
3.1 re.findall(‘匹配规则’ , ‘字符串’, flags=0)
只要符合匹配规则,就找出所有符合的字符串以列表形式返回。
3.1.1 直接匹配
可以只写需要匹配的字符所对应的规则。
import re
content = '《Python 基础合集13:错误的调试和处理》是我最近发布的一篇推文,链接:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日,开发语言:Python。'
# 普通字符
re_1 = re.findall(r'Python',content) # 匹配Python
# 元字符c
re_2 = re.findall(r'P[ab]n',content) # 匹配Pan或Pbn
re_3 = re.findall(r'P[a-c]n',content) # 匹配Pan或Pbn或Pcn
re_4 = re.findall(r'P[^ab]n',content) # 匹配P和n之间存在一个非a和b的字符的字符串,可以是大写字母、数字、_等
re_5 = re.findall(r'P[^a-c]n',content) # 匹配P和n之间存在一个非a、b和c的字符的字符串
# 元字符+数量词
re_6 = re.findall(r'P[ab]{1,10}n',content) # P和n之间的[ab]有1~10个均可匹配成功
re_7 = re.findall(r'P[a-c]{1,10}n',content) # P和n之间的[a-c]有1~10个均可匹配成功
re_8 = re.findall(r'P[^ab]{1,10}n',content) # P和n之间的非[ab]有1~10个均可匹配成功,Python可以匹配成功
re_9 = re.findall(r'P[^a-c]{1,10}n',content) # P和n之间的非[a-c]有1~10个均可匹配成功,Python可以匹配成功
re_10 = re.findall(r'P[a-z]{1,10}n',content) # P和n之间的有1~10个小写英文字母均可匹配成功,Python可以匹配成功
# 字符集
re_11 = re.findall(r'P\w{4}n',content) # P和n之间的有4个大小写英文字母或_或数字均可匹配成功,Python可以匹配成功
re_12 = re.findall(r'P\w+n',content) # P和n之间的有1到无限个大小写英文字母或_或数字均可匹配成功,Python可以匹配成功
# 边界匹配
re_13 = re.findall(r'^《P\w+n',content) # 开头是《P\w+n即匹配成功
re_14 = re.findall(r'P\w+n。$',content) # 结尾是P\w+n。即匹配成功
# 衍生匹配
re_15 = re.findall(r'P.*n',content) # P后匹配到最后一个n才返回
re_16 = re.findall(r'P.*?n',content) # P后匹配到第一个n即返回
print('1%s\n2%s\n3%s\n4%s\n5%s\n6%s\n7%s\n8%s\n9%s\n10%s\n11%s\n12%s\n13%s\n14%s\n15%s\n16%s'
% (re_1,re_2,re_3,re_4,re_5,re_6,re_7,re_8,re_9,re_10,re_11,re_12,re_13,re_14,re_15,re_16))
# 结果如下:
# 1['Python', 'Python']
# 2[]
# 3[]
# 4[]
# 5[]
# 6[]
# 7[]
# 8['Python', 'Python']
# 9['Python', 'Python']
# 10['Python', 'Python']
# 11['Python', 'Python']
# 12['Python', 'Python']
# 13['《Python']
# 14['Python。']
# 15['Python 基础合集13:错误的调试和处理》是我最近发布的一篇推文,链接:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日,开发语言:Python']
# 16['Python', 'Python']
3.1.2 组合查询的形式
没有组则返回整一个匹配结果,有组则返回组内的匹配结果。
没组和有一个组都返回一个列表,元素都是匹配成功的字符;如果是多个组,则将多个组的每一次成功匹配以元组返回作为列表的元素,结构如[(一组,二组,……),(一组,二组,……)……]。
import re
content = '《Python 基础合集13:错误的调试和处理》是我最近发布的一篇推文,链接:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日,开发语言:Python。'
# 单个组
re_1 = re.findall(r'(\d.*\d)',content) # 匹配组(\d.*\d),表示以数字开头,以数字结尾,中间可以是除换行以外的任意字符,匹配到最后一个数字
re_2 = re.findall(r'(\d.*?\d)',content) # 匹配组(\d.*?\d),表示以数字开头,以数字结尾,中间可以是除换行以外的任意字符,遇到第二个数字即返回
print('1%s\n2%s'% (re_1,re_2,))
# 结果如下:
# 1['13:错误的调试和处理》是我最近发布的一篇推文,链接:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24']
# 2['13', '45', '47', '64', '28', '12', '74', '82', '59', '3,发布时间:2', '02', '2年1', '0月2']
re_3 = re.findall(r'(https://[\./\w]+)\W',content) # 匹配链接,https:后面跟上 . / A-Za-z0-9_ 字符,直到第一个非 A-Za-z0-9_ 字符
print(re_3) # 结果为:['https://blog.csdn.net/qq_45476428/article/details/127482593']
# 多个组
re_4 = re.findall(r'(https://[\./\w]+)\W.*?(\d+年.*?日)',content) # 匹配链接和日期
print(re_4) # 结果为:[('https://blog.csdn.net/qq_45476428/article/details/127482593', '2022年10月24日')]
3.2 re.match(‘匹配规则’ , ‘字符串’, flags=0)
match()方法的参数和findall()是一样的,返回的结果是SRE_Match对象。
在匹配的时候,match()从字符串的第一个字符开始匹配,如果第一个未匹配到,直接返回None。所以如果将刚刚findall()的例子将findall都改为match,只有re_13 = re.findall('^《P\w+n',content)这个改为re_13 = re.match('^《P\w+n',content)之后可以匹配到结果,其他的都不可以,因为字符串不是以P开头,所以匹配不到。
基于该逻辑,一般使用match()方法,更倾向于使用.或.?放匹配规则的开头加组合查询的方法,将匹配的目标字符规则放到小括号中。
查看match()匹配的结果,一般需要借助group()或groups()方法,直接打印会是对应的对象信息。
import re
content = '《Python 基础合集13:错误的调试和处理》是我最近发布的一篇推文,链接:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日,开发语言:Python。'
re_1 = re.match(r'.*?(Python)',content) # 匹配第一个Python
re_2 = re.match(r'.*?(https://[\./\w]+)\W.*?(\d+年.*?日)',content) # 匹配链接和日期
print(re_1) # 结果为:<re.Match object; span=(0, 7), match='《Python'>
print(re_1.group()) # 结果为:《Python
print(re_1.group(0)) # 结果为:《Python
print(re_1.group(1)) # 结果为:Python
print(re_1.groups()) # 结果为:('Python',)
print(re_2) # 结果为:<re.Match object; span=(0, 115), match='《Python 基础合集13:错误的调试和处理》是我最近发布的一篇推文,链接:https://bl>
print(re_2.group()) # 结果为:《Python 基础合集13:错误的调试和处理》是我最近发布的一篇推文,链接:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日
print(re_2.group(0)) # 结果为:《Python 基础合集13:错误的调试和处理》是我最近发布的一篇推文,链接:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日
print(re_2.group(1)) # 结果为:https://blog.csdn.net/qq_45476428/article/details/127482593
print(re_2.group(2)) # 结果为:2022年10月24日
print(re_2.groups()) # 结果为:('https://blog.csdn.net/qq_45476428/article/details/127482593', '2022年10月24日')
关于group()和group()的对比说明:
| 方法 | 说明 |
|---|---|
| group() | 整一个匹配规则,即引号内的所有内容 |
| group(0) | 同group() |
| group(1) | 引号内的第1个小括号内匹配的内容(如有) |
| group(2) | 引号内的第2个小括号内匹配的内容(如有) |
| group(3) | 引号内的第3个小括号内匹配的内容(如有) |
| groups() | 以元组返回所有小括号内的匹配结果 |
3.3 re.search(‘匹配规则’ , ‘字符串’, flags=0)
search()和match()语法和用法一样。
不同的是,match()只要字符串的【第一个字符】不符合【匹配规则】就返回None。而search() 则是对整一个字符串进行匹配,整个字符串没有符合【匹配规则】才返回None。
可以将match()中的例子中,改方法名为search,并去掉小括号前面的.*?,然后对比一下结果。
从结果中可以看到,search()和match()一样只匹配了一次,便返回了。而findall()会匹配所有可能的结果。
import re
content = '《Python 基础合集13:错误的调试和处理》是我最近发布的一篇推文,链接:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日,开发语言:Python。'
re_1 = re.search(r'(Python)',content) # 匹配第一个Python
re_2 = re.search(r'(https://[\./\w]+)\W.*?(\d+年.*?日)',content) # 匹配链接和日期
print(re_1) # 结果为:<re.Match object; span=(1, 7), match='Python'>
print(re_1.group()) # 结果为:Python
print(re_1.group(0)) # 结果为:Python
print(re_1.group(1)) # 结果为:Python
print(re_1.groups()) # 结果为:('Python',)
print(re_2) # 结果为:<re.Match object; span=(39, 115), match='https://blog.csdn.net/qq_45476428/article/details>
print(re_2.group()) # 结果为:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日
print(re_2.group(0)) # 结果为:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日
print(re_2.group(1)) # 结果为:https://blog.csdn.net/qq_45476428/article/details/127482593
print(re_2.group(2)) # 结果为:2022年10月24日
print(re_2.groups()) # 结果为:('https://blog.csdn.net/qq_45476428/article/details/127482593', '2022年10月24日')
3.4 re.sub(‘匹配规则’ , ‘替换后字符’ , ‘字符串’, count = 0, flags=0)
sub()能实现的功能是匹配出结果并替换掉内容,使用的匹配机制也是全文匹配所有可能的结果,同findall()。如果是一个比较简单的字符,也可以通过replace()替换。
import re
content = '《Python 基础合集13:错误的调试和处理》是我最近发布的一篇推文,链接:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日,开发语言:Python。'
# 将所有Python替换为java
re_1 = re.sub(r'Python','java',content)
re_2 = content.replace('Python','java')
print('%s\n%s'%(re_1,re_2)) # 结果一致:《java 基础合集13:错误的调试和处理》是我最近发布的一篇推文,链接:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日,开发语言:java。
sub()的第四个参数是count,默认为0,表示无论匹配成功多少个字符,都替换成指定的字符;当不为0时,假设为整数n,则表示无论匹配成功多少个字符,最多只将前n个匹配成功的字符替换成指定字符。
import re
content = '《Python 基础合集13:错误的调试和处理》是我最近发布的一篇推文,链接:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日,开发语言:Python。'
# 通过参数count=1将第一个Python替换为java
re_3 = re.sub(r'Python','java',content,1) # 一般建议使用count=1,以免忘记参数值含义
print(re_3)) # 结果为:《java 基础合集13:错误的调试和处理》是我最近发布的一篇推文,链接:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日,开发语言:Python。
由于sub()是将规则全部匹配,不论是否加括号(可以通过以下代码re_4和re_5对比),所以当匹配规则不能直接通过单个字符匹配时,需要加一些标识,在替换后的字符串也要加上相关标识,如下代码re_6识别出文章的名称然后替换为另外一个名称,但是要保留书名号。
import re
content = '《Python 基础合集13:错误的调试和处理》是我最近发布的一篇推文,链接:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日,开发语言:Python。'
# 对比括号作用
re_4 = re.sub(r'《Python.*。','java',content)
re_5 = re.sub(r'《(Python).*。','java',content)
print('%s\n%s'% (re_4,re_5))
# 结果都是:java
# 替换文章名称
re_6 = re.sub(r'《.*?》','《正则讲义》',content)
print(re_6) # 结果为:《正则讲义》是我最近发布的一篇推文,链接:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日,开发语言:Python。
sub()的匹配规则中的括号虽然不能直接匹配出来,但是并非无用。可以通过编码(\+数字)来指定对应的匹配结果,注意,这里的**\**表示一个反斜杠,由于在Python中它有转义含义,所以,需要使用**\\**表示一个反斜杠。
具体例子如下:\1表示第1个括号的匹配结果,\2表示第2个括号的匹配结果,以此类推,\N表示第N个括号的匹配结果。当然前提是要存在对应数量的匹配组。
替换字符串在调用前面的匹配结果的时候,也可以使用\g<N>,N表示第N个括号的匹配结果。
指定匹配组,还可以在编写规则时指定自定义名称,如下re_9,使用(?P<自定义名称>匹配规则)定义匹配组的名称。
除了在替换字符串中使用别名指定匹配组,还可以在匹配规则中使用,如下代码re_10和re_11,需要注意的是不能使用自定义名称。
简单来讲,**\N**是通用的,可以记住该用法即可。
import re
content = '《Python 基础合集13:错误的调试和处理》是我最近发布的一篇推文,链接:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日,开发语言:Python。'
# 替换第一个Python为java
re_7 = re.sub(r'《(Python)(.*。)','《java\\2',content)
re_8 = re.sub(r'《(Python)(.*。)','《java\g<2>',content)
print('%s\n%s'% (re_7,re_8))
# 结果都是:《java 基础合集13:错误的调试和处理》是我最近发布的一篇推文,链接:https://blog.csdn.net/qq_45476428/article/details/127482593,发布时间:2022年10月24日,开发语言:Python。
# 命名匹配规则组
re_9 = re.sub(r'《(?P<language>Python)(?P<other_str>.*。)','《java\g<other_str>',content)
print(re_9) # 结果同re_8
# 在匹配规则中也可使用\N,匹配两个Python之间的所有字符替换为Python
re_10 = re.sub(r'《(Python).*\\1','\\1',content)
re_11 = re.sub(r'《(?P<language>Python).*\\1','\\1',content)
print('%s\n%s'% (re_10,re_11)) # 结果都是:Python。
sub()的第二个参数还可以是一个函数。
以下代码为例,先定义一个函数判断分数的等级,然后将函数名传递给第二个参数repl,也就是替换字符串参数。
在判断分数时,有两个细节点需要注意,调用sub()时传递的值是需要通过group()获取对应的数字;此时数字是字符串格式,需要转化为整型或浮点型。
这里不是调用(调用需要传值),而是直接把函数名传进去,正则能实现自动给其传递参数并返回。
import re
def judge_level(value):
# 用group方法获取到匹配结果
value = value.group()
if float(value) >= 85:
return '优'
elif float(value) >= 60:
return '良'
else:
return '差'
content = '{"小A":59, "小B":66, "小C":83, "小D": 98}'
re_12 = re.sub(r'\d+', judge_level, content)
print(re_12) # 结果为:{"小A":差, "小B":良, "小C":良, "小D": 优}
不知道作为读者,你看到这个返回的结果是有什么感觉?
看似字典,又非字典,这不是个好的数据结构,如果要转化为字典使用该数据还需要进行进一步处理。
一种方法是对转化后的字符串进行替换,如下re_13;
一种方法是在函数中给每一个评级加上一个引号,然后再进行转化,如下re_14。
# 对转化后的字符串re_12进行替换
re_13 = re.sub(r'(\W+)(\w+)([,}])', ':\\1"\\2"\\3', re_12)
print(re_13)
# 修改判断函数,加上引号
import re
def judge_level(value):
# 用group方法获取到匹配结果
value = value.group()
if float(value) >= 85:
return '"优"'
elif float(value) >= 60:
return '"良"'
else:
return '"差"'
content = '{"小A":59, "小B":66, "小C":83, "小D": 98}'
re_14 = re.sub(r'\d+', judge_level, content)
print(re_14)
# 结果都是:{"小A":"差", "小B":"良", "小C":"良", "小D": "优"}
# 注意:以上得到的结果是一个字典结构的字符串,转化字典可以通过json.loads()
import json
dict_re_13 = json.loads(re_13)
dict_re_14 = json.loads(re_14)
3.5 re.split(‘匹配规则’ , ‘字符串’, maxsplit=0, flags=0)
如果maxsplit非零, 最多进行maxsplit次分隔, 剩下的字符全部返回到列表的最后一个元素。
如果分隔符匹配规则匹配到字符串的开始,结果将会以一个空字符串开始,对于结尾也是一样(如下例子)。
import re
content = '..Words, words, words.'
re_1 = re.split(r'\W+',content) # 结果为:['', 'Words', 'words', 'words', '']
re_2 = re.split(r'(\W+)',content) # 结果为:['', '..', 'Words', ', ', 'words', ', ', 'words', '.', '']
re_3 = re.split(r'\W+',content,2) # 结果为:['', 'Words', 'words, words.']
print('%s\n%s\n%s'% (re_1,re_2,re_3))
样式的空匹配,仅在与前一个空匹配不相邻时才会拆分字符串。
import re
content = 'Words, words, words.'
re_1 = re.split(r'\b', content) # 结果为:['', 'Words', ', ', 'words', ', ', 'words', '.']
re_2 = re.split(r'\B', content) # 结果为:['W', 'o', 'r', 'd', 's,', ' w', 'o', 'r', 'd', 's,', ' w', 'o', 'r', 'd', 's.', '']
print('%s\n%s'% (re_1,re_2))
3.6 re.compile(‘匹配规则’, flags=0)
以上介绍的5种方法都可以通过re.compile()加上对应函数的方法实现相同的目标。compile()更像是一个临时的容器,存放匹配规则,具体匹配结果需要根据对应的方法来确定。
具体看以下例子:
import re
content = 'Python12\\34中文'
patterns = re.compile(r'([A-Za-z]+)(\d+)')
# findall()
re_1_1 = patterns.findall(content)
re_1_2 = re.findall(r'([A-Za-z]+)(\d+)',content)
print('%s\n%s'%(re_1_1,re_1_2)) # 结果都是:[('Python', '12')]
# match()
re_2_1 = patterns.match(content).groups()
re_2_2 = re.match(r'([A-Za-z]+)(\d+)',content).groups()
print('%s\n%s'%(re_2_1,re_2_2)) # 结果都是:('Python', '12')
# search()
re_3_1 = patterns.search(content).groups()
re_3_2 = re.search(r'([A-Za-z]+)(\d+)',content).groups()
print('%s\n%s'%(re_3_1,re_3_2)) # 结果都是:('Python', '12')
# sub()
re_4_1 = patterns.sub('',content)
re_4_2 = re.sub(r'([A-Za-z]+)(\d+)','',content)
print('%s\n%s'%(re_4_1,re_4_2)) # 结果都是:\34中文
# split()
re_5_1 = patterns.split(content)
re_5_2 = re.split(r'([A-Za-z]+)(\d+)',content)
print('%s\n%s'%(re_5_1,re_5_2)) # 结果都是:['', 'Python', '12', '\\34中文']
# 也可以采用链式表示
re_1_3 = re.compile(r'([A-Za-z]+)(\d+)').findall(content) # 同re_1_1
re_2_3 = re.compile(r'([A-Za-z]+)(\d+)').match(content).groups() # 同re_2_1
re_3_3 = re.compile(r'([A-Za-z]+)(\d+)').search(content).groups() # 同re_3_1
re_4_3 = re.compile(r'([A-Za-z]+)(\d+)').sub('',content) # 同re_4_1
re_4_3 = re.compile(r'([A-Za-z]+)(\d+)').split(content) # 同re_5_1
四、场景
4.1 匹配数字
import re
content = '评分:9.1分,评论数:123456789'
# 单个数
re_1 = re.findall(r'\d', content)
print(re_1) # 结果为:['9', '1', '1', '2', '3', '4', '5', '6', '7', '8', '9']
# 多个数
re_2 = re.findall(r'\d+', content)
print(re_2) # 结果为:['9', '1', '123456789']
# 取完整评分和评论数,没有标准答案~
re_3 = re.findall(r'(\d{1,2}\.\d{1,2}).*?(\d+)', content)
print(re_3) # 结果为:[('9.1', '123456789')]
4.2 匹配中文
import re
# 所有中文
content = '评分:9.1分,评论数:123456789'
re_1 = re.findall(r'[\u4e00-\u9fff]+', content)
print(re_1) # 结果为:['评分', '分', '评论数']
# 只取关键中文字眼,评分和 评论数
re_2 = re.findall(r'([\u4e00-\u9fff]+):.*?([\u4e00-\u9fff]+):', content)
print(re_2) # 结果为:[('评分', '评论数')]
爬过QQ音乐的小伙伴可能会遇到过类似以下的字符串,通过以上方法取出中文便十分简单。
[ti#58;晴天]#10;[ar#58;周杰伦]#10;
4.3 匹配链接
可用于爬虫数据提取网址。
import re
content = '<a href="http://news.baidu.com" target="_blank" class="mnav c-font-normal c-color-t">新闻</a>'
re_1 = re.findall(r'<a href="(http.*com)".*',content)
print(re_1) # 结果为:['http://news.baidu.com']
补充:startswith('匹配字符',begin,end)和endswith('匹配字符',begin,end)
二者的参数一样,不同在于startswith()匹配开头,而endswith()匹配结尾。
begin:被匹配字符串开始位置的索引,索引逻辑同字符串end:被匹配字符串结束位置的索引,索引逻辑同字符串
begin和end相当于是给被匹配字符串进行切片,即被匹配字符串[begin : end]。
content = 'http://news.baidu.com'
print(content.startswith('http',0,4)) # True
print(content.endswith('.com',-5,)) # True
4.4 去掉不可见字符
可用于爬虫字符串数据处理。
import re
content = ' 评分: 9.1 分 \n 评论数: 123456789 '
re_1 = re.sub(r'\s+','', content) # 匹配不可见字符
print(re_1) # 结果为:评分:9.1分评论数:123456789
# 将分和评论数分开
re_2 = re.sub(r'\s+','', content.replace('\n',',')) # 匹配不可见字符
print(re_2) # 结果为:评分:9.1分,评论数:123456789
五、小结