need
Most of the pdf files are converted from publications or word, with headers and footers. When identifying the content, the content of the header and footer will be recognized, resulting in a lot of useless information in the content. When identifying the content, you can, According to the size of the header and footer set in advance, this part of the content is ignored.
This tutorial is also applicable to the specified rectangular area recognition. And the result of the recognition is to recognize the paragraphs, avoiding the confusion of text and line breaks. This tutorial uses pdfbox for operation. Proceed as follows:
prerequisite preparation
Developers need to understand a premise. In the process of pdf recognition, the coordinate system starts from the upper left corner (0, 0), and the lower right corner is positive.
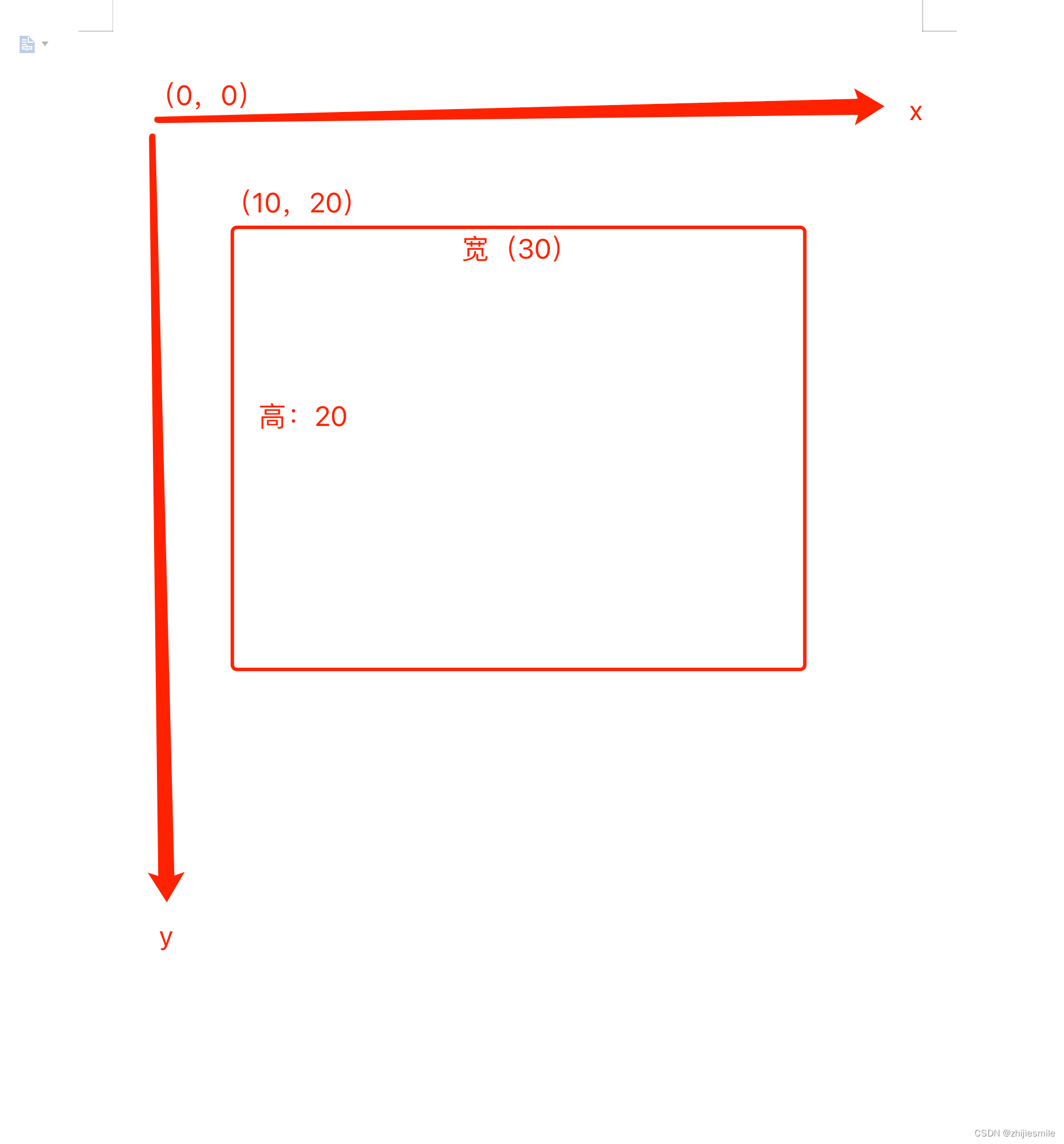
code example start
Introduce dependencies
<dependency>
<!-- 主要是这个依赖包 -->