The weekly learning sharing is recorded here, published on Monday/Tuesday, and the article is maintained on Github: studeyang/leanrning-share .
review
In the article "Redis's String type occupies so much memory" , we learned the underlying structure of SDS and found that SDS stores a lot of metadata, coupled with the implementation of the global hash table, making the Redis String type in terms of memory usage Not ideal.
Then in the article "Learning and Sharing (Phase 1) Redis: Using Hash Types to Save Memory" , we learned another way to save memory. Using the Hash type of the ziplist structure, the memory usage is reduced by half, and the effect is remarkable.
Although we take up more memory after using the String type, in fact Redis has made a memory-saving design for SDS. In addition, Redis also considers memory overhead in other aspects. Today we will take a look at the memory-saving designs from the source code level.
The code version in this article is 6.2.4.
1. Bit field definition method of redisObject
We know that redisObject is an encapsulation of underlying data structures such as SDS and ziplist. Therefore, if redisObject can be optimized, it can eventually bring a memory-saving user experience. server.hThe structure of redisObject is defined in the source code , as shown in the following code:
#define LRU_BITS 24
typedef struct redisObject {
unsigned type:4;//对象类型(4位=0.5字节)
unsigned encoding:4;//编码(4位=0.5字节)
unsigned lru:LRU_BITS;//记录对象最后一次被应用程序访问的时间(24位=3字节)
int refcount;//引用计数。等于0时表示可以被垃圾回收(32位=4字节)
void *ptr;//指向底层实际的数据存储结构,如:sds等(8字节)
} robj;
type, encoding, lru, and refcount are all metadata of redisObject, and the structure of redisObject is shown in the figure below.

From the code, we can see that there is a colon after the three variables of type, encoding and lru, followed by a value, indicating the number of bits occupied by the metadata. This method of defining a variable with a colon and a value is actually a bit field definition method in C language, which can be used to effectively save memory overhead.
The more suitable scenario for this method is that when a variable cannot occupy all the bits of a data type, the bit field definition method can be used to divide the bits (32 bits) in a data type into multiple (3) Bit fields, each bit field occupies a certain number of bits. In this way, all bits of a data type can define multiple variables, thus effectively saving memory overhead.
In addition, in the design of SDS, there are also memory-optimized designs. Let's take a look at them in detail.
2. Design of SDS
After Redis version 3.2, SDS changed from one data structure to five data structures. They are sdshdr5, sdshdr8, sdshdr16, sdshdr32 and sdshdr64, among which sdshdr5 is only applied to the key in Redis, and the other four different types of structure headers can adapt to strings of different sizes.
Taking sdshdr8 as an example, its structure definition is as follows:
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
I don't know if you have noticed that it is used between struct and sdshdr8 __attribute__ ((__packed__)). This is a memory-efficient design of SDS - compact strings.
2.1 Compact strings
What is a compact string?
Its role is to tell the compiler not to use byte alignment when compiling the sdshdr8 structure, but to allocate memory in a compact way. By default, the compiler allocates memory for variables in an 8-byte alignment. That is, even if the size of a variable is less than 8 bytes, the compiler will allocate 8 bytes to it.
for example. Suppose I define a structure st1, which has two member variables, the types are char and int, as follows:
#include <stdio.h>
int main() {
struct st1 {
char a;
int b;
} ts1;
printf("%lu\n", sizeof(ts1));
return 0;
}
We know that the char type occupies 1 byte and the int type occupies 4 bytes, but if you run this code, you will find that the printed result is 8. This is because by default, the compiler will allocate 8 bytes of space to the st1 structure according to the 8-byte alignment, but in this way, 3 bytes will be wasted.
Then I use __attribute__ ((__packed__))the attribute to redefine the structure st2, which also contains two types of member variables: char and int. The code is as follows:
#include <stdio.h>
int main() {
struct __attribute__((packed)) st2{
char a;
int b;
} ts2;
printf("%lu\n", sizeof(ts2));
return 0;
}
When you run this code, you can see that the printed result is 5, which is compact memory allocation, and the st2 structure only occupies 5 bytes of space.
In addition, Redis has also made such an optimization: when the saved string is less than or equal to 44 bytes, the metadata, pointers and SDS in RedisObject are a continuous memory area. This layout is called embstr encoding method; when the string is larger than 44 bytes, SDS and RedisObject are laid out separately, and this layout method is called raw coding mode.

The code for this part is in object.cthe file:
#define OBJ_ENCODING_EMBSTR_SIZE_LIMIT 44
robj *createStringObject(const char *ptr, size_t len) {
// 当字符串长度小于等于44字节,创建嵌入式字符串
if (len <= OBJ_ENCODING_EMBSTR_SIZE_LIMIT)
return createEmbeddedStringObject(ptr,len);
//字符串长度大于44字节,创建普通字符串
else
return createRawStringObject(ptr,len);
}
When the length of len is less than or equal to OBJ_ENCODING_EMBSTR_SIZE_LIMIT(44 bytes by default), createStringObjectthe function will call createEmbeddedStringObjectthe function. This is the second memory saving design of SDS - Embedded Strings.
Before talking about embedded strings, let's take a look at the OBJ_ENCODING_EMBSTR_SIZE_LIMITcreation process of such ordinary strings when the length of len is greater than (44 bytes by default).
2.2 RawString ordinary string
For createRawStringObjectthe function, it will call the function when creating a value of type String createObject. createObjectFunctions are mainly used to create Redis data objects. The code is shown below.
robj *createRawStringObject(const char *ptr, size_t len) {
return createObject(OBJ_STRING, sdsnewlen(ptr,len));
}
createObjectThe function has two parameters, one is used to indicate the type of data object to be created, and the other is a pointer to the SDS object, which is sdsnewlencreated through the function.
robj *createObject(int type, void *ptr) {
// 【1】给redisObject结构体分配内存空间
robj *o = zmalloc(sizeof(*o));
//设置redisObject的类型
o->type = type;
//设置redisObject的编码类型
o->encoding = OBJ_ENCODING_RAW;
// 【2】将传入的指针赋值给redisObject中的指针
o->ptr = ptr;
…
return o;
}
After calling sdsnewlenthe function to create the pointer of the SDS object, it also allocates a piece of SDS memory space. Then, createObjectthe function will redisObjectallocate memory space for the structure, as shown in the above code [1]. Then assign the passed in pointer to the pointer in redisObject, as shown in the above code [2].
Let's look at embedded strings next.
2.3 EmbeddedString embedded string
From the above, we know that when the saved string is less than or equal to 44 bytes, the metadata, pointer and SDS in RedisObject are a continuous memory area. So createEmbeddedStringObjecthow does the function put redisObjectand the memory area of SDS together?
robj *createEmbeddedStringObject(const char *ptr, size_t len) {
// 【1】
robj *o = zmalloc(sizeof(robj)+sizeof(struct sdshdr8)+len+1);
...
if (ptr == SDS_NOINIT)
sh->buf[len] = '\0';
else if (ptr) {
// 【2】
memcpy(sh->buf,ptr,len);
sh->buf[len] = '\0';
} else {
memset(sh->buf,0,len+1);
}
return o;
}
First, createEmbeddedStringObjectthe function will allocate a piece of continuous memory space, the size of this memory space is equal to the sum redisObjectof the size of the structure + the size of SDSthe structure header sdshdr8+ the size of the string, plus a 1-byte end character "\0". This part of the code is as above [1].

A contiguous memory space is allocated first, thus avoiding memory fragmentation.
Then, createEmbeddedStringObjectthe function will copy the character string pointed to by the pointer ptr passed in the parameter to the character array in the SDS structure, and add an end character at the end of the array. This part of the code is as above [2].
Well, the above are the two optimization points for Redis to save memory in designing the SDS structure. However, in addition to embedded strings, Redis also designed a compressed list, which is also a compact memory data structure. Let's learn more Under its design ideas.
Third, the design of the compressed list
In order to facilitate the understanding of the design and implementation of the zip list, let's take a look at its creation function ziplistNew. This part of the code is in the ziplist.cfile, as shown below:
unsigned char *ziplistNew(void) {
// 初始分配的大小
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
…
// 将列表尾设置为ZIP_END
zl[bytes-1] = ZIP_END;
return zl;
}
It can be seen that ziplistNewthe logic of the function is very simple. It is to create a continuous memory space whose size is the sum of ZIPLIST_HEADER_SIZE and ZIPLIST_END_SIZE, and then assign the last byte of the continuous space to ZIP_END, indicating the end of the list.
In addition, ziplist.cthe values of ZIPLIST_HEADER_SIZE, ZIPLIST_END_SIZE and ZIP_END are also defined in the file, which represent the ziplist header size, tail size and tail byte content of the ziplist, as shown below.
//ziplist的列表头大小
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2 + sizeof(uint16_t))
//ziplist的列表尾大小
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
//ziplist的列表尾字节内容
#define ZIP_END 255
The list header includes two 32-bit integers and one 16-bit integer, respectively representing the total number of bytes zlbytes of the compressed list, the offset zltail of the last element of the list from the list header, and the number of elements in the list zllen; the list tail includes An 8-bit integer indicating the end of the list. After executing ziplistNewthe function to create a ziplist, the memory layout is as shown in the figure below.

Note that there is no actual data in the ziplist at this time, so it is not drawn in the figure.
Then, when we insert data into the ziplist, the complete memory layout is shown in the figure below.
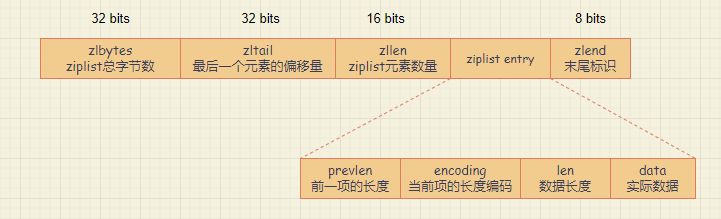
The ziplist entry includes three parts, which are the length of the previous item (prevlen), the encoding result of the length information of the current item (encoding), and the actual data of the current item (data).
When we insert data into the ziplist, the ziplist will encode differently according to whether the data is a string or an integer, and their size. This design idea of encoding according to the data size is exactly what Redis uses to save memory.
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
...
/* Write the entry */
p += zipStorePrevEntryLength(p,prevlen);
p += zipStoreEntryEncoding(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}
The source code here will be mentioned below, for the convenience of description, it is marked here as [source code A].
In addition, the length of the previous item will be recorded in each list item entry, because the length of each list item is different, Redis will select different sizes of bytes to record prevlen according to the data length.
3.1 Use bytes of different sizes to record prevlen
For example, suppose we uniformly use 4 bytes to record prevlen. If the previous list item is just a 5-byte string "redis", then we can use 1 byte (8 bits) to represent 0~256 bytes length of the string. At this time, prevlen uses 4 bytes to record, and 3 bytes are wasted.
Let's take a look at how Redis selects bytes of different sizes to record prevlen according to the data length.
Through the above __ziplistInsertfunction, which is [source code A], we can see that when ziplist encodes prevlen, it will call zipStorePrevEntryLengththe function first, and the function code is as follows:
unsigned int zipStorePrevEntryLength(unsigned char *p, unsigned int len) {
if (p == NULL) {
return (len < ZIP_BIG_PREVLEN) ? 1 : sizeof(uint32_t) + 1;
} else {
//判断prevlen的长度是否小于ZIP_BIG_PREVLEN
if (len < ZIP_BIG_PREVLEN) {
//如果小于254字节,那么返回prevlen为1字节
p[0] = len;
return 1;
} else {
//否则,调用zipStorePrevEntryLengthLarge进行编码
return zipStorePrevEntryLengthLarge(p,len);
}
}
}
It can be seen that zipStorePrevEntryLengththe function will determine whether the previous list item is smaller than ZIP_BIG_PREVLEN (the value of ZIP_BIG_PREVLEN is 254). If yes, then prevlen is represented by 1 byte; otherwise, zipStorePrevEntryLengththe function calls zipStorePrevEntryLengthLargethe function for further encoding.
zipStorePrevEntryLengthLargeThe function will first set the first byte of prevlen to 254, and then use the memory copy function memcpy to copy the length value of the previous list item to the second to fifth bytes of prevlen. Finally, zipStorePrevEntryLengthLargethe function returns the size of prevlen, which is 5 bytes.
int zipStorePrevEntryLengthLarge(unsigned char *p, unsigned int len) {
uint32_t u32;
if (p != NULL) {
//将prevlen的第1字节设置为ZIP_BIG_PREVLEN,即254
p[0] = ZIP_BIG_PREVLEN;
u32 = len;
//将前一个列表项的长度值拷贝至prevlen的第2至第5字节,其中sizeof(u32)的值为4
memcpy(p+1,&u32,sizeof(u32));
...
}
//返回prevlen的大小,为5字节
return 1 + sizeof(uint32_t);
}
Well, after understanding that prevlen uses two encoding methods of 1 byte and 5 bytes, let's learn the encoding method of encoding.
3.2 Use bytes of different sizes to record encoding encoding
Let's go back to the above function, which is [source code A], we can see that after the function logic __ziplistInsertis executed , the function will be called immediately.zipStorePrevEntryLengthzipStoreEntryEncoding
In the ziplist zipStoreEntryEncodingfunction, encoding results of different byte lengths are used for integers and strings.
unsigned int zipStoreEntryEncoding(unsigned char *p, unsigned char encoding, unsigned int rawlen) {
//默认编码结果是1字节
unsigned char len = 1;
//如果是字符串数据
if (ZIP_IS_STR(encoding)) {
//如果字符串长度小于等于63字节(16进制为0x3f)
if (rawlen <= 0x3f) {
//默认编码结果是1字节
if (!p) return len;
...
}
//字符串长度小于等于16383字节(16进制为0x3fff)
else if (rawlen <= 0x3fff) {
//编码结果是2字节
len += 1;
if (!p) return len;
...
}
//字符串长度大于16383字节
else {
//编码结果是5字节
len += 4;
if (!p) return len;
...
}
} else {
/* 如果数据是整数,编码结果是1字节 */
if (!p) return len;
...
}
}
It can be seen that when the data are strings or integers of different lengths, the length len of the encoding result is different.
In short, for data of different lengths, using metadata information prevlen and encoding of different byte sizes to record, this method can effectively save memory overhead.

the cover

References
- Geek Time "Redis Source Code Analysis and Actual Combat"
- redis source code v6.2.4: https://github.com/redis/redis/tree/6.2.4
related articles
Maybe you are also interested in the following article.