Author of this article: Byte, Chief Scientist of Guanyuan Data. Leading the application of multiple AI projects in the world's top 500 companies, and winning the Hackathon championship in the direction of smart retail for many times. He once worked in MicroStrategy and Alibaba Cloud, and has more than ten years of industry experience.
In the previous article, we introduced the composition and construction of the cloud-native machine learning platform [1]. In actual enterprise applications, the machine learning platform is very dependent on the underlying data platform of the enterprise. Although the upsurge of AI has been wave after wave in the past two years, it is very dependent on the infrastructure of the data platform to implement the algorithm application well. It can also be seen from some analysis reports [2] of a16z that data platform companies have attracted a lot of market and capital attention, and concepts such as modern data stack [3] have emerged as the times require . In this article, let's talk about what is the so-called cloud native data platform.
1. Development history
The earliest data platform came from relational database (RDBMS) technology. From the beginning, it started with the OLTP system that recorded business operation data, and gradually developed the related requirements for data analysis of business conditions and further decision-making, which is the so-called OLAP. system, which contains many classic theories and technical methods.
In the 1980s, there was a design method of establishing a data warehouse system (Data Warehouse) for data analysis needs, which became the earliest generation of "data platform" system. In 1992, the famous "Father of Data Warehouse" Bill Inmon published the book "Building the Data Warehouse", which formed a set of top-down and centralized methodologies for building enterprise-level data warehouses. Another tycoon, Ralph Kimball, published the book "The Datawarehouse Toolkit" in 1996, and proposed the idea of building an enterprise-level data warehouse based on the concept of Data Mart from the bottom up. In the 1990s, the books of these two masters almost became the must-read authoritative works for practitioners, and the concept of enterprise-level data warehouses gradually became popular, and was widely adopted and deployed by major enterprises together with BI analysis applications. At that time, the mainstream software systems all came from major commercial closed-source software, such as IBM DB2, SQL Server, Teradata, Oracle, etc.
At the beginning of the 21st century, the concept of the Internet began to rise, and in terms of data processing and analysis, the challenge of "big data" also emerged as the times require. Traditional data warehouse technology has been difficult to cope with the massive data in the Internet era, rapidly changing data structures, and various semi-structured and unstructured data storage and processing requirements. Starting from the three classic papers (MapReduce, GFS, BigTable) published by Google, a distributed data system technology stack different from traditional relational database technology has emerged. This trend was later carried forward by the Hadoop open source ecosystem, which has had a profound impact on the industry for more than ten years. I remember attending various technical conferences at that time, and everyone was talking about technologies and concepts such as "data lake", NoSQL, SQL on Hadoop, etc. Most of the data platforms adopted by Internet companies were based on Hadoop's open source ecosystem (HDFS, Yarn, HBase, Hive, etc.). The famous Hadoop Troika, Cloudera, Hortonworks and MapR have also emerged on the market.
With the rise of the wave of cloud computing led by AWS, everyone is increasingly aware of various problems in the Hadoop system architecture, including storage and computing resource binding, very high difficulty and cost of operation and maintenance, and cannot well support streaming data. processing, interactive queries, etc. A very big change in the cloud native era is that everyone tends to reduce the cost of ownership and operation and maintenance of various systems, and cloud vendors provide professional services. Another major trend is the pursuit of extreme "elasticity" capabilities. For example, some cloud data warehouses can even charge for the amount of computing consumed by a single query. These requirements are relatively difficult to achieve in the Hadoop ecosystem, so the concept of a new generation of cloud-native data platforms has gradually emerged, which is also the main topic of this article.
2. Data platform architecture
2.1 Classic Data Warehouse Architecture
From a traditional perspective, a data platform is approximately equal to a data warehouse platform. Therefore, only ETL tools are needed to load data from various data sources into the data warehouse, and then use SQL to perform various processing, conversion, and build a hierarchical data warehouse system, and then provide external services through the SQL interface:
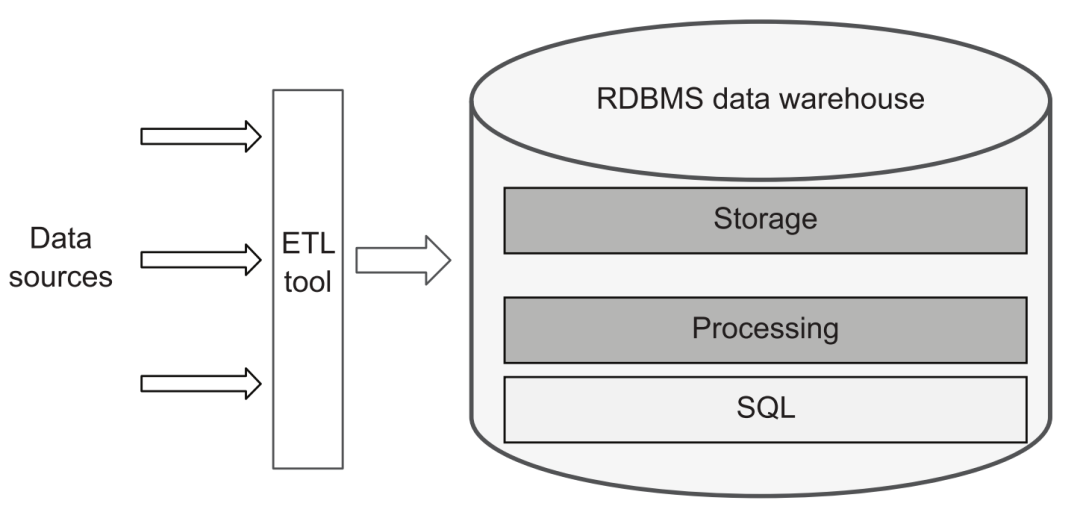
traditional data platform
2.2 Data Lake Architecture
However, with the development of business, everyone gradually has more requirements for the capabilities of the data platform, including some of the classic four Vs:
-
Variaty, the diversity of data. For example, it is necessary to store and process various semi-structured Json, Avro, and ProtoBuf data, or unstructured text, images, audio, and video. The processing of these contents is often difficult for SQL to deal with. In addition, the requirements have become more diverse. In addition to BI analysis, AI analysis and modeling requirements, and the consumption of analysis results by business systems have become more and more common.
-
Volume, the magnitude of the data. With the transformation of business online and digitalization, data-driven thinking is becoming more and more popular, and the amount of data that modern enterprises need to store and process is also becoming larger and larger. Although traditional commercial data warehouse software can support horizontal expansion, its architecture is often bound with storage and computing, which leads to huge overhead. This is also a very significant point of difference in modern data platforms.
-
Velocity, the speed of data change. In some data application scenarios, the need for automated real-time decision-making has gradually begun to emerge. For example, after a user browses some products, the system can obtain new behavioral data and update the user's recommended content in real time; or make an automatic risk control review decision based on the user's behavior in the last few minutes, etc. In this case, the traditional T+1 data warehouse operation obviously cannot meet the demand.
Driven by these requirements, the architecture of the data platform has evolved towards a more complex structure, and many well-known big data system components such as Hadoop and Spark have also begun to be introduced. Among them, the well-known Lambda Architecture proposed by Storm author Nathan Marz:
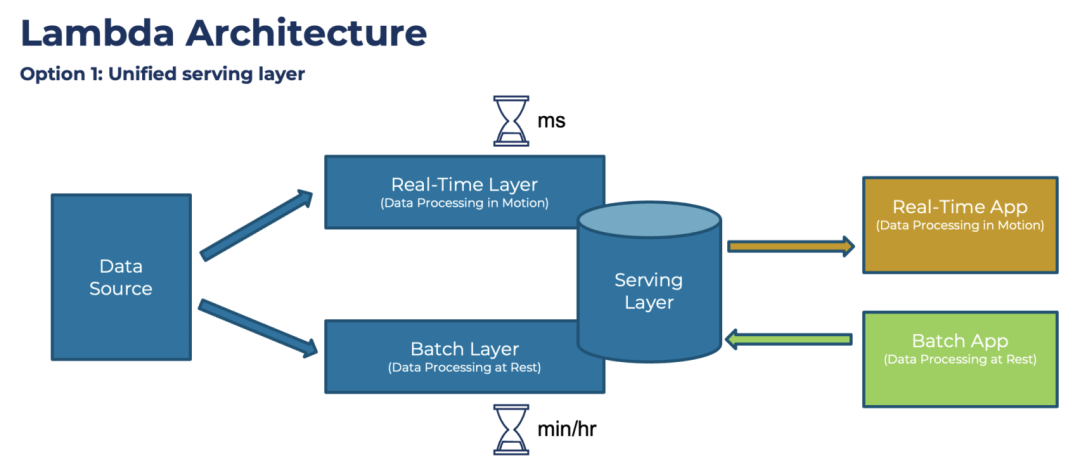
Lambda architecture
The design of this architecture has undergone a lot of experience summarization and deliberation. The core is the batch processing (Batch Layer) of the full amount of data every day. Compared with the traditional SQL-based data conversion, it can support richer data types and processing methods. At the same time, with the help of the Hadoop architecture, it can also support a larger amount of data. At the same time, in order to support "real-time" requirements, a stream processing layer (Real-Time Layer) is added. Finally, when data is consumed, the two pieces of data can be combined (Serving Layer) to form the final result. However, this architecture has also been criticized, especially the need to maintain two sets of computing frameworks, batch processing and real-time, and to implement the same processing logic twice, which is insufficient in terms of architectural complexity and development and maintenance costs. Later, Jay Kreps, the author of Kafka, proposed the Kappa architecture. He wanted to unify batch processing and real-time processing, which meant "stream-batch integration".
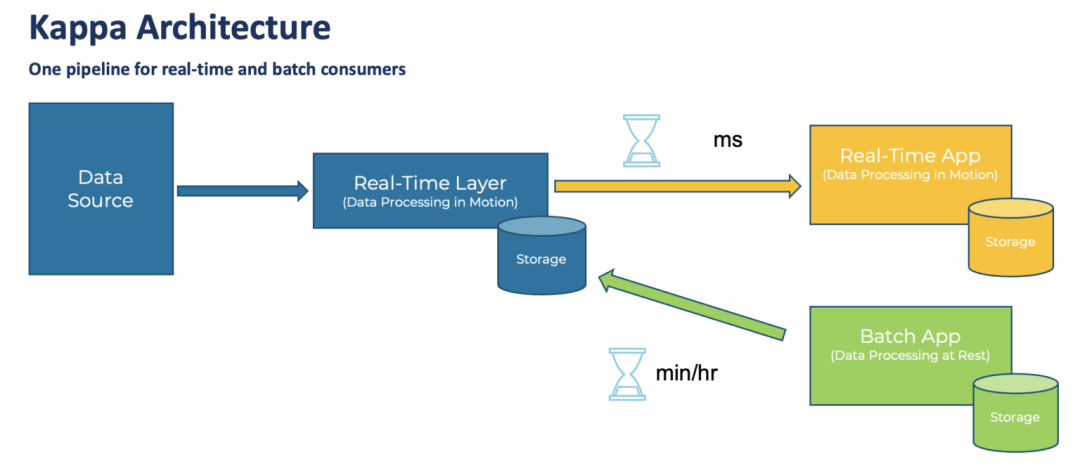
Kappa Architecture
But I personally feel that the Kappa architecture is too idealistic. Even by 2022, streaming data is far from becoming the mainstream of the industry. The data duplication of message flow, message sequence, support for complex calculations (such as real-time join), support for various source data systems, management of data schema, cost control of data storage, etc. have not yet reached a very stable level. Useful and efficient state. Therefore, it is not realistic to let an enterprise's data run entirely on the basis of a streaming data system. Therefore, the mainstream data platform architecture at this stage actually combines the batch processing system with the real-time processing system based on business requirements and the maturity of the whole process system.
2.3 Cloud Native Architecture
For the combination requirements of various components, with the advent of the cloud-native era, more and more SaaS data products that are easier to "assemble and use" have emerged. Compared with the complexity of deploying and maintaining Hadoop and Kafka clusters in the past, the new generation of cloud-native products generally can directly use hosting services, pay as you go, and use them out of the box, which is very friendly to non-Internet companies. Therefore, common data platform architectures have begun to develop in the direction of introducing various product components , and many interesting new ideas have emerged:
-
At the data processing level, different computing engines are used to perform batch processing or stream processing tasks, but for the user interface, it is hoped to be as consistent as possible, so there is the so-called "stream-batch integration".
-
In terms of storage and data services, the "data lake" and "data warehouse" used to be in contention, but after several years of development, they found that they could not completely replace each other. Therefore, the data lake camp has added a lot of support for functions such as SQL, Schema, and data management, and has become a new species of lakehouse. And data warehouses are also becoming cloud-native, and many cloud data warehouses also support the use of their computing engines to directly compute and process files on the data lake. "Hucang integration" has also become a popular term.
-
In addition, there are requirements for batch and single-point query features in the feature store, "HSAP" born from the combination of real-time analysis and data consumption application requirements, and so on.
The unified data architecture overview given by the well-known investment institution a16z is very representative:
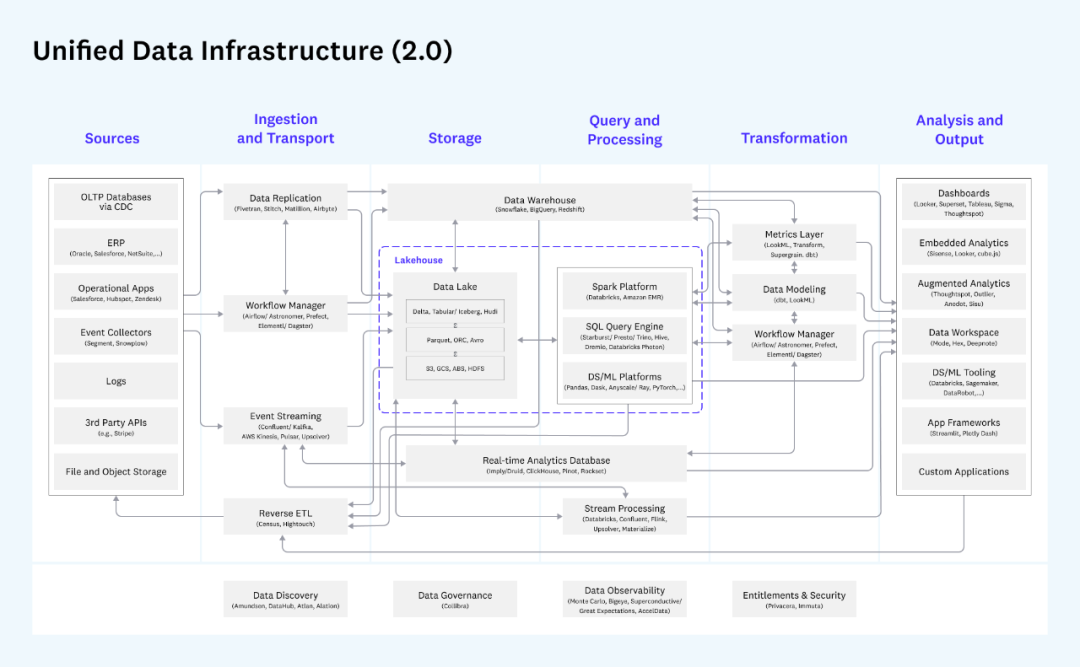
a16z's unified data architecture
This picture is very detailed. It divides the entire data transfer process into data sources (generally not included in the data platform), data acquisition and transmission, storage, query processing, data conversion and analysis output. Each block Each module and related products are marked in detail. Generally, enterprises will select some of the components for deployment according to their needs. For example, if there is no demand for streaming data, then the following part of streaming data access and processing is not needed. Unlike the Lambda architecture, for the same business scenario, it is generally not necessary to let the same piece of data go through the real-time processing link and the batch processing link twice at T+1, but choose the appropriate one. The link can be used for subsequent processing.
However, the above-mentioned architecture diagram is a bit too complicated because it takes into account the needs of different companies in different scenarios and at different stages. I personally prefer a relatively simplified architecture overview given by the author in the book "Designing Cloud Data Platform":
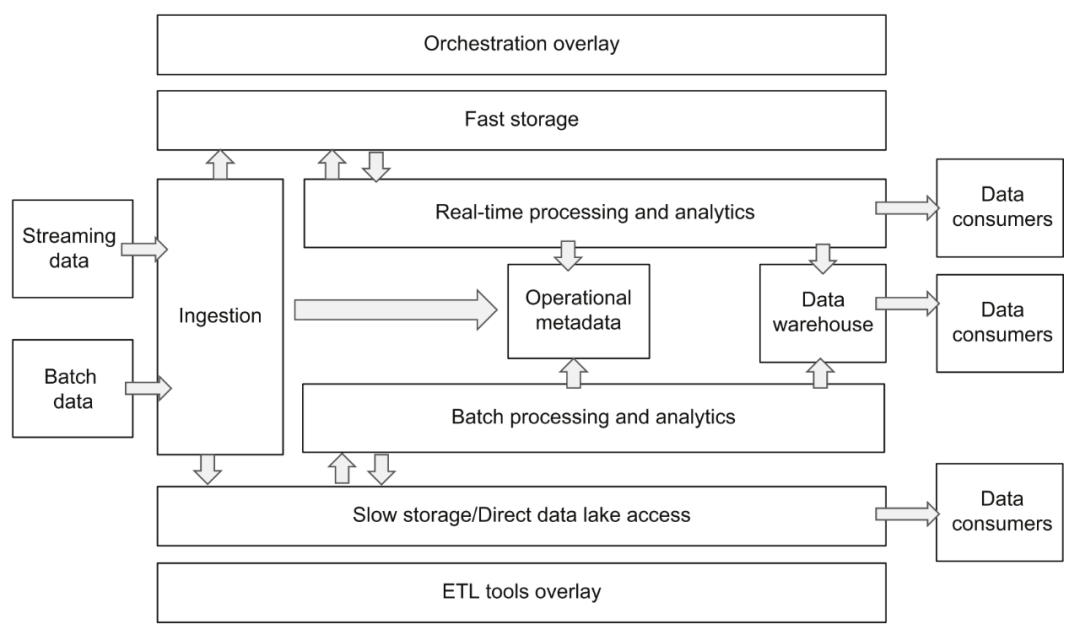
Cloud Data Platform Architecture
The core of this architecture is basically the same as the architecture reference given by a16z, but the split design of each layer is clearer, which helps us understand and plan the entire data platform. If the responsibilities and interfaces between each layer can be clearly defined, it will be very beneficial for the standardization of data flow and the flexible replacement and upgrade of component implementation. Later, we will expand and describe the various components of the cloud data platform based on these two diagrams.
Generally speaking, the evolution trend of the data platform architecture in recent years mainly has two aspects. One is to meet the diverse business needs. The overall system components of the platform are more and more, which is in a highly differentiated stage. The user remains transparent; the second is that the selection of components tends to choose products from various public cloud vendors or data SaaS platform vendors. In the case of a complex architecture, the maintenance cost is not increased too much, but the responsibilities between components are clear (loose coupling) and interface standardization remain a challenge.
3. Data Acquisition
In terms of data acquisition, the platform must be able to support both batch data and streaming data access.
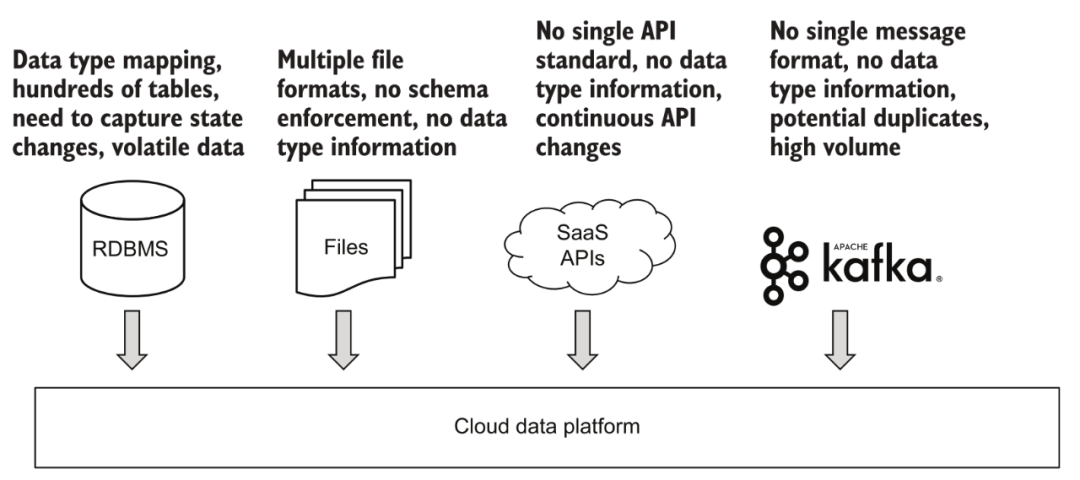
Various data access
3.1 Batch acquisition
For batch data, such as various uploaded files, ftp, or other third-party API data sources that cannot support real-time consumption. In fact, the various data sources currently connected to by most enterprises and the basic data structure within the enterprise are basically in the form of batch processing. The vast majority of platforms support this area quite well. A typical approach is to trigger tasks at regular intervals, obtain full or incrementally updated data content from data sources through components, and store them in the data platform. If the trigger setting of this task is set more frequently, we can also obtain a "quasi-real-time" updated data content through batch processing for subsequent analysis and use.
3.2 Streaming acquisition
Streaming data is a very popular trend in recent years, but it has relatively few applications outside of Internet companies. Everyone's understanding of "real time" is also different. For example, for analysis scenarios, it is generally recognized that the data update of T+1 (the next day sees the situation up to the previous day) belongs to batch processing, as long as there are multiple data updates in a day, it belongs to "real time" Analyzes. This kind of demand can be fully realized through the small batch update mentioned above. For some automatic decision-making scenarios, such as recommendation systems and transaction risk control, even if "small batch" updates at the minute level are achieved, the timeliness does not meet the requirements, and a streaming data system must be connected.
A more interesting scenario is to connect to the database data of the upstream business system. If batch access is used, the general approach is to regularly query related data tables through an update timestamp, and then save the incremental data to the data platform. This method seems to be no problem, but in fact, if the original data entry has been changed multiple times during the update time window, for example, the user first opened the membership within 5 minutes and then canceled it, through batch query, it may be possible After the two queries, the user is in the status of non-member, and the intermediate status change information is lost. This is why more and more scenarios now use CDC technology to capture real-time changes in business data, and connect to the data platform through streaming data to avoid any information loss.
The suggested construction path for this block is to first build a stable batch data access capability, then obtain streaming data, and finally consider streaming data processing and analysis (introducing Flink and the like) based on actual needs.
3.3 Demand and Products
For data acquisition components, the following requirements need to be met:
-
The plug-in architecture supports data access from multiple data sources, such as different databases, files, APIs, streaming data sources, etc., and supports flexible custom configurations.
-
Operability, because it needs to deal with various third-party systems, the record of various information, and the convenience of troubleshooting when errors occur are very important.
-
Performance and stability, in order to cope with the large amount of data and the stable operation of important analysis and decision-making processes, an enterprise-level platform quality assurance is required.
There are also many products that can be considered for data acquisition:
-
Related services of the three major clouds, such as AWS Glue, Google Cloud Data Fusion, Azure Data Factory for batch processing; AWS Kinesis, Google Cloud Pub/Sub, Azure Event Hubs for streaming data, etc.
-
Third-party SaaS services, such as Fivetran, Stitch, Matillion, Airbyte, etc. mentioned by a16z.
-
Open source frameworks such as Apache NiFi, Kafka, Pulsar, Debezium (CDC tool), etc.
-
Based on the Serverless service, the data acquisition function is developed by itself.
Note that when it comes to cloud services, third-party SaaS services, open source or self-developed tool selection, you can refer to the following figure for trade-off evaluation. The closer to the right-end products such as cloud vendors, the less investment in operation, maintenance and development is required, but the controllability and portability are relatively weak (unless they are compatible with the standard API of the open source framework); the further to the left is the opposite, use Open source products have very flexible customization (but attention should be paid to controlling the magic modification of private branches) and deployment flexibility, but the cost of R&D and operation and maintenance will be much higher.
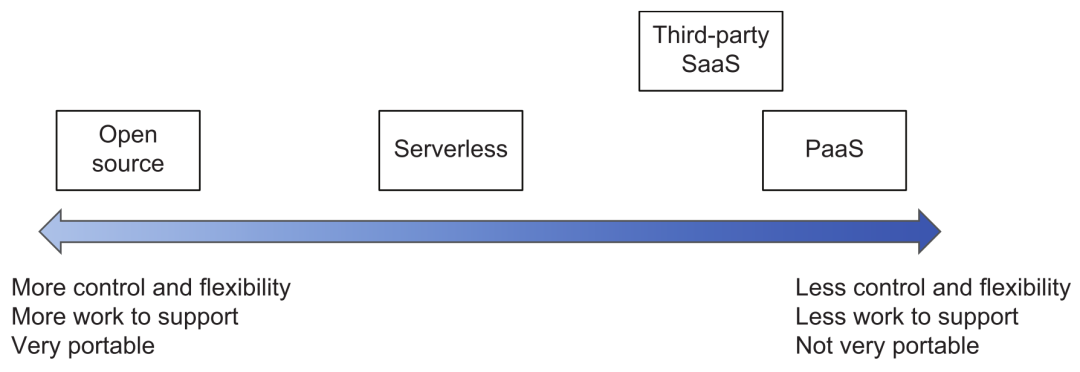
Product Selection Tradeoffs
4. Data storage
After data acquisition, the data needs to be saved to the platform storage. In the previous data platform architecture diagram, we see that the author divides the storage into two parts: fast and slow:
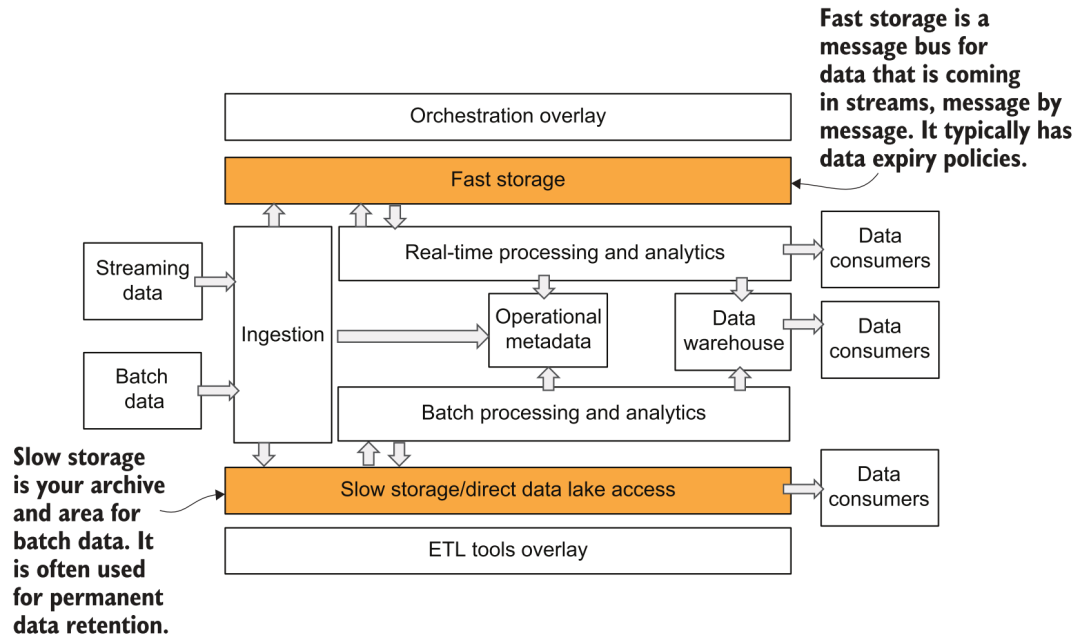
Fast and slow storage
4.1 Slow Storage
This slow storage is relatively easy to understand. In the era of data warehouses, it is the storage part of the warehouse system. In the era of big data, it is the so-called data lake. Distributed file systems such as HDFS were more popular before, and now more and more storage and calculation are used. Developing in the direction of separation, the mainstream storage methods basically choose various object storage, such as S3, GCS, ABS, etc. The storage form of the data lake is relatively free, and it is often difficult to guarantee data quality and enterprise management and control. Therefore, in the past two years, Databricks has proposed the concept of lakehouse, in which the corresponding metadata and storage are built on top of the underlying object storage. The storage protocol can support schema management, data version, transaction support and other features, which we have also introduced in the article Data Lake System in the Algorithm Platform [4].
4.2 Fast Storage
This fast storage may be easier to misunderstand. In the Lambda architecture and a16z architecture diagram, fast storage generally refers to a storage system that provides ad hoc query and real-time analysis services for data consumers. For example, we can use some analytical databases with high real-time performance (Presto, ClickHouse), or for Specific storage services such as KV system, RDBMS, etc. In the picture provided by the author, fast storage actually represents a simpler meaning, which is the built-in storage of the streaming data system, such as Kafka and the part of the Pulsar system that stores event messages. Does this feel like going back to the old way of computing and storage binding? So now both Kafka and Pulsar have begun to support tiered storage [5], improving overall scalability and reducing costs.
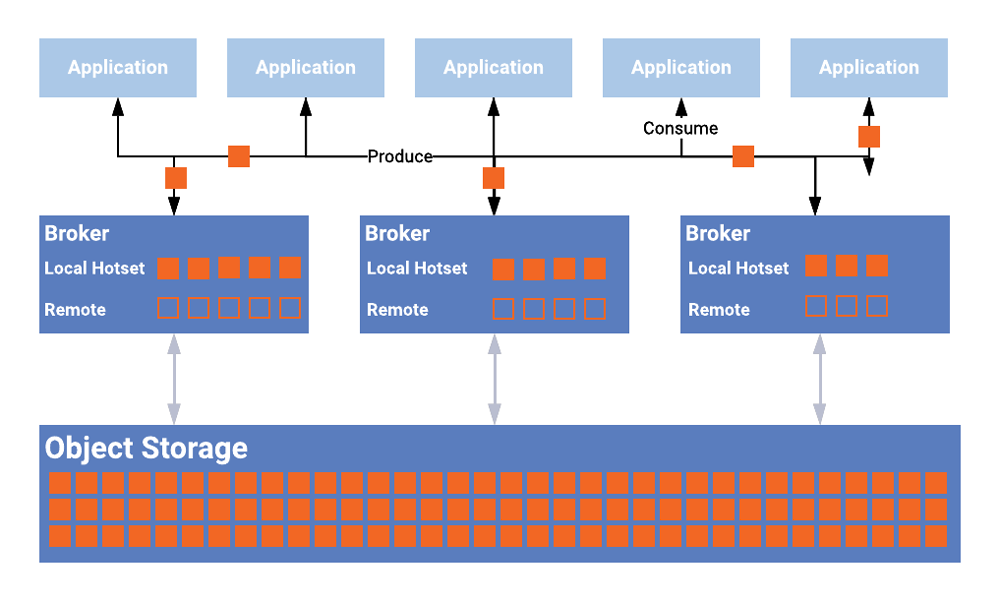
Tiered Storage
4.3 Data Access Process
The data entered from the data access layer is usually directly stored in the slow storage in the form of raw data, and then converted into the form that needs to be used later through other processing and scheduling, such as the table in the lakehouse or the data warehouse that provides external services middle. After the streaming data enters the fast storage, the real-time processing and analysis component will acquire and consume the data, and finally trigger the downstream data update. At the same time, streaming data generally saves a copy of the original data to slow storage synchronously through a real-time processing flow, so that subsequent flexible processing operations can be performed for other usage requirements. The messages in the fast storage that comes with the real-time system are generally only kept for a period of time to avoid high storage costs. It can be seen here that slow storage basically needs to store the full amount of data, and its overhead will be very high, which is why the mainstream generally chooses cheap and easy-to-expand object storage systems.
4.4 Demand and Products
For storage components, some important feature requirements include:
-
High reliability, data loss is definitely the most unacceptable. Generally, only C in CAP is a feature that cannot be compromised.
-
Scalability requires the ability to easily expand and contract storage space.
-
For performance, slow storage needs to have relatively good throughput to support consumers' concurrent acquisition of large amounts of data. And fast storage needs to have a very good read and write response speed for small data volumes.
In terms of storage products, the services of cloud vendors should be the mainstream choice. After all, it is too complicated to build and maintain storage clusters by yourself. There are also some open source projects based on the object storage of these cloud vendors that have added some additional functions (such as supporting POSIX) and optimization, such as lakeFS [6], JuiceFS [7] and SeaseedFS [8], etc. (the latter two are Chinese projects) .
5. Data processing
Data processing is more complex in the entire platform, and it is also a part where various genres compete fiercely. The most typical approach is to use two sets of computing engines to support batch processing and stream processing respectively, which is consistent with the data acquisition part. The advantage of this is that the most suitable technology can be selected for the business scenario, and the strengths of the framework itself can be better utilized. Most companies are mainly based on batch processing requirements, so there is no need to introduce a stream processing engine at the beginning.
5.1 Batch processing
The most popular framework for batch processing is Apache Spark. As an old-fashioned open source project, the community is active, the development stage is relatively mature, and the functions are very comprehensive and powerful. In addition to typical structured data processing, it can also support unstructured data. graph data, etc. If it is based on structured data, then the old Hive, and newcomers such as Presto and Dremio are also very good choices for SQL computing engines. When doing batch processing of massive data, many optimization methods are also involved, such as the selection of various join methods, the adjustment of task parallelism, and the processing of data skew, etc., which will not be detailed here.
5.2 Stream Processing
In terms of stream processing, the most heard in China must be Apache Flink. In addition, like Spark Streaming, Kafka Streams also provide corresponding stream processing capabilities. For some complex calculation logic, the development threshold for stream computing is still quite high, and many requirements can be realized without complex calculations in stream processing. For example, we can simply process the data and write it to real-time analytical databases in real time, such as ClickHouse, Pinot, Rockset, or systems like ElasticSearch, KV storage, and in-memory DB, which can also provide a large part of streaming computing The requirements are met, and we will introduce the corresponding examples later. Stream processing, like batch processing, requires various performance and scalability optimizations, such as specifying partition logic, solving data skew, and checkpoint tuning.
5.3 Flow batch integration
In recent years, the concept of stream-batch integration has become popular, especially in the Flink community, which believes that batch processing is only a special form of stream processing, which can be completed using a unified framework. This is almost the same as the Kappa architecture mentioned earlier. Of course, there are also attempts to unify at the software level, such as Apache Beam, which can use the same DSL for development, and then switch to Spark or Flink for batch processing and stream processing when the underlying execution is executed.
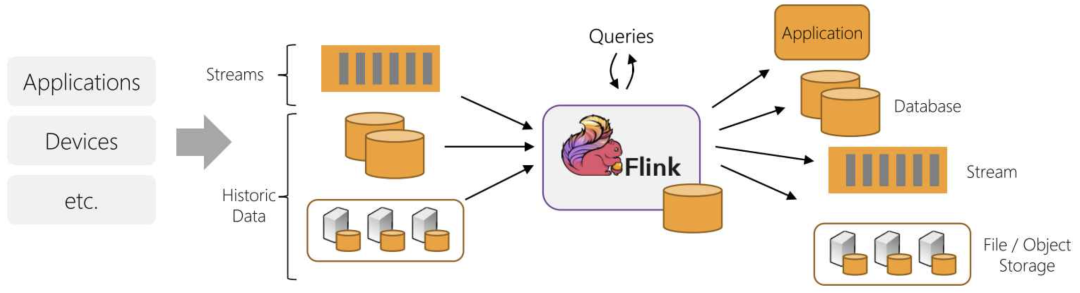
Flink's streaming and batch integration
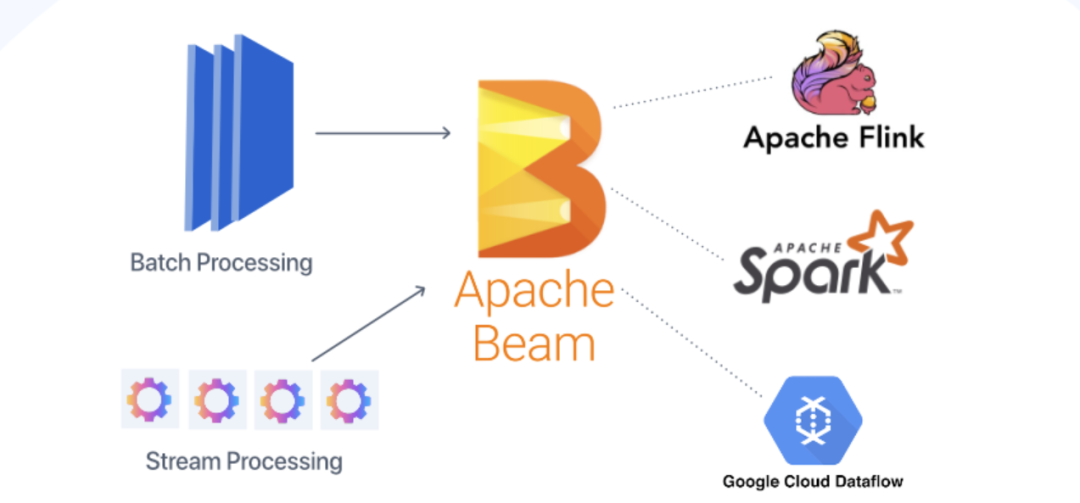
Beam's streaming and batch integration
5.4 Demand and Products
For data processing components, the requirements that need to be met are:
-
The horizontal expansion capability of computing can use multiple nodes to calculate large amounts of data.
-
Stability and availability, multi-node failover/recovery capabilities.
-
Flexible and open API/SDK/DSL support, such as SQL, or various mainstream programming languages to develop processing logic.
Batch processing products In addition to the various open source frameworks mentioned above, cloud vendors also provide various managed services, including the familiar AWS EMR, Google Dataproc or Cloud Dataflow (based on Beam), Azure Databricks, etc.
Stream processing products include AWS Kinesis Data Analytics, Google Cloud Dataflow, and Azure Stream Analytics provided by cloud vendors. In addition, there are some well-known SaaS vendors, including Kafka's "official" company Confluent [9], Upsolver [10], Materialize [11] and so on.
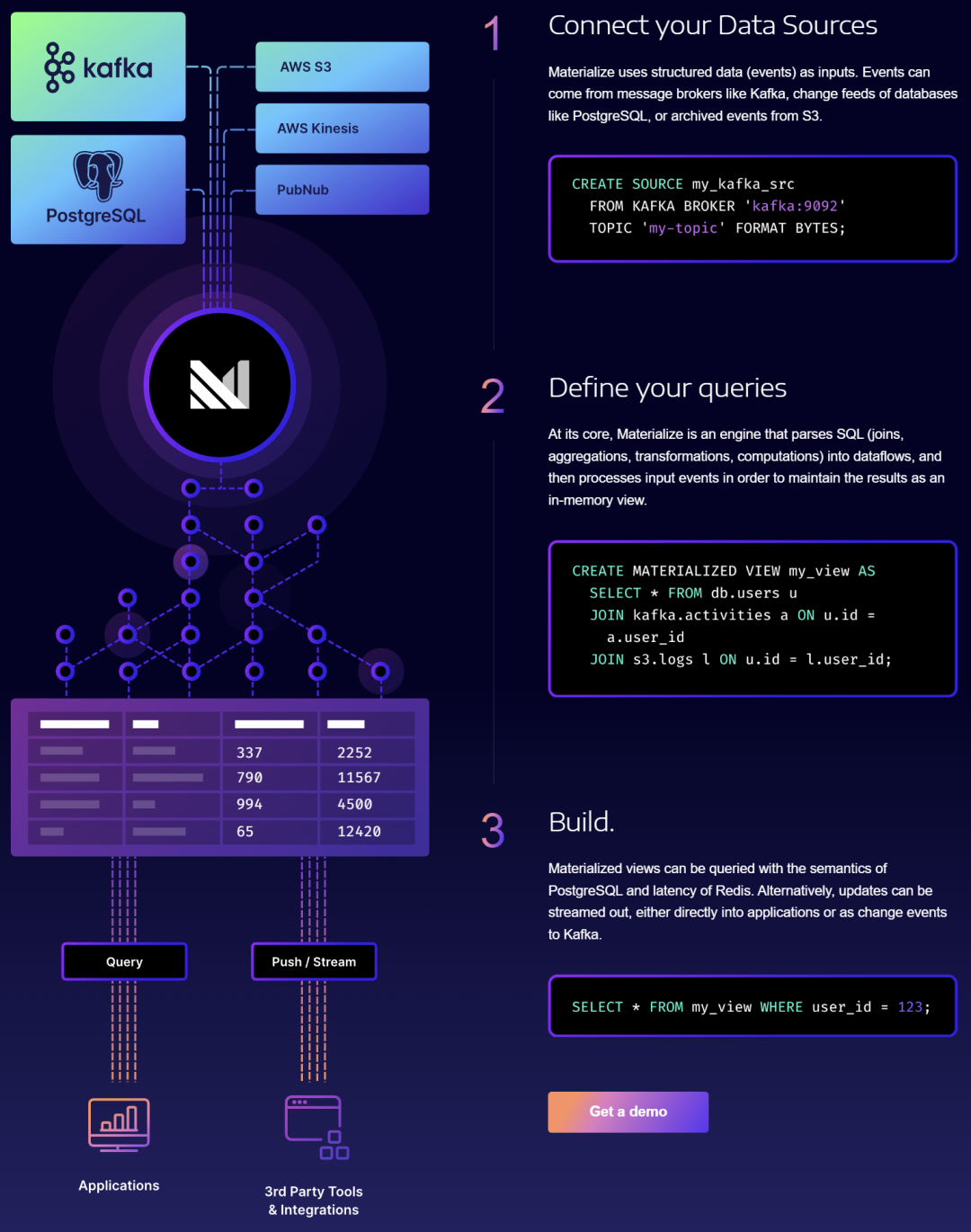
Streaming data processing company Materialize
6. Metadata
After years of industry application and product polishing, the traditional RDBMS is relatively complete in terms of metadata. However, because the cloud data platform has not yet been popularized, it is often easily overlooked in the internal construction process of each company. This part of the capability is actually a crucial part of an enterprise-level mature product.
6.1 Platform metadata
During the operation of the platform, various information will be generated, such as various data sources configured, execution of data acquisition, execution of data processing, schema, statistical information, blood relationship of data sets, resource usage of the system, various log information and more. Through this information, we can monitor and alert various platform tasks, and when problems occur, we can also conveniently troubleshoot and deal with them through viewing these information, instead of logging in to the management console of each module to check one by one.
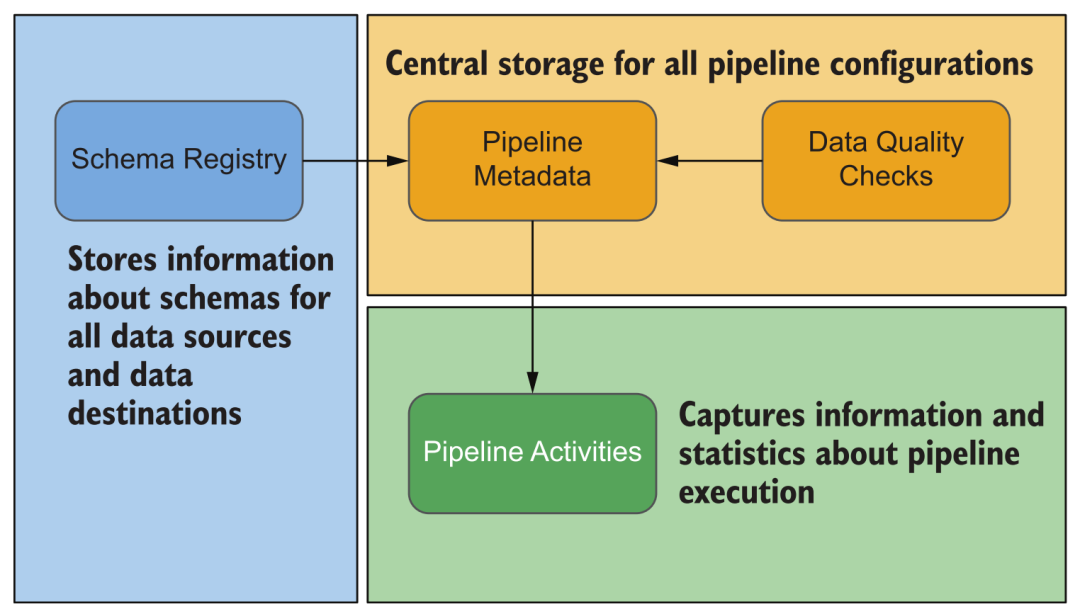
Platform metadata type
Schema is a big topic. Compared with the data warehouse system based on relational database technology, the cloud data platform has certain advantages in flexibly handling changes in the schema of the dataset. When most cloud data warehouses deal with schema changes, their services will be affected to some extent (for example, table locks are required). And many lakehouses can better support schema evolution, such as the mergeSchema option in Delta. Of course, this function is not omnipotent. In the entire data platform, it involves the processing and transformation of various data, the interaction of various links, downstream systems such as data warehouses, real-time analysis of database writing and consumption of other external systems. The schema must be strictly documented and managed.
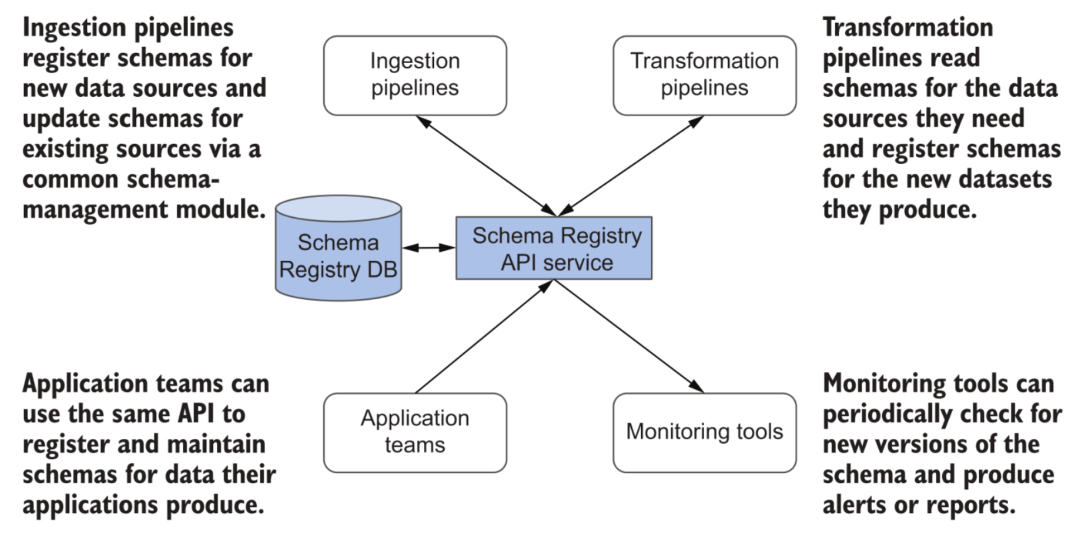
Schema Registry in metadata
Another very important metadata category is data quality. With the advancement of enterprise digitalization, more and more various data sources are involved, and various internal data processing and transformations are becoming more and more complex, and various enterprise decisions are increasingly dependent on data content and corresponding analysis results , How to ensure that we can still guarantee the quality of "data products" and the overall efficiency of iterative operation and maintenance during the entire process of rising complexity has become a very critical issue. Such demands have promoted the emergence of the so-called DataOps movement, drawing on the experience of how to maintain enterprise development, delivery, and operation and maintenance of complex software in DevOps, and applying it to the field of data products.
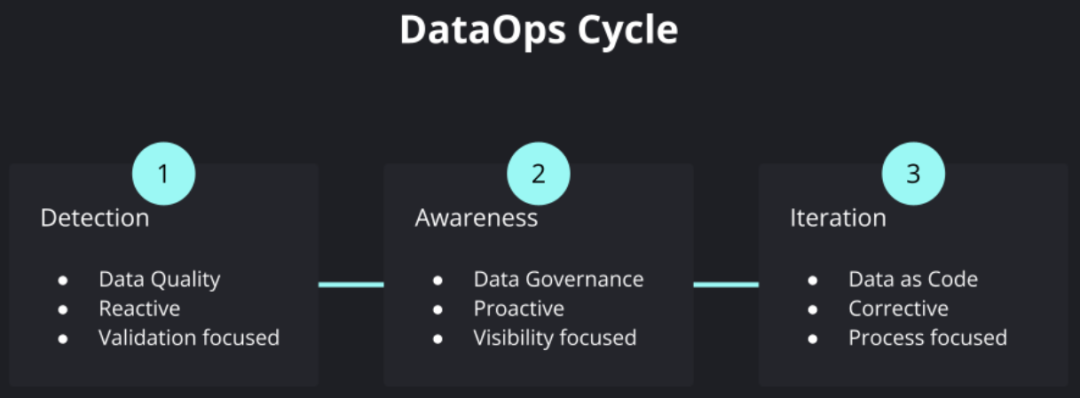
DataOps Cycle
A very important part of this is the continuous monitoring and testing of data quality inspection, which is applied to data flow CI/CD, as well as data control, data discovery and other links. This has also given birth to a new class of products called "Data Observability", which very vividly expresses the goal of insight into the overall data health status in the data platform.
6.2 Business metadata
In addition to metadata at the technical level, there are also related metadata management and use requirements in business. For example, when there are more data sets on the platform, management and search will be more complicated, and the basic folder structure may not meet the needs. Therefore, we need to support functions such as description, tagging, and search of data sets to help business users find them more quickly. Appropriate business data information. The so-called Data Discovery and Data Catalog products are generally designed to meet such needs.
In addition, depending on the company's business, it is also necessary to follow the corresponding data compliance requirements, such as privacy protection of personal information, support for various data rights and freedoms of users, etc. Capabilities in this area also require dedicated metadata management and data governance support. Typical companies are Collibra and so on.
6.3 Demand and Products
For metadata components, the conventional requirements must still ensure high availability and scalability. When the platform scale is large, the scale of metadata will also be very considerable. Another important thing is flexibility and scalability, such as supporting user-defined metadata content and providing external services through open APIs. In modules such as data processing, process orchestration and execution, and subsequent data consumption, all kinds of metadata need to be dealt with. Therefore, a well-designed metadata service has attracted more and more attention.
This field is relatively new, and the products provided by cloud vendors may not meet all needs, such as AWS Glue Data Catalog, Google Data Catalog, and Azure Data Catalog.
There are also some open source vendors that provide related services, and there are relatively few platform metadata. The more representative one is Marquez [12]. On the business metadata level or more comprehensive, there are Apache Atlas [13], Amundsen [14], DataHub [15], Atlan [16], Alation [17] and so on.
Atlan Function Introduction
For Data Observability, there are also many open source tools and products that we are familiar with, such as AWS open source Spark-based Deequ [18], "Pengci" Dickens' Great Expectations [19], Monte Carlo [20], BigEye [21] wait.
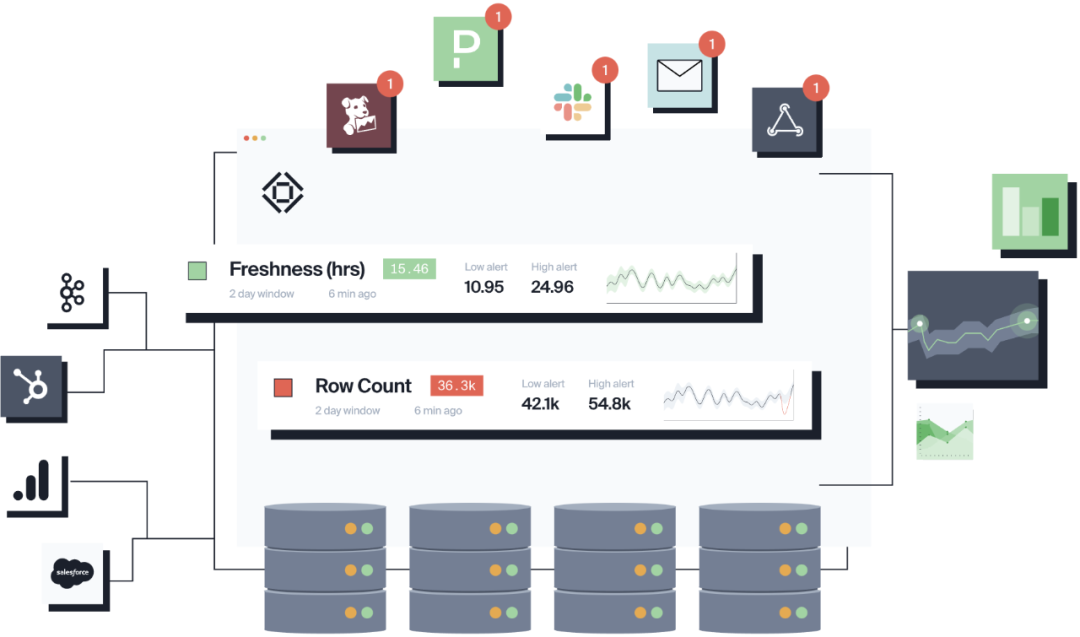
big eye
7. Data Consumption
Compared with the data warehouse era, the external services provided by the data platform are also much richer. In addition to typical data analysis applications, streaming data consumption, data science, and machine learning applications have also begun to emerge. In order to meet different needs, the cloud data platform can introduce or connect various special data systems under the design idea of loose coupling and componentization, and flexibly expand its service capabilities.
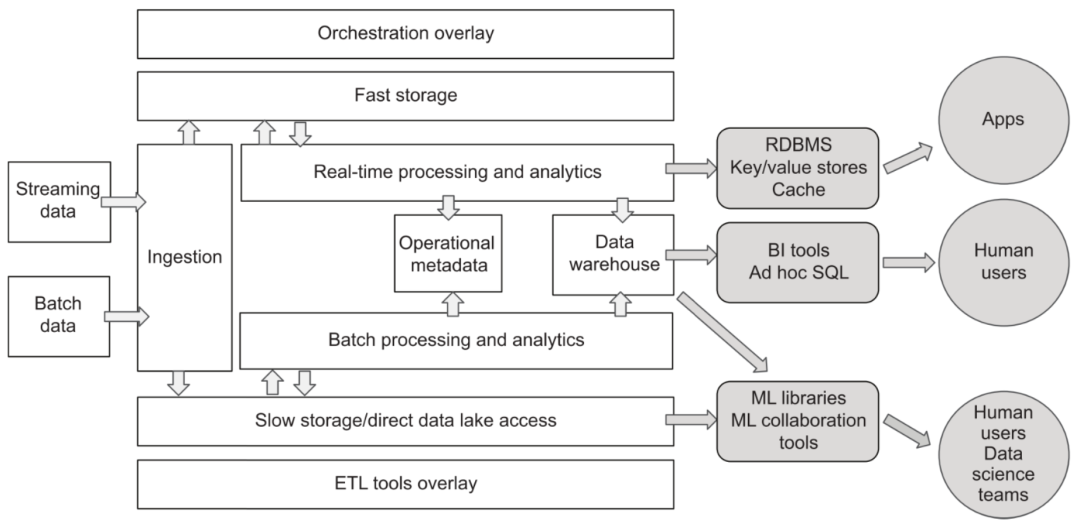
Various data consumption needs
7.1 Analysis query
For BI data analysis requirements, most applications use SQL to query and obtain data. Due to the rise of self-service data analysis needs, the flexibility of queries, the timeliness of interactions (generally requiring sub-second to second-level responses), and the increasing requirements for processing large amounts of data, traditional Hive, Spark queries Due to the problem of response time, it is often unable to meet the demand. In this context, there are many corresponding solutions:
-
Cloud data warehouses, such as BigQuery, Redshift, Azure Synapse from the three major vendors, or Snowflake from the third party. In the case of structured data processing requirements, it is even possible to directly use these systems as the core to replace traditional data warehouses to build the entire data platform.
-
Lakehouse, such as Spark's commercial computing engine Photon, or technologies such as Presto and Dremio, perform efficient query processing based on open formats (Delta, Hudi, Iceberg) on some data lakes.
-
Open source real-time analysis databases, such as ClickHouse mentioned many times above, and various emerging projects such as Apache Doris [22], Databend [23] and so on.
7.2 Data Science
In the field of data science and machine learning, the most important ecology is built based on Python. Its typical operation mode will directly obtain a large amount of data from the data storage layer through notebooks, Python scripts, etc. for unified processing and use Subsequent model training, etc., rarely need to execute complex queries through SQL. In this case, if you can directly access the original files in slow storage, then the cost overhead is naturally the lowest. Of course, there are also disadvantages in doing so, such as data control, permissions, etc. will be difficult to guarantee.
In addition, if you consider the entire process of machine learning development, deployment, and monitoring, then another large set of MLOps-related requirements will be introduced. Among them, the requirements for data involve the Feature Store, and the difference between batch and real-time feature request modes. , which also corresponds to the requirements of batch acquisition and single-point query in the data platform we discussed, and whether the deployment components can be reused can be considered during construction.
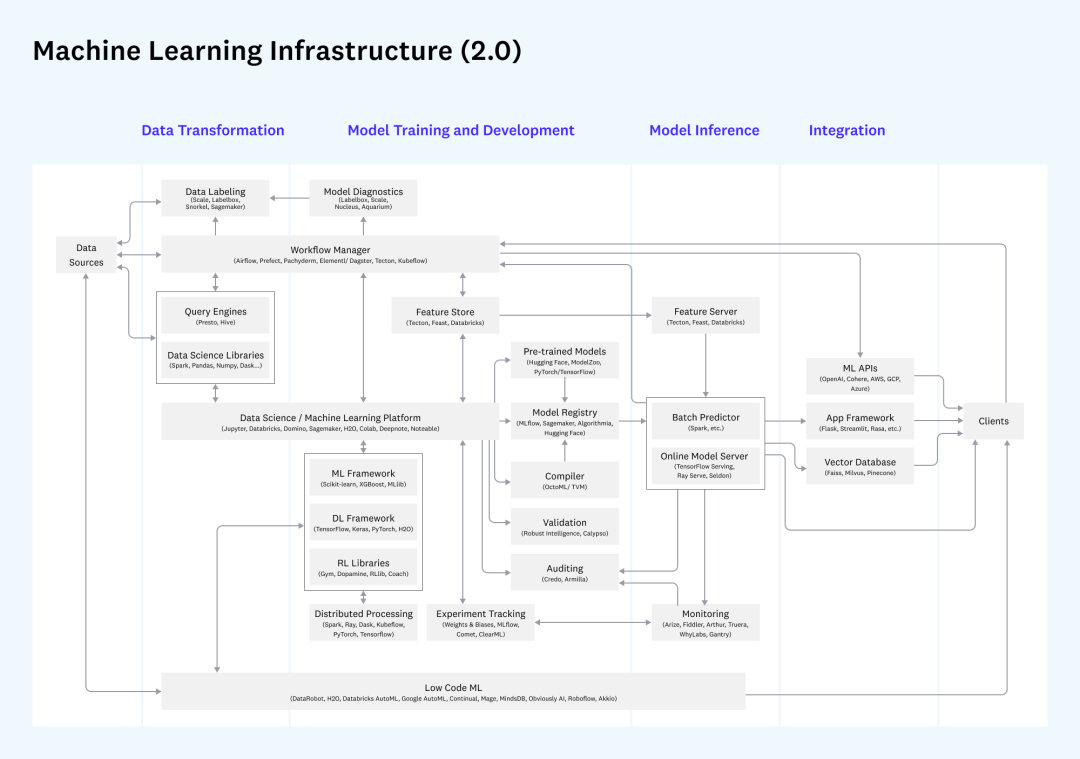
Machine learning related Infra
For discussions related to MLOps, you can also refer to my previous introduction to MLOps [24].
7.3 Real-time consumption
Finally, for the results of stream processing and analysis, there will also be corresponding applications for real-time consumption. External services can be provided through real-time result push, writing to relational databases, KV storage, cache systems (such as Redis), and search systems (such as ElasticSearch). Many stream processing systems such as Flink also support real-time query, and specific APIs can be developed to provide data results directly from the stream system.
7.4 Permissions and Security
In enterprise-level applications, the control of user permissions, the auditing and monitoring of various operation records, including data desensitization, encryption, etc., are very important. In addition to the support of the platform itself, we can also consider using various related cloud services, such as Azure Active Directory, identity authentication services such as Auth0 [25], data security companies such as Immuta, and cloud vendors Provide various VPC, VPN-related network security services, etc.
7.5 Service Layer Products
In addition to the cloud data warehouse mentioned above, lakehouse and real-time analysis database, there are also products like Metric Store, which are built on various data sources and provide unified services to the outside world. Such as LookML [26], Transform [27], Metlo [28], etc.
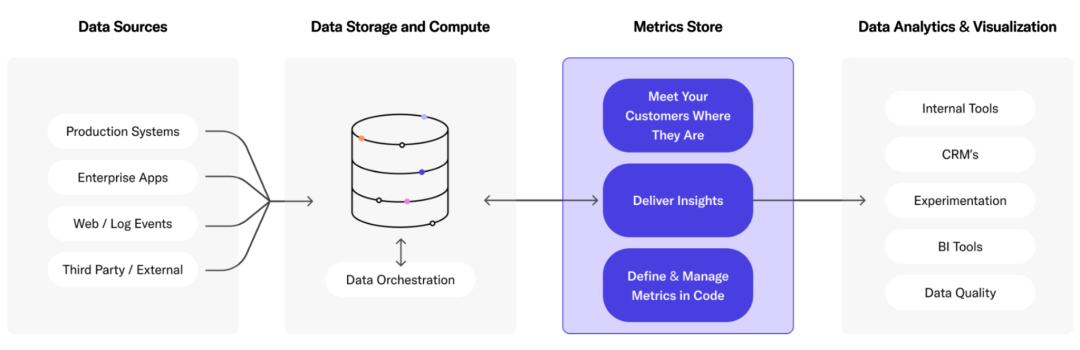
Metric Store
8 Process orchestration and ETL
8.1 Process Orchestration
In the traditional data warehouse architecture, orchestration tools are also an extremely important part. In the cloud data platform, the execution scheduling of related pipeline processes will be more complicated. For example, we need to trigger the process of data acquisition through timing or API, and then trigger and schedule various cascading tasks. When there is a problem or failure in task execution, it can automatically retry and recover, or prompt the user to intervene.
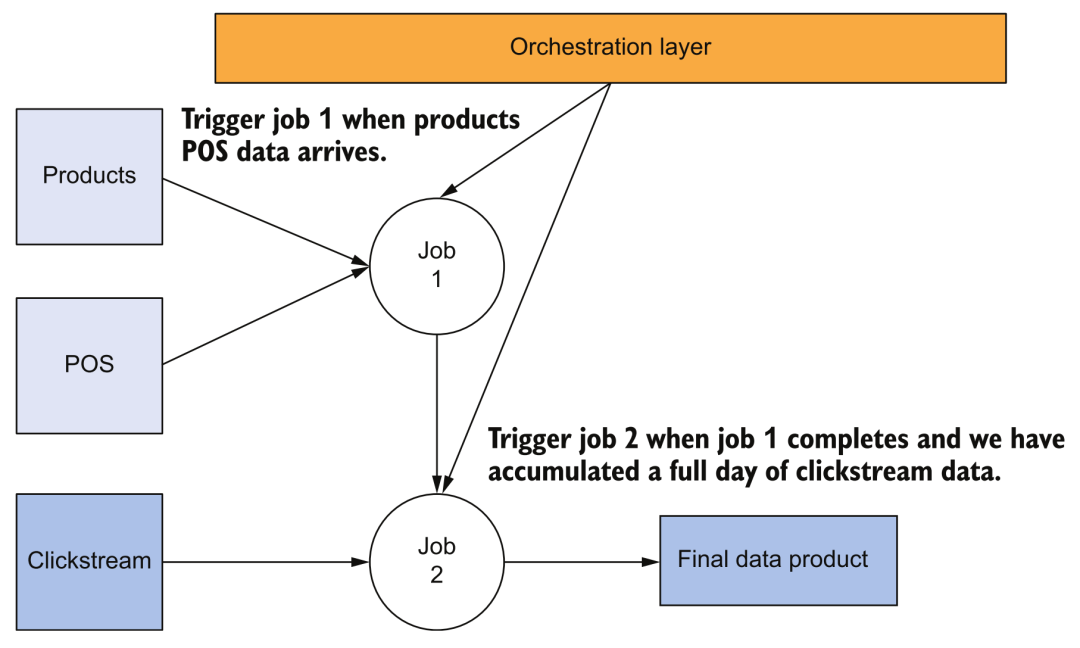
Flow chart
For example, the above figure shows the simplest task dependency. The triggering of task 2 depends on the successful completion of the batch task of task 1. At this time, we need orchestration tools to support this kind of work.
8.2 ETL
The specific tasks performed in the orchestration process are generally various data access and data conversion operations, which is what we commonly call ETL. In addition to developing business logic through SQL or computing engine SDKs (such as PySpark), there are also many products on the market that support no-code/low-code development, which greatly reduces the threshold for users. For example, our Guanyuan SmartETL is a good product in this regard, and has been loved by many business personnel.
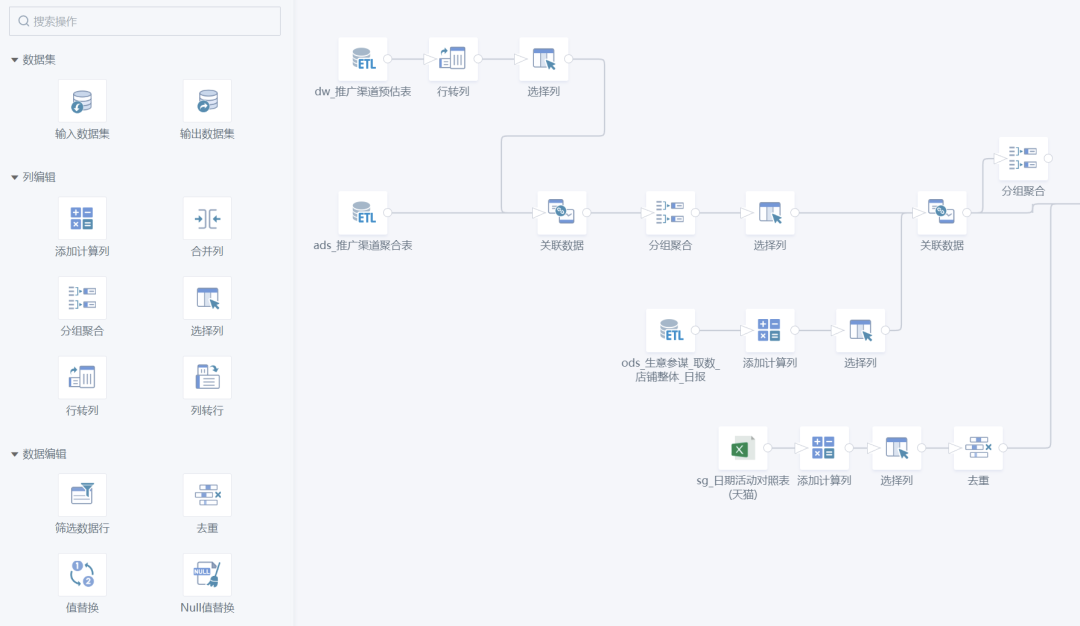
Guanyuan SmartETL
8.3 Demand and Products
For tools related to process orchestration, the main system requirements are:
-
Scalability, supporting scheduling and monitoring of massive pipelines.
-
Stability must ensure stability and high availability. Once the process orchestration capability is paralyzed, it means that the core data processing capabilities of the entire platform have come to a standstill.
-
Observable, operable and maintainable, the execution status of various tasks, logs, system resource overhead, etc. need to be recorded and easily viewed, convenient for operation and maintenance and troubleshooting.
-
Openness makes it easy to develop various custom processing logic in the tool to run different types of tasks.
-
DataOps support, even if no-code drag-and-drop development is provided, the bottom layer should still be able to well support the needs of DataOps, such as version management of pipeline logic, testing and release (CI/CD), and support API calls to realize the process automation etc.
It can be noticed that in fact, a lot of data acquisition and data processing tools also have some ETL or orchestration capabilities. The products of cloud vendors are basically data acquisition tools, including AWS Glue, Google Cloud Composer (hosted version of Airflow), Google Cloud Data Fusion, and Azure Data Factory.
In terms of open source tools, among the orchestration tools, Airflow should be the most famous one. With the huge demand for workflow orchestration in the field of machine learning, many rising stars have emerged, such as Dagster, Prefect, Flyte, Cadence, Argo (KubeFlow Pipeline) wait. In addition, the popularity of DolphinScheduler [29] is quite good. There are not many open source tools for ETL, and talend is not completely open source. The more famous ones are Apache NiFi [30] and OpenRefine [31], two open source projects with a long history.
SaaS vendors can refer to data acquisition vendors, such as Airbyte, Fivetran, Stitch, Rivery, etc. Many open source projects of orchestration tools mentioned above also have corresponding commercial companies that provide hosting services. I also have to mention the very popular dbt [32], a data conversion tool used by almost every company. It has borrowed a lot of best practices in the software engineering field. It can be said that it meets the needs of DataOps. A very good product to support.
9. Best Practices
9.1 Data Layering
When we build an enterprise data warehouse system, we generally follow some classic best practices. For example, regarding the data table model, there are design methods such as star schema and snowflake model; from the perspective of data transfer process, there are very classic data warehouses Hierarchical mode:
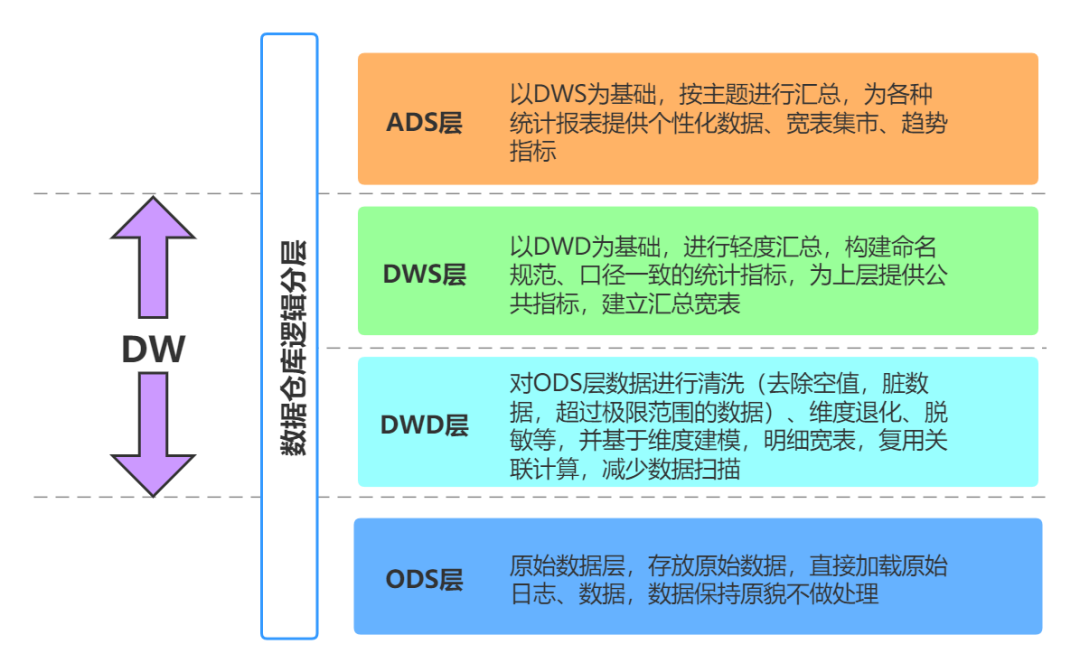
Data Warehouse Hierarchy
In the cloud data platform, we can also learn from this idea. For example, the data flow in the lakehouse designed by Databricks is very similar to the data warehouse layer above:
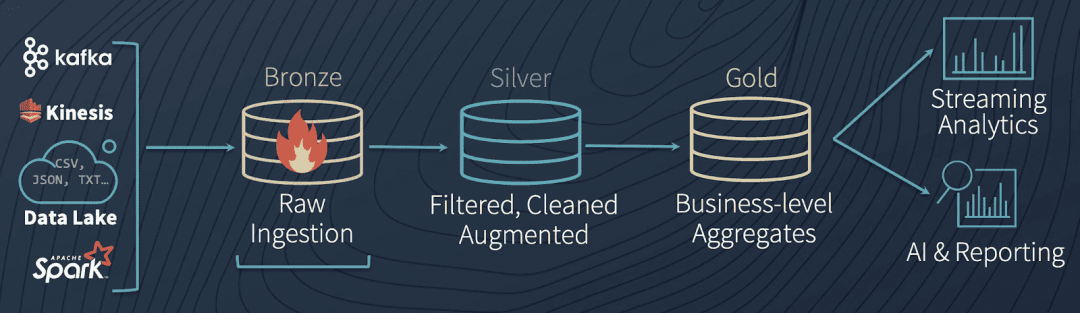
Lakehouse data architecture
The specific process steps are as follows:
-
Generally, when entering the cloud data platform through data acquisition, the state of the original data (which can be in the original format or Avro format) will be kept as much as possible and stored in the landing (bronze) area. Note that in the overall architecture, only data acquisition layer tools can write to this area.
-
The original data will then undergo some general quality checks, deduplication, cleaning and conversion, and enter the staging (silver) area. From here on, it is recommended to use a columnar storage format similar to parquet.
-
At the same time, the original data will be copied to the archive area, and then used for reprocessing, process debugging, or testing of new pipelines.
-
The data processing layer tool will read data from the staging area, perform various business logic processing, aggregation, etc., and finally form production (golden) data and provide data services.
-
The data in the staging area can also be left unprocessed, bypassed to the production area, and finally flowed into the data warehouse. This part is equivalent to raw data, which can help data consumers to compare and locate related problems in some cases.
-
Different data processing logics will form "data products" for different business themes and application scenarios, provide batch consumption services (especially algorithm scenarios) in the production area, or load data warehouses to provide SQL query services.
-
During the transfer process between staging and production, if the data processing layer encounters any errors, it can save the data to the failed area, and after the troubleshooting is resolved, put the data back into the landing area to trigger the whole process again.
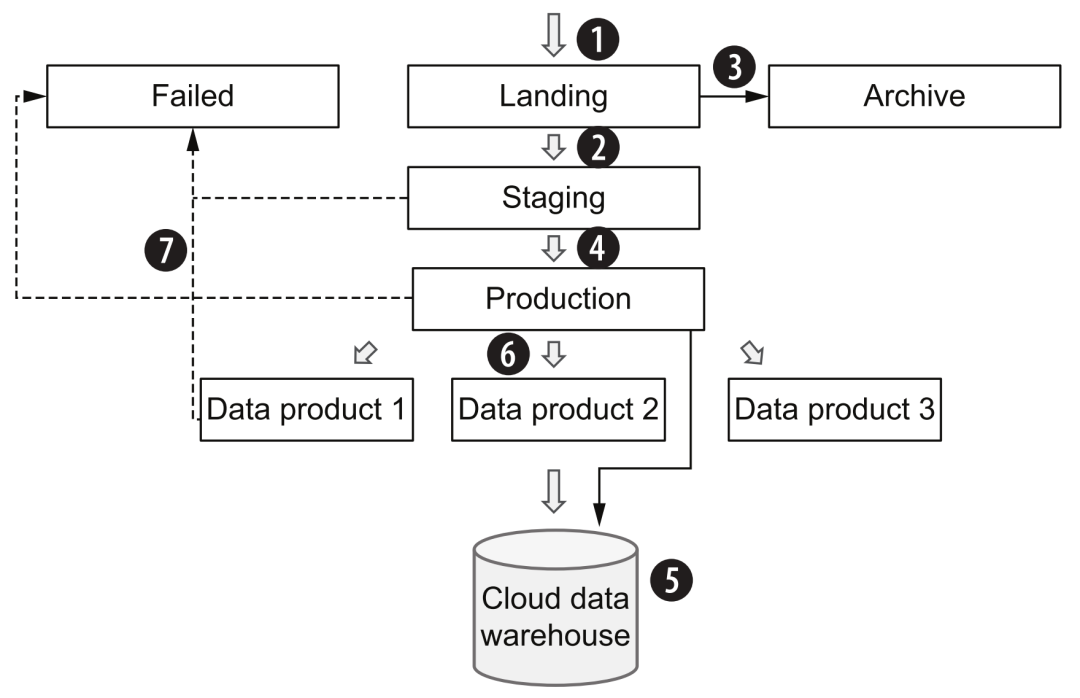
Data Process Best Practices
These areas can be divided by typical object storage concepts, such as "bucket" or "folder". The access control of each area to different layer modules can also be determined according to different read and write patterns, as well as the design of cold and hot storage to save costs. In addition, the processing flow of streaming data can also learn from similar logic, but there will be more challenges in data deduplication, quality inspection, data enhancement, and schema management.
9.2 Distinguish between streaming acquisition and streaming analysis requirements
We often hear that BI analysis customers have the demand for "real-time data analysis". However, after careful analysis, users do not stare at the BI analysis board all the time to do "real-time analysis". Generally speaking, there is a certain time interval for opening the board. We only need to ensure that the data that customers see every time they open the analysis dashboard is up-to-date, so the following architecture can be used to meet the requirements:
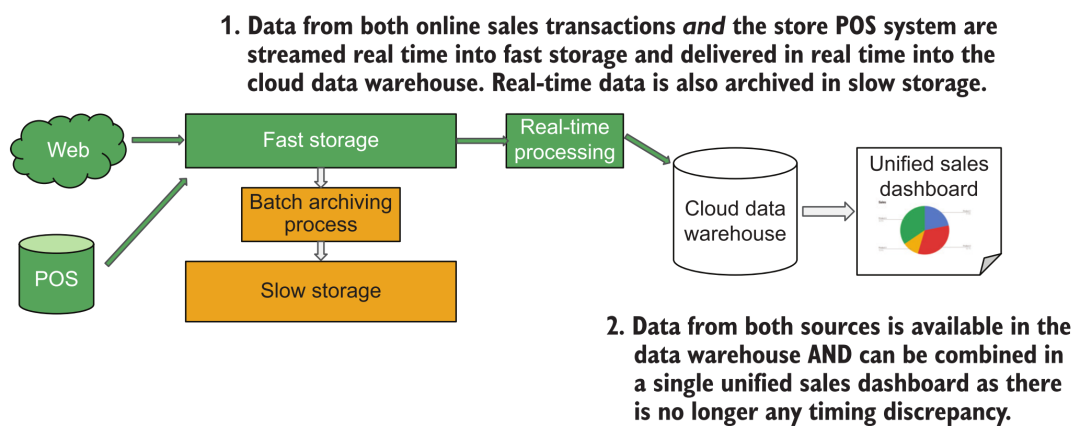
Streaming Data Acquisition Architecture
Here we only need to write the order data into the cloud data warehouse in real time through the streaming data acquisition system. When the user opens the report every once in a while, trigger the SQL query of the data warehouse to display the latest results.
But consider another scenario. In a certain game, we want to display real-time action data of users, such as statistical information such as experience points gained since launch. At this time, it may not be appropriate if we still use the above-mentioned "streaming acquisition" architecture. Because at this time, each player is really staring at his statistics in "real time", so high-frequency and large-concurrency query support must be achieved. The response time and concurrent service capabilities of general cloud data warehouses are difficult to meet, and this is the real requirement for "real-time analysis". We need to perform streaming statistical analysis operations after streaming new data from users, and store the results in some database/cache systems that can support high-concurrency and low-latency queries in order to support the data consumption needs of massive online players .
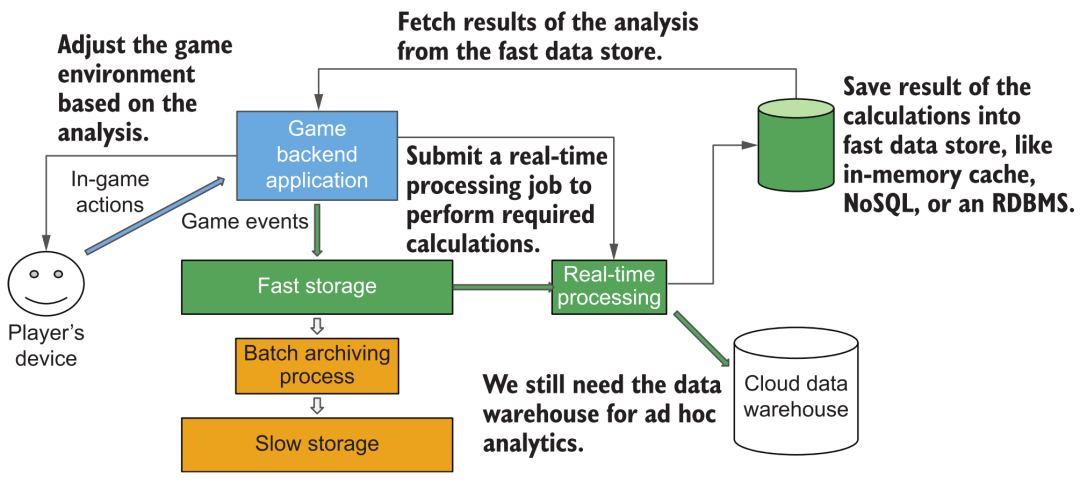
Streaming Data Analysis Architecture
9.3 Controlling Cloud Computing Spending
In the cloud-native era, the barriers to entry for us to use various components are much lower. Out-of-the-box, elastic scaling, and O&M-free have brought a lot of convenience to developers, and are quietly changing our thinking. In the era of self-built systems, we have a more refined understanding and in-depth optimization of the resource overhead of each component and the utilization rate of the entire cluster. But now the trade-off of various system designs has shifted from the allocation of limited resource pools to the trade-off between cost and performance, which has reduced the awareness of resource cost optimization for each component. Including cloud vendors themselves sometimes "bad" intentionally or unintentionally. Recently, there is an article The Non-Expert Tax [33] dedicated to discussing the economics of auto-scaling of cloud vendors.
Therefore, as a developer of a cloud data platform, it is still necessary to have an in-depth understanding of various cloud computing components, product architecture principles, charging models, and practice corresponding resource monitoring and optimization methods. Typical examples include network overhead control (reducing cross-cloud transmission), cold and hot storage design, data partitioning and other optimization methods to improve data computing and processing efficiency, etc.
9.4 Avoid Tight Coupling
As can be seen from the complex architecture diagram above, a cloud data platform generally consists of a large number of components, and the entire technological ecology changes with each passing day. Generally, for this type of complex system, we will adopt a step-by-step construction method. During the process, we will continue to increase, replace or eliminate some component products. Therefore, we must learn from the principle of loose coupling in software engineering to avoid specific product/interface have tight dependencies. Although sometimes direct access to the underlying storage seems to reduce the intermediate steps and be more efficient, but it will also make us encounter a lot of trouble when we want to expand and change later. Ideally, we should clarify the boundaries and interfaces between components as much as possible, and encapsulate different products to provide relatively standard interfaces for interaction and services.
10. Data platform construction
10.1 Business Value
Finally, it is worth mentioning that the construction of a complex cloud data platform cannot be promoted solely from a technical perspective. The entire project must be initiated and planned from business (commercial) goals. Typical values of a data platform include:
-
Reduce expenditure, improve business operation efficiency, save asset investment and various operation and maintenance costs.
-
Open source, support marketing optimization, customer experience optimization and other scenarios, and promote the company's revenue growth.
-
Innovation, through excellent product capabilities, to support self-service data analysis and decision-making of the business, to quickly explore new growth points.
-
Compliance, through the construction of a unified platform to meet various data regulations, policies, and regulatory needs.
We should clarify the business demands of the enterprise, and design data strategies and plans for data platform construction in a targeted manner. For how technical strategies serve business goals, you can also refer to this article The Road to Senior Engineers: Technical Strategy [34], which will not be elaborated here.
10.2 Construction path
As can be seen from the previous architecture diagram, the composition of the entire platform is quite complicated, and it generally takes several years to gradually build and improve it. This is consistent with the online, digital, and intelligent evolution of the enterprise itself, instead of ignoring the status quo of enterprise data and developing and deploying streaming data platforms, machine learning platforms, and other seemingly trendy technologies.
In the early days of its establishment, Guanyuan thought deeply and proposed a 5A implementation path methodology for data analysis and intelligent decision-making in enterprises [35], including self-service analysis, scene-based, automation, and enhancement, and finally realizing decision-making automation. step. Corresponding to the construction of the data platform, you can also refer to similar policy frameworks, for example:
-
Agility can be achieved through the construction of the basic data warehouse system and the application of self-service BI analysis products to achieve the goal of "seeing data".
-
Scenario-based, through the metric layer and the application market in BI products, form the best practices of various business scenarios, so that more users can know "how to look at data".
-
Automation requires the platform to have certain orchestration capabilities, connect various analysis results with business systems, automatically push results (reverse ETL), data early warning, etc., to achieve the effect of "data chasing people".
-
Enhancement, on the basis of analysis, further adding AI modeling and forecasting capabilities requires the platform to support algorithmic data processing and consumption (such as unstructured data, notebooks) to achieve "insight into the future".
-
Mobility, in the end we hope to go further on the basis of forecasting, extending from analytical AI to action AI, which requires the platform to provide more comprehensive external service capabilities (API, real-time data, AB Test, etc.), combined with some low-code tools Creating data-driven business applications is expected to achieve "automatic decision-making."
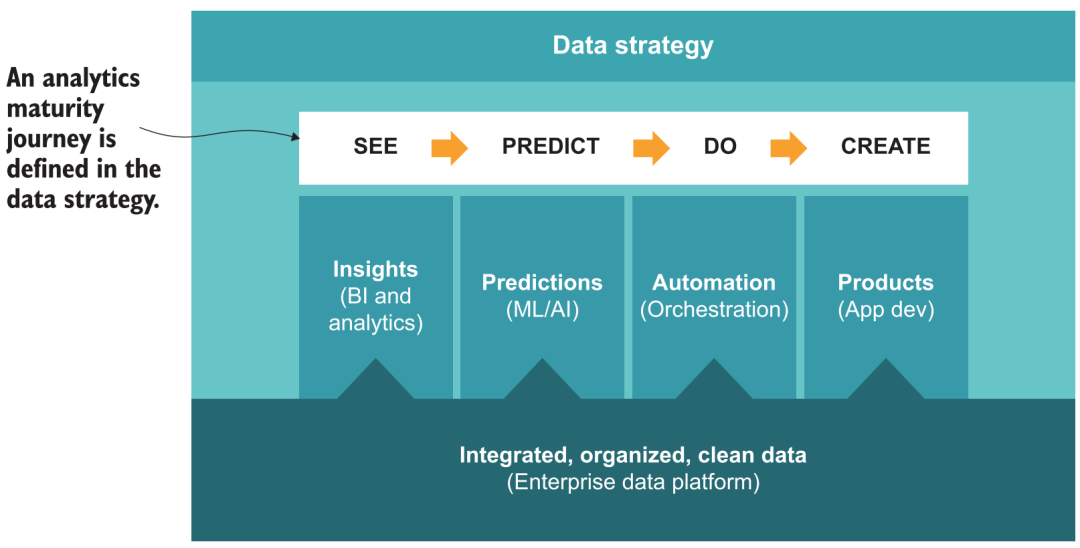
Data Analytics Maturity Journey
10.3 User promotion
In addition to the evolution methodology at the technical architecture level, how to publicize and promote the platform at the business level is also an important issue. There are too many data platform projects that lack in-depth business communication and understanding. In the absence of a consensus between both parties, complex projects are promoted, and the construction period is extremely long, which eventually leads to failure midway. We should quickly reflect the value of the platform through some small projects, enhance the consensus between the two parties, gain the trust of users, and gradually promote it to more organizational departments; after getting more applications, it will also drive the scene and enrich the demand, which in turn will also increase It can guide and promote the construction and development of the platform itself, and enter a virtuous circle. This is also the route and method of "making business use" that we are constantly exploring and practicing.
In the end, we put up a small advertisement. We at Guanyuan Data have very rich experience in the product technology level mentioned above, enterprise services, and business promotion. Through the Universe, Galaxy, and Atlas product lines, it can support enterprise data platforms at various stages of data analysis maturity, BI + AI analysis and decision-making needs. For some leading customers in the industry, our products have also successfully reached the milestone of more than 20,000 active analysts and data decision-making users. It is conceivable that such an enterprise can embody the huge advantages of decision-making efficiency and quality in the fierce market competition. Interested friends are very welcome to discuss and exchange together, and seek opportunities for cooperation and co-construction :)
References
[1] Composition and construction of cloud-native machine learning platform: https://zhuanlan.zhihu.com/p/383528646
[2] Some analysis reports of a16z: https://future.com/data50/
[3] modern data stack: https://www.moderndatastack.xyz/
[4] Data Lake System in Algorithm Platform: https://zhuanlan.zhihu.com/p/400012723
[5] tiered storage: https://www.confluent.io/blog/infinite-kafka-storage-in-confluent-platform/
[6] lakeFS: https://github.com/treeverse/lakeFS
[7] JuiceFS: https://github.com/juicedata/juicefs
[8] SeaseedFS: https://github.com/chrislusf/seaweedfs
[9] Confluent: https://www.confluent.io/
[10] Upsolver: https://www.upsolver.com/
[11] Materialize: https://materialize.com/
[12] Marquez: https://github.com/MarquezProject/marquez
[13] Apache Atlas: https://atlas.apache.org/
[14] Amundsen: https://www.amundsen.io/
[15] DataHub: https://datahubproject.io/
[16] Atlan: https://atlan.com/
[17] Alation: https://www.alation.com/
[18] Deequ: https://github.com/awslabs/deequ
[19] Great Expectations: https://github.com/great-expectations/great_expectations
[20] Monte Carlo: https://www.montecarlodata.com/
[21] BigEye: https://www.bigeye.com/
[22] Apache Doris: https://doris.apache.org/
[23] Databend: https://databend.rs/
[24] Introduction to MLOps: https://zhuanlan.zhihu.com/p/357897337
[25] Auth0: https://auth0.com/
[26] LookML: https://www.looker.com/platform/data-modeling/
[27] Transform: https://transform.co/
[28] Metlo: https://blog.metlo.com/
[29] DolphinScheduler: https://github.com/apache/dolphinscheduler
[30] Apache NiFi: https://github.com/apache/nifi
[31] OpenRefine: https://github.com/OpenRefine/OpenRefine
[32] dbt: https://www.getdbt.com/
[33] The Non-Expert Tax: https://dl.acm.org/doi/10.1145/3530050.3532925
[34] The Road to Senior Engineer: Technical Strategy: https://zhuanlan.zhihu.com/p/498475916
[35] 5A landing path methodology: https://zhuanlan.zhihu.com/p/43515719