- How to optimize the pagination query with query in sql
1. Analyze the efficiency of shallow paging and deep paging queries (the efficiency of deep paging is even worse)

analyze:

- Where type is all to indicate the full table scan
- Extra shows that there is an additional implementation of our using filesort
deep pagination

analyze:

The situation is the same but the execution time will be different

Shallow pagination 1.2s
Deep Paging 2.0s
Thinking: Why is the query time of shallow paging short, while the query time of deep paging is long?
Principle: In shallow paging, our offset is small, while in our deep paging, the offset is large. If the offset is large, the number of rows scanned will be more than that of shallow paging, so it will take longer
2. How to optimize SQL
2.1. Scheme 1: Add an index to order by (we need to create an index for this sorting field first. Wouldn’t it just be an index?)

analyze

We found that the key has gone to the index, then the type is the index, and the extra is empty, so no additional tasks are performed.
Let's look at deep pagination again (there is a problem)

Analysis: It is still a full table scan, and there are additional execution tasks, without indexing

Shallow paging time, 0.38s
Deep paging time, 1.91s
Thinking: Why is the shallow paging query improved, but the deep paging has not changed?
principle:

It is very fast for us to find the source, but we will go back to the table to find other fields, and the cost of returning to the table in shallow pages will be very low, while the cost of returning to the table in deep pages will be high, so it will not work
2.2 Deep paging to force the index? (3.1s is higher)

The time is higher! ! !

Principle: Our sorting has a time cost, and returning to the table also has a time cost (mysql helps us to optimize the two, but it is useless)
2.3. If the cost of deep page return is high, we don’t need to return the table. Adding a joint index (adding a joint index to order by and select) greatly improves the execution time

Among them, the key has a joint index, and the extra eliminates the using filesort, that is, uses our covering index

! ! ! Execution time 0.04s
2.4. Inadequacies
When our requirements change (for example, we need to find other fields), the index becomes invalid

solution
2.4.1, Solution 1. We manually return to the table according to the id (let it force the index)
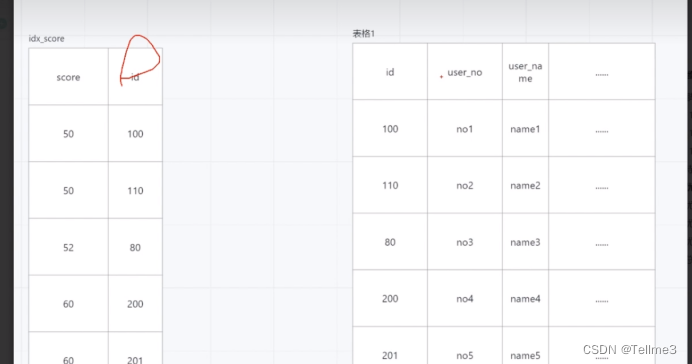
Find the id first, and then find the corresponding three parameters according to the id

analyze


Time spent 0.08s
2.4.2. Solution 2: Start with the business, and interact with the front end by limiting pagination (the required data fields of the last item on each page are passed in)
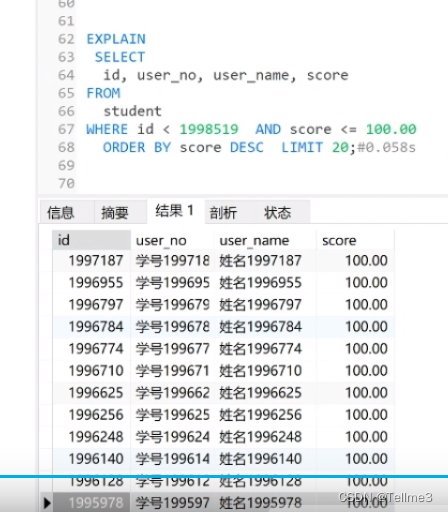
Time 0.058s
Principle: Our where condition cooperates with our desc to query the pagination.
Summarize
