Table of contents
1. Solve the error ModuleNotFoundError: No module named 'tensorflow.examples
2. Solve the error ModuleNotFoundError: No module named 'tensorflow.contrib'
3. Install onnx error assert CMAKE, 'Could not find "cmake" executable!'
四、ImportError: cannot import name 'builder' from 'google.protobuf.internal'
5. Solve ModuleNotFoundError: No module named 'sklearn'
六、解决AttributeError: module ‘torch._C‘ has no attribute ‘_cuda_setDevice‘
Download ImportError: Missing optional dependency 'pytables'. Use pip or conda to install pytables.
八、解决AttributeError: module ‘distutils’ has no attribute ‘version’.
1. Solve the error ModuleNotFoundError: No module named 'tensorflow.examples
Note: Do not decompress the MNIST dataset after downloading, just put it into the mnist_data folder and read it.
Question : I am using tensorflow to do the mnist data set case, and an error is reported.

Reason : There are no examples in tensorflow.
Solution : (1) First find the file corresponding to tensorflow. Mine is in D:\python3\Lib\site-packages\tensorflow (python installation directory), enter the tensorflow folder, and find that there is no examples folder.
We can enter github to download: mirrors / tensorflow / tensorflow GitCode .
(2) After the download is complete, copy the examples folder in the \tensorflow-master\tensorflow\ directory to the local tensorflow folder, and then run the code again.
(3) Later, it was found that the problem still could not be solved, and it was found that the tutorials folder was missing in the examples. This file was not found in the official github, and it was downloaded from other bloggers.

Download address: Baidu network disk, please enter the extraction code
Extraction code: cxy7
(4) But the problem is still not solved...
The previous blogger should be using the tf1.0 version. Refer to the methods of other bloggers to solve the problem.
- Create a new input_data.py file under the project, copy the content of input_data.py in mnist under the tutorials folder to the file,
- Then import input_data in the main file.
The content of the input_data.py file is placed below, and you can get it yourself if you need it.
# Copyright 2016 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Functions for downloading and reading MNIST data (deprecated).
This module and all its submodules are deprecated.
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import collections
import gzip
import os
import numpy
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
from tensorflow.python.framework import dtypes
from tensorflow.python.framework import random_seed
from tensorflow.python.platform import gfile
from tensorflow.python.util.deprecation import deprecated
_Datasets = collections.namedtuple('_Datasets', ['train', 'validation', 'test'])
# CVDF mirror of http://yann.lecun.com/exdb/mnist/
DEFAULT_SOURCE_URL = 'https://storage.googleapis.com/cvdf-datasets/mnist/'
def _read32(bytestream):
dt = numpy.dtype(numpy.uint32).newbyteorder('>')
return numpy.frombuffer(bytestream.read(4), dtype=dt)[0]
@deprecated(None, 'Please use tf.data to implement this functionality.')
def _extract_images(f):
"""Extract the images into a 4D uint8 numpy array [index, y, x, depth].
Args:
f: A file object that can be passed into a gzip reader.
Returns:
data: A 4D uint8 numpy array [index, y, x, depth].
Raises:
ValueError: If the bytestream does not start with 2051.
"""
print('Extracting', f.name)
with gzip.GzipFile(fileobj=f) as bytestream:
magic = _read32(bytestream)
if magic != 2051:
raise ValueError('Invalid magic number %d in MNIST image file: %s' %
(magic, f.name))
num_images = _read32(bytestream)
rows = _read32(bytestream)
cols = _read32(bytestream)
buf = bytestream.read(rows * cols * num_images)
data = numpy.frombuffer(buf, dtype=numpy.uint8)
data = data.reshape(num_images, rows, cols, 1)
return data
@deprecated(None, 'Please use tf.one_hot on tensors.')
def _dense_to_one_hot(labels_dense, num_classes):
"""Convert class labels from scalars to one-hot vectors."""
num_labels = labels_dense.shape[0]
index_offset = numpy.arange(num_labels) * num_classes
labels_one_hot = numpy.zeros((num_labels, num_classes))
labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1
return labels_one_hot
@deprecated(None, 'Please use tf.data to implement this functionality.')
def _extract_labels(f, one_hot=False, num_classes=10):
"""Extract the labels into a 1D uint8 numpy array [index].
Args:
f: A file object that can be passed into a gzip reader.
one_hot: Does one hot encoding for the result.
num_classes: Number of classes for the one hot encoding.
Returns:
labels: a 1D uint8 numpy array.
Raises:
ValueError: If the bystream doesn't start with 2049.
"""
print('Extracting', f.name)
with gzip.GzipFile(fileobj=f) as bytestream:
magic = _read32(bytestream)
if magic != 2049:
raise ValueError('Invalid magic number %d in MNIST label file: %s' %
(magic, f.name))
num_items = _read32(bytestream)
buf = bytestream.read(num_items)
labels = numpy.frombuffer(buf, dtype=numpy.uint8)
if one_hot:
return _dense_to_one_hot(labels, num_classes)
return labels
class _DataSet(object):
"""Container class for a _DataSet (deprecated).
THIS CLASS IS DEPRECATED.
"""
@deprecated(None, 'Please use alternatives such as official/mnist/_DataSet.py'
' from tensorflow/models.')
def __init__(self,
images,
labels,
fake_data=False,
one_hot=False,
dtype=dtypes.float32,
reshape=True,
seed=None):
"""Construct a _DataSet.
one_hot arg is used only if fake_data is true. `dtype` can be either
`uint8` to leave the input as `[0, 255]`, or `float32` to rescale into
`[0, 1]`. Seed arg provides for convenient deterministic testing.
Args:
images: The images
labels: The labels
fake_data: Ignore inages and labels, use fake data.
one_hot: Bool, return the labels as one hot vectors (if True) or ints (if
False).
dtype: Output image dtype. One of [uint8, float32]. `uint8` output has
range [0,255]. float32 output has range [0,1].
reshape: Bool. If True returned images are returned flattened to vectors.
seed: The random seed to use.
"""
seed1, seed2 = random_seed.get_seed(seed)
# If op level seed is not set, use whatever graph level seed is returned
numpy.random.seed(seed1 if seed is None else seed2)
dtype = dtypes.as_dtype(dtype).base_dtype
if dtype not in (dtypes.uint8, dtypes.float32):
raise TypeError('Invalid image dtype %r, expected uint8 or float32' %
dtype)
if fake_data:
self._num_examples = 10000
self.one_hot = one_hot
else:
assert images.shape[0] == labels.shape[0], (
'images.shape: %s labels.shape: %s' % (images.shape, labels.shape))
self._num_examples = images.shape[0]
# Convert shape from [num examples, rows, columns, depth]
# to [num examples, rows*columns] (assuming depth == 1)
if reshape:
assert images.shape[3] == 1
images = images.reshape(images.shape[0],
images.shape[1] * images.shape[2])
if dtype == dtypes.float32:
# Convert from [0, 255] -> [0.0, 1.0].
images = images.astype(numpy.float32)
images = numpy.multiply(images, 1.0 / 255.0)
self._images = images
self._labels = labels
self._epochs_completed = 0
self._index_in_epoch = 0
@property
def images(self):
return self._images
@property
def labels(self):
return self._labels
@property
def num_examples(self):
return self._num_examples
@property
def epochs_completed(self):
return self._epochs_completed
def next_batch(self, batch_size, fake_data=False, shuffle=True):
"""Return the next `batch_size` examples from this data set."""
if fake_data:
fake_image = [1] * 784
if self.one_hot:
fake_label = [1] + [0] * 9
else:
fake_label = 0
return [fake_image for _ in xrange(batch_size)
], [fake_label for _ in xrange(batch_size)]
start = self._index_in_epoch
# Shuffle for the first epoch
if self._epochs_completed == 0 and start == 0 and shuffle:
perm0 = numpy.arange(self._num_examples)
numpy.random.shuffle(perm0)
self._images = self.images[perm0]
self._labels = self.labels[perm0]
# Go to the next epoch
if start + batch_size > self._num_examples:
# Finished epoch
self._epochs_completed += 1
# Get the rest examples in this epoch
rest_num_examples = self._num_examples - start
images_rest_part = self._images[start:self._num_examples]
labels_rest_part = self._labels[start:self._num_examples]
# Shuffle the data
if shuffle:
perm = numpy.arange(self._num_examples)
numpy.random.shuffle(perm)
self._images = self.images[perm]
self._labels = self.labels[perm]
# Start next epoch
start = 0
self._index_in_epoch = batch_size - rest_num_examples
end = self._index_in_epoch
images_new_part = self._images[start:end]
labels_new_part = self._labels[start:end]
return numpy.concatenate((images_rest_part, images_new_part),
axis=0), numpy.concatenate(
(labels_rest_part, labels_new_part), axis=0)
else:
self._index_in_epoch += batch_size
end = self._index_in_epoch
return self._images[start:end], self._labels[start:end]
@deprecated(None, 'Please write your own downloading logic.')
def _maybe_download(filename, work_directory, source_url):
"""Download the data from source url, unless it's already here.
Args:
filename: string, name of the file in the directory.
work_directory: string, path to working directory.
source_url: url to download from if file doesn't exist.
Returns:
Path to resulting file.
"""
if not gfile.Exists(work_directory):
gfile.MakeDirs(work_directory)
filepath = os.path.join(work_directory, filename)
if not gfile.Exists(filepath):
urllib.request.urlretrieve(source_url, filepath)
with gfile.GFile(filepath) as f:
size = f.size()
print('Successfully downloaded', filename, size, 'bytes.')
return filepath
@deprecated(None, 'Please use alternatives such as:'
' tensorflow_datasets.load(\'mnist\')')
def read_data_sets(train_dir,
fake_data=False,
one_hot=False,
dtype=dtypes.float32,
reshape=True,
validation_size=5000,
seed=None,
source_url=DEFAULT_SOURCE_URL):
if fake_data:
def fake():
return _DataSet([], [],
fake_data=True,
one_hot=one_hot,
dtype=dtype,
seed=seed)
train = fake()
validation = fake()
test = fake()
return _Datasets(train=train, validation=validation, test=test)
if not source_url: # empty string check
source_url = DEFAULT_SOURCE_URL
train_images_file = 'train-images-idx3-ubyte.gz'
train_labels_file = 'train-labels-idx1-ubyte.gz'
test_images_file = 't10k-images-idx3-ubyte.gz'
test_labels_file = 't10k-labels-idx1-ubyte.gz'
local_file = _maybe_download(train_images_file, train_dir,
source_url + train_images_file)
with gfile.Open(local_file, 'rb') as f:
train_images = _extract_images(f)
local_file = _maybe_download(train_labels_file, train_dir,
source_url + train_labels_file)
with gfile.Open(local_file, 'rb') as f:
train_labels = _extract_labels(f, one_hot=one_hot)
local_file = _maybe_download(test_images_file, train_dir,
source_url + test_images_file)
with gfile.Open(local_file, 'rb') as f:
test_images = _extract_images(f)
local_file = _maybe_download(test_labels_file, train_dir,
source_url + test_labels_file)
with gfile.Open(local_file, 'rb') as f:
test_labels = _extract_labels(f, one_hot=one_hot)
if not 0 <= validation_size <= len(train_images):
raise ValueError(
'Validation size should be between 0 and {}. Received: {}.'.format(
len(train_images), validation_size))
validation_images = train_images[:validation_size]
validation_labels = train_labels[:validation_size]
train_images = train_images[validation_size:]
train_labels = train_labels[validation_size:]
options = dict(dtype=dtype, reshape=reshape, seed=seed)
train = _DataSet(train_images, train_labels, **options)
validation = _DataSet(validation_images, validation_labels, **options)
test = _DataSet(test_images, test_labels, **options)
return _Datasets(train=train, validation=validation, test=test)
2. Solve the error ModuleNotFoundError: No module named 'tensorflow.contrib'
Problem : The contrib package cannot be used in TensorFlow2.x version

3. Install onnx error assert CMAKE, 'Could not find "cmake" executable!'
 After Baidu, I found out: installing onnx requires protobuf compilation, so protobuf needs to be installed before installation.
After Baidu, I found out: installing onnx requires protobuf compilation, so protobuf needs to be installed before installation.
四、ImportError: cannot import name 'builder' from 'google.protobuf.internal'
Problem : When running the torch to onnx code, it appears ImportError: cannot import name 'builder' from 'google.protobuf.internal', as shown below:
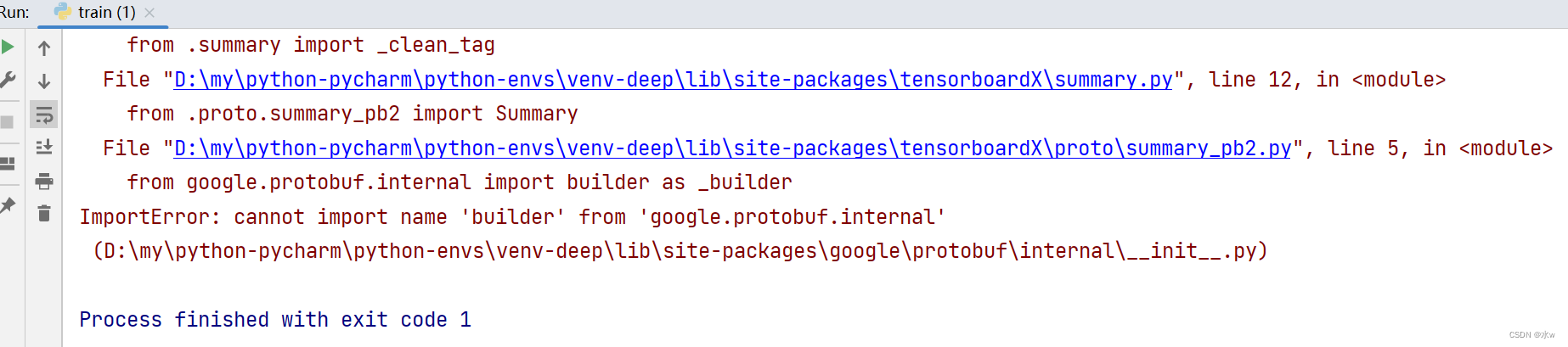
Causegoogle.protobuf : Caused by using too low version. In newer versions, buildermodules have been moved to google.protobufpackages and are no longer in google.protobuf.internal.
Solution : upgrade the protobuf library
pip install --upgrade protobuf5. Solve ModuleNotFoundError: No module named 'sklearn'
Problem : sklearn third-party library installation failed
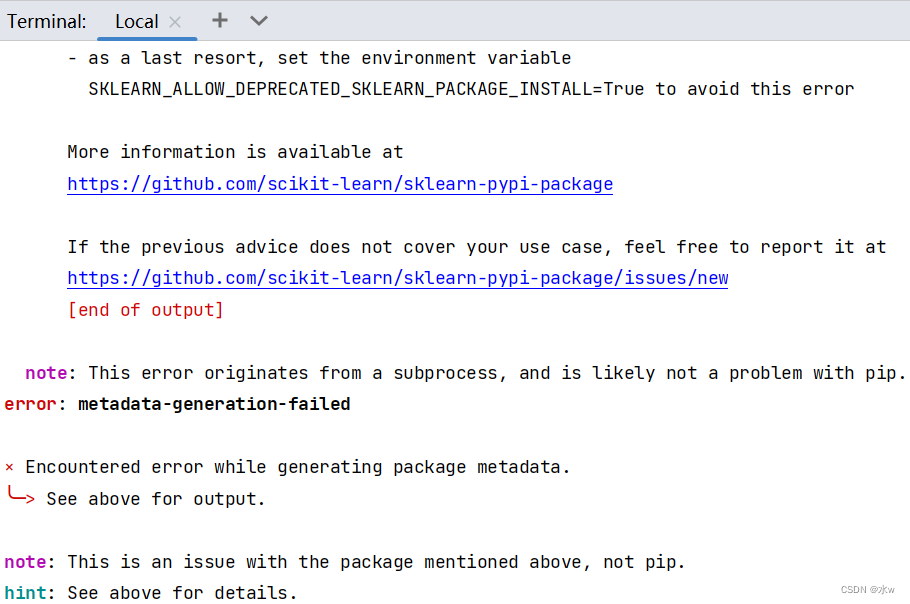
Reason : Check the list of other libraries and find that the package name of sklearn is scikit-learn
Solution : install scikit-learn,
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn
六、解决AttributeError: module ‘torch._C‘ has no attribute ‘_cuda_setDevice‘
The reason for the online query : It is said that the torch I installed is suitable for CPUs, not GPUs. So I inquired about the pytorch version, the code is as follows,
import torch
torch.cuda.is_available()The result is False.
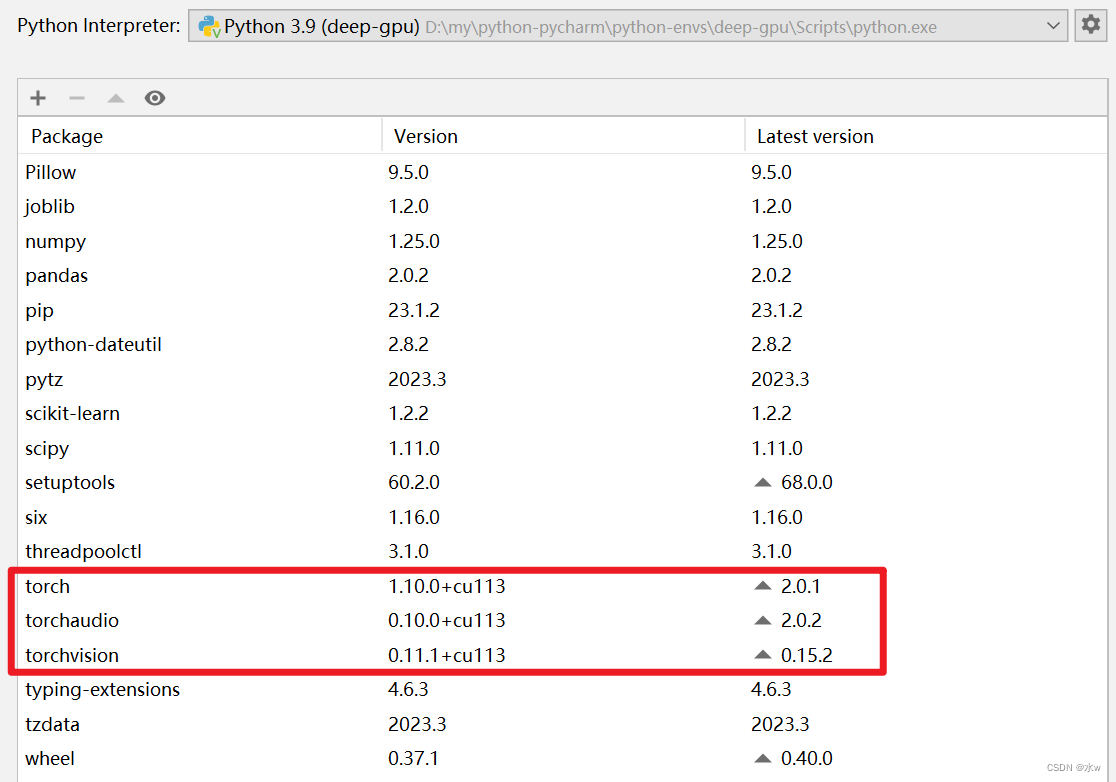
Obviously, the environment uses the CPU version of torch, but I double checked the commands I installed, as follows
Solution : Download three installation packages, suitable for the GPU version,
You can refer to this (1 message) GPU version to install the latest method of Pytorch tutorial_pytorch gpu_水w的博客-CSDN博客

Then pip install them separately, so that you can install torch suitable for the GPU version.
Download ImportError: Missing optional dependency 'pytables'. Use pip or conda to install pytables.
Problem : Running the py file reports an error
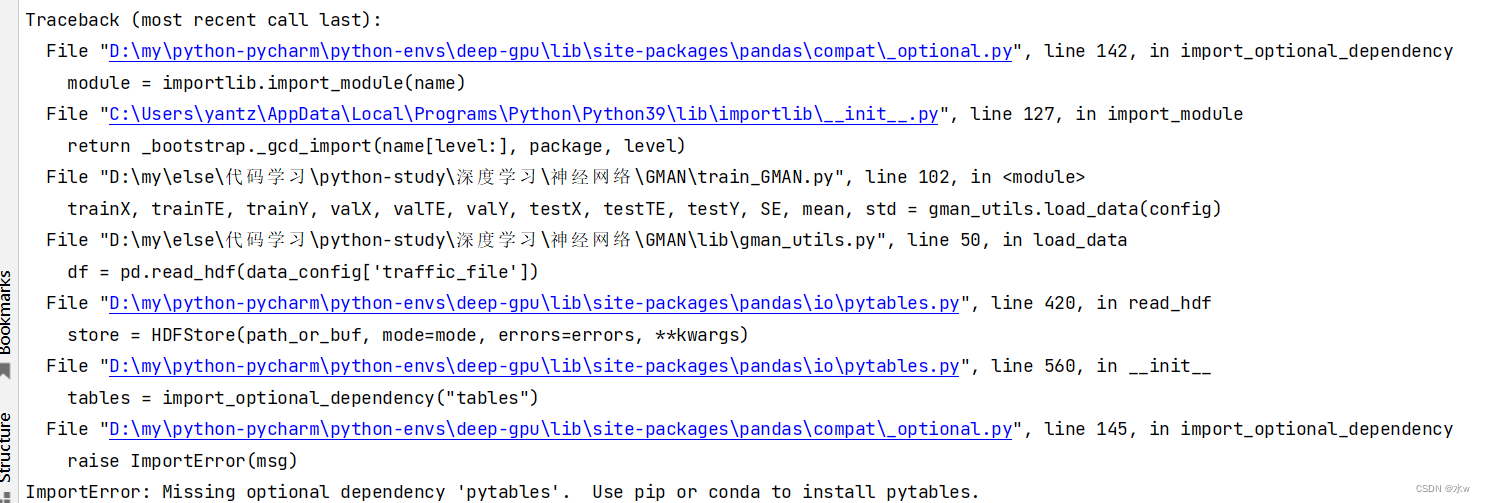
Solution process : Follow the prompts to install pytables, "pip install pytables" failed to install, and then tried "pip install tables" to install it.
Re-run the code and find that no error is reported.
八、解决AttributeError: module ‘distutils’ has no attribute ‘version’.
问题: AttributeError: module ‘distutils’ has no attribute ‘version’.
Solve : "setuptools version problem", the problem caused by the version is too high; setuptools version
- Step 1: pip uninstall setuptools [use pip, not conda uninstall setuptools; [cannot use conda commands, the reason is that when conda uninstalls, it will automatically analyze its related libraries, and then delete them all, if y, the entire The environment needs to be reconfigured.
- Step 2: pip or conda install setuptools==59.5.0 [Now the latest version has reached 65, the previous old version is only partially reserved, and the version that cannot be found will not work
Then re-run the code and found that no error was reported.