Multilayer Perceptron Algorithm (Learning Record)
1. Why introduce the multi-layer perceptron algorithm?
The pseudocode used when training the perceptron is
initialize w=0 and b=0
repeat
if [yi<w,xi>+b] <=0 then
w = w+yixi and b = b+yi
end if
untill all classified correct
If the classification is correct, it means that yi <w,xi>+b is a positive value, otherwise it means that the classification is wrong, and it needs to continue to propagate backwards. Therefore, the loss function when training the perceptron can be defined as loss=Max(0,-y<w,x>), and when within a radius r, y(wx+b)>=rou, it can be classified into two categories.
But because the linear model often makes mistakes, for example, when using the linear model to realize the xor data, there is no way to handle it well, so the multi-layer perceptron algorithm is used to train the model.
2. When looking at the algorithm implementation of Li Mu's multi-layer perceptron, I noticed several functions
One, loss = nn.CrossEntropyLoss(reduction='none') The corssentropyLoss here represents the cross entropy loss. So what is cross entropy?
1.1 Information volume
(The content of this section refers to "Deep Learning Flower Book" and "Pattern Recognition and Machine Learning")
The basic idea of information volume is that an unlikely event happened, and we receive more information than a very likely event happened.
To understand with an example, suppose we received the following two messages:
A: The sun rose this morning
B: There is a solar eclipse this morning
We think that message A is so informative that it is unnecessary to send it, while message B is very informative. Using this example, let's refine the basic idea of information volume: ① events that are very likely to occur should have less information, and in extreme cases, events that are guaranteed to happen should have no information; ② events that are unlikely to occur should have less information; have a higher amount of information. The amount of information an event contains should be inversely related to its probability of occurrence.
Suppose it is a discrete random variable, its value set is, and the amount of information defining the event is:
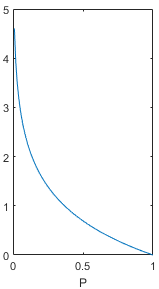
Among them, log represents the natural logarithm, and the base is e (there are also some data that use the logarithm with the base 2). In the formula, it is the probability of the value of the variable. This probability value should fall between 0 and 1. Draw the value of the above function when P is 0-1. The image is as follows. When the probability value tends to 0, the amount of information tends to be positive infinity, and when the probability value tends to 1, the amount of information tends to 0. This function can satisfy the basic idea of information amount and can be used to describe the amount of information.
1.2 Entropy
(This section refers to "Pattern Recognition and Machine Learning")
The information amount formula given above can only deal with the amount of information when a random variable takes a specified value. We can use Shannon entropy (referred to as entropy) to describe the average information amount of the entire probability distribution. The specific method is to find the expectation of the above-mentioned information amount function about the probability distribution. The expected value (ie entropy) is:
Let's get a deeper understanding of entropy by computing a few examples.
1.3 Relative entropy (KL divergence)
(This section refers to "Pattern Recognition and Machine Learning")
Assume that the real probability distribution of random variables is , and we use an approximate distribution for modeling when dealing with practical problems. Since we are using is instead of real, we need some additional information to counteract the effect of different distributions when specifying the value. The average amount of additional information we need can be calculated using relative entropy, or KL divergence (Kullback-Leibler Divergence), which can be used to measure the difference between two distributions:
Two properties of the KL divergence are introduced below:
① KL divergence is not a symmetrical quantity,
② The value of KL divergence is always 0, if and only when the equal sign holds ****1.4 cross entropy****
1.4 Cross entropy
Finally, the protagonist cross-entropy is here. In fact, cross-entropy is closely related to the KL divergence just introduced. Let us change the KL divergence formula above:
Cross entropy is equal to:
That is, the right half (with the negative sign) of the KL divergence formula.
Careful friends may have discovered that if we regard it as the real distribution of random variables, the left half of the KL divergence is actually a fixed value, and the size change of the KL divergence is actually determined by the cross entropy of the right half. Because the right half contains approximate distribution, we can regard it as the real-time output of the network or model, and regard KL divergence or cross entropy as the difference between the real label and the network prediction result, so the purpose of the neural network is to make the approximate distribution through training close to the true distribution. In theory, optimizing KL divergence should have the same effect as optimizing cross-entropy. So I think that the reason for choosing to optimize cross-entropy instead of KL divergence in deep learning may be to reduce some calculations. After all, cross-entropy is one less item than KL divergence.
In the cross-entropy here, I am very grateful to the author, the original link is placed below http://t.csdn.cn/XPP3S
Second, hands-on deep learning - multi-layer perceptron : updater = torch.optim.SGD( params , lr=lr), what is it used for?
The params here contain [w1, b1, w2, b2], and these parameters need to be continuously updated with random gradient gradients, and torch.optim is a library that implements various optimization algorithms. In order to use torch.optim , you need to construct an optimizer object. This object holds the current parameter state and performs parameter updates based on the computed gradients. It is more convenient to use.