Recommended reading time 20 minutes
background
In the recent renovation project, the url of all static resources is issued by the server, and params such as authentication and expiration time are brought, which leads to the invalidation of http cache, one of the static resource optimization tools: as long as the url of the delivered resource expires, the resource will be The download was re-requested, but the resource has not actually changed .
This article describes offline/long cache from three aspects:
- http cache
- Offline cache (Application Cache)
- Service Worker
HTTP cache
The following part directly quotes the previous article "Understanding the HTTP Cache Mechanism in One Article"
One-sentence overview: The requested resources are cached locally, and subsequent requests can reuse these resources directly as much as possible, reducing Http requests, thereby significantly improving the performance of websites and applications.
So when do you cache resources locally? When do cached resources expire? Under what circumstances are these cached resources used? This article begins with these three questions.
HTTP caching mechanism process
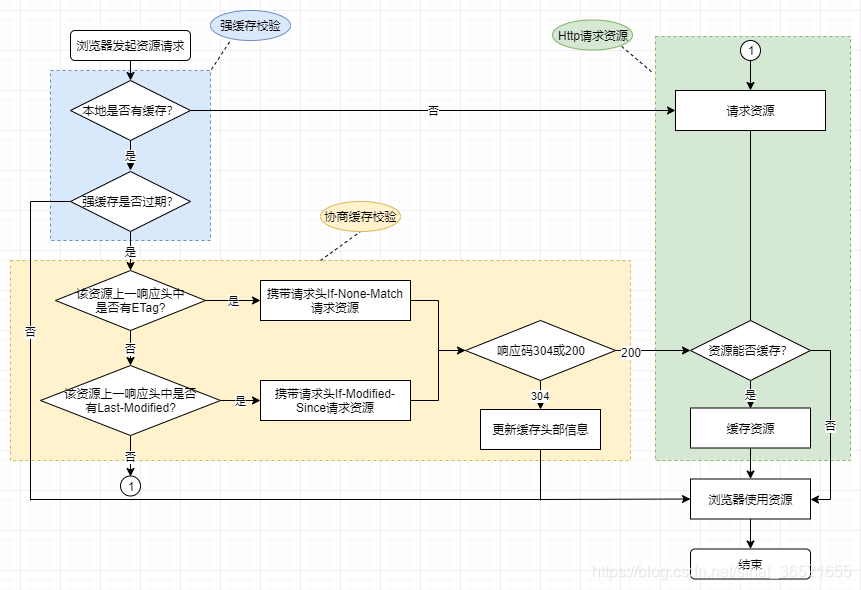
As can be seen from the process, after the browser initiates a resource request, there are roughly three parts: strong cache verification, negotiation cache verification, and resource request. This article mainly explains the strong cache and negotiation cache module. The resource request part is a normal HTTP interaction process, but it is worth noting that:
Because only requests are generally
GETcached, this generally refers to generalGETresource requests.
strong cache
There is no need to send additional requests to the server, and the local cache is used directly. In the Chrome browser, the local strong cache is divided into two types, one is disk cache, and the other is memory cache, if you view the Networks in devtools, you will see that the request status is 200, and the request followed by from disk cacheand from memory cacheis the use of strong cache, as shown in the following two figures .
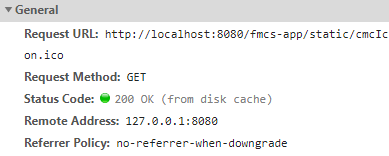
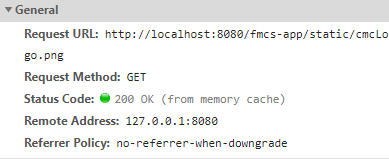
I have not yet understood how the Chrome browser controls the two strong caches, so I will not expand it, so as not to mislead readers, and I hope someone can point it out! ! ! ! Here is the description found in the official Chrome document, which generally means that the two strong caching strategies are related to the life cycle of the rendering process, and the cycle of the rendering process roughly corresponds to the tab tab:
Chrome employs two caches — an on-disk cache and a very fast in-memory cache. The lifetime of an in-memory cache is attached to the lifetime of a render process, which roughly corresponds to a tab. Requests that are answered from the in-memory cache are invisible to the web request API.
Whether to use strong caching is controlled by three HTTP header fields: Expires, Pragma, Cache-Control.
Expires
Exipresfield is Http/1.0the field in which has the lowest priority of the three cache-control fields.
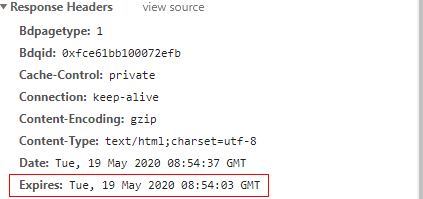
As shown in the figure, the value in the response header Expiresis a timestamp. When the request is initiated, if the local system time is before this timestamp, the cache is valid; otherwise, the cache is invalid and enters the negotiation cache. If the response header Expiresis set to an invalid date, for example 0, it represents a date in the past, that is, the resource has expired.
Cache-Control
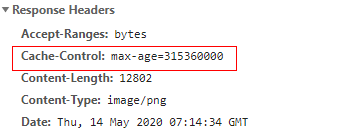
Cache-ControlIs HTTP/1.1the general header field specified in , and the common attributes are as follows:
no-store: The use of cache is prohibited, and each request goes to the server to get the latest resources;no-cache: Do not use a strong cache, directly enter the negotiation cache module, and request the server to verify whether the resource is "fresh";private: private cache, the intermediate proxy server cannot cache resourcespublic: public cache, the intermediate proxy server can cache resourcesmax-age: Unit: second, the maximum effective time of the cache. Its starting time is the Date field in the response header when caching, that is, the validity period reaches responseDate + max-age, and the cache expires when the request is initiated beyond this time.must-revalidate: Once the cache expires, you must re-authenticate to the server.
Pragma
Pragmais HTTP/1.0a common header field specified in , used for backward compatibility with HTTP/1.0cache servers that only support the protocol. This field has only one value: no-cache, and its behavior is Cache-Control: no-cacheconsistent with that of , but HTTPthe response header does not clearly define this attribute, so it cannot be used to completely replace the header HTTP/1.1defined in Cache-control.
If both fields
PragmaandCache-Controlexist at the same time,Pragmathe priority of is greater thanCache-Control.
negotiation cache
When the strong cache expires or the request header field setting does not strengthen the cache, such as Cache-Control:no-cacheand Pragma:no-cache, enter the negotiation cache part. Negotiation caching involves two pairs of header fields, Last-Modified/ If-Modified-Since, and ETag/ If-None-Match.
If-Modified-SinceIf the or field is carried in the request header If-None-Match, it will initiate to the server to check whether the resource has changed. If there is a change, the cache will be missed, and the server will return. The browser will calculate 200whether the resource in the response body is cached and use the resource; if not, Then hit the cache, return 304, the browser updates the cache header information according to the response header, extends the validity period, and directly uses the cache.
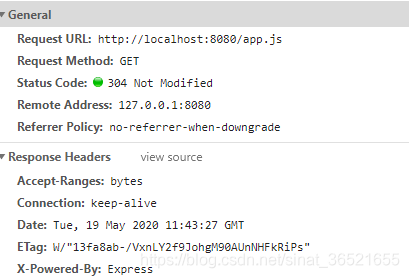
Last-Modified/If-Modified-Since
Last-ModifiedThe value of / If-Modified-Sinceis the resource modification time. When requesting a resource for the first time, the server puts the last modification time of the resource in the field of the response header Last-Modified, and when requesting the resource for the second time, the browser will automatically Last-Modifiedput the value in the last response header of the resource in the second In the field of the second request header If-Modified-Since, the server compares the last modification time of the server resource with If-Modified-Sincethe value in the request header. If they are equal, the cache hits and returns 304, otherwise, 200 is returned.
ETag/If-None-Match
ETagThe value of / If-None-Matchis a hashstring of values ( hashthe algorithm is not uniform), which is the identifier of the resource. When the content of the resource changes, its hashvalue will also change. The process is similar to the above, but the server compares hashthe value of the server resource with the value in the request header If-None-Match, but the comparison method is different because ETagthere are two types:
强校验: The resource hash value is unique, once it changes, the hash will also change.弱校验: The resource hash value startsW/with . If the resource changes slightly, it may also hit the cache.
For example like this:
ETag: “33a64df551425fcc55e4d42a148795d9f25f89d4”
ETag: W/ “0815”
difference between the two
ETag/ has a higherIf-None-Matchpriority thanLast-Modified/If-Modified-Since;Last-Modified/If-Modified-SinceThere is a 1S problem, that is, the server modifies the file within 1S, and when it is requested again, it will return incorrectly304.
Proxy service cache
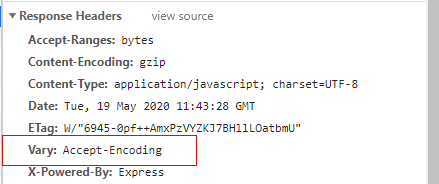
VaryIt is HTTP/1.1a header field in , whose value is the field in the request header. As shown in the figure above Accept-Encoding, it can be multiple, separated by commas, which records which request header fields are referenced by the resource returned by the proxy server. When the proxy server gets the response message from the source server, it will Varycache resources of different versions according to the field list in . When a resource request is accessed again, the proxy server will analyze the request header field and return the correct version.
Application Cache (deprecated)
Although some browsers still support it, W3C has abandoned this solution and recommends developers to use Service Worker.

Introduction
HTML5's offline storage (Application Cache) is a caching mechanism (not a storage technology) based on a manifest file (cache manifest file, generally suffixed as .appcache). Define the files that need to be cached in this file. Browsers that support the manifest will save the files locally according to the rules of the manifest file. Afterwards, when the network is offline, the browser will use the data stored offline. exhibit. It is mainly used in scenarios where the content changes little and is relatively fixed. The process is roughly as follows:
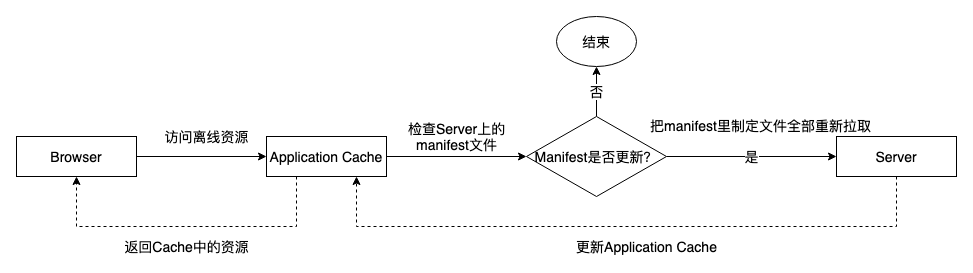
It has the following advantages:
- Offline Browsing - Users can use apps while they are offline.
- Faster speed - Cached resources load faster.
- Reduced server load - the browser will only download updated or changed resources from the server.
file configuration
A typical manifest file structure is as follows:
CACHE MANIFEST
#version 1.0
CACHE:
/static/img/dalizhineng.c66247e.png
http://localhost:8080/static/img/setting-icon-hover.413c0d7.png
NETWORK:
*
FALLBACK:
/html5/ /404.html
The CACHE MANIFEST of the first line is a fixed line and must be written in front.
Generally, the second line is a comment starting with #. When there is a cache file that needs to be updated, just change the content of the comment. It can be version number, timestamp or md5 code, etc.
The remaining content is divided into three sections (in any order, and each section can be repeated in the same manifest):
-
CACHE (required)
identifies which files need to be cached, which can be a relative path or an absolute path. -
NETWORK (optional)
identifies which files must be requested over the network. It can be a relative path or an absolute path, indicating that the specified resource must be requested through the network; the wildcard * can also be used directly, indicating that all resources except CACHE require a network request.
For example, the following example is that 'index.css' will never be cached and must go through the network request.
NETWORK:
index.css
- FALLBACK (optional)
indicates that the browser will use the fallback resource when the specified resource cannot be accessed.
Each of these records lists two URIs: the first for the resource, and the second for the fallback resource. Both URIs must use relative paths and have the same origin as the manifest file. Wildcards can be used. For example, in the following example, when the page cannot be accessed, 404.html is used instead.
FALLBACK:
*.html /404.html
Instructions
Set the manifest attribute in the html tag of the document, and refer to the manifest file, which can point to an absolute URL or a relative path, but the absolute URL must have the same origin as the corresponding web application, and the MIME-type must be correctly configured on the server side, that is, "
text /cache-manifest".
<html lang="en" manifest="manifest.appcache">
accessing and manipulating the cache
Some browsers provide window.applicationCache object to access and operate offline cache.
cache status
The window.applicationCache.status property indicates the current cache status.
| state | status value | describe |
|---|---|---|
| UNCACHED | 0 | No cache, i.e. no application cache associated with the page |
| IDLE | 1 | Idle, i.e. the app cache is not being updated |
| CHECKING | 2 | Checking, i.e. downloading description files and checking for updates |
| DOWNLOADING | 3 | Downloading, that is, the application cache is downloading the description file |
| UPDATEREADY | 4 | The update is complete and all resources have been downloaded |
| OBSOLETE | 5 | Obsolete, that is, the description file of the application cache no longer exists, so the page can no longer access the application cache |
Cache events
| event name | describe |
|---|---|
| cached | When the download is complete and the app is downloaded into the cache for the first time, the browser fires a "cached" event |
| checking | Whenever the application loads, the manifest file is checked, and the "checking" event is always triggered first |
| downloading | If the application has not been cached, or the manifest file has changed, the browser will download and cache all the resources in the manifest, and trigger the "downloading" event, which means that the download process starts |
| error | The "error" event is fired if the browser is offline and fails to check the manifest list. It is also fired when an uncached application references a manifest file that does not exist. |
| noupdate | If there are no changes, and the application has been cached, the "noupdate" event is triggered and the whole process ends |
| obsolete | If a cached application references a manifest file that does not exist, "obsolete" will be triggered, and resources will not be loaded from the cache but will be loaded over the network after the application is removed from the cache. |
| progress | The "progress" event is triggered intermittently during the download process, usually when each file is downloaded |
| updateready | When the download is complete and the application in the cache is updated, the browser fires an "updaterady" event |
caching method
| method name | describe |
|---|---|
| abort | Cancel resource loading |
| swapCache | Replace the old cache with the new cache, but it is more convenient to use location.reload() |
| update | refresh cache |
Precautions
- Updating a file listed in the manifest does not mean that the browser will re-cache the resource, the manifest file itself must be changed.
- Browsers may have different limits on cached data (some browsers set a limit of 5MB per site).
- If the manifest file, or one of the files listed inside cannot be downloaded normally, the entire update process will fail, and the browser will continue to use the old cache.
- The html that references the manifest must have the same origin as the manifest file and be under the same domain. The resources in FALLBACK must have the same origin as the manifest file.
- The browser will automatically cache the HTML file that references the manifest file, which means that if the HTML content is changed, the version of the manifest file must be updated or the application cache must be updated by the program to update.
Service Worker
Introduction
A service worker is also a type of web worker, with the additional capability of persistent offline caching. The host environment will provide a separate thread to execute its script to solve the performance problems caused by the time-consuming and resource-consuming calculation process in js. As can be seen from the figure below, except for IE, the support is quite high.
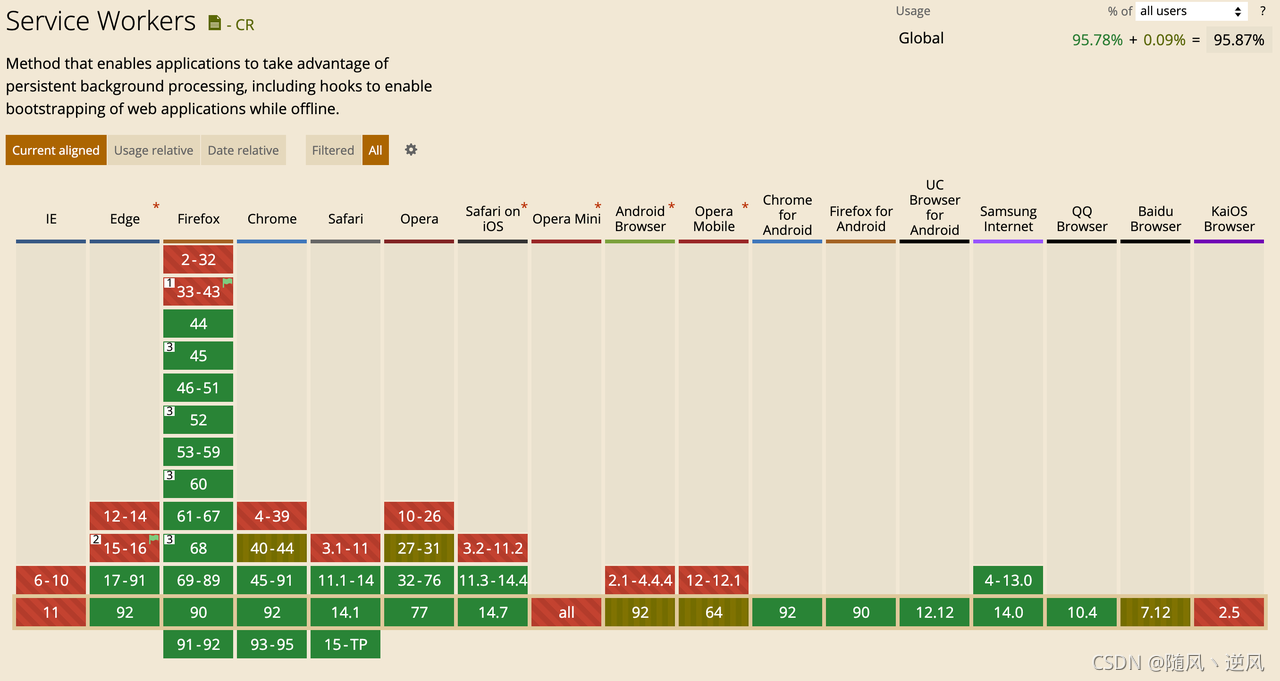
features
- Independent of the main thread of the JS engine, the script running in the background does not affect page rendering
- It exists forever after being installed, unless it is manually uninstalled. Manual uninstall method:
if ('serviceWorker' in navigator) {
navigator.serviceWorker.getRegistrations()
.then(function (registrations) {
for (let registration of registrations) {
// 找到需要移除的SW
if (registration && registration.scope === 'https://xxx.com') {
registration.unregister();
}
}
});
}
-
Can intercept requests and returns, cache files. sw can use the fetch api to intercept the network and process network requests, and cooperate with cacheStorage to realize the cache management of web pages and communicate with the front-end postMessage.
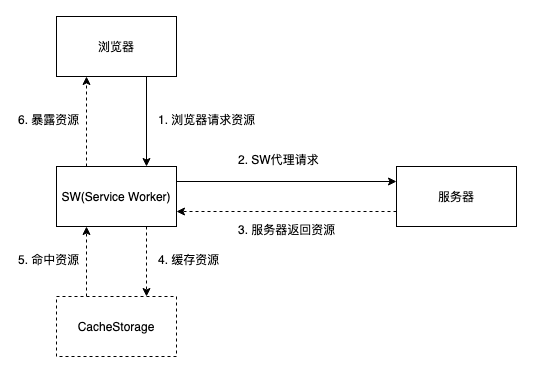
-
The dom cannot be directly manipulated: because sw is a script that runs independently of the web page, in its operating environment, the window and dom of the window cannot be accessed.
-
The production environment must be https protocol to use. When debugging locally, http://localhost and http://127.0.0.1 can also be used, but you need to check Bypass for network, otherwise the resource static resources will be cached (without hash value), making debugging impossible.

-
Asynchronous implementation, sw uses promises extensively.
-
According to the description in the document , the cacheStorage capacity is not limited at the SW level, but it is still limited by the QuotaManager of the host environment.
scope
The scope of SW is a URL path address, indicating the range of pages that SW can control. For example, the following can control all pages under the http://localhost:8080/ehx-room/ directory. The default scope is the path when registering. The following example is ./ehx-room/sw.js.
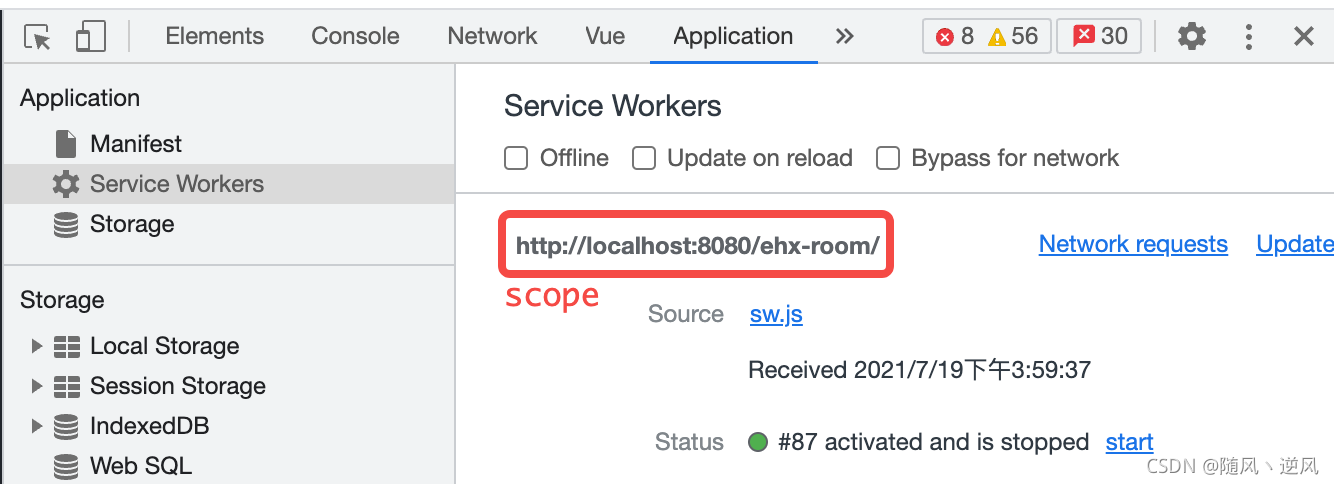
You can also pass in the {scope: '/xxx/yyyy/'} parameter in the navigator.serviceWorker.register() method to specify the scope, but the specified scope must be in the directory of the path registered by SW, for example, when registering sw above, add On, {scope: '/'} will report an error.

life cycle
When we register a Service Worker, it will go through various stages of the life cycle and trigger corresponding events. The whole life cycle includes: installing --> installed --> activating --> activated --> redundant. When the Service Worker is installed (installed), it will trigger the install event; and after it is activated (activated), it will trigger the activate event.

- Installing
This state occurs after the service worker is registered, indicating that the installation has started. During this process, the install event will be triggered, and resources can be cached offline.
- In the install callback event function, you can call the event.waitUntil() method and pass in a promise, and the install will not end until the promise is completed.
- You can also use the self.skipWaiting() method to directly enter the activating state without waiting for other Service workers to be closed
- Installed
SW has completed the installation and entered the waiting state, waiting for other Service workers to be closed - Activating
clients that are not controlled by other SWs in this state allow the current worker to complete the installation, clear other workers and the old cache resources associated with the cache, and wait for the new Service Worker thread to be activated. - Activated
will handle the activate event callback in this state, and provide processing functional events: fetch, sync, push.
In addition to supporting the event.waitUntil() method, in the activate callback event function, you can also use the self.clients.claim() method to control the currently opened webpage without refreshing.
- The state of Redundant
indicates that the life cycle of a SW is over and is being replaced by another SW.
work process
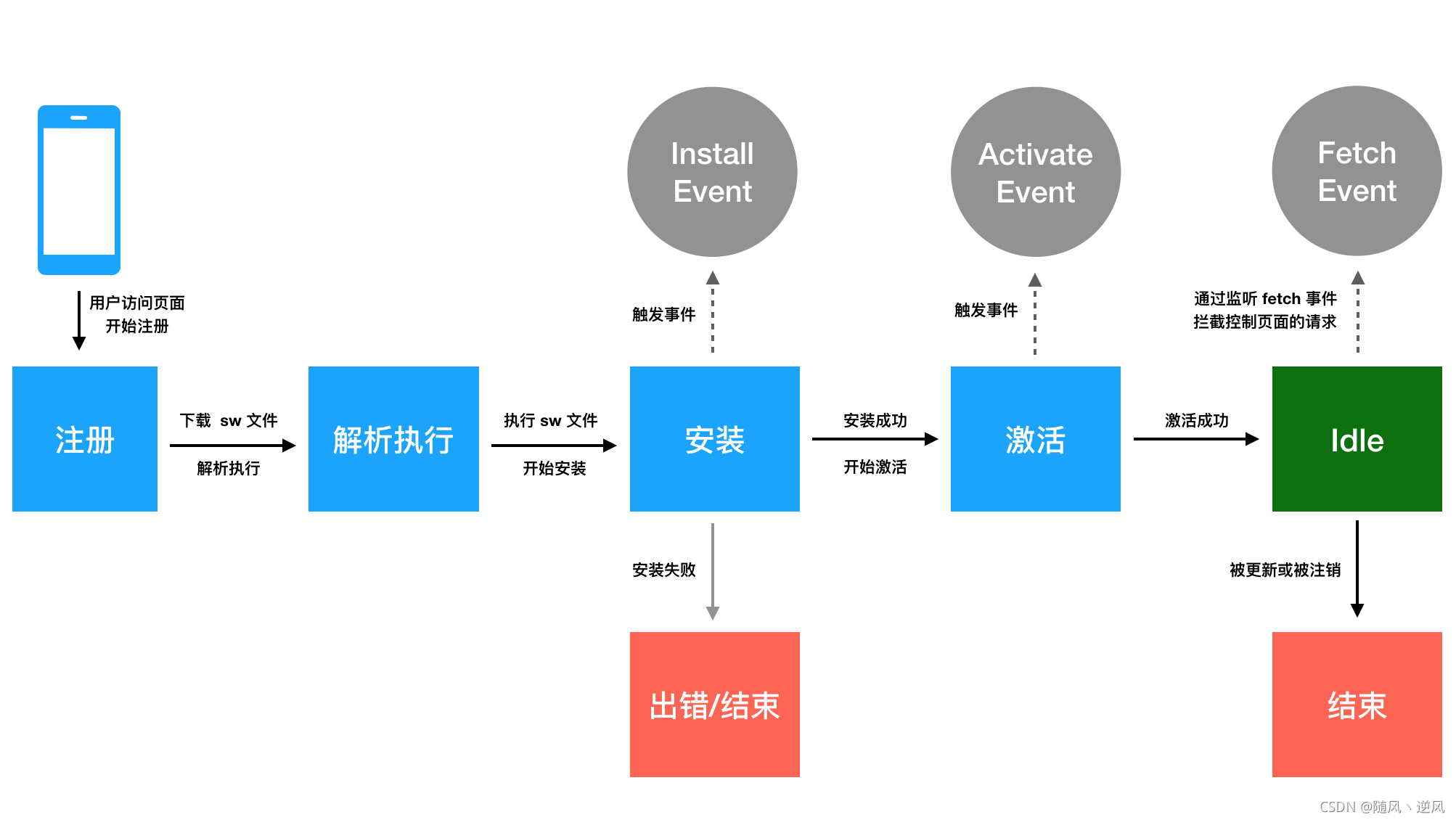
- After the main thread successfully registers the Service Worker, it starts to download and parse and execute the Service Worker file. During the execution, the Service Worker starts to be installed, and the install event of the worker thread is triggered during the process.
- If the install event callback is successfully executed (the install callback usually does some cache read and write work, and there may be failures), the Service Worker will be activated, and the activate event of the worker thread will be triggered during the process. If the install event If the callback execution fails, the life cycle enters the Error termination state, terminating the life cycle.
- After the activation is completed, the Service Worker can control the resource requests of the pages under the scope, and can listen to the fetch event.
- If the Service Worker is unregistered after activation or a new Service Worker version is updated, the current Service Worker life cycle ends and enters the Terminated final state.
example
// 在页面onload事件回调中,注册SW
if ('serviceWorker' in navigator) {
window.addEventListener('load', () => {
navigator.serviceWorker.register('service-worker.js')
.then(registration => {
// 注册成功
})
.catch(err => {
// 注册失败
});
});
}
// service-worker.js
const CACHE_VERSION = 'unique_v1';
// 监听activate事件,激活后清除其他缓存
self.addEventListener('activate', event => {
const cachePromise = caches.keys().then(keys => {
return Promise.all(
keys.map(key => {
if (key !== CACHE_VERSION) {
return caches.delete(key);
}
})
);
});
event.waitUntil(cachePromise).then(() => {
// 通过clients.claim方法,让新的SW获得当前页面的控制权
return self.clients.claim();
});
});
// 在fetch事件里能拦截网络请求,进行一些处理
self.addEventListener('fetch', event => {
event.respondWith(
caches
.match(event.request, {
// 忽略url上的query部分
ignoreSearch: true,
})
.then(response => {
// 如果匹配到缓存里的资源,则直接返回
if (response) {
return response;
}
// 匹配失败则继续请求,拷贝原始请求
const request = event.request.clone();
return fetch(request).then(httpRes => {
// 无响应数据、请求失败(非200和304)、post请求(SW不能缓存post请求)三种情况直接返回
if (!httpRes || ![200, 304].includes(httpRes.status) || request.method === 'POST') {
return httpRes;
}
// 请求成功的话,将请求缓存起来。
const responseClone = httpRes.clone();
caches.open(CACHE_VERSION).then(cache => {
cache.put(event.request, responseClone);
});
return httpRes;
});
})
);
});
Summarize
There are three methods, specific scenarios and specific applications, each with its own advantages.
| method\class | Graininess | Do you need to connect to the Internet | Can you actively update | size limit |
|---|---|---|---|---|
| HTTP cache | single resource | Strong cache resources can be used offline | no | Browser QuotaManager Limitations |
| Application Cache | entire application | no | yes | Usually 5MB |
| Service Worker | single resource | no | no | Browser QuotaManager Limitations |
reference documents
Read an article to understand the HTTP caching mechanismUse
Service Worker and cacheStorage caching and offline development
Workbox webpack Plugins
to make your WebApp available
offlineHTML5 offline caching-manifest introduction
Application caching primary user guideChapter
4 Service Worker · PWA application combat
Service Worker offline caching practice