Here is a detailed summary of the data structure of the queue in C++, involving the basic knowledge of the queue, the variants of the queue, and the corresponding application scenarios. its a try.
Queue Basics
Simply put, a queue is a linear table of "First In First Out" , referred to as "FIFO structure" for short .
Specifically, refer to the following
01. Queue Basics | Algorithm Clearance Manual (itcharge.cn)
Basic operation of the queue
- Initialize an empty queue : Create an empty queue, define the size of the queue
size, and the queue head element pointerfrontand queue tail pointerrear. - Determine whether the queue is empty : return when the queue is empty
True. Returns when the queue is not emptyFalse. Generally, it is only used in "dequeue operation" and "get queue head element operation". - Determine whether the queue is full : return when the queue is full
True, and return when the queue is not fullFalse. It is generally only used for inserting elements in sequential queues. - Inserting elements (enqueuing) : It is equivalent to inserting a new data element after the last data element of the linear table. And change the pointing position of the tail pointer
rear. - Delete element (dequeue) : Equivalent to delete the first data element in the linear table. And change the pointing position of the queue head pointer
front. - Get the head element of the queue : it is equivalent to getting the first data element in the linear table. Different from inserting elements (into the queue) and deleting elements (out of the queue), this operation does not change the
frontpointing position of the queue head pointer. - Get the tail element : it is equivalent to get the last data element in the linear table. Different from inserting elements (into the queue) and deleting elements (out of the queue), this operation does not change the
rearpointing position of the pointer at the end of the queue.
The basic knowledge of the queue and the basic operation of the queue determine the uniqueness of the queue in the data structure. These are the core things.
circular queue
To put it simply: the queue is the data structure of the original linear relationship, and the circular queue connects it end to end, which is logically regarded as a ring, similar to the circular linked list, but the operation is still the operation of the queue.
Specifically, refer to Baidu Encyclopedia:
Circular Queue_Baidu Encyclopedia (baidu.com)
01. Queue Basics | Algorithm Clearance Manual (itcharge.cn)
The basics of the first linked queue above also have an implementation of a circular queue.
The emergence of the circular queue is to solve the "false overflow" problem. This problem will only occur when you use the structure of an array as the underlying implementation queue.
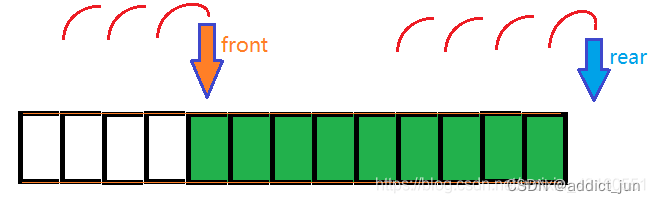
A picture is stolen here (hey), we can see that every time we go out and enter the team, we just change the position of the pointer. So every time you go out of the queue, the front space will not be used. Similarly, every time you enter the queue, the tail pointer will point backwards, so that such a "false overflow" problem will appear over time, obviously the space is enough, But the last displayed result is indeed a stack overflow.
priority queue
To put it simply: the order in which the priority queue is pushed into the stack is irrelevant, but the order in which the priority queue is popped needs to be dequeued according to the highest-level rules.
Specifically, you can refer to the following knowledge.
01. Priority queue knowledge | Algorithm clearance manual (itcharge.cn)
for example:
For example, Dijkstra's algorithm, if the labeling method is used for calculation, it is necessary to extract the data closest to the labeled data from the unlabeled data each time. Then the order in which the unlabeled nodes enter the queue through calculation does not matter, but the dequeue must be the shortest distance.
There are generally three implementations of priority queues: heaps, arrays, and linked lists.
| Enqueue operation time complexity | Dequeue operation (take out the element with the highest priority) time complexity | |
|---|---|---|
| heap | O(log2n) | O(log2n) |
| array | O(n) | O(1) |
| linked list | O(1) | O(n) |
Here is a detailed explanation of the heap implementation of the priority queue. Let you have a deeper understanding of the priority queue. The bottom layer of the priority queue can use arrays and linked lists, but the efficiency is not as fast as using heaps.
A binary heap is used here to implement a priority queue. The first is to heap the result, we can see
The data in the heap structure is arranged in the order of parent node < left child node < right child node.
- When inserting a new element, the element is at the end of the heap.
- Adjustments are required when newly inserted elements disrupt the balance of the original data.
- Adjust the speed, according to the binary heap, the time is O(logn).
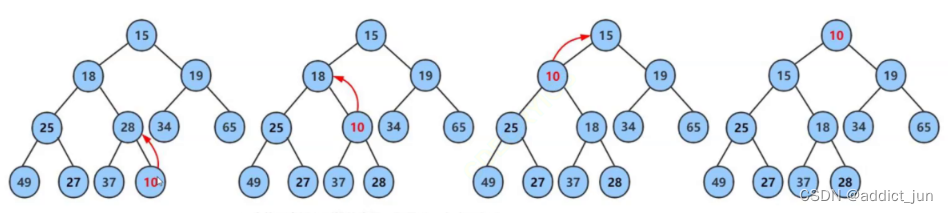
So we found that the priority queue is the same as the heap sort, borrow the structure of the heap, and take out the maximum or minimum value each time.
deque
To put it simply: a double-ended queue has the properties of a stack and a queue at the same time, and can perform enqueue, dequeue, stack, and pop operations. However, the limitation is that only the entry and exit of the head and tail elements of the queue can be controlled each time.
Application Scenario
Here I found an interesting application scenario, that is work stealing
In the producer-consumer mode, all consumers take elements from a work queue, generally using a blocking queue; the blocking queue here is ignored.
In the work-stealing mode, each consumer has its own separate work queue. If it completes its own double-ended queue, it can secretly obtain work from the end of other consumers' double-ended queues. This is nothing short of capitalist oppression that will stop a single thread.
To put it more vividly
For example, when a page is processed in a web crawler program, more pages may be found to be processed, and efficient parallelism can be achieved through the work stealing mechanism. When a worker thread finds a new unit of work, it puts it at the end of its queue. When the deque is empty, it looks for new tasks at the end of another thread's queue, thus ensuring that each thread remains busy.
These commonly used queue structures are roughly introduced, and other queue structures are used in use.