The difference between deep learning and machine learning
Contents of this article:
1.3. Machine Learning Feature Extraction
1.4, deep learning feature extraction
1.5. Example of deep learning feature extraction
2. Data volume and computing performance requirements
1. Feature extraction
1.1. Machine learning
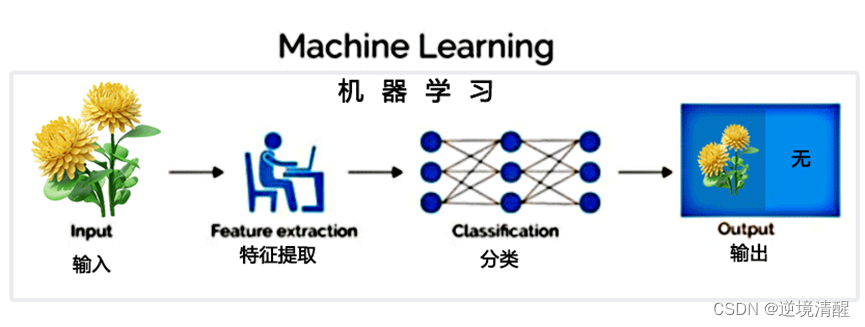
Machine learning is an artificial intelligence technique that, given a data set, automatically learns patterns and uses the learning results to predict or make decisions. It relies on mathematical and statistical algorithms to build models that allow computers to learn autonomously without being explicitly programmed.
Machine learning is a branch of artificial intelligence that refers to the ability of computer systems to automatically identify and predict patterns by analyzing and learning from large amounts of data.
In simple terms, machine learning is to let computers learn from data to perform tasks at the level of human intelligence.
Here are some commonly used concepts in machine learning:
- Dataset: Refers to the data used to train and test machine learning algorithms.
- Features: Refers to the description of the data set, which can be in digital or text format.
- Model: A concrete implementation of a machine learning algorithm that can be trained based on features and target values.
- Supervised learning: predicting the output of unknown data by training the matching of input data and known results.
- Unsupervised learning: discovering patterns in unlabeled data to infer the structure and relationships of the data.
- Deep Learning: A neural network-based machine learning technology that can simulate the neural network structure of the human brain and use multiple hidden layers to learn and classify data.
Machine learning is widely used in many fields, such as e-commerce, finance, healthcare, natural language processing, computer vision, and autonomous vehicles, among others. Common machine learning algorithms include decision trees, logistic regression, support vector machines, neural networks, and random forests.
The feature engineering step of machine learning is done manually and requires a lot of domain expertise.
1.2. Deep Learning
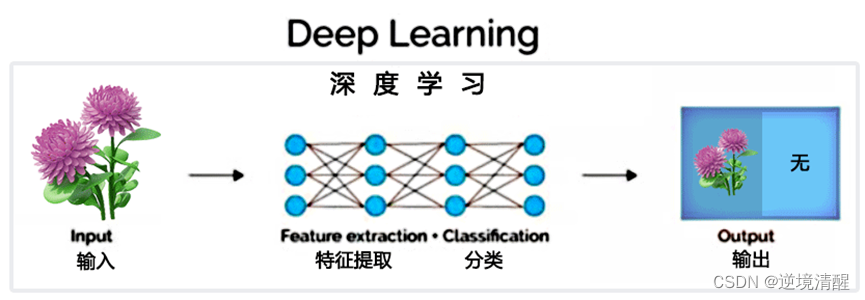
Deep learning is a method of machine learning that uses neural networks composed of multiple layers to simulate and solve complex problems. Its core idea is to gradually improve the model's ability to represent and predict data through hierarchical learning and feature extraction. In deep learning, the core technologies include backpropagation algorithm, convolutional neural network, recurrent neural network, generative confrontation network, etc. Deep learning has a wide range of application scenarios, such as image recognition, speech recognition, natural language processing, artificial intelligence and other fields.
Deep learning typically consists of multiple layers, which often combine simpler models, passing data from one layer to another to build more complex models. The model is automatically obtained by training a large amount of data, without the need for manual feature extraction.
Deep learning algorithms try to learn high-level features from data, which is a very unique part of deep learning. Thus, the task of developing a new feature extractor for each problem is reduced. It is suitable for image, speech, and natural language processing fields that are difficult to extract features.
1.3. Machine Learning Feature Extraction
Machine learning feature extraction refers to extracting useful features from raw data for training of machine learning algorithms and establishment of models. These features can be numerical values, text, images or even sounds. Through feature extraction, it can help machine learning algorithms to better understand data and achieve better data analysis and classification.
The goal of feature extraction is to find a set of features that best represent the data, and these features can enable machine learning algorithms to learn more meaningful information from the data.
The process of feature extraction includes steps such as data preprocessing, feature selection, feature extraction and feature representation. In these processes, factors such as the type, quantity, quality and distribution of data, as well as the applicability and demand of machine learning algorithms need to be considered.
1.4, deep learning feature extraction
Deep learning feature extraction refers to the process of using the deep neural network model to automatically learn and extract features from the original data, so that the original data can be better represented as a set of high-level, abstract features, which can be better applied to classification and recognition. , detection and other tasks.
Deep learning feature extraction is widely used in computer vision, natural language processing, speech recognition and other fields. The specific methods of deep learning feature extraction include convolutional neural network (CNN), recurrent neural network (RNN) and so on. By using deep neural networks to extract features from data, the accuracy and robustness of the model can be greatly improved.
Deep learning can learn complex features of input data by stacking multiple layers of neural networks.
In deep learning, each layer of neural network can be regarded as a mapping of input data, and the output of each layer can be used as the input of the next layer. By continuously stacking multiple layers of neural networks and training the weights, more complex features can be gradually extracted to achieve more accurate classification and prediction.
1.5. Example of deep learning feature extraction
The following is a deep learning model implemented using Keras to classify handwritten digits.
The model contains two convolutional layers and two fully connected layers, which can automatically learn to extract the features of handwritten digits and classify them as one of the digits 0 to 9.
import numpy as np
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D, MaxPooling2D
from keras.utils import np_utils
# Load the MNIST dataset and preprocess it
# 加载MNIST数据集并进行预处理
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32') / 255
X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32') / 255
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
# Build a deep learning model
# 构建深度学习模型
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(10, activation='softmax'))
# Compile the model
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# train the model and evaluate the performance
# 训练模型并评估性能
model.fit(X_train, y_train, epochs=10, batch_size=32, verbose=1)
score = model.evaluate(X_test, y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])
In this example, we used convolutional and max-pooling layers to extract visual features of handwritten digits, which were then transformed into digit label predictions through fully connected layers. By training the weights through the backpropagation algorithm, we can let the model automatically learn the process of extracting features, so as to achieve more efficient and accurate classification.
2. Data volume and computing performance requirements
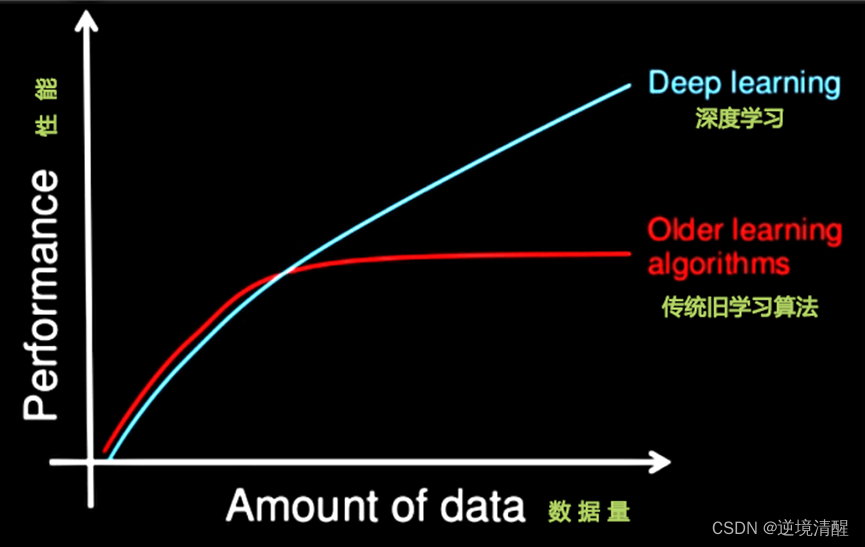
The execution time required by machine learning is much less than that of deep learning. The parameters of deep learning are often very large, and the parameters need to be trained through multiple optimizations of a large amount of data.
First, deep learning requires a large training data set.
Second, training a deep neural network requires a lot of computing power.
It can take days, or even weeks, to train a deep network using a dataset of millions of images.
So deep learning in general.
1. A powerful GPU server is required for calculation.
2. Fully managed distributed training and prediction services - such as Google's TensorFlow cloud machine learning platform.
3. Algorithm representative
Machine Learning: Naive Bayes, Decision Trees, and more
3.1. Naive Bayes algorithm
The Naive Bayesian algorithm is a classification algorithm based on Bayesian theorem and the assumption of independence of feature conditions. Bayes' theorem is a theory of probability that describes the probability of another event occurring given certain conditions.
The Naive Bayesian algorithm assumes that all features are independent of each other, that is, each feature variable has nothing to do with other feature variables. Based on this assumption, the Naive Bayes algorithm can predict the label category of new data by observing the already labeled data set.
Naive Bayes algorithms are commonly used in applications such as text classification, spam filtering, and sentiment analysis.
The following is a sample code to implement the Naive Bayes algorithm model using Python:
import numpy as np
class NaiveBayes:
def __init__(self, n_classes):
self.n_classes = n_classes
self.priors = None
self.posteriors = None
def fit(self, X, y):
n_samples, n_features = X.shape
self.priors = np.zeros(self.n_classes)
self.posteriors = np.zeros((self.n_classes, n_features))
for c in range(self.n_classes):
X_c = X[y == c]
self.priors[c] = len(X_c) / n_samples
self.posteriors[c] = (X_c.sum(axis=0) + 1) / (len(X_c) + 1)
def predict(self, X):
y_pred = []
for x in X:
posteriors = []
for c in range(self.n_classes):
prior = np.log(self.priors[c])
likelihood = np.sum(np.log(self.posteriors[c]) * x)
posterior = prior + likelihood
posteriors.append(posterior)
y_pred.append(np.argmax(posteriors))
return y_pred
This implementation uses Laplace smoothing to avoid zero probability problems, and converts probabilities to logarithmic form to avoid numerical underflow problems. The fit method is used to train the Naive Bayesian model, while the predict method is used to classify new samples.
3.2. Decision tree
Decision tree is a classification and regression model based on tree structure, which is often used in the field of data mining and machine learning. It recursively splits the data set and continuously selects features until a recursive decision tree is finally obtained.
The node of the decision tree represents a feature in the data set, the edge represents the value of this feature, and the leaf node represents the classification result or regression result.
In the classification problem, the decision tree divides a sample from the root node to a specific leaf node, and the category of the leaf node is the category of the sample;
In the regression problem, the decision tree divides a sample from the root node to a specific leaf node, and the value of the leaf node is the predicted value of the sample.
Decision tree has the advantages of good interpretability, easy to understand and use, and is widely used in practical applications.
4. Neural Network
A neural network is a computer program that simulates the way the nervous system of the human brain works. It is composed of a large number of artificial neurons (simulated biological neurons) through a certain connection method. Through learning and training, it can identify, classify, simulate and predict various things. It has good adaptability and nonlinear mapping capabilities. It is widely used in artificial intelligence, image recognition, natural language processing, speech recognition and other fields.
Neural networks include feedforward neural networks, recurrent neural networks and other structures, among which feedforward neural networks are the most common.
Sample code for neural network to implement logic and operation
The neural network realizes logic and operation.
The logical AND operation is an operation in which the result is 1 when both binary numbers are 1, and 0 otherwise.
Neural networks can implement logic and operations by learning the mapping between the input and output of logic and operations.
The following is a sample code for a simple neural network to implement logical AND operations:
import numpy as np# 输入数据和标签
x = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[0], [0], [0], [1]])
# define the neural network
# 定义神经网络
class NeuralNetwork:
def __init__(self):
np.random.seed(1)
self.weights = 2 * np.random.random((2, 1)) - 1
def sigmoid(self, x):
return 1 / (1 + np.exp(-x))
def sigmoid_derivative(self, x):
return x * (1 - x)
def train(self, x, y, iterations):
for i in range(iterations):
output = self.predict(x)
error = y - output
adjustment = np.dot(x.T, error * self.sigmoid_derivative(output))
self.weights += adjustment
def predict(self, x):
return self.sigmoid(np.dot(x, self.weights))
# train the neural network
# 训练神经网络
neural_network = NeuralNetwork()
neural_network.train(x, y, 10000)
# predict
# 预测
print(neural_network.predict(np.array([0, 0])))
print(neural_network.predict(np.array([0, 1])))
print(neural_network.predict(np.array([1, 0])))
print(neural_network.predict(np.array([1, 1])))The output is:
[0.5]
[0.2689864]
[0.2689864]
[0.11738518]
Since the neural network is a probability-based model, the output results are not completely accurate,
But it can be seen that when the input is (0, 0), (0, 1) and (1, 0), the output is close to 0,
When the input is (1, 1), the output is close to 1, which is consistent with the result of the logical AND operation.
Recommended reading:








































|
|
|
|
| Tomcat11, tomcat10 installation configuration (Windows environment) (detailed graphics) |
Tomcat startup flashback problem solving set (eight categories in detail) |
|


