The correct solution to the RuntimeError: CUDA error: device-side assert triggered exception has been solved, and the personal test is effective! ! !

Article directory
Error report
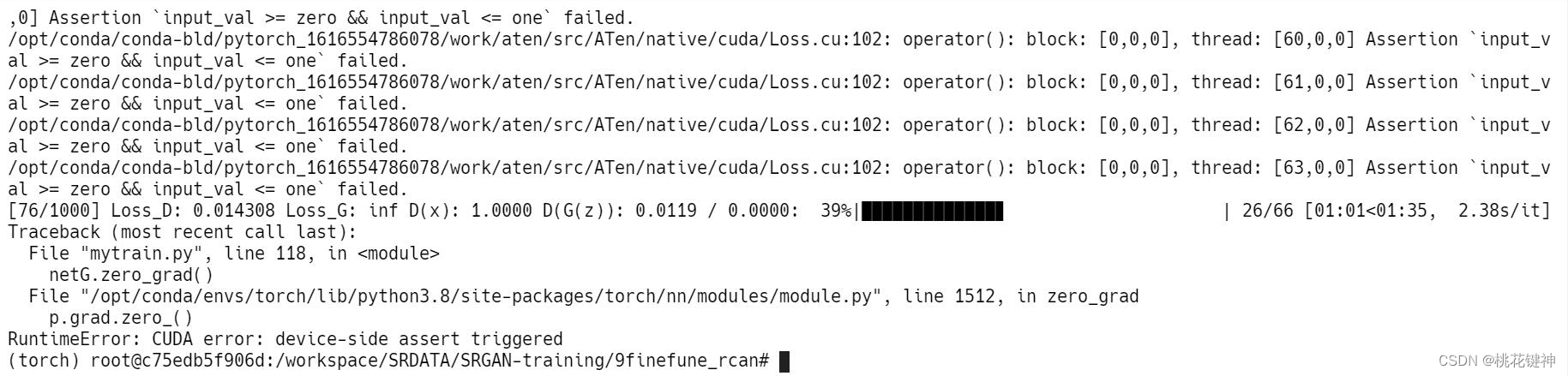
A friend in the fan group reported an error when he typed the code (at that time, his heart was cold for a moment, and he came to me for help, and then helped him solve it smoothly. By the way, I hope it can help more people encounter this bug. Friends who will not solve it), the error message is as follows:

First of all, the text of the problem I reported is: RuntimeError: CUDA error: device-side assert triggered and
Assertion input_val >= zero && input_val <= one failed
Put these two texts in front for search engines to retrieve. Let me talk about my solution below, because I didn't take screenshots step by step during the problem solving process, so some steps can only be described in words.
RCAN is a deep residual network in the field of super-resolution restoration, but its code is very old, based on the framework of EDSR and Pytorch<1.2. So I transplanted its model to my own framework, but suddenly reported the above error during the training process.
Moreover, this error report did not occur at the beginning of network training, but a sudden error report after training. This puzzled me a lot, and the thinking process is as follows:
First of all, according to the text description of the error, it is in /src/ATen/native/cuda/Loss.cu:102 of the source code, open the source code of pytorch on github, and find this part: It turns
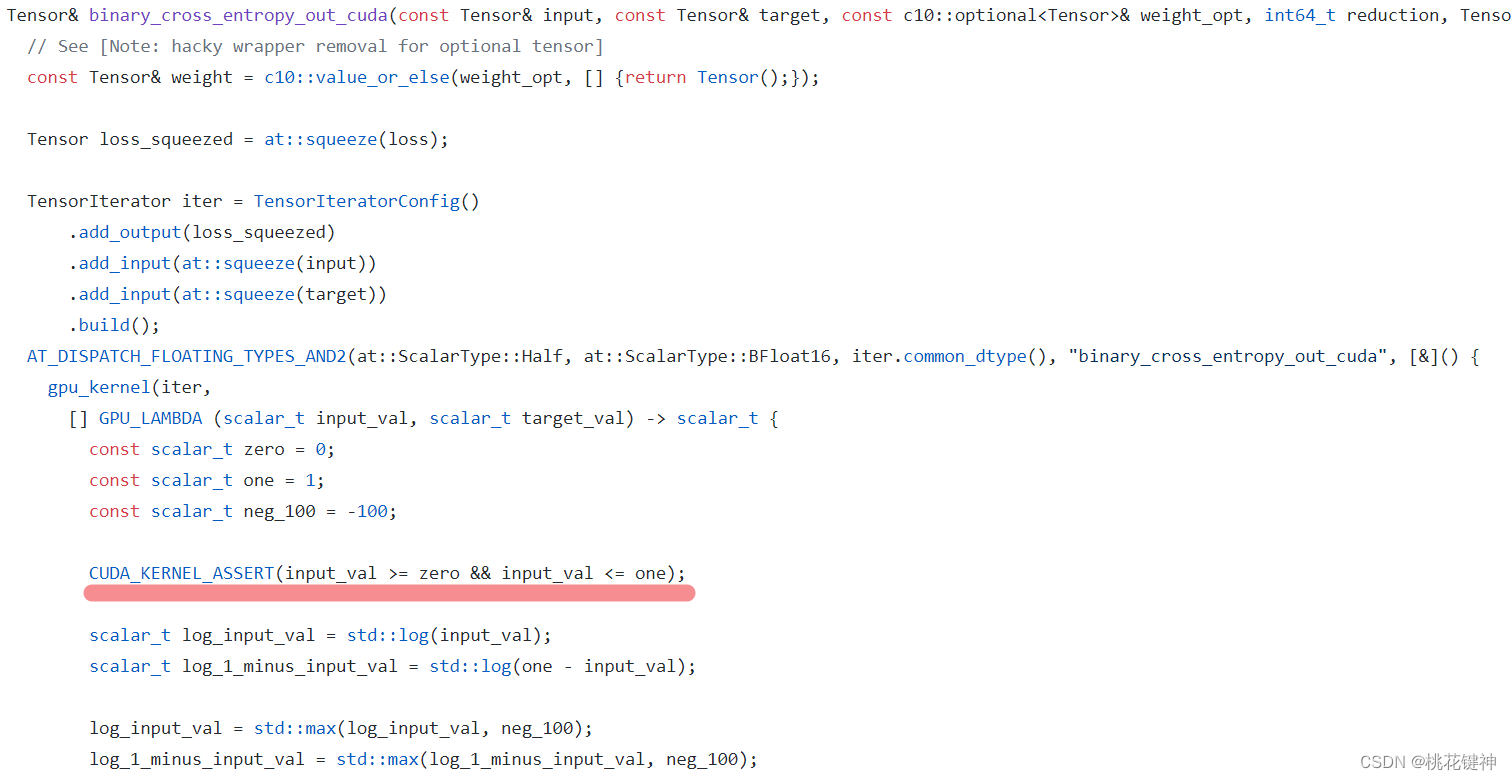
out that this assertion originally occurred in binary_cross_entropy_out_cuda( ), that is, an error was reported when using nn.BCELoss.
Looking back at my source code, I let the output and target perform a BCELoss. However, in my model (denoted as modelB), the last layer is sigmoid, that is to say, my network guarantees that the output value must be between [0, 1]! ! So, why do you say that my value is not in this range? Is Pytorch sick?
Well, there is no other way, I added a print statement in the source code to print the output of the model to see if it really outputs values in [0, 1] as expected. I was startled at first glance. At the beginning, the output value was very normal, and they were all between [0, 1]. But at a certain time node, the output of the network suddenly becomes a full screen of nan, which is an infinite value! This is strange, because as we all know, the operations in the convolutional neural network are "limited", and when the input is limited, the output must be limited. Wait, when the input is limited. I take it for granted that this input is finite, but is the input value really that way? (The input here is the output of modelA)
With this idea, I printed the output of modelA (actually RCAN), and found that, like modelB, at a certain time node, the output value suddenly became nan.
The problem is found, but it seems to be deadlocked again. RCAN is also a convolutional neural network, and there is no log in it that will generate an infinite number of operations, so where is the problem?
In a flash of inspiration, I suddenly thought that in the network structure of RCAN, there seem to be some network layers that do not need to be trained and optimized. But in my source code, the optimizer code is like this:
optimizerG = optim.Adam(netG.parameters())
Solution
The solution is as follows
That is, all the parameters in the RCAN network are handed over to OptimizerG for hooking. Then, is it possible that the optimizer optimizes some fixed network parameters that should not be optimized, resulting in network abnormalities. Look at the source code of RCAN and find clues. There is such a paragraph in the source code:
def make_optimizer(args, my_model):
trainable = filter(lambda x: x.requires_grad, my_model.parameters())
if args.optimizer == 'SGD':
optimizer_function = optim.SGD
kwargs = {
'momentum': args.momentum}
elif args.optimizer == 'ADAM':
optimizer_function = optim.Adam
kwargs = {
'betas': (args.beta1, args.beta2),
'eps': args.epsilon
}
elif args.optimizer == 'RMSprop':
optimizer_function = optim.RMSprop
kwargs = {
'eps': args.epsilon}
kwargs['lr'] = args.lr
kwargs['weight_decay'] = args.weight_decay
return optimizer_function(trainable, **kwargs)
Damn it, the source code of RCAN seems to filter the parameters that need to be trained and the parameters that do not need to be trained in the first line here. And my code doesn't do it. Then, I'll just use the original author's code and give it a try: 
Well, the training effect is very unsatisfactory. But the same error has never been reported again. It seems that the problem has been solved! ! !
Welfare
6 technical books will be sent home every week
due to the limited time and energy of the blogger, and there are too many private messages every day, so it is impossible for every fan to reply in time. You
can enter the community skirt or add the blogger’s WeChat
and click the link below
http:/ /t.csdn.cn/6kInJ