Let chatGPT use Tensor flow Keras to assemble Bert, GPT, Transformer
This article mainly shows the relationship and differences between the neural network structures of Transformer, Bert, and GPT. There are a lot of information on the Internet, but not many clearly show this relationship. This article is organized as a supplementary information, while using chatGPT, let it use Tensor flow Keras to assemble the corresponding mini-code to assist understanding.
From this assembly, it can be seen intuitively that:
- Transformer: Encoder-Decoder modules are used
- Bert: Only Transformer's Encoder is used for module assembly
- GPT: Only Transformer's Decoder is used for module assembly
implement Transformer Model by Tensor flow Keras
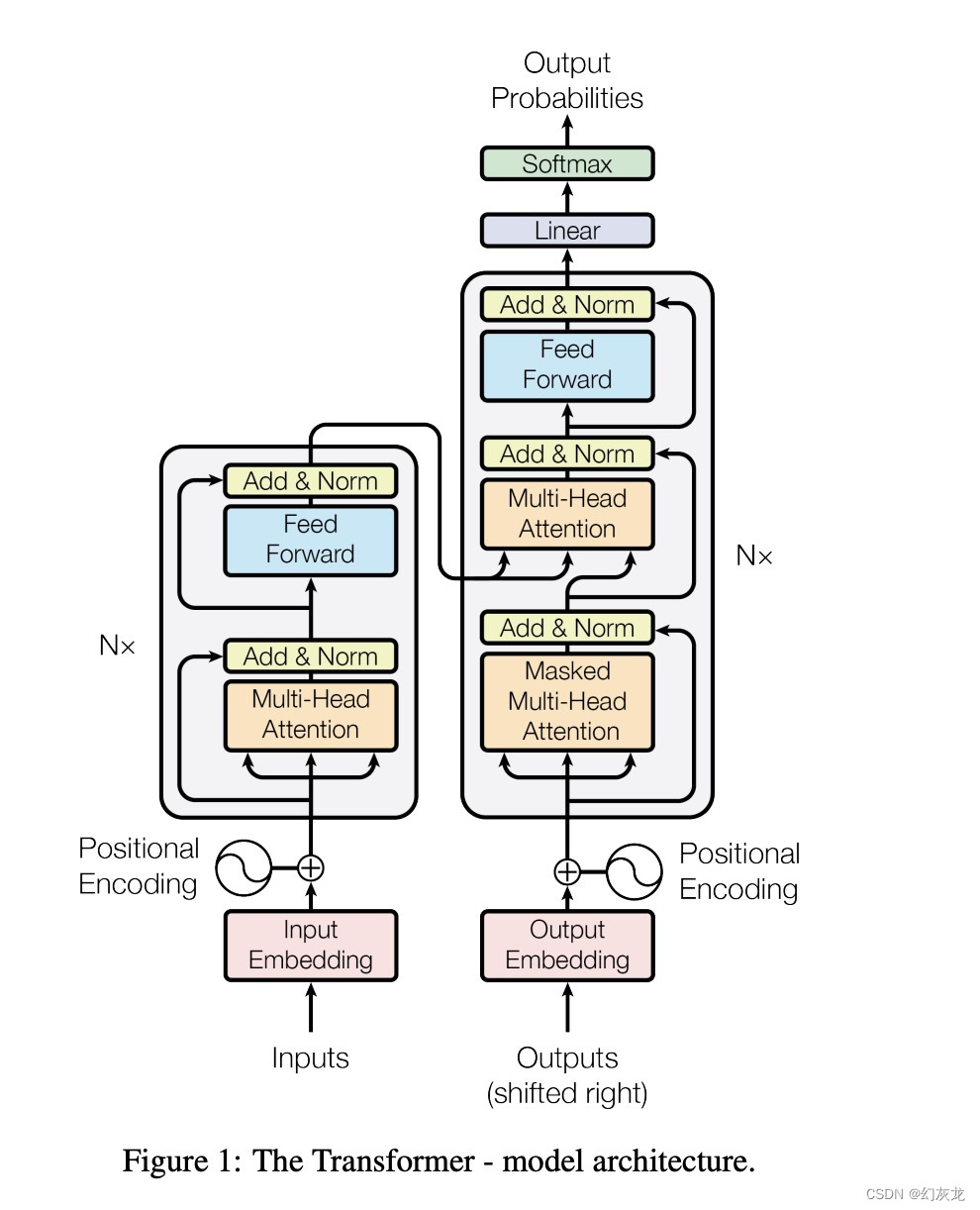
There are a lot of things on the Internet that explain what each layer of Transformer does. This can be disassembled in a separate article for my understanding. This document assumes the reader already understands at this point.
import tensorflow as tf
class Transformer(tf.keras.Model):
def __init__(self, num_layers, d_model, num_heads, d_ff, input_vocab_size, target_vocab_size, dropout_rate=0.1):
super(Transformer, self).__init__()
self.encoder = Encoder(num_layers, d_model, num_heads, d_ff, input_vocab_size, dropout_rate)
self.decoder = Decoder(num_layers, d_model, num_heads, d_ff, target_vocab_size, dropout_rate)
self.final_layer = tf.keras.layers.Dense(target_vocab_size)
def call(self, inputs, targets, enc_padding_mask, look_ahead_mask, dec_padding_mask):
enc_output = self.encoder(inputs, enc_padding_mask)
dec_output = self.decoder(targets, enc_output, look_ahead_mask, dec_padding_mask)
final_output = self.final_layer(dec_output)
return final_output
class Encoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, d_ff, vocab_size, dropout_rate=0.1):
super(Encoder, self).__init__()
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(vocab_size, d_model)
self.positional_encoding = PositionalEncoding(vocab_size, d_model)
self.encoder_layers = [EncoderLayer(d_model, num_heads, d_ff, dropout_rate)
for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(dropout_rate)
def call(self, inputs, padding_mask):
embedded_input = self.embedding(inputs)
positional_encoded_input = self.positional_encoding(embedded_input)
encoder_output = self.dropout(positional_encoded_input)
for i in range(self.num_layers):
encoder_output = self.encoder_layers[i](encoder_output, padding_mask)
return encoder_output
class Decoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, d_ff, vocab_size, dropout_rate=0.1):
super(Decoder, self).__init__()
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(vocab_size, d_model)
self.positional_encoding = PositionalEncoding(vocab_size, d_model)
self.decoder_layers = [DecoderLayer(d_model, num_heads, d_ff, dropout_rate)
for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(dropout_rate)
def call(self, inputs, encoder_output, look_ahead_mask, padding_mask):
embedded_input = self.embedding(inputs)
positional_encoded_input = self.positional_encoding(embedded_input)
decoder_output = self.dropout(positional_encoded_input)
for i in range(self.num_layers):
decoder_output = self.decoder_layers[i](decoder_output, encoder_output,
look_ahead_mask, padding_mask)
return decoder_output
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, d_ff, dropout_rate=0.1):
super(EncoderLayer, self).__init__()
self.multi_head_attention = MultiHeadAttention(d_model, num_heads)
self.ffn = FeedForwardNetwork(d_model, d_ff)
self.layer_norm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layer_norm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(dropout_rate)
self.dropout2 = tf.keras.layers.Dropout(dropout_rate)
def call(self, inputs, padding_mask):
attention_output = self.multi_head_attention(inputs, inputs, inputs, padding_mask)
attention_output = self.dropout1(attention_output)
attention_output = self.layer_norm1(inputs + attention_output)
ffn_output = self.ffn(attention_output)
ffn_output = self.dropout2(ffn_output)
encoder_output = self.layer_norm2(attention_output + ffn_output)
return encoder_output
class DecoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, d_ff, dropout_rate=0.1):
super(DecoderLayer, self).__init__()
self.multi_head_attention1 = MultiHeadAttention(d_model, num_heads)
self.multi_head_attention2 = MultiHeadAttention(d_model, num_heads)
self.ffn = FeedForwardNetwork(d_model, d_ff)
self.layer_norm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layer_norm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layer_norm3 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(dropout_rate)
self.dropout2 = tf.keras.layers.Dropout(dropout_rate)
self.dropout3 = tf.keras.layers.Dropout(dropout_rate)
def call(self, inputs, encoder_output, look_ahead_mask, padding_mask):
attention1_output = self.multi_head_attention1(inputs, inputs, inputs, look_ahead_mask)
attention1_output = self.dropout1(attention1_output)
attention1_output = self.layer_norm1(inputs + attention1_output)
attention2_output = self.multi_head_attention2(attention1_output, encoder_output, encoder_output, padding_mask)
attention2_output = self.dropout2(attention2_output)
attention2_output = self.layer_norm2(attention1_output + attention2_output)
ffn_output = self.ffn(attention2_output)
ffn_output = self.dropout3(ffn_output)
decoder_output = self.layer_norm3(attention2_output + ffn_output)
return decoder_output
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
self.depth = d_model // num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, query, key, value, mask):
batch_size = tf.shape(query)[0]
q = self.wq(query)
k = self.wk(key)
v = self.wv(value)
q = self.split_heads(q, batch_size)
k = self.split_heads(k, batch_size)
v = self.split_heads(v, batch_size)
scaled_attention, attention_weights = scaled_dot_product_attention(q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3])
concat_attention = tf.reshape(scaled_attention, (batch_size, -1, self.d_model))
output = self.dense(concat_attention)
return output, attention
implement Bert model by Tensor flow Keras
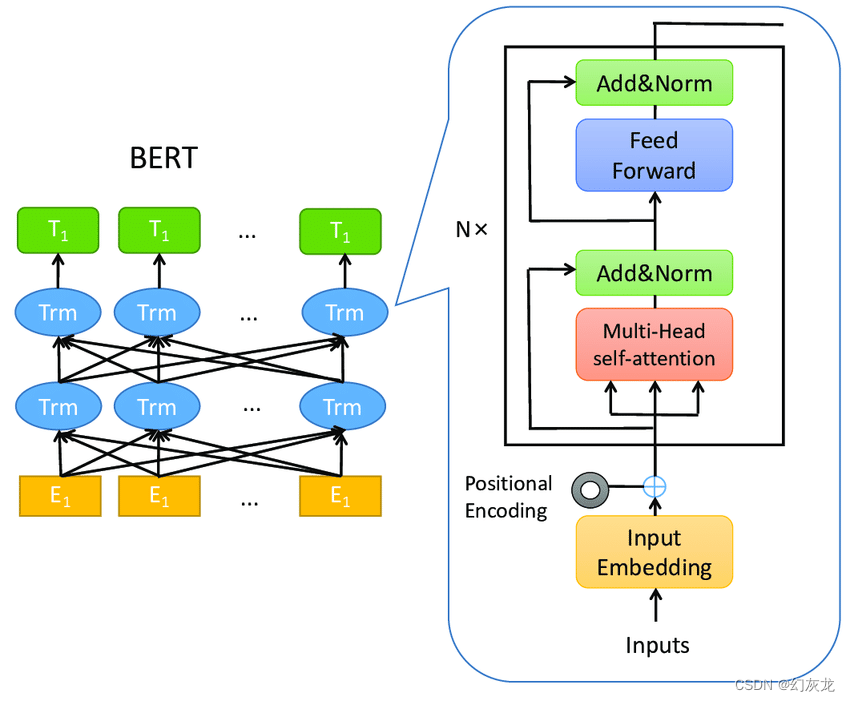
Among them, each Trm on the left represents, and the enlarged picture on the right is the Encoder part structure of the original Transformer. At the same time, it can be seen that Bert is on the left and assembles Transformer in two directions. Bert's training tasks include MLM (Masked Language Model) and NSP (Next Sentence Prediction). Bert's training is unsupervised, because MLM actually blocks some tokens of the corpus, so the output needs to know what the answer is ( annotation information) is actually included in the corpus. From this point of view, it is actually supervised.
import tensorflow as tf
class BERT(tf.keras.Model):
def __init__(self, vocab_size, hidden_size, num_attention_heads, num_transformer_layers, intermediate_size):
super(BERT, self).__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, hidden_size)
self.transformer_layers = [TransformerLayer(hidden_size, num_attention_heads, intermediate_size)
for _ in range(num_transformer_layers)]
self.dropout = tf.keras.layers.Dropout(0.1)
def call(self, inputs, attention_mask):
embedded_input = self.embedding(inputs)
hidden_states = embedded_input
for transformer_layer in self.transformer_layers:
hidden_states = transformer_layer(hidden_states, attention_mask)
hidden_states = self.dropout(hidden_states)
return hidden_states
class TransformerLayer(tf.keras.layers.Layer):
def __init__(self, hidden_size, num_attention_heads, intermediate_size):
super(TransformerLayer, self).__init__()
self.attention = MultiHeadAttention(hidden_size, num_attention_heads)
self.feed_forward = FeedForward(hidden_size, intermediate_size)
self.layer_norm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layer_norm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(0.1)
self.dropout2 = tf.keras.layers.Dropout(0.1)
def call(self, inputs, attention_mask):
attention_output = self.attention(inputs, inputs, inputs, attention_mask)
attention_output = self.dropout1(attention_output)
attention_output = self.layer_norm1(inputs + attention_output)
feed_forward_output = self.feed_forward(attention_output)
feed_forward_output = self.dropout2(feed_forward_output)
layer_output = self.layer_norm2(attention_output + feed_forward_output)
return layer_output
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, hidden_size, num_attention_heads):
super(MultiHeadAttention, self).__init__()
self.num_attention_heads = num_attention_heads
self.attention_head_size = hidden_size // num_attention_heads
self.query = tf.keras.layers.Dense(hidden_size)
self.key = tf.keras.layers.Dense(hidden_size)
self.value = tf.keras.layers.Dense(hidden_size)
self.dense = tf.keras.layers.Dense(hidden_size)
def call(self, query, key, value, attention_mask):
query = self.query(query)
key = self.key(key)
value = self.value(value)
query = self._split_heads(query)
key = self._split_heads(key)
value = self._split_heads(value)
attention_scores = tf.matmul(query, key, transpose_b=True)
attention_scores /= tf.math.sqrt(tf.cast(self.attention_head_size, attention_scores.dtype))
if attention_mask is not None:
attention_scores += attention_mask
attention_probs = tf.nn.softmax(attention_scores, axis=-1)
context_layer = tf.matmul(attention_probs, value)
context_layer = tf.transpose(context_layer, perm=[0, 2, 1, 3])
context_layer = tf.reshape(context_layer, (tf.shape(context_layer)[0], -1, hidden_size))
attention_output = self.dense(context_layer)
return attention_output
def _split_heads(self, x):
batch_size = tf.shape(x)[0]
length = tf.shape(x)[1]
x = tf.reshape(x, (batch_size, length, self.num_attention_heads,
implement GPT model by Tensor flow Keras
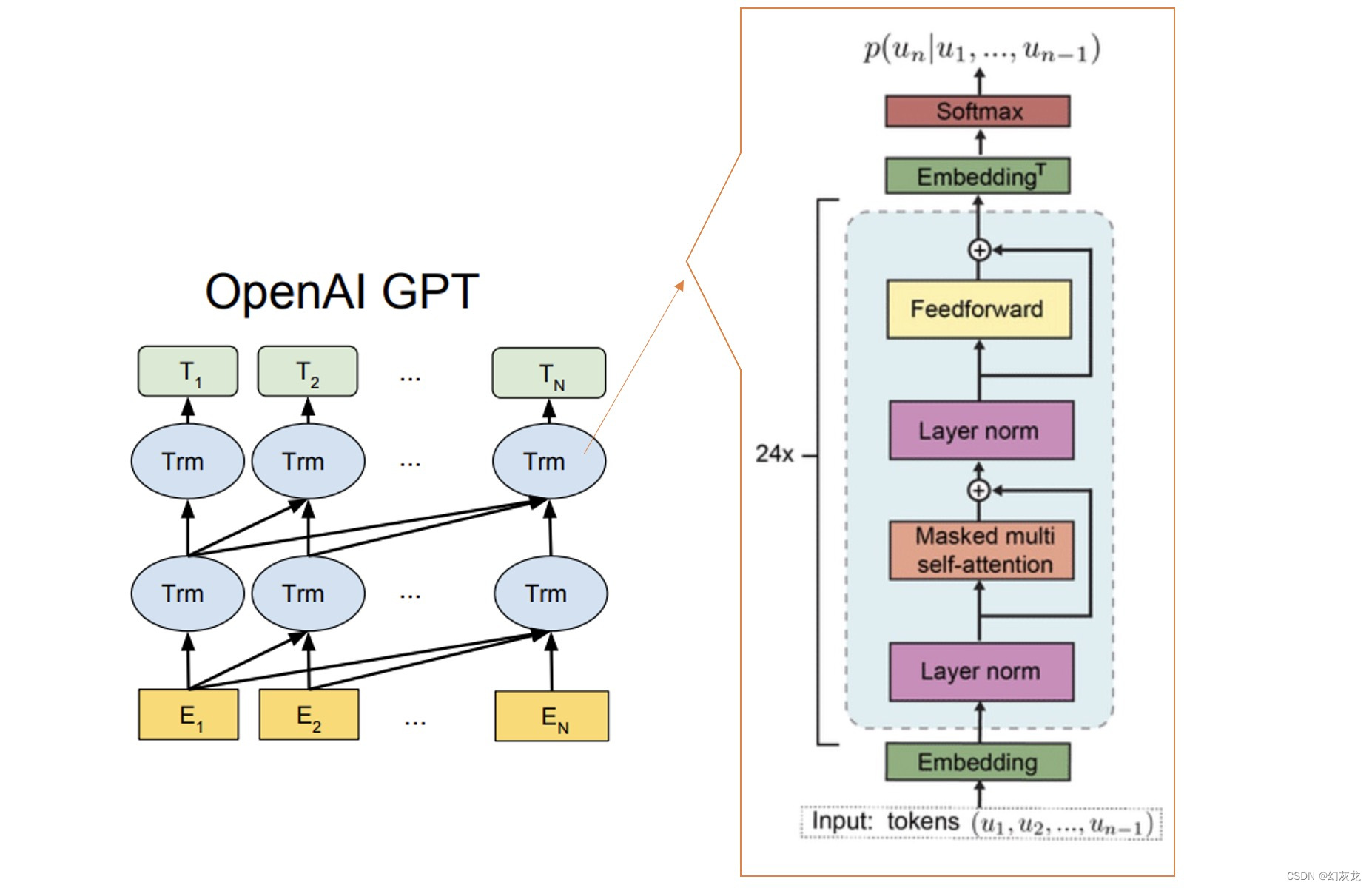
Among them, each Trm amplification on the left is the part on the right, which is the Decoder part in the original structure of Transformer. At the same time, it can be seen that GPT is on the left, and it is a one-way assembly of Transformer. The training task of GPT is to generate the next Token. GPT is unsupervised, because from the perspective of machine learning, the "label information" (the next Token) required to output data is already provided by the corpus. From this point of view, it is actually supervised.
import tensorflow as tf
class GPT(tf.keras.Model):
def __init__(self, vocab_size, hidden_size, num_layers, num_heads, intermediate_size, max_seq_length):
super(GPT, self).__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, hidden_size)
self.positional_encoding = PositionalEncoding(max_seq_length, hidden_size)
self.transformer_blocks = [TransformerBlock(hidden_size, num_heads, intermediate_size)
for _ in range(num_layers)]
self.final_layer_norm = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.final_dense = tf.keras.layers.Dense(vocab_size, activation='softmax')
def call(self, inputs):
embedded_input = self.embedding(inputs)
positional_encoded_input = self.positional_encoding(embedded_input)
hidden_states = positional_encoded_input
for transformer_block in self.transformer_blocks:
hidden_states = transformer_block(hidden_states)
final_output = self.final_layer_norm(hidden_states)
final_output = self.final_dense(final_output)
return final_output
class TransformerBlock(tf.keras.layers.Layer):
def __init__(self, hidden_size, num_heads, intermediate_size):
super(TransformerBlock, self).__init__()
self.attention = MultiHeadAttention(hidden_size, num_heads)
self.feed_forward = FeedForward(hidden_size, intermediate_size)
self.layer_norm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layer_norm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
def call(self, inputs):
attention_output = self.attention(inputs, inputs, inputs)
attention_output = self.layer_norm1(inputs + attention_output)
feed_forward_output = self.feed_forward(attention_output)
layer_output = self.layer_norm2(attention_output + feed_forward_output)
return layer_output
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, hidden_size, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.attention_head_size = hidden_size // num_heads
self.query = tf.keras.layers.Dense(hidden_size)
self.key = tf.keras.layers.Dense(hidden_size)
self.value = tf.keras.layers.Dense(hidden_size)
self.dense = tf.keras.layers.Dense(hidden_size)
def call(self, query, key, value):
query = self.query(query)
key = self.key(key)
value = self.value(value)
query = self._split_heads(query)
key = self._split_heads(key)
value = self._split_heads(value)
attention_scores = tf.matmul(query, key, transpose_b=True)
attention_scores /= tf.math.sqrt(tf.cast(self.attention_head_size, attention_scores.dtype))
attention_probs = tf.nn.softmax(attention_scores, axis=-1)
context_layer = tf.matmul(attention_probs, value)
context_layer = tf.transpose(context_layer, perm=[0, 2, 1, 3])
context_layer = tf.reshape(context_layer, (tf.shape(context_layer)[0], -1, hidden_size))
attention_output = self.dense(context_layer)
return attention_output
def _split_heads(self, x):
batch_size = tf.shape(x)[0]
length = tf.shape(x)[1]
x = tf.reshape(x, (batch_size, length, self.num_heads, self.attention_head_size))
return tf.transpose(x, perm=[0, 2, 1, 3])