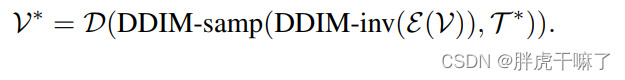Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
Abstract
This paper proposes a method to stand on the shoulders of giants - a text to image generation model that pretrains and performs well on a large-scale image dataset - adding a new structure and fine-tuning to train a set of one shot text to video generator. The advantage of this is that it uses the already very successful image diffusion generation model with various styles, and expands on it. At the same time, its training time is very short, which greatly reduces the training overhead. As a one shot method, tune a video also requires additional information, a text-video pair as a demo.
The author got the T2I (text to image) modeltwo observations:
(1) The T2I model can generate still images showing the effect of verb terms
(2) Multiple images simultaneously generated by the extended T2I model show good content consistency.
With these two observations as a basis, in factThe key to generating video is how to ensure continuous motion of consistent objects。
In order to go one step further and learn coherent movements, the author designed a one shot Tune-A-Video model. This model involves a custom spatiotemporal attention mechanism and an efficient one shot tuning strategy. In the inference phase, use the inversion process of DDIM (the sampling part of the conventional DDIM in the inverse diffusion process is deterministic: the standard deviation in the predicted Gaussian noise ~N(μ, σ) is set to 0, thereby eliminating the inverse diffusion process The randomness in DDIM inversion; on the contrary, the forward diffusion process of DDIM inversion is deterministic.) to provide structural guidance for the sampling process.
1. Introduction
In order to assign the results of T2I generative models in the T2V domain, many models [30, 35, 6, 42, 40] also try to extend the T2I generative models in the spatial domain to the spatio-temporal domain. They usually adopt the standard training paradigm on large-scale text-video datasets, which works well, but the computational overhead is too large and time-consuming.
The idea of this model: After completing the pre-trained T2I model on a large-scale text-image dataset and having a lot of knowledge of the concept of open domain, then simply give it a video sample, can it infer other videos by itself?
One-Shot Video Tuning uses only one text-video pair to train a T2V generator that captures basic motion information from an input video and then generates novel videos based on edited prompts.

As mentioned in the abstract above, the key to generating video is how to ensure continuous motion of consistent objects. Below, the authors make the following observations from sota's T2I diffusion model and motivate our model accordingly.
(1) Regarding actions: The T2I model is able to generate images well from text including verb items. This shows that the T2I model can take into account the verb terms in the text through cross-modal attention in static action generation.
(2) Consistent objects: Simply expand the spatial self-attention in the T2I model to change from generating one image to generating multiple images, which is enough to generate different frames with consistent content, as shown in Figure 2 No. 1 Rows are multiple images with different contents and backgrounds, while row 2 in Figure 2 is the same person and beach. However, the actions are still not continuous, which indicates that the self-attention layer in T2I only pays attention to the spatial similarity and not the location of the pixel.
The Tune A Video method is a simple expansion of the sota T2I model in the space-time dimension. In order to avoid the quadratic increase of the calculation amount, this solution is obviously not feasible for tasks with increasing number of frames. Also, with the original fine-tuning method, updating all the parameters may destroy the existing knowledge of the T2I model and hinder the generation of new concept videos. To solve this problem, the author uses a sparse spatiotemporal attention mechanism instead of full attention, using only the first and previous frames of the video. As for the fine-tuning strategy, only the projection matrix in the attention block is updated. The above operations only guarantee the consistency of the content in the video frame, but do not guarantee the continuity of the action.
Therefore, in the inference stage, the author seeks structure guidance from the input video through the inversion process of DDIM. The reverse latent vector obtained by this process is used as the initial noise, so as to generate temporally coherent and smooth motion video frames.
Author's contributions:
(1) A new class of model One-Shot Video Tuning is proposed for the T2V generation task, which removes the burden of model training on large-scale video datasets (2) This is the first T2V generation using
T2I The framework of the task
(3) uses efficient attention tuning and structural inversion to significantly improve the timing connection
3.2 Network Expansion
Let’s talk about the T2I model first, take the LDM model as an example, use U-Net, first use Kong’s down-sampling and then up-sampling, and keep skipping. U-Net consists of stacked 2d residual convolutions and transformer blocks. Each transformer block consists of a spatial self-attention layer, a cross-attention layer, and a feedforward network. The spatial self-attention layer uses pixel locations in the feature map to find similar relationships; cross-attention considers the relationship between pixels and conditional inputs.
z vi represents the vi frame of the video, and the spatial self-attention can be expressed in the following form
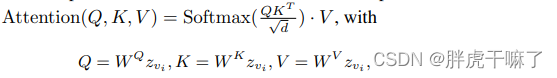
:
- Convert the two-dimensional LDM to the space-time domain:
(1) expand the 2d convolutional layer into a pseudo 3d convolutional layer, and 3x3 becomes 1x3x3;
(2) add timing self-attention to each transformer block layer (to complete time modeling);
(3) (to enhance temporal coherence,) convert the spatial self-attention mechanism to the spatiotemporal self-attention mechanism. The method of conversion is not to use full attention or causal attention, which can also capture spatiotemporal consistency. But apparently it doesn't apply due to overhead issues mentioned in the introduction. This article uses the causal attention of the coefficient, which changes the calculation amount from O((mN) 2 ) to O(2mN 2 ), where m is the number of frames, and N is the number of squences in each frame. It should be noted that in this self-attention mechanism, the vector used to calculate the query is zvi, and the vector used to calculate the key and value is the concatenation of v1 and vi-1.
4.4 Fine-tuning and inference
Model fine-tuning
For temporal modeling capability, the network is fine-tuned using the input video.
Since the spatio-temporal attention mechanism models its temporal consistency by querying relevant locations on previous frames. Therefore, W K and W V in the ST-Attn layers are fixed , and only the projection matrix W Q is updated .
For the newly added temporal self-attention layer, all parameters are updated, because the parameters of the newly added layer do not contain priors.
For cross-attention Cross-Attn, the correspondence between text-video is improved by updating the query projection matrix of Query.
Such fine-tuning saves computational overhead compared to full adjustment, and also helps to maintain the original properties obtained by the original T2I pre-training. All modules that need to update parameters are highlighted in the figure below.
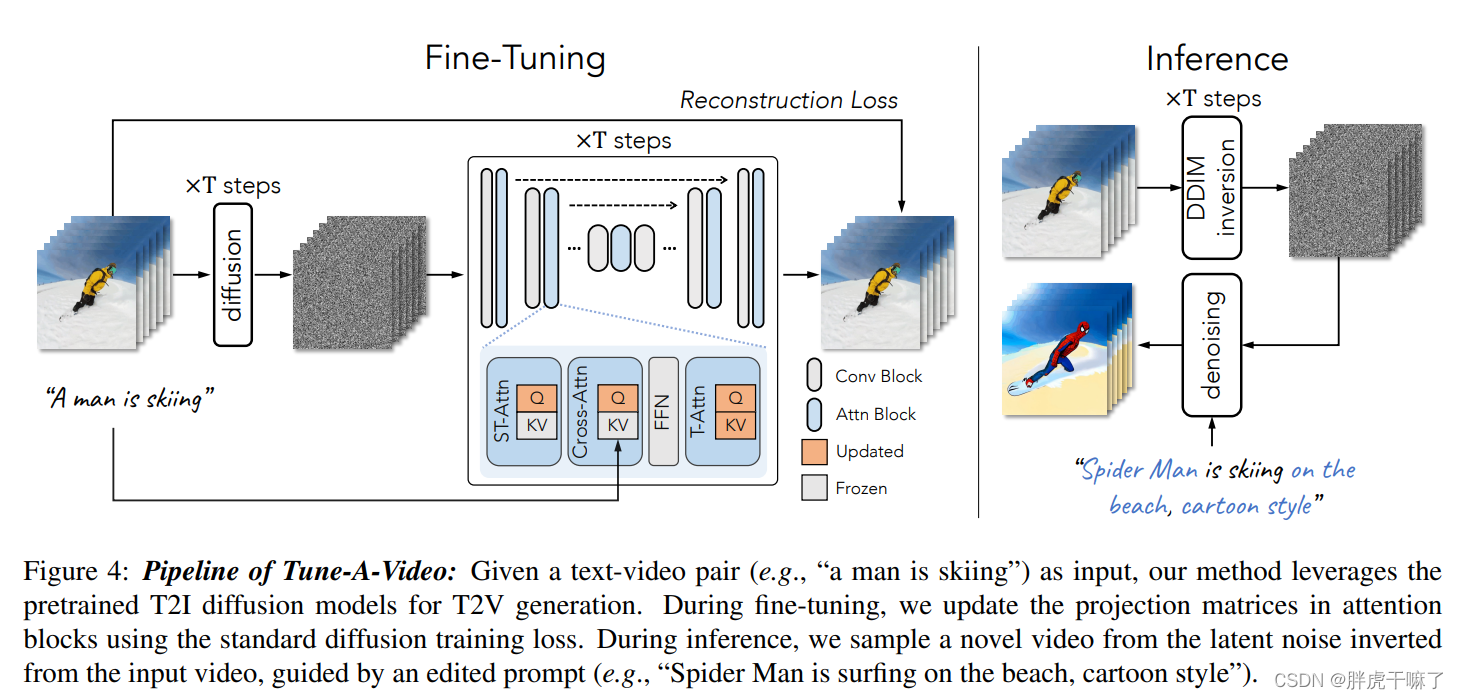
Get structural guidance through DDIM's inversion
To better ensure pixel movement between different frames, during the inference stage, our model introduces structural guidance from the original video. Specifically, through the inversion process of DDIM, latent vector noise can be extracted from the original video without text conditions. This noise serves as the starting point of the DDIM sampling process, and is guided by the edited prompt T* to enter the DDIM sampling process. The output video can be expressed as follows