the problem we are facing
The main scene of the initial business is the group chat message in the live broadcast room and a small part of the single chat message. Since it is an educational scenario, the business is divided into classes when dividing chat rooms. It is assumed that the number of people in each chat room is 500.
Problem 1: User Maintenance
There is a big difference in user maintenance between group chats in live broadcast scenarios and common group chats such as WeChat. The group user relationship of WeChat is relatively fixed. It is a relatively infrequent operation for users to enter and exit the group, and the user set is relatively fixed. The users in the live broadcast room come in and out very frequently, and the live broadcast room is time-sensitive. The actual peak value of entering and leaving the live broadcast room QPSwill not exceed 10,000, which Rediscan solve the problem of storage and expiration of the chat room user list.
Question 2: Message Forwarding
When all users in a 500-person chat room send messages at the same time, the message forwarding QPSis 500*500=2.5w. From the perspective of the live broadcast client:
Real- time : If the message service performs peak-elimination processing, the accumulation of peak messages will increase the message delay, and some signaling messages are time-sensitive, and too much delay will affect the user experience and real-time interaction.
User experience : The terminal displays various user chat and signaling messages. Generally, there will not be more than 10-20 messages per screen; if more than 20 messages are sent per second, there will be a phenomenon of continuous screen swiping; a large number of messages will also be sent to the terminal bring about a sustained high load.
So we define different priorities for messages. High-priority messages are forwarded first and guaranteed not to be discarded; low-priority messages are forwarded after a certain discarding strategy.
Question Three: Historical News
In terms of business, it is necessary to generate replay videos and obtain historical signaling, interactive chat and other information. It is required to be able to quickly write historical messages to ensure the timeliness of message forwarding.
The storage of messages mainly includes two categories: write diffusion and read diffusion. We adopt the method of read diffusion, which can reduce the storage space and the time for saving messages. Considering that the priority of playback is not high, we chose to choose storage components Pika. PikaIt is the interface and Redissimilarity that can reduce learning and development costs. At the same time, because it adopts the method of appending, the writing performance can be Rediscompared with .
Question 4: Message Sequence
The requirements for the order of signaling messages need to ensure the order in which the same person sends messages, and the order in which users in the same chat room receive messages is the same.
Solving the order of messages can Kafkabe guaranteed by using queues such as , but there is Kafkaa certain delay. In order to reduce the delay, we use a consistent hashing strategy to handle message forwarding, which will be introduced in detail later.
Design goals
Create a stable and efficient message communication server.
- Provide high-reliability, high-stability, and high-performance long-term connection services;
- Support millions of long connections online at the same time;
- Support multi-cluster rapid deployment and expansion;
Stability and Scalability
Stability and scalability are very important parts of the overall architecture. The main strategy of message service is 动态配置communication 策略下发, which can effectively realize dynamic scheduling of multiple computer rooms, automatic fault transfer, and also has the ability of horizontal expansion.
- Configuration: Common configuration information obtained by each end before connecting to the server
SDK, such as core parameters such as retry strategy, timeout time, and business scheduling address - Scheduling: According to different business types and user information, request the scheduling address to obtain the connection address of the current service
- Connection: Initiate a connection to the target service cluster
- Failover: If there is a problem in the middle of the service and the connection is disconnected, the scheduling will be initiated again, and the back-end cluster will recalculate the available clusters and schedule users to available cluster nodes
- There are many possible reasons for disconnection, the common ones are as follows:
- The network is unstable, causing network packet loss and triggering heartbeat timeout
- An exception occurs on the client and server, and the connection is actively closed
- At the high availability level of configuration and scheduling interfaces, strategies such as multi-address polling, multiple retries, and
CDNstatic resource coverage are used to ensure that
You should be wondering, why not return the scheduling address together in the configuration service in the first step, and split it into two steps? This is actually considering that the message service supports multi-service concurrency, and the configuration service is SDKonly obtained once during initialization, and the obtained SDK core control parameters. Subsequent different services can dynamically obtain their own scheduling addresses at different times, which can effectively improve the isolation and stability of services, so that services do not affect each other.
safety
A series of measures have been taken in terms of security and anti-attack, the encryption of message content and the security authentication of accounts. The methods we currently use are:
AppIssued to each business partyAppKey, the signature will be verified during the scheduling process, so as to prevent unsafe traffic from getting the scheduling address, or at least need to break throughAppthe defense to get it- The access address obtained by the dispatcher will be legal
Token, and the serverAuthmodule will verifyTokenthe timeliness and legality, as well as the user's account system, so as to avoid speculation by criminals and increase the cost of cracking - The content encryption function can be dynamically enabled, and the user's independent symmetric encryption
AESkey will be obtained for content encrypted transmission - Data transfer usage
TLS/SSLtunnel encryption - Use a secure network environment, such as
IDCcomputer room protection, intelligent protection from cloud vendors, etc.
connection stability
In a real and complex network environment, there may be a very small number of users with poor network stability, packet loss, frequent disconnection, or complete failure to establish a connection. On the one hand, we will collect the client's network status logs to diagnose users; on the other hand, we will also accelerate the network for this last mile problem.
TCP Use the acceleration of cloud vendors Websocket to solve the connection problems of some edge users
Self-built edge nodes can be more finely controlled
Overseas network acceleration, docking with multiple cloud service providers
reliability and consistency
As the core guarantee of the message service, it will be mainly introduced in the architecture of the server and the client respectively. The main guarantee strategies are:
- The strict confirmation mechanism of the message ensures that the message sent by the client to the server will be placed on the disk as long as it is confirmed, so as to ensure that the uplink message is not lost, and the downlink message can be retried multiple times afterwards
- Client failure retransmission, sorting, timeout and other strategies mainly refer to
TCPthe idea of sliding window, which can return the confirmed sequence of messages to the business layer, and out of order messages need to wait for timeout according to the strategy - Server-side anti-duplicate submission and retransmission strategy
- Globally unique messages
IDand locally ordered sequence numbers to ensure uniqueness and order
Design of server message ID
The design of the message ID is of great significance to the reliability and consistency of the message. On the one hand, it is necessary to ensure that any message can be traced and queried to ensure the uniqueness of the message; on the other hand, it is necessary to ensure the order of the messages.
ID The only algorithm for message service generation is based on Twitter the snowflake algorithm Snowflake, and some fine-tuning is done to suit the service.
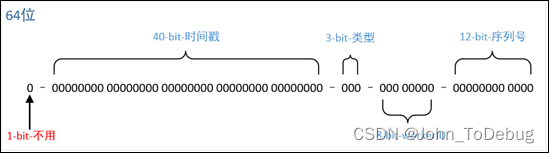
locally ordered sequence ID
In orderly sequence ID , we adopt some innovative designs to generate an independent serial number for each session, such as a group chat and a group chat. There is no mutual influence, which can greatly improve the serial number issuing performance. The main purpose of the sequence number is to ensure the local order of the message. So what has the server done to achieve reliability and consistency? First of all, we redesigned the message structure. The new message structure is as follows:
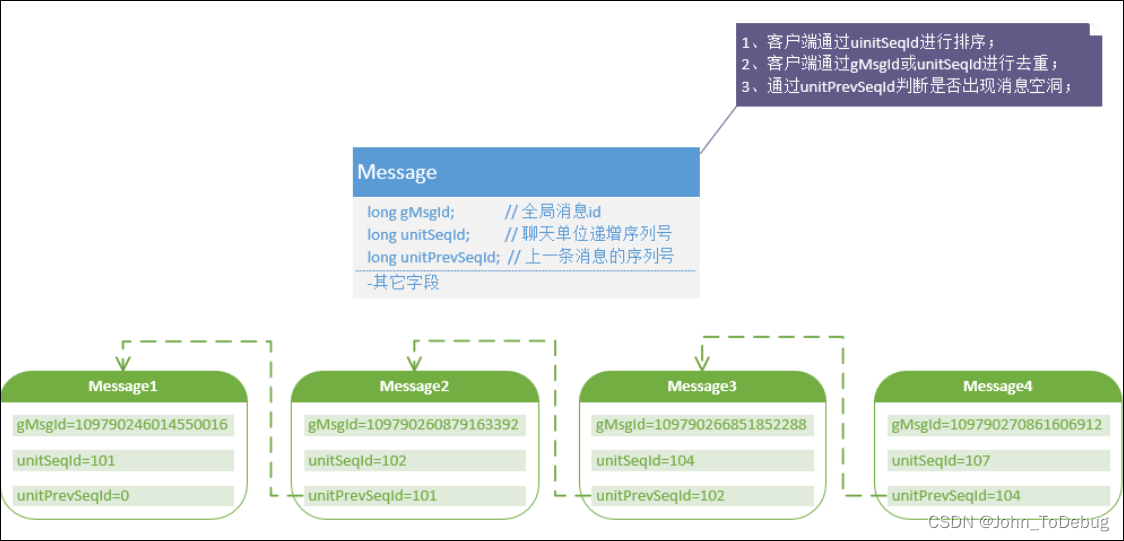
The new message structure is similar to a one-way linked list. The difference from the traditional one-way linked list is that the linked list is in reverse order, and each message has a previous message, SeqIdthis message SeqId, and a global message Id (used for message tracking). Messages SeqId are all aimed at chat objects, for example, chat rooms A and chat room B messages SeqIdare independent of each other.
The main consideration of using a preorder here ID is that the monotonically increasing sequence can be used to ensure the reliable consistency of messages. Note that continuous monotonically increasing is not required here. For example, our serial number in the figure is: 101, 102, 104, 107. We can use some serial number generation services that support massive amounts of high performance to support it, and use the strategy of pre-allocating number segments to improve performance. If you are interested, you can check some more mature solutions online. Of course, if the message size is not large, it can be used simply and rudely Redis to generate continuously increasing sequence numbers.
Message reliability and consistency guarantee
The reliability and consistency of messages are mainly reflected in the following aspects:
- The messages received on the terminal are not lost, not repeated, and not out of order
. With the above introductionSeqId, the client can sort the messages and judge the empty logic. The specific process is as follows:

- Users in the same room see messages in the same order
- The order sent by the user is the same as the order received by the user
For the latter two features, the server mainly processes messages from the same sender Hash in the same thread, and messages in the same room are also Hash processed in the same thread.
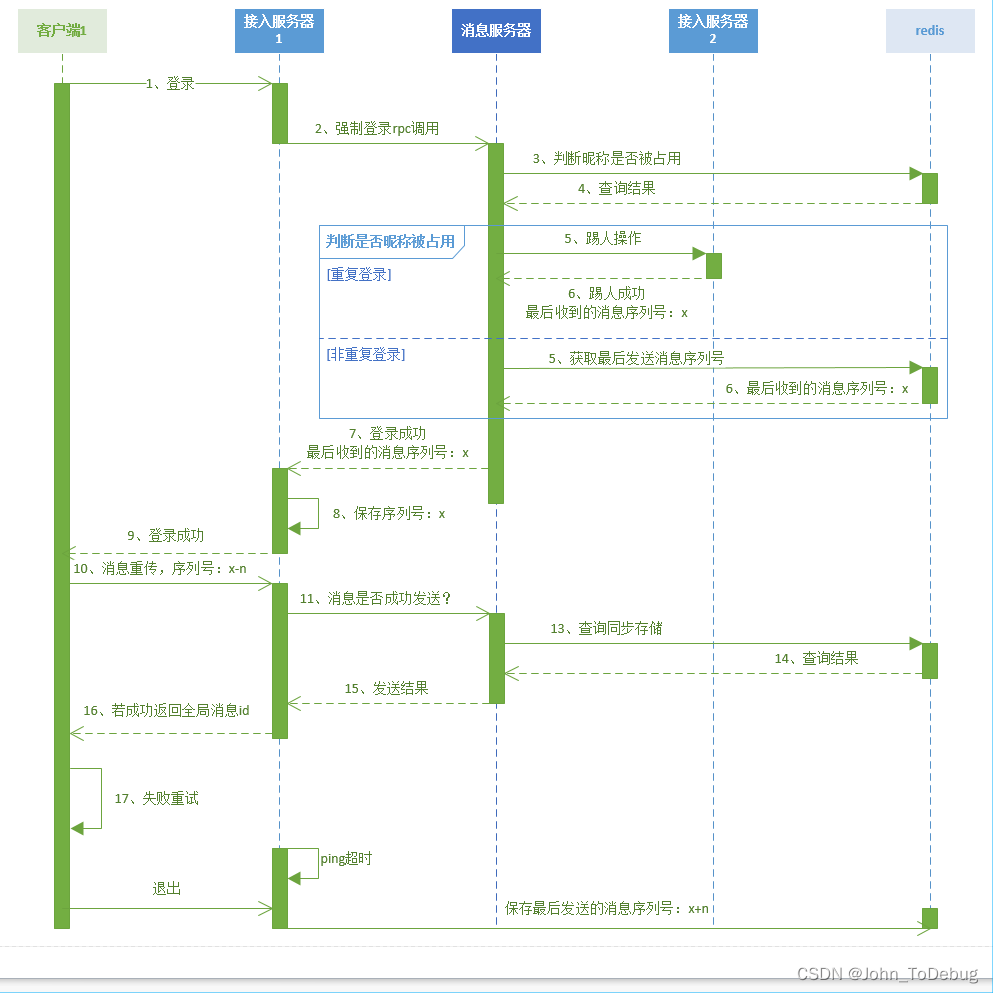
If the client fails to send the message, how can the message be guaranteed to be reliable?
In order to ensure that retransmissions are sent and messages are not repeated we do two things:
-
First of all, we also introduce a serial number. This serial number is at the user level. A user will only maintain one serial number during the online period. This serial number is monotonically increasing. When the client fails to send, it will try a certain number of retransmissions. If
Nall retransmissions fail, it will call back to notify the business layer. When the client resends, the sequence number remains unchanged, because the sequence number is monotonically increasing, so the server can distinguish whether it is a resent message by judging whether the sequence is repeated. -
Secondly, the server will cache the message sending results for a certain period of time. When it is judged that the message is retransmitted, it will query the last sending result and return the result directly to the client. The overall process is as follows:
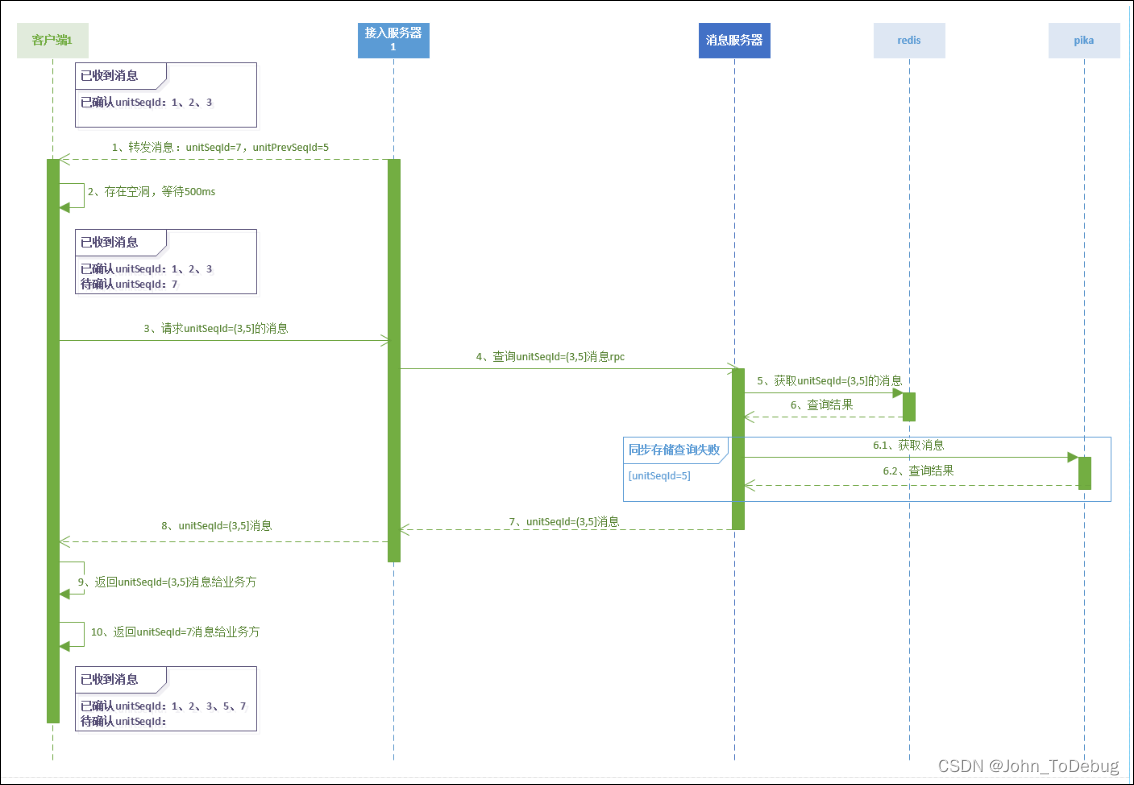
Users are spread all over the country, and the network conditions of each user are different, and the quality varies widely, so it TCP is normal for long-term connection drops. Because the server cannot normally forward the message to the user during the period from disconnection to reconnection, we use the process shown in the figure below to ensure that the user can receive the lost message after reconnection.