网络文学Using the Internet as a display platform and communication medium, using related Internet means to express literary works and network technology products containing some written works, has become a new literary phenomenon at present, and it is rising rapidly. Various online novels are also emerging in endlessly. Today We use selenium to crawl the novel data of Hongxiu Tianxiang website, and do simple data visualization analysis.

Established in 1999, Hongxiu Tianxiang is one of the world's leading digital copyright operators of women's literature. It updates 5,000 novels every day and provides more than 2.4 million registered users with novels, essays, essays, poems, lyrics, scripts, diaries and other genres. Its high-quality creation and reading services have an exclusive high ground in the field of female literature writing and publishing such as romance and workplace novels. (Baidu Encyclopedia)
Preliminary analysis of web pages
Open the web page as shown in the figure:
We need to capture all the novel data in the novel category: there are a total of 50 pages, 20 pieces of data per page, and a total of 1,000 pieces of data.
First use the requests third-party library to request data, as follows:
import requests
url = 'https://www.hongxiu.com/category/f1_f1_f1_f1_f1_f1_0_1' # 第一页url
headers = { 'xxx' : 'xxx'}
res = requests.get(url,headers=headers)
print(data.content.decode('utf-8'))
We found that the requested data did not have the novel data information on the first page. Obviously, the data is not in the source code of the web page. Then, by checking the network, we found such a request field:
_csrfToken: btXPBUerIB1DABWiVC7TspEYvekXtzMghhCMdN43
_: 1630664902028
This is js encryption, so in order to avoid analyzing the encryption method, it may be faster to use selenium to crawl data.
Selenium crawls data
01 Preliminary test
from selenium import webdriver
import time
url = 'https://y.qq.com/n/ryqq/songDetail/0006wgUu1hHP0N'
driver = webdriver.Chrome()
driver.get(url)
It turned out to work fine, no issues.
02 Novel Data
Specify the novel data information to be crawled
Image link, name, author, type, completed or not, popularity, profile
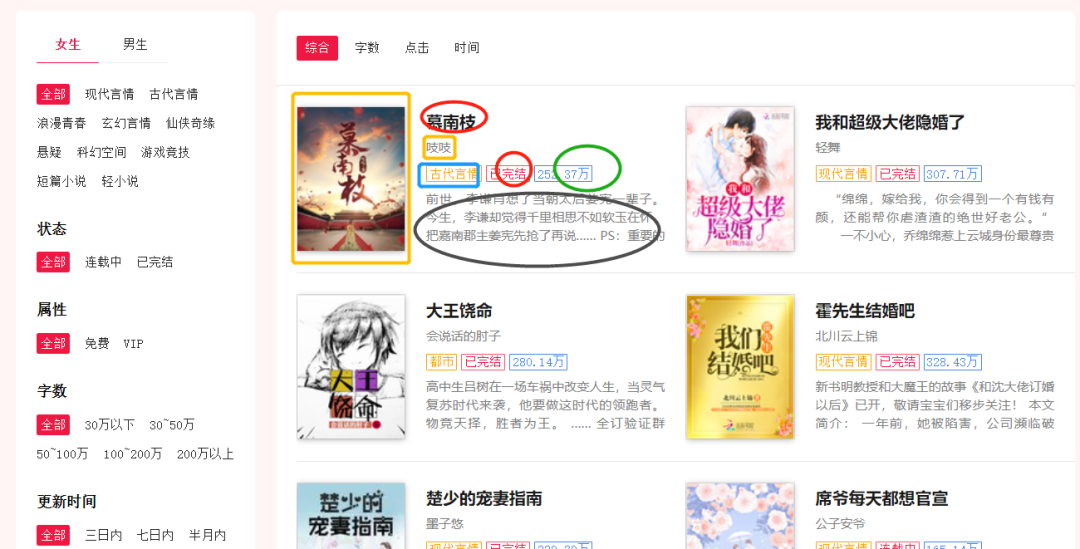
Then check whether it is dynamic data by clicking the button on the next page: it is found that it is not; the url rule is as follows:
'https://www.hongxiu.com/category/f1_f1_f1_f1_f1_f1_0_1' # 第一页的url
'https://www.hongxiu.com/category/f1_f1_f1_f1_f1_f1_0_2' # 第二页的url
03 Parsing data
Here is the code that parses the page data:
def get_data():
ficList = [] # 存储每一页的数据
items = driver.find_elements_by_xpath("//div[@class="right-book-list"]/ul/li")
for item in items:
dic = {}
imgLink = item.find_element_by_xpath("./div[1]/a/img").get_attribute('src')
# 1.图片链接 2.小说名称(name) 3.小说类型(types) ....
dic['img'] = imgLink
# ......
ficList.append(dic)
Here are a few points to note:
-
Pay attention to the writing of xpath statements, pay attention to details, and don't make mistakes;
-
For the introduction of novels, some introductions are relatively long and have line breaks. In order to facilitate storage, you need to use the replace method of the string to replace '\n' with an empty string
04 Page crawling
The following is the code for flipping and crawling data:
try:
time.sleep(3)
js = "window.scrollTo(0,100000)"
driver.execute_script(js)
while driver.find_element_by_xpath( "//div[@class='lbf-pagination']/ul/li[last()]/a"):
driver.find_element_by_xpath("//div[@class='lbf-pagination']/ul/li[last()]/a").click()
time.sleep(3)
getFiction()
print(count, "*" * 20)
count += 1
if count >= 50:
return None
except Exception as e:
print(e)
Code description:
-
Use
trystatements to perform exception handling to prevent any special page elements from being unable to match or other problems. -
The driver executes the js code, operates the scroll wheel, and slides to the bottom of the page.
js = "window.scrollTo(0,100000)" driver.execute_script(js) -
time.sleep(n)Because the analysis function (driver positioning) is added in the loop, it needs to wait for the data to be loaded completely. -
whileIn the loop statement,‘下一页’the button positioned to ensure that the data on the next page is crawled cyclically. -
Use
ifthe statement as the judgment condition, as the exit condition of the while loop, and then use return to exit the function, break will not work.
05 Data storage
titles = ['imgLink', 'name', 'author', 'types', 'pink','popu','intro']
with open('hx.csv',mode='w',encoding='utf-8',newline='') as f:
writer = csv.DictWriter(f, titles)
writer.writeheader()
writer.writerows(data)
print('写入成功')
06 Program running
The results are as follows, 1000 pieces of data displayed:

Some points to note when using selenium to crawl data:
① After clicking the next page, the data cannot be loaded completely in an instant. Once the data is not loaded completely, then using the find_Element_by_xpath statement of webdriver will not be able to locate the element on the dom document, and an error will be thrown:
selenium.StaleElementReferenceException:
stale element reference: element is not
attached to the page document
大概意思:The referenced element is obsolete and is no longer attached to the current page.
产生原因:Typically, this is due to a page refresh or jump.
解决方法:
1. Re-use the findElement or findElements method to locate elements.
2. Or just use webdriver.Chrome().refresh to refresh the webpage, and wait for a few seconds before refreshing, time.sleep(5).For the solution to this error, refer to the following blog:
https://www.cnblogs.com/qiu-hua/p/12603675.html
② When dynamically clicking the next page button, it is necessary to accurately locate the button on the next page. Secondly, a very important issue is that when selenium opens the browser page, the window needs to be maximized .
Since there is a small QR code window with absolute positioning on the right side of the window , if the window is not maximized, the window will block the next page button and cannot be clicked. This needs attention.
Data Analysis and Visualization
open a file
import pandas as pd
data = pd.read_csv('./hx.csv')
data.head()

According to our data information, we can do the following visual display:
01 Proportion of different types of novels
types = ['现代言情', '古代言情', '玄幻', '玄幻言情', '科幻空间', '仙侠', '都市', '历史', '科幻', '仙侠奇缘', '浪漫青春', '其它']
number = [343, 285, 83, 56, 45, 41, 41, 25, 14, 14, 13,40]
pyecharts pie chart
from pyecharts import options as opts
from pyecharts.charts import Page, Pie
pie=(
Pie()
.add(
"",
[list(z) for z in zip(types, number)],
radius=["40%", "75%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="不同类型小说占比"),
legend_opts=opts.LegendOpts(
orient="vertical", pos_top="15%", pos_left="2%"
),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render('pie.html')
The result is shown in the figure
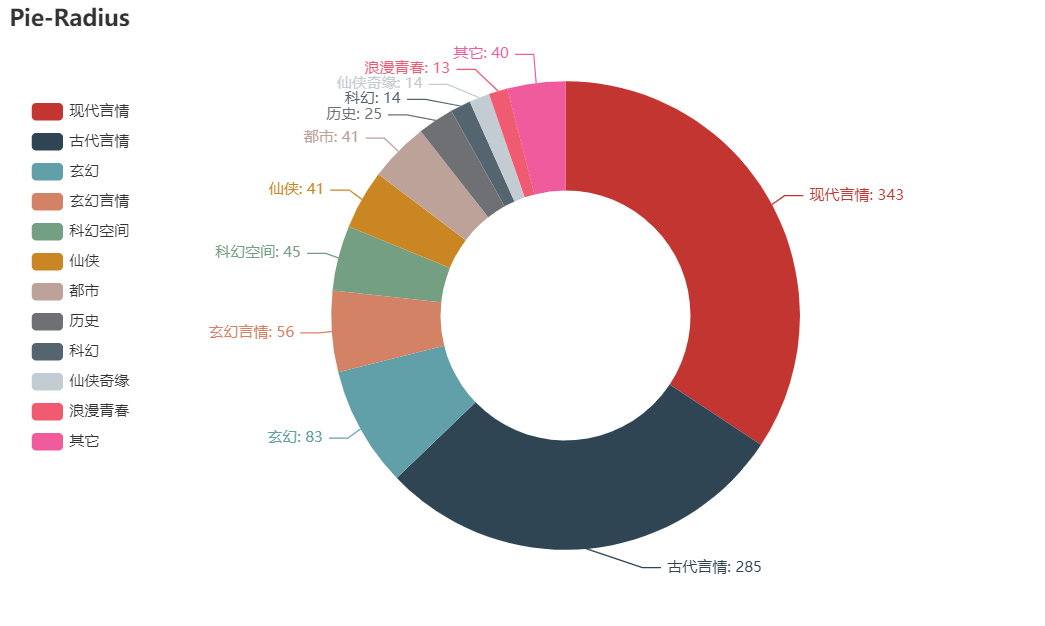
It can be seen from the figure that romance novels account for half of all novels.
02 Proportion of completed novels
from pyecharts import options as opts
from pyecharts.charts import Page, Pie
ty = ['已完结','连载中']
num = [723,269]
pie=(
Pie()
.add("", [list(z) for z in zip(ty,num)])
.set_global_opts(title_opts=opts.TitleOpts(title="完结小说占比"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render('pie1.html')
The result is shown in the figure:

It can be seen from the figure that more than 1/4 of the novels are still being serialized.
03 Novel introduction word cloud display
Generate .txt file
with open('hx.txt','a',encoding='utf-8') as f:
for s in data['intro']:
f.write(s + '\n')
Initialization settings
# 导入相应的库
import jieba
from PIL import Image
import numpy as np
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 导入文本数据并进行简单的文本处理
# 去掉换行符和空格
text = open("./hx.txt",encoding='utf-8').read()
text = text.replace('\n',"").replace("\u3000","")
# 分词,返回结果为词的列表
text_cut = jieba.lcut(text)
# 将分好的词用某个符号分割开连成字符串
text_cut = ' '.join(text_cut)
word cloud display
word_list = jieba.cut(text)
space_word_list = ' '.join(word_list)
# print(space_word_list) 打印文字 可以省略
# 调用包PIL中的open方法,读取图片文件,通过numpy中的array方法生成数组
mask_pic = np.array(Image.open("./xin.png"))
word = WordCloud(
font_path='C:/Windows/Fonts/simfang.ttf', # 设置字体,本机的字体
mask=mask_pic, # 设置背景图片
background_color='white', # 设置背景颜色
max_font_size=150, # 设置字体最大值
max_words=2000, # 设置最大显示字数
stopwords={'的'} # 设置停用词,停用词则不在词云途中表示
).generate(space_word_list)
image = word.to_image()
word.to_file('h.png') # 保存图片
image.show()
The result is shown in the figure

We can't see the special content from the picture here. We can consider some other more effective natural language analysis and processing methods, and leave it to readers and friends to think together.
04 Analyze novel popularity rankings according to genre
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = Bar()
bar.add_xaxis(list(c['types'].values))
bar.add_yaxis('小说热度排行',numList)
bar.set_global_opts(xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=45)))
bar.render()
The result is shown in the figure
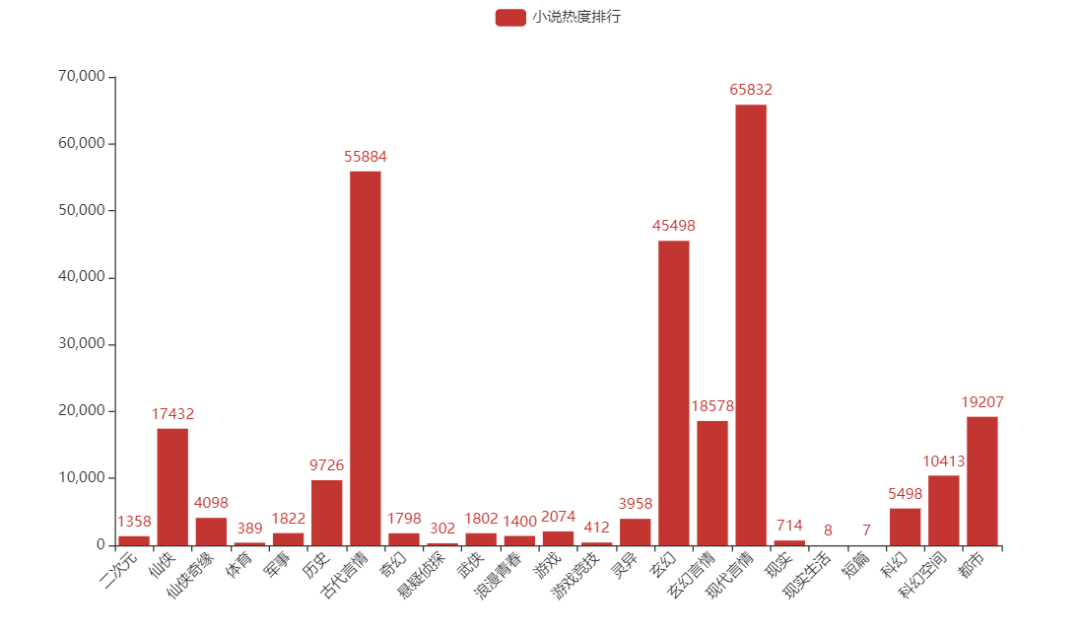
It can be seen that romance novels have been an eternal topic since ancient times...
Romance novels are a kind of Chinese old-style novels, also known as novels of gifted scholars and beautiful ladies. It is a literary genre that focuses on heterosexual love and reflects the psychology, state, things and other social life of love through complete storylines and specific environmental descriptions.
There are many types of romance novels, mainly divided into ancient and modern themes. Among them, there are rebirth articles, time-travel articles, anti-time-travel articles, science fiction articles, house fighting articles, palace fighting articles, fantasy articles, road articles and other different themes. (Baidu Encyclopedia)
05 Proportion of popular novels by different authors
We look at the number of novels written by authors and get the following results:
data['author'].value_counts()

According to the top three writers who wrote the most, they only wrote romance novels, and the last two wrote multiple novels. Next, analyze the popularity of romance novelists and other novelists among these novelists.
Romance novelist popularity
from pyecharts import options as opts
from pyecharts.charts import Page, Pie
attr = ["希行", "吱吱", "青铜穗"]
v1 = [1383,1315,1074]
pie=(
Pie()
.add("", [list(z) for z in zip(attr,v1)])
.set_global_opts(title_opts=opts.TitleOpts(title="言情小说作家热度"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render('pie.html')

These three novelists are equally popular, of course, the most popular one 希行.
Xixing, a pen name, formerly known as Pei Yun, female, one of the representative writers of ancient sayings on the Qidian Chinese website, and a super popular author of female online literature. Member of Chinese Writers Association. Orange Melon Witness · Top 100 Authors of Internet Literature in 20 Years. Since its creation in 2009, Xixing has completed 11 works and created more than 10 million words. Most of his works have been published in simplified and traditional forms. Among them, "Jiaoniang Medical Classic" and "Jun Jiuling" have sold film and television rights. (Baidu Encyclopedia)
The popularity ranking of the two novelists
from pyecharts.charts import Bar
from pyecharts import options as opts
bar = Bar()
#指定柱状图的横坐标
bar.add_xaxis(['玄幻','奇幻','仙侠'])
#指定柱状图的纵坐标,而且可以指定多个纵坐标
bar.add_yaxis("唐家三少", [2315,279,192])
bar.add_yaxis("我吃西红柿", [552,814,900])
#指定柱状图的标题
bar.set_global_opts(title_opts=opts.TitleOpts(title="热度小说排行"))
#参数指定生成的html名称
bar.render('tw.html')

As shown in the figure, Tang Jia San Shao ’s fantasy novels are more prominent, while I Eat Tomatoes are more evenly popular among the three novels.
write at the end
We use selenium to crawl the novel page data of Hongxiu Tianxiang website. Because of the js encryption of the page, we use selenium, and then summarize the points for attention:
① There are a few points to note when selenium crawls data:
-
The positioning of various elements needs to be precise;
-
Since using selenium needs to load js code, all elements need to be fully loaded before they can be positioned, so you need to set time.sleep(n) to open the web page;
-
Then for many websites, there is an absolutely positioned element, which may be a QR code..., which is fixed on the computer screen and will not move with the scrolling of the page wheel, so the page needs to be maximized to prevent the window from blocking the page elements. Resulting in inability to click or other operations.
② It is necessary to clean the data when displaying the data visually, because some data is irregular, for example, such errors may occur:
'utf-8' codec can't decode byte 0xcb in
position 2: invalid continuation byte
This is due to the different encoding methods. Generally, the encoding method is obtained by checking the charset attribute of the meta tag on the page, and the encoding attribute value is set when pandas opens the file; if the error is still reported, the attribute value can be modified to'gb18030'
<meta charset="UTF-8">
Remarks, this article is only for learning and communication, and I have a little taste of crawlers, so as not to increase the burden on the server.
OK, that's all for today's sharing!
Python is
becoming more and more popular, and it is not far from the era when all people learn python. There are so many python application scenarios, whether it is a main business, a side business or other things. I have a copy here. A full set of Python learning materials, I hope to give some help to those who want to learn Python!
1. The learning route of all directions of Python
The route of all directions of Python is to sort out the technical points commonly used in Python to form a summary of knowledge points in various fields. Its usefulness lies in that you can find corresponding learning resources according to the above knowledge points. Make sure you learn more comprehensively.
2. Learning software
If a worker wants to do a good job, he must first sharpen his tools. The commonly used development software for learning Python is here, which saves you a lot of time.

3. Introductory learning videos
When we watch videos and learn, we can’t just move our eyes and brains without doing it. A more scientific learning method is to use them after understanding. At this time, the hands-on project is very suitable.
4. Practical cases
Optical theory is useless. You have to learn to follow along and do practical exercises in order to apply what you have learned to practice. At this time, you can learn from some practical cases.
5. Interview materials
We must learn Python to find a high-paying job. The following interview questions are the latest interview materials from first-line Internet companies such as Ali, Tencent, and Byte, and Ali bosses have given authoritative answers. Brush After completing this set of interview materials, I believe everyone can find a satisfactory job.
This full version of the full set of Python learning materials has been uploaded to CSDN. If you need it, you can scan the QR code of CSDN official certification below on WeChat to get it for free【保证100%免费】
