foreword
This article will discuss with you python's multi-process concurrent programming (Part 1) , use the built-in basic library multiprocessing来实现并发, and use this module simply through the official. Lay a good foundation first, so that you can have a basic usage and cognition, and we will use it in detail in the follow-up articles.
This article is the fourth article of python concurrent programming. The address of the previous article is as follows:
Python: Concurrent Programming (3)_Lion King's Blog-CSDN Blog
The address of the next article is as follows:
Python: Concurrent Programming (5)_Lion King's Blog-CSDN Blog
1. Quick start
Official documentation: multiprocessing --- Process-based parallelism — Python 3.11.4 documentation
1. Compare the process status through Process Explorer
Based on the official code, I added the "while True:" wireless loop to facilitate the observation of the process.
This code creates an infinite loop, using multiprocessingthe module's process pool to execute functions in each loop f(x). Specific steps are as follows:
(1) Import the class multiprocessingof the module Pool.
(2) A function is defined f(x)to calculate xthe square of the incoming parameter.
(3) if __name__ == '__main__':Create a process pool under the condition p, and specify the size of the process pool as 5.
(4) Use the method to apply the function to each element in p.map()the given iterable object in parallel and return the result.[1, 2, 3]f(x)
(5) Print out the results.
(6) Enter an infinite loop.
from multiprocessing import Pool
def f(x):
return x*x
if __name__ == '__main__':
while True:
with Pool(5) as p:
print(p.map(f, [1, 2, 3]))Process conditions before running:

Process status at runtime:
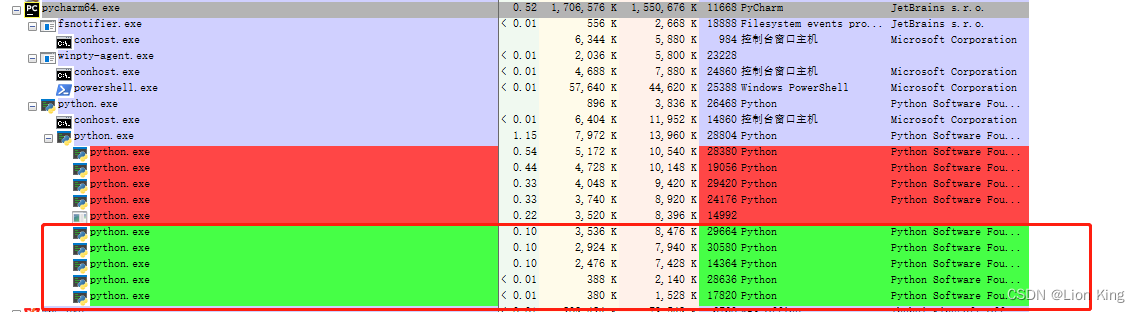
Through the above experiments, we know that this program is constantly creating and destroying 5 processes, the red part is the 5 processes that were destroyed, and the green part is the newly generated 5 processes. When running a script through Pycharm, a python.exe sub-process will be generated first, and this sub-process will generate a python.exe sub-process and a conhost.exe sub-process, and the second python.exe sub-process will generate 5 sub-processes, to perform tasks.
Modify the above code to make it report an error:
from multiprocessing import Pool
def f(x):
return x*x
# if __name__ == '__main__':
# while True:
with Pool(5) as p:
print(p.map(f, [1, 2, 3]))This experiment tells us that the process can only run under the main module (if __name__ == '__main__':), otherwise the following error will be reported:
RuntimeError:
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
Therefore, to avoid the problem of triggering infinite recursion when creating a child process, you need to use if __name__ == '__main__':conditions to ensure that the code is executed in the main module. This is because multiprocessingthe module will create a new Python interpreter instance in the multi-process implementation under the Windows operating system, and this code itself also includes the operation of creating a process, so you need to ensure that it is only executed once in the main module.
2. The use of process class
from multiprocessing import Process
import os
def info(title):
print(title)
print('module name:', __name__)
print('parent process:', os.getppid())
print('process id:', os.getpid())
def f(name):
info('function f')
print('hello', name)
if __name__ == '__main__':
while True:
info('main line')
p = Process(target=f, args=('bob',)) # 创建一个子进程,目标函数为f,传入参数为'bob'
p.start() # 启动子进程的执行
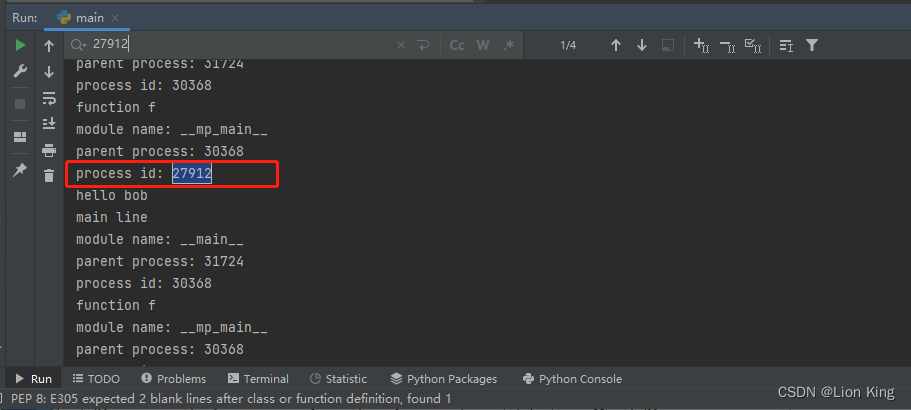
p.join() # 等待子进程执行结束The above code uses multiprocessing.Processmodules to create a subprocess and execute functions in the subprocess f. In the main module, two helper functions infoand f.
infoThe function is used to print the relevant information of the process, including title, module name, parent process ID and current process ID.
fThe function is the target function executed by the child process. It accepts a parameter name. Inside the function, infothe function will be called to print information and output helloplus the parameter passed in name.
In the main module, first call infothe function to print the information of the main thread. Then, Processcreate a child process object through the class p, set the target function as f, and pass in parameters ('bob',). Next, the call p.start()starts the execution of the child process, which executes the function f('bob'). Finally, by p.join()waiting for the child process to finish executing.
When running, it will output the relevant information of the main process and the child process, and print out hello bobthe result of executing as a child process.

3. Context startup method
In order to improve the portability and compatibility of the code, when using multiprocessingthe module, an appropriate startup method can be set according to different operating systems. By using it mp.set_start_method('spawn'), you can ensure that the code can run normally on each operating system (for example, first determine the system type, and then call the corresponding method of the system), and there is no need to write different code logic for different operating systems.
import multiprocessing as mp
def foo(q):
q.put('hello')
if __name__ == '__main__':
mp.set_start_method('spawn') # 设置启动方法为'spawn'
q = mp.Queue() # 创建进程间通信的队列
p = mp.Process(target=foo, args=(q,)) # 创建子进程,目标函数为foo,传入参数为q
p.start() # 启动子进程的执行
print(q.get()) # 从队列中获取子进程放入的值并打印
p.join() # 等待子进程执行结束
where set_start_method('spawn')方法可以被 get_context('spawn') is substituted.
4. Exchanging objects between processes
queue
from multiprocessing import Process, Queue
def f(q):
q.put([42, None, 'hello'])
if __name__ == '__main__':
# 创建一个队列对象
q = Queue()
# 创建子进程,指定目标函数为f,将队列对象作为参数传递给子进程
p = Process(target=f, args=(q,))
# 启动子进程
p.start()
# 从队列中获取数据并打印
print(q.get()) # 输出 "[42, None, 'hello']"
# 等待子进程执行完成
p.join()
This code uses and multiprocessingin the module to achieve inter-process communication. The specific code is explained as follows:ProcessQueue
(1) Import the necessary modules:from multiprocessing import Process, Queue
(2) Define a function fthat takes an Queueobject as a parameter and puts a list containing the data into the queue [42, None, 'hello'].
(3) if __name__ == '__main__':Under the condition, create an Queueobject qfor inter-process communication.
(4) Create a subprocess p, specify the function to be executed through Processthe class constructor f, and pass Queuethe object qas a parameter to the subprocess.
(5) Start the child process pand wait for the child process to complete.
(6) Use the method in the main process q.get()to get data from the queue and print the result [42, None, 'hello'].
(7) Wait for the execution of the child process to complete, and p.join()block the call to ensure that the execution of the child process is completed before continuing to execute the main process.
The code implements the function of data transfer between the main process and the child process through the queue. The main process creates a queue qand passes it as an argument to the child process p. The child process calls the function fto put the data into the queue, and the main process q.get()obtains the data from the queue through the method and prints it. In this way, the data exchange between the main process and the child process is realized.
pipeline
from multiprocessing import Process, Pipe
def f(conn):
# 向管道发送数据
conn.send([42, None, 'hello'])
# 关闭管道连接
conn.close()
if __name__ == '__main__':
# 创建管道,返回父进程和子进程的连接对象
parent_conn, child_conn = Pipe()
# 创建子进程,指定目标函数为f,将管道的子连接对象作为参数传递给子进程
p = Process(target=f, args=(child_conn,))
# 启动子进程
p.start()
# 从父连接接收数据并打印
print(parent_conn.recv()) # 输出 "[42, None, 'hello']"
# 等待子进程执行完成
p.join()
When we need inter-process communication in multi-process programming, we can use pipes (Pipe) to achieve it. The above code demonstrates an example of using pipes for inter-process communication.
First, we imported Processthe and Pipemodules. ProcessUsed to create subprocesses, Pipeused to create pipeline objects.
fThen, a function named is defined that takes a pipe connection object as an argument. Inside the function, we sendsend a list [42, None, 'hello']containing and closeclose the pipe connection using method.
In if __name__ == '__main__'the condition, we create a pipeline object with Pipe()functions returning a parent connection object and a child connection object.
Next, we create a subprocess p, specify the target function as f, and pass the subprocess of the pipeline as a parameter to the subprocess.
Then, we start the child process p.
In the parent process, we use parent_conn.recv()the method to receive data from the parent connection and print the received data. In this example, we receive it [42, None, 'hello'], and print it out.
Finally, we use p.join()to wait for the child process to finish executing.
Through this code, we have realized the communication between the parent process and the child process, using the pipeline as the channel for data transmission. The parent process sends data to the pipe, the child process receives data from the pipe, and prints the received data in the parent process. This enables simple inter-process communication.
2. Queues and pipelines
1. Queue and its function
Queue (Queue) for inter-process communication is a mechanism used in multi-process programming to transfer data between different processes. It allows one process to put data into a queue, and other processes can get this data from the queue.
The role of queues in multi-process programming mainly includes the following aspects:
(1) Data sharing: Queues provide a safe and reliable way to share data. Different processes can exchange and share data through queues, without using other complex mechanisms to handle data synchronization and exclusive access.
(2) Synchronization mechanism: Queues can be used as a synchronization mechanism between processes. For example, one process can put tasks in a queue, and other processes can get tasks from the queue and process them. This enables coordination and synchronization between processes, ensuring that each process executes tasks in the expected order.
(3) Decoupling: By using queues, different processes can be decoupled. Each process can independently execute its own tasks and exchange data through the queue without explicitly depending on the status and execution order of other processes.
(4) Buffering role: The queue can be used as a data buffer to balance the speed difference between producers and consumers. When the producer generates data faster than the consumer can process the data, the data can be temporarily stored in the queue to avoid data loss or producer blocking. This buffering mechanism can improve system performance and stability.
All in all, the queue for inter-process communication is an important mechanism for data exchange, synchronization and decoupling between different processes, improving system reliability, performance and scalability.
2. The pipeline and its function
The pipe (Pipe) of inter-process communication is used in multi-process programming to realize two-way communication between two processes.
Specifically, a pipe provides a channel connecting two processes, allowing them to transfer data in both directions. The pipeline has two endpoints, the parent process end and the child process end. The parent process can send data to the child process through one endpoint of the pipe, and the child process can send data back to the parent process through the other endpoint.
The role of the pipeline for inter-process communication includes:
(1) Data transmission: The pipeline allows the parent process to send data to the child process, the child process can receive and process the data, and then send the processing results back to the parent process through the pipeline.
(2) Two-way communication: The pipeline provides two-way communication capabilities. The parent process and the child process can perform two-way data exchange on the same pipeline to realize mutual communication between processes.
(3) Synchronization mechanism: The pipeline provides a synchronization mechanism to ensure the order and consistency of sending and receiving operations. If a process tries to read data from the pipe, but the pipe is empty, the process will block until data is available in the pipe.
(4) Inter-process decoupling: By using pipes, different processes can be decoupled from each other, and they only need to focus on sending and receiving data through pipes, without caring about the specific implementation details of other processes.
In general, the interprocess communication pipeline provides a reliable, two-way communication channel to help different processes perform two-way data exchange and cooperation during concurrent execution.
3. The difference between queues and pipelines
In Python multiprocessingmodules, both queues ( Queue) and pipes ( Pipe) can be used to implement inter-process communication, but they have some differences:
(1) Function: The queue is a thread-safe data structure that supports multiple processes to put and take data into it, and can realize the producer-consumer model. The pipeline is a two-way channel that can perform two-way data transmission between two processes.
(2) Interface: The queue provides put()and and get()other methods for safely putting and taking out data between processes. The pipeline provides two connection objects, which can realize inter-process communication by sending and receiving messages.
(3) Communication method: The queue uses the first-in-first-out (FIFO) method, that is, the data put in first is taken out first. Pipelines, on the other hand, can transmit data in both directions, sending and receiving as needed.
(4) Implementation method: The queue is implemented based on the pipeline and lock mechanism, so it is process-safe. The pipeline is to achieve inter-process communication by creating two connection objects.
In general, queues are suitable for scenarios where data sharing and communication between multiple processes is required, and are especially suitable for producer-consumer models. The pipeline is suitable for scenarios that require two-way communication, and can perform two-way data transmission between two processes. According to the specific needs and scenarios, choose the appropriate inter-process communication method.