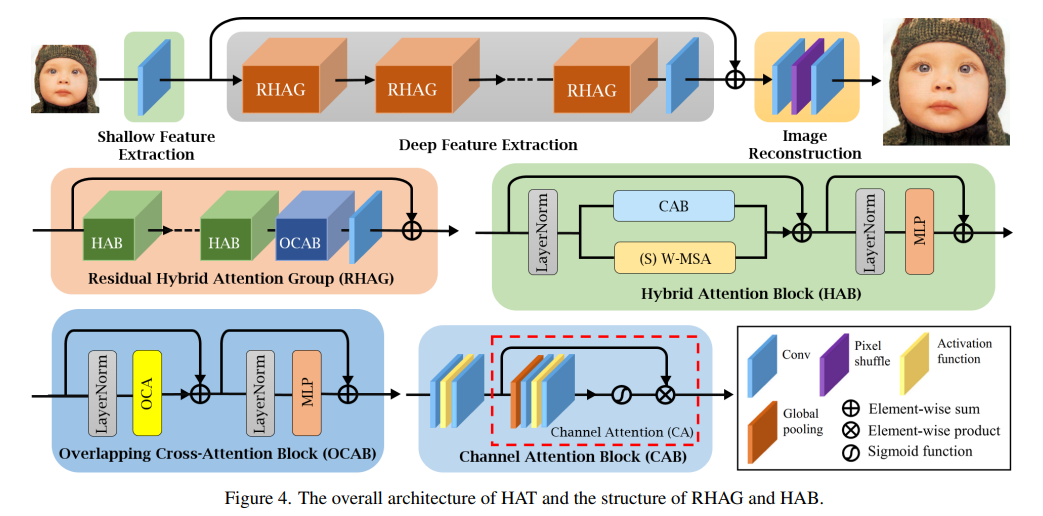
1、Activating More Pixels in Image Super-Resolution Transformer
Transformer-based methods have shown impressive performance in low-level vision tasks such as image super-resolution. The potential of Transformer is still underutilized in existing networks. To activate more input pixels for better reconstruction, a new Hybrid Attention Transformer (HAT) is proposed. It combines channel attention and window-based self-attention schemes simultaneously, thereby taking full advantage of their respective advantages, namely, the ability to exploit global statistics and strong local fitting capabilities.
Furthermore, to better aggregate cross-window information, an overlapping cross-attention module is introduced to enhance the interaction between adjacent window features. In the training phase, the same task pre-training strategy is adopted to exploit the potential of the model for further improvement. Extensive experiments demonstrate the effectiveness of the proposed module, and the model is further extended to show that the performance of this task can be greatly improved. The overall method outperforms the existing state-of-the-art methods by more than 1dB in PSNR.
https://github.com/XPixelGroup/HAT
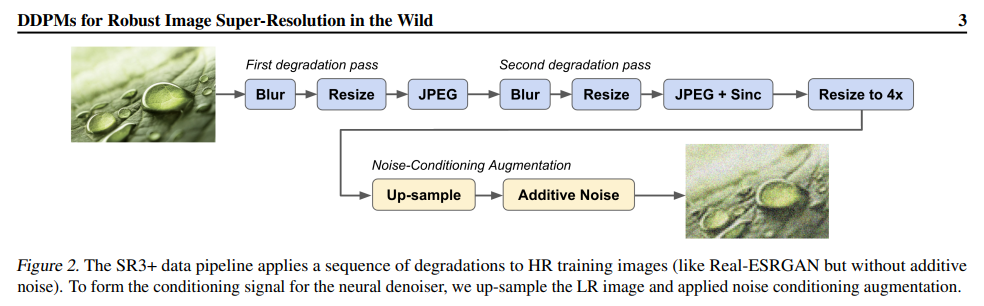
2、Denoising Diffusion Probabilistic Models for Robust Image Super-Resolution in the Wild
Diffusion models have shown good results in single image super-resolution and other image-to-image translation tasks. Despite this success, they do not outperform state-of-the-art GAN models on the more challenging blind super-resolution task, where the distribution of input images is not uniform and the degradation is unknown .
This paper introduces a diffusion-based blind super-resolution model SR3+, for which self-supervised training is combined with noise-conditioned augmentation during training and testing. The performance of SR3+ is much better than SR3. Outperforms RealESRGAN when trained on the same data.
3、Implicit Diffusion Models for Continuous Super-Resolution
Image super-resolution (SR) has received increasing attention due to its wide range of applications. However, current SR methods often suffer from over-smoothing and artifacts, while most works are limited to fixed magnifications. This paper introduces an implicit diffusion model (IDM) for high-fidelity continuous image super-resolution.
IDM employs a unified end-to-end framework combining implicit neural representations and denoising diffusion models, where the implicit neural representations are employed during decoding to learn continuous-resolution representations. Furthermore, a scale-adaptive scaling mechanism is designed, which includes a low-resolution (LR) scaling network and a scaling factor that tunes the resolution and accordingly scales the LR information and generated features in the final output, thus Adapt the model to continuous resolution requirements. Extensive experiments confirm the effectiveness of IDM and demonstrate its superior performance over previous works of art. The code is at https://github.com/Ree1s/IDM

4、Perception-Oriented Single Image Super-Resolution using Optimal Objective Estimation
Single image super-resolution (SISR) networks trained with perceptual and adversarial losses provide high-contrast outputs relative to networks trained with distortion-guided losses such as L1 or L2. However, it has been shown that locally distinct shapes in pictures cannot be accurately recovered using a single perceptual loss, often resulting in undesirable artifacts or unnatural details. Therefore, various combinations of losses have been tried, such as perceptual, adversarial, and distortion losses, but it is often difficult to find the optimal combination.
This paper proposes a novel SISR framework applied to each region for optimal object generation to generate reasonable results in the overall region of high-resolution output. Specifically, the framework consists of two models: a predictive model to infer the optimal target map given a low-resolution (LR) input, and a generative model to generate the corresponding SR output. The generative model is trained based on the proposed object trajectory, which represents a basic set of objects, enabling a single network to learn various SR results corresponding to the losses combined on the trajectory.
Across five benchmarks, experimental results show that the proposed method outperforms state-of-the-art perception-driven SR methods on LPIPS, DISTS, PSNR and SSIM metrics. The visual results also demonstrate the superiority of the method in perception-guided reconstruction. Code and models are at https://github.com/seunghosnu/SROOE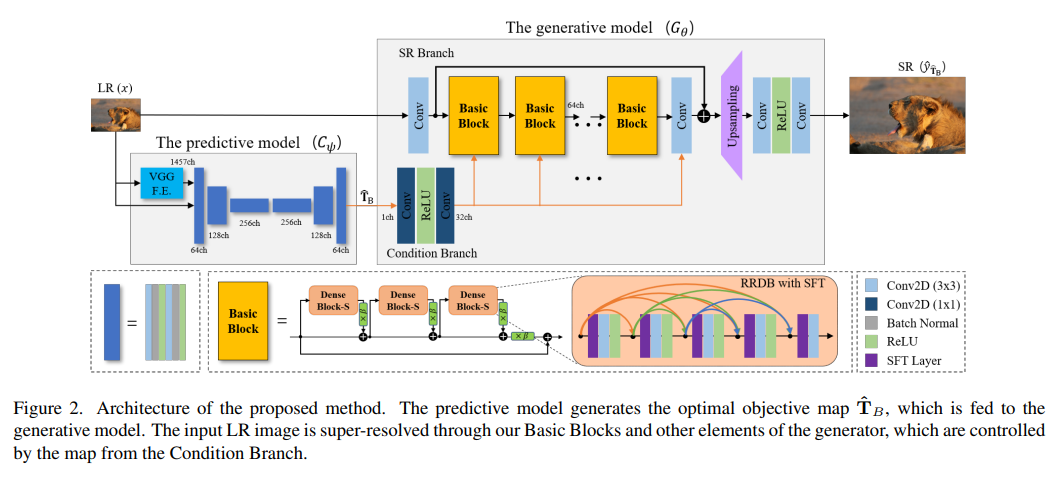
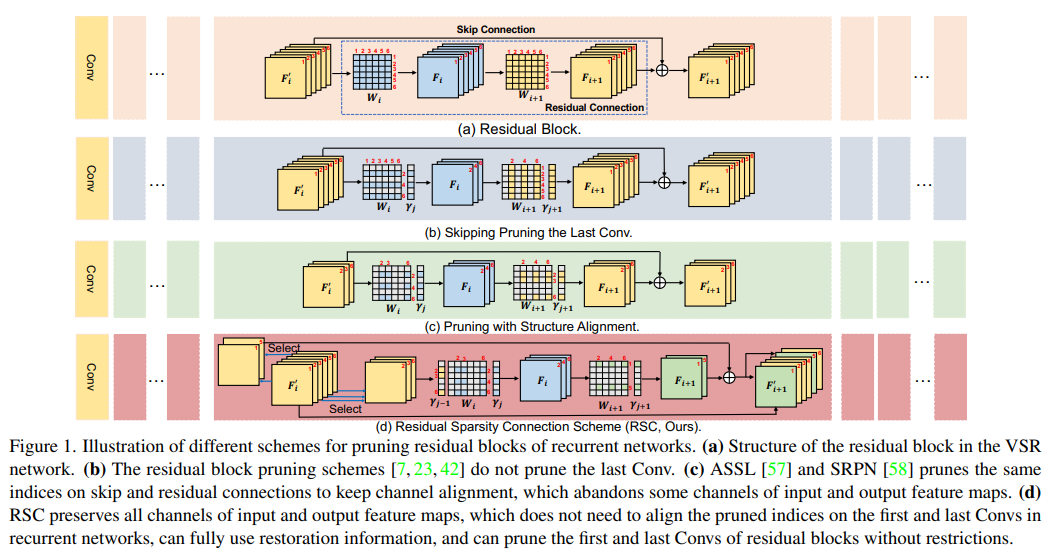
5、Structured Sparsity Learning for Efficient Video Super-Resolution
The high computational cost of existing video super-resolution (VSR) models hinders their deployment on resource-constrained devices such as smartphones and drones. Existing VSR models contain quite a lot of redundant parameters, which slows down the inference efficiency. To prune these unimportant parameters, a structured pruning scheme called Structural Sparse Learning (SSL) is developed based on the properties of VSR.
SSL designs pruning schemes for several key components of the VSR model, including residual blocks, recurrent networks, and upsampling networks. Specifically, a Residual Sparse Connection (RSC) scheme is designed for the residual blocks of recurrent networks to liberate the pruning limitation and preserve the recovery information. For the upsampling network, a pixel shuffling and pruning scheme is designed to ensure the accuracy of feature channel spatial transformation. It is also observed that pruning error is amplified as the hidden state is propagated along the recurrent network. To alleviate this problem, temporal fine-tuning (TF) is designed. Extensive experiments demonstrate that SSL significantly outperforms recent methods both quantitatively and qualitatively. The code is at https://github.com/Zj-BinXia/SSL
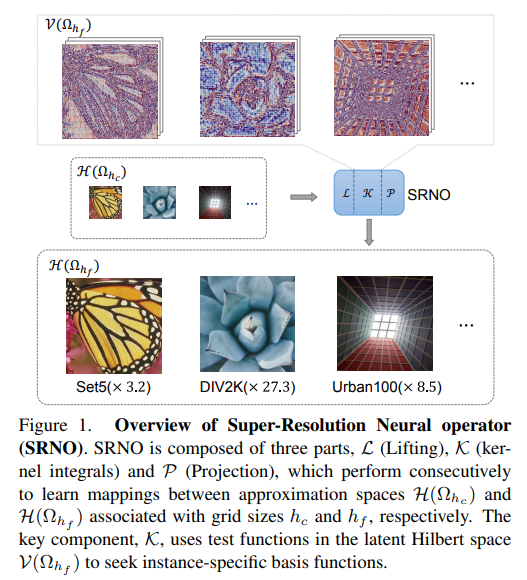
6、Super-Resolution Neural Operator
A Super-resolution Neural Operator (SRNO) is proposed, which can solve arbitrary scaling of high-resolution (HR) images from their low-resolution (LR) counterparts. Treating LR-HR image pairs as continuous functions approximated using different grid sizes, SRNO learns a mapping between the corresponding function spaces.
Compared with previous work on continuous SR, the key features of SRNO are: 1) The kernel integration in each layer is efficiently realized by Galerkin-type attention, which has non-local properties in the spatial domain, thus facilitating grid-free continuous 2) The multi-layer attention structure allows dynamic latent basis updates, which is very important for SR problems to "fantasy" high-frequency information from LR images.
Experimental results show that SRNO outperforms existing continuous SR methods in terms of accuracy and running time. The code is at https://github.com/2y7c3/Super-Resolution-Neural-Operator
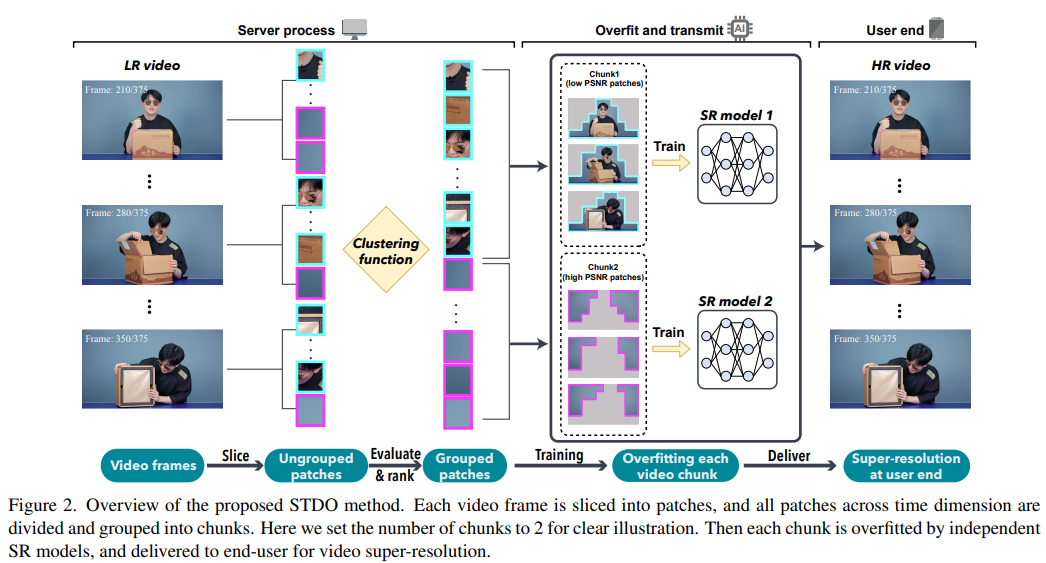
7、Towards High-Quality and Efficient Video Super-Resolution via Spatial-Temporal Data Overfitting
A new high-quality and efficient method for video resolution upscaling is proposed, which utilizes spatio-temporal information to accurately segment videos into blocks, thereby keeping the number of blocks and model size to a minimum. Deploying the model on off-the-shelf mobile phones, experimental results show that the method achieves real-time video super-resolution with high video quality. Compared with the state-of-the-art method, we achieve 28 fps streaming speed, 41.6 PSNR, 14 times faster speed and 2.29 dB higher quality in the real-time video resolution upscaling task. Code will be released: https://github.com/coulsonlee/STDO-CVPR2023
Pay attention to the official account [Machine Learning and AI Generation Creation], more exciting things are waiting for you to read
In-depth explanation of ControlNet, a controllable AIGC painting generation algorithm!
Classic GAN has to read: StyleGAN
 Click me to view GAN's series albums~!
Click me to view GAN's series albums~!
A cup of milk tea, become the frontier of AIGC+CV vision!
The latest and most complete 100 summary! Generate Diffusion Models Diffusion Models
ECCV2022 | Summary of some papers on generating confrontation network GAN
CVPR 2022 | 25+ directions, the latest 50 GAN papers
ICCV 2021 | Summary of GAN papers on 35 topics
Over 110 articles! CVPR 2021 most complete GAN paper combing
Over 100 articles! CVPR 2020 most complete GAN paper combing
Dismantling the new GAN: decoupling representation MixNMatch
StarGAN Version 2: Multi-Domain Diversity Image Generation
Attached download | Chinese version of "Explainable Machine Learning"
Attached download | "TensorFlow 2.0 Deep Learning Algorithms in Practice"
Attached download | "Mathematical Methods in Computer Vision" share
"A review of surface defect detection methods based on deep learning"
A Survey of Zero-Shot Image Classification: A Decade of Progress
"A Survey of Few-Shot Learning Based on Deep Neural Networks"
"Book of Rites·Xue Ji" has a saying: "Learning alone without friends is lonely and ignorant."
Click on a cup of milk tea and become the frontier waver of AIGC+CV vision! , join the planet of AI-generated creation and computer vision knowledge!