I have written a lot of technical documents on how to logarithm and how to logarithm in batches. Recently, the project encountered this problem, and I found out that no article on this topic has been published on the official blog. It's like being dark under the lights, knowledge points that have been used for too long, but did not realize its importance.
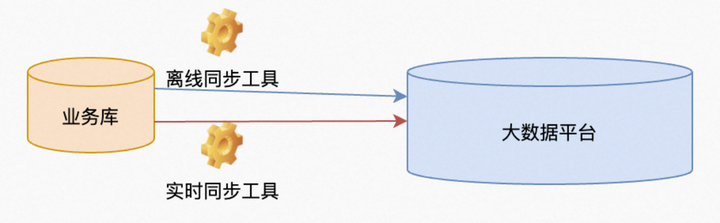
Note: The logarithmic scenario here refers to the scenario where big data development tools such as dataworks are used on the Alibaba Cloud platform to integrate business system database (oracle, etc.) data to the cloud to maxcompute. Therefore, the example SQL is also for maxcompute.
Let’s talk about the logarithm in general business first. We made a report and produced a data “30 units of a certain product were sold”. This data is not only available on the big data platform, but also in the business system. These statistical actions will also have a copy in the business system through procedures and manual work. Generally, this data will be checked first after the report is prepared.
Therefore, the data fed back from the front line is the problem of inconsistent summary data. However, this result is very general, because just like I feel that my salary is underpaid by 50 cents this month, if I don’t look at my salary slip, I actually don’t know if I am underpaid. The salary slip is not just a summary data, it contains a series of detailed data such as my pre-tax salary, bonus (floating), social security, tax deduction, etc. These data allow me to judge whether I have lost 50 cents, and the processed data is complicated.
Speaking of this, I actually want to express one thing, the logarithm is to compare the detailed data. This is the basis of all calculated facts, which can be used as evidence.
Therefore, both sides check the corresponding records of the table used by this summary value, for example, query "the sales record of this product ID today". As a result, it was found that there were 31 business systems and 30 big data platforms.
Even here, in fact, we still don't know what happened during the period and why the data was lost. In addition, we don't know whether the data of other product IDs are also lost, and whether similar situations will occur with the data of other tables.
1. Detailed data comparison
Since the detailed data is ultimately compared, can I directly compare the detailed data? The answer is: correct.
Generally, when this happens, the data in the two tables of the business system and the big data platform must be compared first.
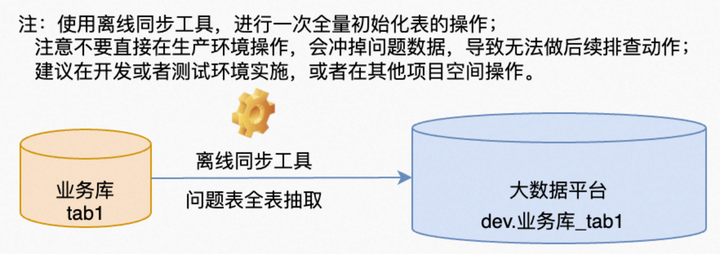
1. Then use the full integration tool to extract all the data from the database of the business system to the big data platform. To compare data, the data must be put together, and there is no space comparison. Because the capacity of the big data platform is hundreds of times that of the business system, it is generally compared on the big data platform. (There is a paradox here. If the integrated tool itself is flawed, resulting in data loss during the extraction process, it will never be possible to compare. Therefore, if you are not sure about this tool, you have to export data from the database to a file. Then load it to a database for comparison. Here, through my years of experience in using this product for offline integration, this tool is very reliable and I have never encountered this problem.)
2. According to the primary key association, compare the differences of the primary keys in the two tables. If it is the problem of record loss mentioned above, it is easy to compare after this step. There is also a problem here, that is, the tables of the business system are constantly changing, so there will be differences when compared with the tables of the big data platform. The core reason for this difference is: the table of the big data platform is the data of a point in time at the end of each day (00:00:00) of the business system table, and the data of the business system is always changing. So, don't panic even if there is a difference that exceeds expectations. If real-time synchronization is used, every change in data during this period can be obtained from the archive log, and the cause of the change can be traced. If there is no real-time synchronization, you can also use the time-related fields in the table to determine whether the data has been updated. If there is nothing (this situation also exists), then go and scold the business system development of the design table (yes, it is their fault), or you can ask the business to find out in detail whether this record is made today Yes, not yesterday.
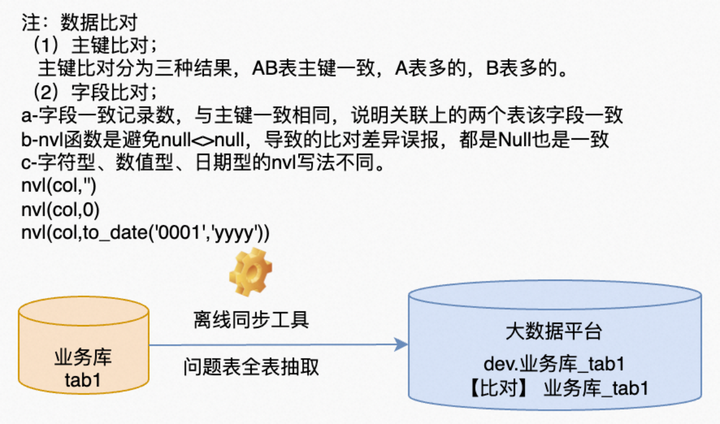
3. There is another situation where the primary key is consistent and the data content (fields other than the primary key) is inconsistent. In this case, it is still necessary to consider the data changes, which can be compared from several perspectives such as logs, time fields, and business. If you find that the data does not meet expectations, you need to query the problem of the synchronization tool.
2. Compare SQL Analysis
In the above section, I described the link of comparing the full table extracted today with the previous day's full table that was merged with the previous day's full table and the previous day's increment on maxcompute. The SQL method for comparing whether the sets of two tables are consistent is actually relatively simple, and everyone will immediately think of set operations. There are Minus and except in oracle, as well as in maxcompute. But in order to facilitate the analysis of the problem, I still wrote a SQL myself. Sample SQL (maxcompute sql) is as follows:
--限定日期分区,比对上日
select count(t1.BATCH_NUMBER) as cnt_left
,count(t2.BATCH_NUMBER) as cnt_right
,count(concat(t1.BATCH_NUMBER,t2.BATCH_NUMBER)) as pk_inner
,count(case when t1.BATCH_NUMBER is not null and t2.BATCH_NUMBER is null then 1 end) as pk_left
,count(case when t2.BATCH_NUMBER is not null and t1.BATCH_NUMBER is null then 1 end) as pk_right
,count(case when nvl(t1.rec_id ,'') = nvl(t2.rec_id ,'') then 1 end) as col_diff_rec_id
,count(case when nvl(t2.rec_creator ,'') = nvl(t1.rec_creator ,'') then 1 end) as col_diff_rec_creator
,count(case when nvl(t2.rec_create_time,'') = nvl(t1.rec_create_time,'') then 1 end) as col_diff_rec_create_time
from ods_dev.o_rz_lms_im_timck01 t1 -- 开发环境重新初始化的今天数据
full join ods.o_rz_lms_im_timck01 t2 -- 生产环节昨日临时增量合并的数据
on t1.BATCH_NUMBER =t2.BATCH_NUMBER
and t1.IN_STOCK_TIME =t2.IN_STOCK_TIME
and t1.OP_NO =t2.OP_NO
and t1.STOCK_CODE =t2.STOCK_CODE
and t1.YP_ID =t2.YP_ID
and t2.ds='20230426'
where t1.ds='20230426'
;
--cnt_left 9205131 说明:左表有记录数 9205131
--cnt_right 9203971 说明:右表有记录数 9203971
--pk_inner 9203971 说明:主键关联一致记录数 9203971
--pk_left 1160 说明:左表比右表多记录数 1160
--pk_right 0 说明:右表比左表多有记录数 0
--col_diff_rec_id 9203971 说明:字段一致记录数与主键一致相同,说明关联上的两个表该字段一致
--col_diff_rec_creator 9203971 说明:同上
--col_diff_rec_create_time 9203971 说明:同上In the above example, the left table is the data reinitialized today, and the right table is the full data of the previous day merged on maxcompute. Before comparing, we should actually understand that the data in these two tables must be inconsistent. Although it is the same table, the time points are inconsistent.
Inconsistencies include several types:
1. The primary key that exists in the t1 table does not exist in the t2 table;
2. The primary key that exists in the t2 table does not exist in the t1 table;
3. The primary key exists in both tables t1 and t2, but the values of fields other than the primary key are inconsistent;
4. The primary key exists in both tables t1 and t2, but the values of fields other than the primary key are the same;
Except for the case in No. 4, the values of the other three states are inconsistent in the two tables, and further verification is required. Under normal circumstances, the first case is the data newly inserted into the business database after midnight today, the second case is the data in the business database deleted after midnight today, and the third case is the data updated after midnight today Data, the fourth case is the data in the business table that has not been updated after midnight today.
After understanding these conditions, we can identify
3. Dataworks real-time synchronization log table
If only the offline synchronization of DataWorks is available for synchronization, it is actually somewhat difficult to observe the above data changes. If we use real-time synchronization, the changes in the database data will be preserved. The changes mentioned in the previous chapter can be observed from the log. The following SQL is the SQL I used to query this change. The query (dataworks real-time data synchronization log table) sample SQL is as follows:
select from_unixtime(cast(substr(to_char(_execute_time_),1,10) as bigint)) as yy
,get_json_object(cast(_data_columns_ as string),"$.rec_id") item0
,x.*
from ods.o_rz_lms_odps_first_log x -- 实时同步数据源 o_rz_lms 的日志表
where year='2023' and month='04' and day>='10' --数据区间限制
--and hour ='18'
and _dest_table_name_='o_rz_lms_im_timck01' --数据表限制
-- 以下为主键字段
and get_json_object(cast(_data_columns_ as string),"$.yp_id") ='L1'
and get_json_object(cast(_data_columns_ as string),"$.batch_number") ='Y1'
and get_json_object(cast(_data_columns_ as string),"$.in_stock_time") ='2'
and get_json_object(cast(_data_columns_ as string),"$.op_no") ='9'
and get_json_object(cast(_data_columns_ as string),"$.stock_code") ='R'
--and _operation_type_='D'
order by _execute_time_ desc
limit 1000
;
-- _execute_time_ 数据操作时间
-- _operation_type_ 操作类型 增删改UDI
-- _sequence_id_ 序列号,不会重复
-- _before_image_ 修改前数据
-- _after_image_ 修改后数据
-- _dest_table_name_ 操作的表名
-- _data_columns_ 操作的数据内容JSONThe real-time synchronized data source of DataWorks will be written into a table named "data source name + _odps_first_log" in real time every once in a while. The table has four levels of partitions: year, month, day, and hour. The primary key of this table is not the data operation time, but the serial number "_execute_time_". Therefore, the update order of the primary key of a row of data is updated according to "_execute_time_".
A row of data update has two states before and after, so there are two fields "_before_image_ data before modification, _after_image_ data after modification" to identify the before and after states.
The data is stored in JSON format in the field "_data_columns_". In order to identify a certain row of data, I use a function to parse the corresponding field to determine the data I want.
4. Continuous quality assurance
So far, I haven't talked about how to deal with data inconsistencies. If it is indeed found that the data is inconsistent, the available processing method is to reinitialize the full amount of data. It should be emphasized here that if the offline full integration tool is credible, the fully initialized data will not be lost. But if this method is not credible, then it is necessary to change the method.
In many cases, some business changes at the source end will occasionally result in data exceptions. When the cause of data loss is not identified, it is necessary to frequently compare the data consistency to prevent problems before they happen. Therefore, the consistency of daily monitoring data is also very important.
This article is the original content of Alibaba Cloud and may not be reproduced without permission.