Hadoop startup related configuration
Article directory
The case of formatting nodes
Under what circumstances does Hadoop need to format nodes?
Hadoop requires the NameNode to be formatted in the following cases:
- Installing Hadoop for the first time: When building and configuring a Hadoop cluster for the first time, you need to format the NameNode. The formatting operation creates the HDFS metadata storage structure and initializes the NameNode. Note that in subsequent operations, there is no need to format the NameNode again, unless the entire HDFS is to be reset.
- Reset HDFS: If you want to reset the entire HDFS, removing all data and metadata, you can reformat the NameNode. But be aware that this will result in loss of all data on HDFS.
To format the NameNode, run the following command:
$HADOOP_HOME/bin/hadoop namenode -format
Hadoop startup steps
Is the startup step of Hadoop just start-dfs.sh?
start-dfs.shThe script is only used to start Hadoop Distributed File System (HDFS) related components such as NameNode, Secondary NameNode (if configured) and DataNode. After running this script, the HDFS service will be up and running.
However, the Hadoop ecosystem also includes other components such as YARN (for resource management and task scheduling). To start the YARN components, the following commands need to be run:
$HADOOP_HOME/sbin/start-yarn.sh
This will start the ResourceManager and NodeManager.
Therefore, in order to fully start a Hadoop cluster, two scripts need to be run: start-dfs.shand start-yarn.sh. This will start HDFS and YARN components. If you're only concerned with HDFS functionality, then running start-dfs.shis sufficient.
hdfs web management page parameter description
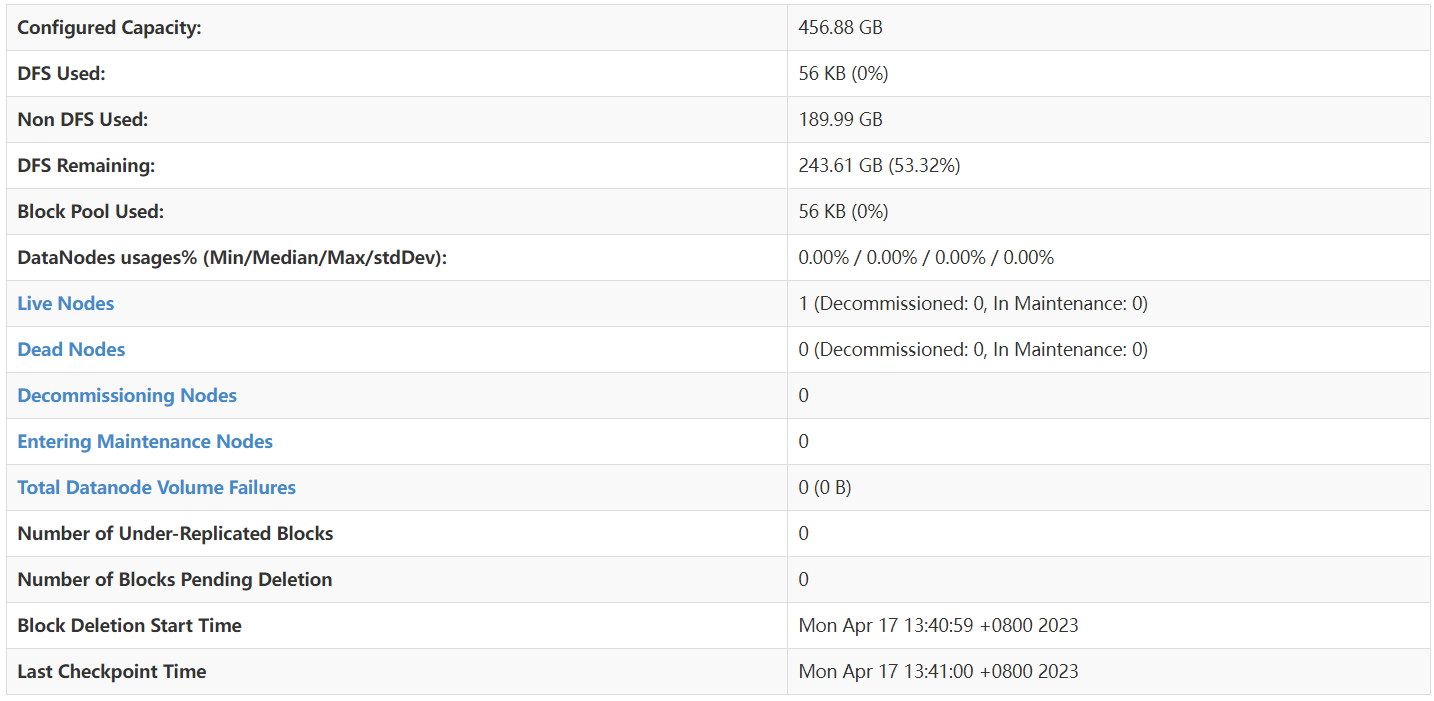
- Configured Capacity: The configured capacity is the total storage capacity of all DataNodes in the HDFS cluster . In this example, the configured capacity is 456.88 GB.
- DFS Used: The storage space used by DFS. This is the amount of data already stored in HDFS . In this example, 56 KB has been used.
- Non DFS Used: Non-DFS used storage space. This is storage space on the DataNode used for other purposes (non-HDFS) . In this example, non-DFS has used 189.99 GB.
- DFS Remaining: The remaining storage space of DFS. This is unused storage space in the HDFS cluster . In this example, 243.61 GB (53.32% of the configured capacity) remains.
- Block Pool Used: The storage space used by the block pool. This is the storage space in HDFS that has been allocated to the block pool. In this example, 56 KB has been used.
- DataNodes usages% (Min/Median/Max/stdDev): Statistics of DataNode usage, including min, median, max and standard deviation. In this example, all of these values are 0.00%.
- Live Nodes: The number of DataNodes currently running. In this example, there is 1 active DataNode (not decommissioned or under maintenance).
- Dead Nodes: The number of DataNodes that are currently unavailable or down. In this example, there are no dead DataNodes.
- Decommissioning Nodes: The number of DataNodes that are being decommissioned. In this example, there are no DataNodes being decommissioned.
- Entering Maintenance Nodes: The number of DataNodes that are entering the maintenance state. In this example, there are no DataNodes entering maintenance state.
- Total Datanode Volume Failures: The total number of datanode volume failures. In this example, data node disk failures are 0.
- Number of Under-Replicated Blocks: The number of blocks whose replica count is below the configured value. In this example, there are no replicas below the configured value.
- Number of Blocks Pending Deletion: The number of blocks to be deleted. In this example, there are no blocks to delete.
- Block Deletion Start Time: The time when block deletion started. In this example, block deletion started at 13:40:59 on April 17, 2023 (UTC+8).
- Last Checkpoint Time: The time of the last checkpoint. In this example, the most recent checkpoint occurred on April 17, 2023 at 13:41:00 (UTC+8).
Parameter Evaluation Scenario
- Cluster health monitoring: These parameters help to monitor the health of the HDFS cluster to ensure that the cluster is functioning properly . For example, by viewing the **"Live Nodes" and "Dead Nodes" parameters, you can know the running status of the data nodes**, so as to determine whether the cluster is running normally .
- Storage space management: Understanding storage space usage is critical to cluster management . For example, by looking at parameters such as " Configured Capacity ", " DFS Used ", " Non DFS Used " and " DFS Remaining ", you can understand the storage space usage of the cluster , so as to determine whether to expand or optimize storage space .
- Data Replication and Consistency Monitoring: Certain parameters help to assess the replication and consistency status of data . For example, " Number of Under-Replicated Blocks" indicates the number of blocks for which the number of replicas is below the configured value , which may lead to an increased risk of data loss . Monitoring these parameters helps ensure data reliability and consistency.
- Performance optimization: Some parameters can help understand the performance and load of the cluster , such as " DataNodes usages% ", through which you can understand the utilization of data nodes . This information helps optimize cluster configuration and improve cluster performance.
- Troubleshooting and Recovery: When a problem occurs, these parameters can help identify the cause of the problem. For example, the " Total Datanode Volume Failures " parameter represents the total number of datanode disk failures , which can lead to data loss or degraded cluster performance . Knowing these parameters can help in quickly diagnosing and resolving problems.