Originally this article was intended to be called "If I were a lottery system developer", but if you think about it, if you quote too much JavaScript in the article, it will not be so pure. After all, it is just my wishful thinking, and lottery development is not complete. As mentioned in this article, if it is misleading, it will not be worth the candle.
So it is simply called "The Truth of the Lottery Winning Rate: Using JavaScript to See Through the Random Algorithm Behind the Lottery" , which is a bit clearer. Let me declare that the real lottery system is not developed in this way, nor does it have obvious rules. We The fairness of the lottery should be trusted , even though it may not be based on randomness!
gossip
Recently, I have become obsessed with the lottery. I imagined that if I can get rich, I can also take my family to "ascension to heaven".
When I bought a lottery ticket, I also thought about it for a long time. What kind of numbers can stand out among the 17 million bets? I tried random numbers, carefully selected ones, and tried to find regular patterns. I even used crawlers to find them. The statistics are ridiculous!
Our default lottery system is based on statistics to achieve the first prize draw, so of course the first prize in history should be the bet with the lowest statistical rate in the current period, so, at the beginning, I thought this way:
-
Get all winning lottery numbers in history
-
Use the code to count the winning times of all numbers
-
Sort by the least likely number
-
Form some new numbers in turn
It's just a way to vent your desire to make money. It's not an exaggeration to call it whimsical. It's a lot of talk, haha!
I have already practiced the above idea, and it has been used for almost a year, but it is useless! do not use! Of course, you can also try, if you win, congratulations, you are the chosen one!
lottery rules
Our lottery rules here are unified using the rules of "two-color ball" to illustrate, and the rules for its purchase are as follows:
-
The red ball is six, the option is selected from 1 - 33, non-repeatable
-
The blue ball is one, and the options are selected from 1 - 16
-
A total of seven red and blue two-color balls form a bet
The first prize usually selects one bet among all the bets purchased. This bet may be bought by multiple people, or it may be a multiple of the bet bought by one person.
So roughly, the formula for calculating the odds of winning a lottery is as follows:
Use the combination number formula to calculate, the combination number formula nfor taking elements out of elements is:k
C(kn)=n!k!(n−k)!C\binomial{k}{n}=\frac{n!}{k!(nk)!}C(nk)=k!(n−k )!n!
According to the formula, we can easily write a simple algorithm:
function factorial(n) {
if (n === 0 || n === 1) {
return 1
} else {
return n * factorial(n - 1)
}
}
function combination(n, k) {
return factorial(n) / (factorial(k) * factorial(n - k))
}
console.log(combination(33, 6) * combination(16, 1)) // 17721088
复制代码
Therefore, it can be concluded that the odds of winning the double-color ball jackpot are: 117721088\frac{1}{17721088}177210881
The amount of data
Through the above algorithm, we know that the total number of bets in the lottery is 17721088, so how big is the data composed of so many bet numbers?
By simple calculation, a lottery note can be represented by 14 numbers. For example 01020304050607, in the operating system, the size of this string of numbers is 14B, and it is roughly known that if all lottery notes are in one file, then this The size of the file is:
const totalSize = 17721088 * 14 / 1024 / 1024 // 236.60205078125MB
复制代码
Terrible amount, is it possible to be smaller? Let's study the compression algorithm!
01This number occupies two bytes in memory, which is 2B. If we replace it 01 with lowercase a , then its capacity can become 1B, and the overall capacity can be reduced by about half!

In this way, our special bet number above 01020304050607 can be expressed as abcdefg !
This is the most basic principle of compression algorithm. There are many kinds of compression algorithms, which are roughly divided into lossy compression and lossless compression. For the content of our data class, we generally choose lossless compression!
-
Lossy compression algorithms: These algorithms can discard some information when compressing data, but usually achieve higher compression ratios without affecting actual use, the most common of which are image, audio, and video compression algorithms
-
Lossless compression algorithms: These algorithms do not discard any information, they achieve compression by looking for repeated patterns in the input data and using shorter symbols to represent them. Lossless compression algorithms are often used for text, code, configuration files and other types of data
First of all, let us prepare some test data first, we use the following simple combination number generation algorithm to get 1000 combination numbers:
function generateCombinations(arr, len, maxCount) {
let result = []
function generate(current, start) {
// 如果已经生成的组合数量达到了最大数量,则停止生成
if (result.length === maxCount) {
return
}
// 如果当前已经生成的组合长度等于指定长度,则表示已经生成了一种组合
if (current.length === len) {
result.push(current)
return
}
for (let i = start; i < arr.length; i++) {
current.push(arr[i])
generate([...current], i + 1)
current.pop()
}
}
generate([], 0)
return result
}
复制代码
Next, we need to generate 1000 double-color balls. Red balls are selected from 1-33, and blue balls are selected from 1-16.
function getDoubleColorBall(count) {
// 红球数组:['01', '02' .... '33']
const arrRed = Array.from({ length: 33 }, (_, index) => (index + 1).toString().padStart(2, '0'))
const arrRedResult = generateCombinations(arrRed, 6, count)
const result = []
let blue = 1
arrRedResult.forEach(line => {
result.push(line.join('') + (blue++).toString().padStart(2, '0'))
if (blue > 16) {
blue = 1
}
})
return result
}
复制代码
We put the acquired lottery content in a file for the next step:
const firstPrize = getDoubleColorBall(1000).join('')
fs.writeFileSync('./hello.txt', firstPrize)
复制代码
In this way, we get the first version of the file, which is its file size:
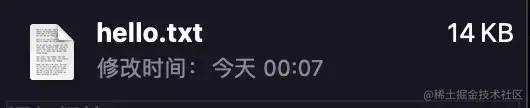
Try our preliminary compression algorithm. We will implement the rules just set, that is, the replacement of numbers to letters, with JavaScript, as follows:
function compressHello() {
const letters = 'abcdefghijklmnopqrstuvwxyzABCDEFG'
const doubleColorBallStr = getDoubleColorBall(1000).join('')
let resultStr = ''
for (let i = 0; i < doubleColorBallStr.length; i+=2) {
const number = doubleColorBallStr[i] + doubleColorBallStr[i+1]
resultStr += letters[parseInt(number) - 1]
}
return resultStr
}
const firstPrize = compressHello()
fs.writeFileSync('./hello-1.txt', firstPrize)
复制代码
In this way, we get a brand new hello file, whose size is as follows, which just confirms our idea!

If we follow this algorithm, we can compress the previous file to half the size, that is , but is this the limit? No, as we said above, this is just the most basic compression. Next, let's try a more subtle method! 118.301025390625MB
more subtle way
Here we do not explain the principle of the compression algorithm too much. If you are interested, you can find similar articles to read by yourself. Since the quality of the articles on the Internet is uneven, I will not recommend it!
What we need to understand here is that what we are studying is a lottery system, so its data compression should have the following characteristics:
-
It has the characteristics of no data loss, that is, lossless compression
-
The compression rate should be as small as possible, because the transferred files may be very large, as in the example we gave above
-
Facilitate the transmission of information, that is, support HTTP requests
Students who often work on the front end should know that a common parameter in the HTTP request header will also choose to convert resource files for distribution content-encoding: gzipin terms of project optimization . gzipIn daily use, we also often rely on WebpacklibrariesRollup such as , or nginx complete resource compression through a network server, which gzip not only greatly reduces the content to be sent, but also allows the client to decompress and access the source files without loss.
So, can we use gzip to complete the compression? The answer is yes, Node.js it provides us with zlib a tool library and a corresponding compression function:
const zlib = require('zlib')
const firstPrize = compressHello()
fs.writeFileSync('./hello-2.txt.gz', zlib.gzipSync(firstPrize))
复制代码
The result is:
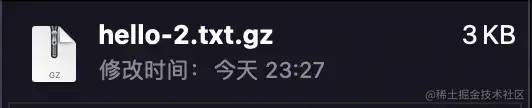
We've done a 14KB -> 3KB compression process! Isn't it interesting? But again, is it possible to be smaller? sure!
content-encoding The response header is generally the server's setting information for the resource response encoding format returned. There are three common values:
-
gzipUniversal compression format supported by all browsers -
brotliA new compression format withgzipbetter compression performance and smaller compression rate, which is not supported by old browsers -
deflateFor some reason, it is not widely used, and there is a compression format based on this algorithmzlib, but it is not used very much
The compression formats supported by browsers are not limited to these, but we have listed the more commonly used ones. Let’s try to use these three compression formats:
const firstPrize = compressHello()
fs.writeFileSync('./hello-2.txt.gz', zlib.gzipSync(firstPrize))
fs.writeFileSync('./hello-2.txt.def', zlib.deflateSync(firstPrize))
fs.writeFileSync('./hello-2.txt.br', zlib.brotliCompressSync(firstPrize))
复制代码
We can see that the compression rate of deflate and gzip is comparable, and surprisingly, brotlithe compression of and has reached an astonishing 1KB! Isn't this what we want?

Could it be smaller? Hahahaha, of course, if HTTP support is not considered, we can use a 7-zip compression algorithm with a lower compression rate to complete the compression, and then use the client to do manual decompression. But so far, we have not done more important work!
Before that, we need to understand the decompression process first. If the data is lost after decompression, then the loss outweighs the gain!
// 执行解压操作
const brFile = fs.readFileSync('./hello-2.txt.br')
const gzipFile = fs.readFileSync('./hello-2.txt.gz')
const deflateFile = fs.readFileSync('./hello-2.txt.def')
const brFileStr = zlib.brotliDecompressSync(brFile).toString()
const gzipFileStr = zlib.gunzipSync(gzipFile).toString()
const deflateFileStr = zlib.inflateSync(deflateFile).toString()
console.log(brFileStr)
console.log(gzipFileStr)
console.log(deflateFileStr)
console.log(brFileStr === gzipFileStr, brFileStr === deflateFileStr) // true, true
复制代码
As above, we know that although the effect of the compression algorithm is amazing, the decompressed data is still lossless!
complete data
Let us build a complete 17721088 note data to test the ability of the complete compression algorithm? Here we use brotli the and gzip algorithms to perform compression tests separately!
First, the function we generate data should be modified as follows:
function generateAll() {
const arrRed = Array.from({ length: 33 }, (_, index) => (index + 1).toString().padStart(2, '0'))
const arrRedResult = generateCombinations(arrRed, 6, Number.MAX_VALUE)
const result = []
arrRedResult.forEach(line => {
for (let i = 1; i <= 16; i++) {
result.push(line.join('') + i.toString().padStart(2, '0'))
}
})
return result
}
console.log(generateAll().length) // 17721088
复制代码
Next we go through the initial compression and write it to a file:
function compressAll() {
const letters = 'abcdefghijklmnopqrstuvwxyzABCDEFG'
const allStr = generateAll().join('')
let resultStr = ''
for (let i = 0; i < allStr.length; i += 2) {
const number = allStr[i] + allStr[i+1]
resultStr += letters[parseInt(number) - 1]
}
return resultStr
}
const firstPrize = compressAll()
fs.writeFileSync('./all-ball.txt', firstPrize)
复制代码
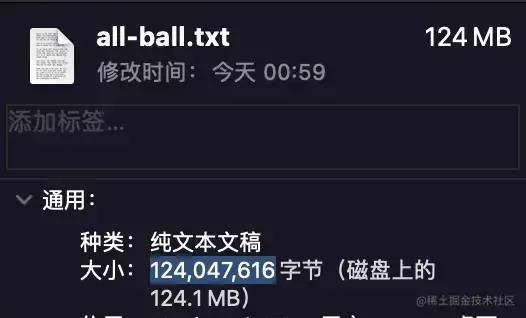
As we expected, after preliminary compression, the file size has reached about 118MB, but its actual occupation is 124MB, which belongs to the category of computer storage. We will not discuss it in this article. Interested students can check it by themselves. According to Calculated in bytes, its size is:
const totalSize = 124047616 / 1024 / 1024 // 118.30102539 MB
复制代码
At present, it is in line with expectations. Let's take a look at the real skills of the two compression algorithms!
const firstPrize = compressAll()
fs.writeFileSync('./all-ball.txt.gz', zlib.gzipSync(firstPrize))
fs.writeFileSync('./all-ball.txt.br', zlib.brotliCompressSync(firstPrize))
复制代码

In fact, it was a shocking thing. Although my brotli expectations were high enough, I would not have thought that it could be compressed to a size of only 4M, but for us, this is a blessing, and it has a huge advantage for subsequent distribution operations !
two random bets
Random double bets are very common when buying lottery tickets from lottery stations, but what happens when you try random numbers?
Let's start with the distribution of lottery data. First of all, the design of the security and stability of the distribution of lottery data is definitely beyond doubt, but this is not a problem we need to consider at present. What we should solve at present is that if we can achieve a lower degree control costs!
Assuming that you are the one who designed this system, if you control the winning rate of random numbers? My answer is to choose from the existing pool of numbers!
If each lottery station can obtain its corresponding number pool, answer: data distribution! If the data distribution mode is adopted, the issues to be considered are as follows:
-
when to distribute
-
How to do data back-to-source
-
How to Avoid All Data Hijacking
-
The strategy of handing over the data to the lottery station
According to public information in 2021, the number of lottery stations has reached 200,000 (unverified, no reference value), we assume that the current number of lottery stations is 300,000!
when to distribute
What we know is that the deadline for purchasing lottery tickets is at 8:00 p.m., and the drawing time is at 9:15 p.m. Starting at eight o'clock, the plan is as follows:
-
From the current lottery library, arrange the numbers according to the probability of occurrence from high to low
-
The first 500,000 bets are selected and distributed to 300,000 lottery stations. The data of the lottery stations at this time is unified
-
The data is synchronized every hour, which is "specially selected data" of other lottery stations
How big is the data volume of 500,000 notes? Try it out:
function getFirstSend() {
const letters = 'abcdefghijklmnopqrstuvwxyzABCDEFG'
const doubleColorBallStr = getDoubleColorBall(500000).join('')
let resultStr = ''
for (let i = 0; i < doubleColorBallStr.length; i+=2) {
const number = doubleColorBallStr[i] + doubleColorBallStr[i+1]
resultStr += letters[parseInt(number) - 1]
}
return resultStr
}
const firstPrize = getFirstSend()
fs.writeFileSync('./first-send.txt.br', zlib.brotliCompressSync(firstPrize))
复制代码

The size of only one picture, it takes less than 1 second to obtain these data, decompress and synchronize them to the lottery machine!
An example of decompression is as follows:
function decodeData(brFile) {
const result = []
const content = zlib.brotliDecompressSync(brFile)
// 按照七位每注的结构拆分
for (let i = 0; i < content.length; i += 7) {
result.push(content.slice(i, i + 8))
}
return result
}
const firstSend = fs.readFileSync('./first-send.txt.br')
const firstDataList = decodeData(firstSend)
console.log(firstDataList.length) // 500000
复制代码
How to convert the obtained lottery tickets in the form of characters into numbers, such abcdefga as ['01', '02', '03', '04', '05', '06, '01']:
function letterToCode(letterStr) {
const result = []
const letters = 'abcdefghijklmnopqrstuvwxyzABCDEFG'
for (let i = 0; i < letterStr.length; i++) {
result.push((letters.indexOf(letterStr[i]) + 1).toString().padStart(2, '0'))
}
return result
}
复制代码
As for distribution? We can refer to some existing concepts on the market for comparison. The following is a general estimate of the TPS of a web server, that is to say, the maximum number of requests that the lottery server can handle within 1 second:
-
Low performance: TPS below 50, suitable for low-traffic application scenarios, such as personal blogs, small business websites, etc.
-
Medium performance: TPS is between 50 and 500, suitable for general websites and application scenarios, such as small and medium-sized e-commerce websites, social networks, etc.
-
High performance: TPS is between 500~5000, suitable for high-traffic websites and application scenarios, such as large e-commerce websites, game websites, etc.
-
Ultra-high performance: TPS is above 5000, suitable for ultra-high-traffic websites and application scenarios, such as websites of Internet giants, online games, etc.
According to this model, the data synchronization of the 500,000 lottery station can be completed within 100 seconds. Of course, everyone, this is a stand-alone mode. If you want to do a lottery service, stand-alone is definitely impossible. If you want to improve TPS, then Just do a server cluster. If there are 100 server clusters, it only takes 1 second to process these requests! (Are you willful? Of course you can be willful if you have money!) (These data are based on theory and do not provide reference value)
How to do data back-to-source
very simple! What kind of data do we need to obtain? The lottery data purchased directly without random algorithm! That is, those old lottery players who "keep their numbers" that we often hear!
Similarly, according to media inquiries (not for reference), the passenger flow of the lottery station is 1 to 10 people per hour, and the operating hours are from 9:00 am to 9:00 pm. The maximum passenger flow is expected to be 100 people per day!
Then the total passenger flow of all lottery stations is 100 * 500000 = 50000000, which is about 50 million person-times, about 50% of which belong to "number keepers". It may be necessary to exclude the known numbers in lottery stations, but Here we do not deal with it first, but make all estimates first, then
The maximum TPS that the server needs to carry is:
// 服务器集群数量
const machineCount = 100
// 总访问量,50%中的号码才会上报
const totalVisit = 50000000 * 0.5 // 25000000
// 总的时间,因为我们计算的是 10个小时的时间,所以应该计算的总秒数为 36000 秒!
const totalSeconds = 10 * 60 * 60
console.log(totalVisit / totalSeconds / machineCount) // 6.944444444444445
复制代码
TPS is only 7 ! ! This still does not rule out the already known number. For the specific reporting logic, refer to the following figure:
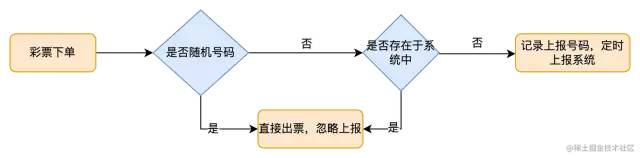
The strategy of handing over the data to the lottery station (to avoid data hijacking)
Of course, all the lottery data cannot be handed over to the lottery station. We need to layer all the data. The "data specially selected" by other lottery stations is the data we want to distribute hierarchically! This will also solve the problem of "how to avoid all data being hijacked" !
So how do we layer the data?
In short, we synchronize the ticket purchase information of Xi'an lottery station in Shaanxi to Taiyuan, Shanxi, and the ticket purchase information of Shanghai to Suzhou, Jiangsu! Of course, there are many points to consider, not only the exchange of data between the two places, but also the logic is more complicated. Usually, the points to be considered are:
-
Data synchronization is difficult, cross-regional synchronization puts great pressure on the server, such as synchronization from South China to North China
-
The degree of data similarity, if the historical similarity of the data of the two places is very different, it will not be able to achieve the purpose of coverage, because we ultimately want this bet number to be purchased more times
-
Data synchronization time difference, such as Xinjiang and other places, due to network problems, is much slower than other places, so numbers will be missed, then the data of these places should be synchronized to more prosperous areas, such as Shanghai, but this It seems to be contrary to the first two points
That's all I've said, and I don't really understand if I talk too much. Or I haven't figured it out yet, if there is a big guy who is more powerful in this area, he can provide ideas! Let's see how the random number turns out:
Let's try to randomly get the two bets you need:
function random(count) {
let result = []
for (let i = 0; i < count; i++) {
const index = Math.floor(Math.random() * firstDataList.length)
console.log(firstDataList[index])
result.push(letterToCode(firstDataList[index]))
}
return result
}
console.log(random(2))
复制代码
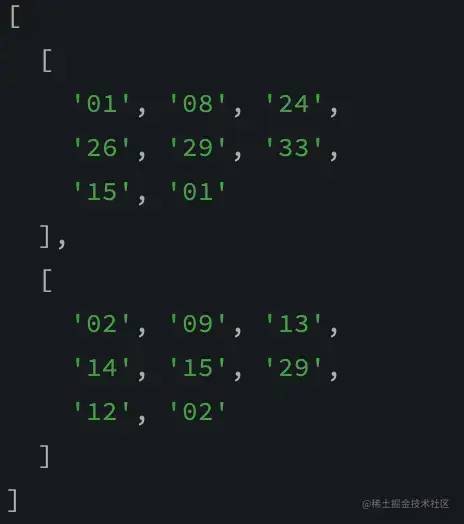
OK, do you think you can win the lottery? Hahaha, it's still possible, keep reading!
Deliberately picked two bets
I am a typical "number keeper" person. Every day I buy a lottery ticket with a few numbers I calculated by myself. Can I win the lottery? (Currently not selected)
According to the above description, we should know that the number purchased by the "number keeper" needs to judge whether there is data in the system. If it exists, the report will not be triggered. If the data does not exist, it will be reported to the system, and the system will distribute the current number. For adjacent cities or cities with similar data, it is expected that the current number can be purchased by more people. If more numbers are purchased, the probability of winning the prize will be lower!
However, the probability of winning a lottery is higher if you choose it deliberately than if you choose it randomly, but it is not much higher.
I want first prize
The first prize of the lottery is based on statistics. Even if there are empty numbers in the lottery center, the number of second to sixth prizes generated by the empty numbers needs to be considered. This is a very large amount of data and requires a lot of calculations. Time, so how do we simulate it?
Let's take 500,000 lottery tickets and simulate the situation when these lottery tickets are purchased. There may be empty numbers, repeated purchases, or multiple purchases, etc. Try to calculate the total amount we need to pay!
The winning rules of the lottery are as follows. We will not consider the floating prizes for the time being, and give fixed amounts to both the first prize and the second prize:
-
6 + 1 first prize bonus of 5 million
-
6 + 0 second prize bonus of 300,000
-
5 + 1 third prize bonus of 3000 yuan
-
5 + 0 or 4 + 1 The fourth prize bonus is 200 yuan
-
4 + 0 or 3 + 1 The fifth prize bonus is 10 yuan
-
2 + 1 or 1 + 1 or 0 + 1 is the sixth prize bonus of 5 yuan
According to this rule, we can first write the function of reward:
/**
* @param {String[]} target ['01', '02', '03', '04', '05', '06', '07']
* @param {String[]} origin ['01', '02', '03', '04', '05', '06', '07']
* @returns {Number} 返回当前彩票的中奖金额
*/
function compareToMoney(target, origin) {
let money = 0
let rightMatched = target[6] === origin[6]
// 求左边六位的交集数量
let leftMatchCount = target.slice(0, 6).filter(
c => origin.slice(0,6).includes(c)
).length
if (leftMatchCount === 6 && rightMatched) {
money += 5000000
} else if (leftMatchCount === 6 && !rightMatched) {
money += 300000
} else if (leftMatchCount === 5 && rightMatched) {
money += 3000
} else if (leftMatchCount === 5 && !rightMatched) {
money += 200
} else if (leftMatchCount === 4 && rightMatched) {
money += 200
} else if (leftMatchCount === 4 && !rightMatched) {
money += 10
} else if (leftMatchCount === 3 && rightMatched) {
money += 10
} else if (leftMatchCount === 2 && rightMatched) {
money += 5
} else if (leftMatchCount === 1 && rightMatched) {
money += 5
} else if (rightMatched) {
money += 5
}
return money
}
复制代码
So, how to maximize the benefits, the steps should be like this:
-
Randomly generate a set of winning numbers
-
For each purchased number, check if it matches the winning number and calculate its bonus amount
-
Sum the bonus amounts for all purchased numbers
-
Repeat this process until the optimal winning number is found
The random winning number is very important. It determines the speed at which we can calculate the overall data, so we follow the steps below to obtain it:
-
Sort all the numbers according to the number of purchases (in fact, the real scene here should consider the distribution trend of the winning numbers to be more accurate)
-
Start the query from the empty number, and perform calculations sequentially
First simulate our purchase data:
function getRandomCode(count = 500000) {
const arrRed = Array.from({ length: 33 }, (_, index) => (index + 1).toString().padStart(2, '0'))
// generateCombinations 是我们上面定义过的函数
const arrRedResult = generateCombinations(arrRed, 6, count)
const result = []
let blue = 1
arrRedResult.forEach(line => {
result.push([...line, (blue++).toString().padStart(2, '0')])
if (blue > 16) {
blue = 1
}
})
return result
}
function randomPurchase() {
const codes = getRandomCode()
const result = []
for (let code of codes) {
let count = Math.floor(Math.random() * 50)
result.push({
code,
count,
})
}
return result
}
console.log(randomPurchase())
复制代码
We will get a data structure similar to the following, which is convenient for statistics:
[
{
code: [
'01', '02',
'03', '04',
'05', '10',
'05'
],
count: 17
},
{
code: [
'01', '02',
'03', '04',
'05', '11',
'06'
],
count: 4
}
]
复制代码
Next, it is very simple statistics, the logic is very simple, but for the lottery with a huge amount of data, it takes time!
// 空号在前,购买数量越多越靠后
const purchaseList = randomPurchase().sort((a, b) => a.count - b.count)
const bonusPool = []
for (let i = 0; i < purchaseList.length; i++) {
// 假设这就是一等奖,那么就需要计算其价值
const firstPrize = purchaseList[0]
let totalMoney = 0
for (let j = 0; j < purchaseList.length; j++) {
// 与一等奖进行对比,对比规则是参照彩票中奖规则
const money = compareToMoney(purchaseList[j].code, firstPrize.code) * purchaseList[j].count
totalMoney += money
}
bonusPool.push({
code: firstPrize.code,
totalMoney,
})
}
const result = bonusPool.sort((a, b) => a.totalMoney - b.totalMoney)
// 至于怎么挑,那就随心所欲了
console.log(result[0].code, result[0].totalMoney)
复制代码
As for how to choose the final first prize, you can do whatever you want, but the above algorithm takes nearly 10 minutes to calculate on my M1 chip. If there is a more powerful machine and a more powerful algorithm, this time can also be shortened. Don't start, I'm tired, so be it!
Huangliang a dream
After all, it is a dream of Huangliang, and in the end I have to return to life and work hard! But who knows, how about buying another bet later?
The lottery system is purely speculative and there can be no similarities!