6. Time and windows in Flink
6.1, time semantics
6.1.1. Time Semantics in Flink
Flink is a distributed processing system. The biggest feature of the distributed architecture is that the nodes are independent of each other and do not affect each other, which brings higher throughput and fault tolerance.
But there are advantages and disadvantages. In a distributed system, nodes "do their own thing" and there is no unified clock. Data and control information are transmitted through the network. For example, now there is a task of window aggregation, and we hope to collect the data of each hour for statistical processing. For parallel window subtasks, the system time will be different because of the different nodes they are located in; when we want to count the data from 8 o'clock to 9 o'clock, it is not "simultaneous" for parallel tasks, the collected data There will also be errors.
Since there is a JobManager as a manager in a cluster, should it be enough to send a synchronous clock signal to all TaskManagers uniformly? This is also not acceptable. Because the network transmission will be delayed, and this delay is uncertain, the synchronization signal sent by the JobManager cannot reach all nodes at the same time; it is impossible to have a globally unified clock in a distributed system.
Another troublesome problem is that in the process of stream processing, data is constantly flowing between different nodes, which also causes delays in network transmission. In this way, when upstream and downstream tasks need to transfer data across nodes, their understanding of "time" will also be different. For example, the upstream task sends out a piece of data at 8:59:59, and it is already 9:01 seconds when the window calculation is done downstream. Should this data be received in the window of 8:00 to 9:00? ? Therefore, when we want to collect and calculate data according to the time window, it is very important who is the standard for "time".
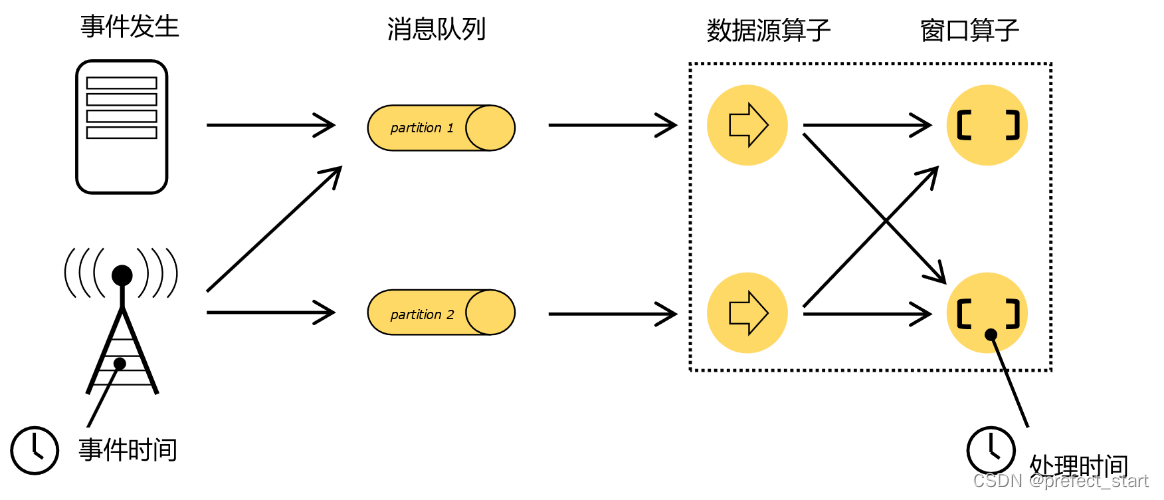
As shown in the figure above, after an event occurs, the generated data is collected, first enters the distributed message queue, and then is read and consumed by the source operator in the Flink system, and then passed to the downstream conversion operator (window operator) , and finally calculated by the window operator.
There are two very important time points here: one is the time when the data is generated, we call it "Event Time" (Event Time); the other is the moment when the data is actually processed, called "Processing Time" (Processing Time) ).
The window operation we define is based on the time as a measure, which is the so-called "Notions of Time". Due to the delay of network transmission and clock drift in distributed systems, the processing time will lag behind the time of event occurrence.
6.1.1.1, Processing Time (Processing Time)
The concept of processing time is very simple, it refers to the system time of the machine performing the processing operation.
If we use it as a measure, it is obvious which window the data belongs to: just look at the current system time when the window task processes this data. For example, in the previous example, the data is generated at 8:59:59, and the window calculation time is 9:01 seconds, then this piece of data belongs to the window from 9:00 to 10:00; if the data transmission is very fast, 9:00 The window task has been reached before, so it belongs to the 8:00-9:00 window. Each parallel window subtask only divides the window according to its own system clock. If we start the program at 8:10 in the morning, then all data processed until 9:00 will belong to the first window; all data after 9:00 and before 10:00 will belong to the second window. This method is very simple and rude, and does not require coordination and synchronization between nodes, nor does it need to consider the position of data in the stream, so processing time is the simplest time semantics.
6.1.1.2, Event Time (Event Time)
Event time refers to the time when each event occurs on the corresponding device, that is, the time when data is generated.
Once the data is generated, the time is naturally determined, so it can be embedded in the data as an attribute. This is actually the "timestamp" (Timestamp) of this data record. Under the event time semantics, we don't look at the system time of any machine for the measurement of time, but rely on the data itself. For example, this is equivalent to not having a clock when processing tasks, so you have to ask "what time is it now" when you come to a piece of data; and the data itself has no table, only a built-in "factory time", The task then
determines its own clock based on this time. Since the data in stream processing is continuously generated, generally speaking, the data generated first will be processed first, so when tasks continue to receive data, their timestamps are basically continuously increasing, and you can Represents the advancement of time.
6.1.2 Which time semantics is more important
In computer systems, it is meaningless to consider the "time change" of data processing. What we care more about is obviously the time when the data itself was generated.
For example, we calculate the PV, UV and other indicators of the website, and we need to count the daily visits. If a user has a visit at 23:59:59, but the time for our task to process this data is already 0:00:01 the next day; then this data should be counted as the visit of the day , or the next day's visit? Obviously, to count user behavior, we need to consider the time when the behavior itself occurred, so we should count this data into the traffic of the day. The window we use at this time is based on event time as the division standard, and has nothing to do with processing time.
So in practical applications, event time semantics will be more common. In general, the business log data will record the timestamp of data generation, which can be used as the basis for judging the event time.
In a distributed environment, the processing time is actually uncertain, and the clocks of each parallel task are not uniform; and due to network delays, the time for data to reach each operator task varies, and the correct data may not be collected for window operations. If the data is corrupted, the order of data processing will also be disrupted. This will affect the correctness of the calculation results. Therefore, processing time semantics is generally used in scenarios that have extremely high requirements for real-time performance but not high requirements for calculation accuracy.
Under the event time semantics, the water level becomes a clock, which can uniformly control the progress of time. This ensures that we can always divide the data into the correct window, such as the data generated at 8:59:59, no matter what the delay in network transmission is, it will always belong to the window from 8:00 to 9:00, and will not be misclassified . But we know that the data may be out of sequence. If we want the window to collect all the data correctly, we must wait for all the disordered data to arrive, which requires a certain amount of waiting time. So on the whole, event time semantics is at the cost of a certain delay in exchange for the correctness of the processing results. Since the network delay is generally only milliseconds, even the event time semantics can also complete the task of low-latency real-time stream processing.
In addition, in addition to event time and processing time, Flink also has a concept of "Ingestion Time", which refers to the time when data enters the Flink data stream, that is, the time when the Source operator reads the data. Ingestion time is equivalent to a neutralization of event time and processing time. It adds the processing time of the Source task to the data as the generation time of the data. In this way, the watermark is directly generated based on this time and does not need to be specified separately. This time semantics can guarantee better correctness without introducing too much delay. Its specific behavior is very similar to event time and can be treated as a special event time.
6.2. Watermark
6.2.1, event time and window
The moment when a piece of data is generated is the time point when an event is triggered in stream processing. This is the "event time", which is generally recorded in the data as a field in the form of a timestamp. If we want to count the data for a period of time, we need to divide the time window. At this time, we only need to judge the timestamp to know which window the data belongs to.
The window to which a data belongs has been clarified, but it cannot be directly calculated. Because the window deals with bounded data, we need to wait for all the data in the window to arrive before we can calculate the final statistical result. When will the data be available? For time windows this is obvious: at the end of the window, all data should naturally be collected and the output of the calculation can be triggered. For example, if we want to count the number of user clicks from 8:00 to 9:00, we start collecting data from 8:00 and end at 9:00, and process and calculate the collected data.
Under the processing time semantics, the system time of the node where the current task is located shall prevail. This method is simple, crude and easy to implement. In a distributed environment, this will lead to errors due to the uncertainty of network transmission delay.
Under processing time semantics, we actually customize a "logical clock" based on the timestamp of the data. The time of this clock does not pass automatically; its time progress is driven by the timestamp of the newly arrived data. The advantage of this is that the calculation process does not depend on the processing time (system time) at all, and the results obtained are correct whenever statistical processing is performed.
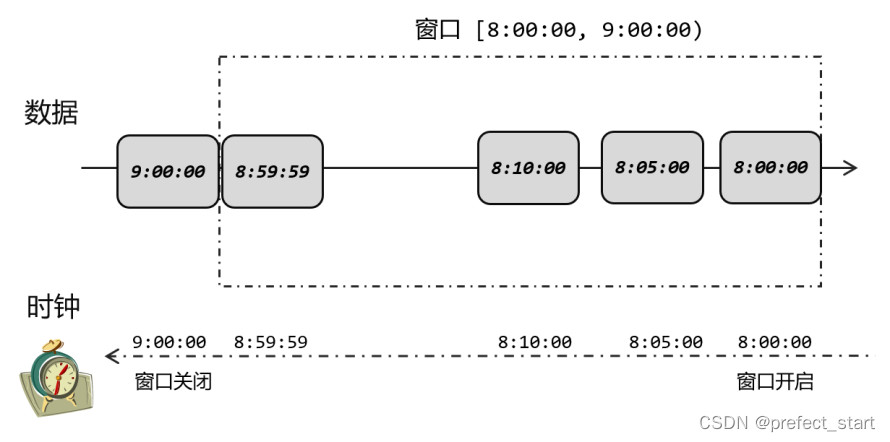
We can think of it this way: under normal circumstances, after the product is produced, it will be sent to the car immediately; so the time when the product arrives on the car (system time) should be slightly behind the production time of the product (data timestamp). If we don't consider a little delay in the transmission process, we can directly use the product production time to represent the current time on the car. As shown in the figure below, the production time of the product arriving on the vehicle is
8:05, so the current time on the vehicle is 8:05; another product produced at 8:10 comes, and the current time on the vehicle is 8 10 points. We directly use the timestamp of the data to indicate the current time progress, and the closing of the window is naturally based on the timestamp of the data being equal to the end time of the window, which is equivalent to not being affected by network transmission delays. As mentioned before, the products produced at 8:59:59, no matter what time the actual time (system time) is when they arrive in the car, we think it is currently 8:59:59, so it can always catch up As for the 9 o'clock bus, the train will not officially start until the products produced at 9 o'clock arrive. In this way, correct statistical results can be obtained.
6.2.2. What is the water level line
Under the event time semantics, we do not rely on the system time, but define a clock based on the timestamp of the data to represent the progress of the current time. Therefore, each parallel subtask will have its own logical clock, and its progress is driven by the timestamp of the data.
But in a distributed system, this driving method has some problems. Because the data itself will change during the process of processing and conversion, if you encounter an operation such as window aggregation, you actually need to accumulate a batch of data before outputting a result, then the downstream data will be less, and the control of the time schedule will not be fine enough up. In addition, when data is passed to downstream tasks, it can generally only be transmitted to one subtask (except broadcast), so that the clocks of other parallel subtasks cannot be advanced. For example, if a data with a time stamp of 9 o'clock arrives, the clock of the current task is already 9 o'clock; after processing the current data, it must be sent to the downstream. If the downstream task is a window calculation with a parallelism of 3, then the data is received For the subtasks, the clock will progress to 9 o'clock, and the window at 9 o'clock can be closed for calculation; while the other two parallel subtasks have no change in time, and window calculation cannot be performed.
Therefore, we should also pass the clock in the form of data to tell downstream tasks the progress of the current time; and the transmission of this clock will not be stagnant due to operations such as window aggregation. A simple idea is to add a clock mark to the data stream to record the current event time; this mark can be directly broadcast to the downstream, and when the downstream task receives this mark, it can update its own clock.
Because it is similar to the mark used as a mark in water flow, in Flink, this mark used to measure the progress of event time (Event Time) is called "Watermark". In terms of specific implementation, the water level can be regarded as a special data record, which is a mark point inserted into the data stream, and its main content is a timestamp, which is used to indicate the current event time. The position where it is inserted into the stream should be after a certain data arrives; in this way, the timestamp can be extracted from this data as the timestamp of the current water level.
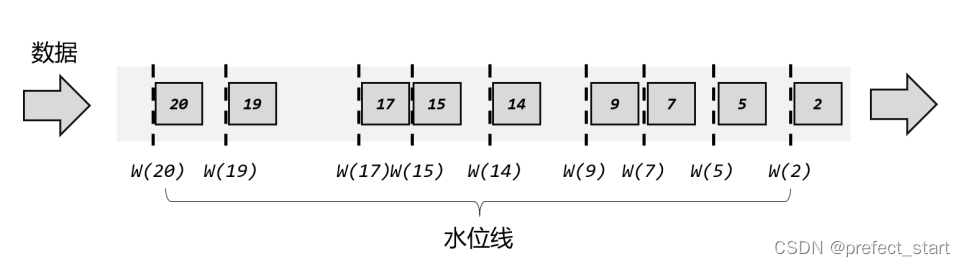
As shown in the figure above, the data generated by each event contains a timestamp, which we directly represent with an integer. There is no specified unit here, which can be understood as seconds or milliseconds (for convenience, it is uniformly considered as seconds). When the data generated in 2 seconds arrives, the current event time is 2 seconds; a watermark with a time stamp of 2 seconds is also inserted in the back, and flows downstream together with the data. And when the data generated in 5 seconds arrives, a water level line is also inserted in the back, and the timestamp is also 5, and the current clock advances to 5 seconds. In this way, if there are multiple parallel subtasks downstream, we can notify the current time progress of all downstream tasks as long as we broadcast the water level. As its name suggests, the watermark is a part of the data flow, which flows with the data and is transmitted between different tasks.
6.2.2.1. Water level in ordered flow
Ideally, data should be queued into the stream in the order in which they were generated; that is, they will be processed in the same order as they were originally processed, on a first-come, first-served basis. In this way, we extract the timestamp from each data, which can be guaranteed to always grow from small to large, so the inserted water level will also continue to grow, and the event clock will continue to advance.
In practical applications, if the current data volume is very large, there may be many data with the same timestamp. At this time, extracting the timestamp and inserting the watermark for each piece of data will do a lot of useless work. And even if the timestamps are different, the time difference between the data coming in at the same time will be very small (for example, a few milliseconds), and it often has no effect on the processing calculation. Therefore, in order to improve efficiency, a water level is generally generated at regular intervals. The timestamp of this water level is the timestamp of the latest current data, as shown in the figure below. So the water level at this time is actually a time mark that appears periodically in the orderly flow.

It should be noted here that the "period" of water level insertion is itself a concept of time. Under the current event time semantics, if we set the water level to be generated every 100ms, the water level is generated periodically, and the cycle time refers to the processing time (system time), not the event time.
6.2.2.2. Water level in disordered flow
The processing of ordered streams is very simple, and it seems that the water level does not play a big role. But this situation only exists in an ideal state. We know that in a distributed system, when data is transmitted between nodes, the order will change due to the uncertainty of network transmission delay. This is the so-called "out-of-order data".
The "out-of-order" mentioned here refers to the inconsistent order of data, mainly based on the generation time of data. As shown in the figure below, the data generated at 7 seconds is naturally generated earlier than the data at 9 seconds; but after data caching and transmission, the processing task may receive the data at 9 seconds first, and the data at 7 seconds later Long overdue. At this time, if we want to insert a water level to indicate the progress of the current event time, what should we do?

The most intuitive idea is naturally the same as before. We are still driven by data. Every time a piece of data comes, we extract its timestamp and insert a water level. However, the current situation is that the data is out of order, so it is possible that the new timestamp is smaller than the previous one. When inserting a new water level, you must first determine whether the timestamp is larger than the previous one, otherwise no new water level will be generated. line, as shown in the figure below. That is to say, only when the time stamp of the data is greater than the current clock can the clock be pushed forward, and then the watermark is inserted.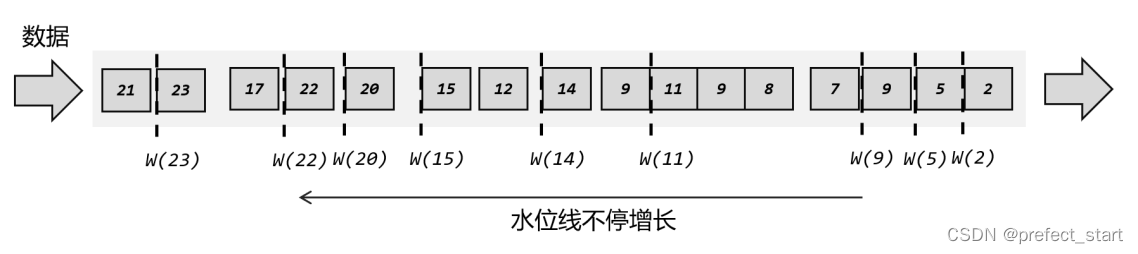
If we consider the processing efficiency of a large amount of data arriving at the same time, we can also periodically generate the water level. At this time, you only need to save the largest time stamp in all the previous data. When you need to insert the water level, you can directly use it as the time stamp to generate a new water level, as shown in the figure below.

Although this can define an event clock, it will also bring a very big problem: we cannot correctly handle "late" data.
In the above example, when the data generated in 9 seconds arrives, we directly advance the clock to 9 seconds; if there is a window with an end time of 9 seconds (for example, to count all data from 0 to 9 seconds), then this The time window should be closed, and all the collected data will be calculated and output. But in fact, because the data is out of order, there may be data with a timestamp of 7 seconds and 8 seconds arriving after the data of 9 seconds. This is "late data".
They should also belong to the window of 0~9 seconds, but at this time the window has been closed, so these data are omitted, which will lead to incorrect statistical results.
In order for the window to correctly collect late data, you can wait for n seconds, that is, subtract n (2) seconds from the maximum timestamp of the current existing data, which is the timestamp of the water level to be inserted, as shown in the figure below . In this case, after the 9-second data arrives, the event clock will not advance directly to 9 seconds, but will progress to 7 seconds; the event clock will not progress to 9 seconds until the 11-second data arrives, and the late data will also advance to 9 seconds. All have been collected, and the results can be calculated correctly in the window of 0~9 seconds. n is a general term, and the specific time can be determined according to the time frequency of business data.

6.2.2.3. Characteristics of water level line
The watermark represents the current event time clock, and some delay can be added to the timestamp of the data to ensure that no data is lost, which is very important for the correct processing of out-of-order streams.
Features of watermarks:
- The water level is a mark inserted into the data stream, which can be considered as a special data
- The main content of the water level is a timestamp, which is used to represent the progress of the current event time
- Watermarks are generated based on the timestamp of the data
- The watermark's timestamp must be monotonically increasing to ensure that the task's event-time clock keeps advancing
- The water level can ensure correct processing of out-of-order data by setting a delay
- A watermark (Watermark(t), indicating that the event time in the current stream has reached the timestamp t, which means that all the data before t has arrived, and no data with a timestamp t' ≤ t will appear in the stream afterwards
6.2.3. How to generate the water level line
6.2.3.1. The general principle of generating the water level line
The perfect water level is "absolutely correct", that is, once a water level appears, it means that all the data before this time has arrived, and it will never appear again. But the perfect water level is ideal. In reality, we try our best to ensure that the water level is correct.
- If we want the calculation results to be more accurate, we can set the delay of the water level higher. The longer the waiting time, the less likely it is to miss data. However, the cost of doing this is that the real-time performance of the processing is reduced, and we may add a lot of unnecessary delay to the very small number of late data.
- If we want to process faster and more real-time, we can set the watermark delay lower. In this case, a lot of late data may arrive after the water level, which will cause the window to miss data and the calculation result will be inaccurate.
6.2.3.2. Watermark Strategies
In Flink's DataStream API, there is a separate method for generating watermarks: .assignTimestampsAndWatermarks(), which is mainly used to assign timestamps to data in the stream and generate watermarks to indicate event time:
public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks(
WatermarkStrategy<T> watermarkStrategy)
In specific use, just use DataStream to call this method directly, which is exactly the same as the ordinary transform method.
DataStream<Event> stream = env.addSource(new ClickSource());
DataStream<Event> withTimestampsAndWatermarks =
stream.assignTimestampsAndWatermarks(<watermark strategy>);
The .assignTimestampsAndWatermarks() method needs to pass in a WatermarkStrategy as a parameter, which is the so-called "watermark generation strategy". WatermarkStrategy contains a "Timestamp Assigner" TimestampAssigner and a "Watermark Generator" WatermarkGenerator.
public interface WatermarkStrategy<T> extends TimestampAssignerSupplier<T>,
WatermarkGeneratorSupplier<T>{
@Override
TimestampAssigner<T>
createTimestampAssigner(TimestampAssignerSupplier.Context context);
@Override
WatermarkGenerator<T>
createWatermarkGenerator(WatermarkGeneratorSupplier.Context context);
}
- TimestampAssigner: It is mainly responsible for extracting the timestamp from a field of the data element in the stream and assigning it to the element. The assignment of timestamps is the basis for generating watermarks.
- WatermarkGenerator: It is mainly responsible for generating watermarks based on timestamps in a predetermined way. In the WatermarkGenerator interface, there are two main methods: onEvent() and onPeriodicEmit().
- onEvent: A method that will be called when each event (data) arrives. Its parameters include the current event, timestamp, and a WatermarkOutput that allows the water level to be issued. Various operations can be performed based on the event.
- onPeriodicEmit: A method called periodically, which can emit watermarks from WatermarkOutput. The cycle time is the processing time, which can be set by calling the .setAutoWatermarkInterval() method of the environment configuration, and the default is 200ms.
env.getConfig().setAutoWatermarkInterval(60 * 1000L);
6.2.3.3, Flink built-in water level generator
Flink provides a built-in watermark generator (WatermarkGenerator), which not only simplifies programming out of the box, but also provides a template for our custom watermark strategy. These two generators can be created by calling static helper methods of WatermarkStrategy. They all generate water levels periodically, corresponding to the scenarios of processing ordered flow and disordered flow respectively.
6.2.3.3.1, ordered flow
For ordered streams, the main feature is 时间戳单调增长(Monotonously Increasing Timestamps), so there will never be a problem with late data arriving. This is the simplest scenario for periodically generating the water level, which WatermarkStrategy.forMonotonousTimestamps()can be achieved by directly calling the method. To put it simply, it is enough to directly take the current largest timestamp as the water level.
stream.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>()
{
@Override
public long extractTimestamp(Event element, long recordTimestamp)
{
return element.timestamp;
}
})
);
In the above code, we call the .withTimestampAssigner() method to extract the timestamp field in the data and assign it to the data element as a timestamp; then use the built-in ordered pipeline generator to construct a generation strategy. In this way, the extracted data timestamp is the event time we process and calculate. It should be noted here that the units of the timestamp and the water level must both be milliseconds.
6.2.3.3.2. Out-of-order flow
Since the out-of-order stream needs to wait for late data to arrive, a fixed amount of delay (Fixed Amount of Lateness) must be set. At this time, the timestamp of the generated water level is the result of subtracting the delay from the maximum timestamp in the current data stream, which is equivalent to slowing down the watch, and the current clock will lag behind the maximum timestamp of the data. This can be achieved by calling the WatermarkStrategy.forBoundedOutOfOrderness() method. This method needs to pass in a maxOutOfOrderness parameter, which means the "maximum out-of-order degree", which indicates the maximum difference between the time stamps of out-of-order data in the data stream; if we can determine the degree of out-of-order, then set the delay corresponding to the length of time. Wait until all the out-of-order data is gone.
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(new ClickSource())
// 插入水位线的逻辑
.assignTimestampsAndWatermarks(
// 针对乱序流插入水位线,延迟时间设置为 5s
WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(5))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
// 抽取时间戳的逻辑
@Override
public long extractTimestamp(Event element, longrecordTimestamp) {
return element.timestamp;
}
})
).print();
env.execute();
}
The timestamp field is extracted as a timestamp, and a watermark generator is created to handle out-of-order streams with a 5-second delay.
In fact, the water level generator of the ordered stream is essentially the same as the out-of-order stream, which is equivalent to the out-of-order water level generator with the delay set to 0, and the two are completely equivalent:
WatermarkStrategy.forMonotonousTimestamps()
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(0))
6.2.3.4. Custom water level strategy
In WatermarkStrategy, the timestamp assigner TimestampAssigner is similar, just specify the field to extract the timestamp; and the key to different strategies lies in the realization of WatermarkGenerator. Generally speaking, Flink has two different ways to generate water levels: one is periodic (Periodic), and the other is breakpoint (Punctuated).
onEvent() and onPeriodicEmit(), the former is called when each event arrives, while the latter is called periodically by the framework. When the water level is issued in the periodically called method, the water level is naturally generated periodically; when the water level is issued in the event-triggered method, the water level is naturally generated by a breakpoint. The difference between the two methods is concentrated in the realization of these two methods.
6.2.3.4.1, Periodic water level generator (Periodic Generator)
The periodic generator generally observes and judges the input events through onEvent(), and emits the water level in onPeriodicEmit().
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(new CustomWatermarkStrategy())
.print();
env.execute();
}
public static class CustomWatermarkStrategy implements WatermarkStrategy<Event> {
@Override
public TimestampAssigner<Event> createTimestampAssigner(TimestampAssignerSupplier.Context context) {
return new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp; // 告诉程序数据源里的时间戳是哪一个字段
}
};
}
@Override
public WatermarkGenerator<Event> createWatermarkGenerator(WatermarkGeneratorSupplier.Context context) {
return new CustomPeriodicGenerator();
}
}
public static class CustomPeriodicGenerator implements WatermarkGenerator<Event> {
private Long delayTime = 5000L; // 延迟时间
private Long maxTs = Long.MIN_VALUE + delayTime + 1L; // 观察到的最大时间戳
@Override
public void onEvent(Event event, long eventTimestamp, WatermarkOutput
output) {
// 每来一条数据就调用一次
maxTs = Math.max(event.timestamp, maxTs); // 更新最大时间戳
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 发射水位线,默认 200ms 调用一次
output.emitWatermark(new Watermark(maxTs - delayTime - 1L));
}
}
Call output.emitWatermark() in onPeriodicEmit() to emit the watermark; this method is called periodically by the system framework, and the default time is 200ms. Therefore, the timestamp of the water level depends on the maximum timestamp of the current existing data (the implementation here is similar to the built-in generator, which also subtracts the delay time and then minus 1), but when it is generated has nothing to do with the data.
6.2.3.4.2. Punctuated Generator
The breakpoint generator will continuously detect the events in onEvent(), and when it finds a special event with water level information, it will immediately send out the water level. In general, breakpoint generators do not emit watermarks via onPeriodicEmit().
The custom breakpoint water level generator code is as follows:
public class CustomPunctuatedGenerator implements WatermarkGenerator<Event> {
@Override
public void onEvent(Event r, long eventTimestamp, WatermarkOutput output) {
// 只有在遇到特定的 itemId 时,才发出水位线
if (r.user.equals("Mary")) {
output.emitWatermark(new Watermark(r.timestamp - 1));
}
}
@Override
public void onPeriodicEmit(WatermarkOutput output) {
// 不需要做任何事情,因为我们在 onEvent 方法中发射了水位线
}
}
In onEvent(), the user field of the current event is judged. Only when the special value "Mary" is encountered, the output.emitWatermark()water level is called and sent. This process is triggered entirely by events, so the water level must be generated after a certain data arrives.
6.2.3.5. Send water level in custom data source
We can also extract the event time from a custom data source, and then send the watermark. It should be noted here that after the watermark is sent in the custom data source, the assignTimestampsAndWatermarks method can no longer be used in the program to generate the watermark.
There is only one option between generating watermarks in the custom data source and using the assignTimestampsAndWatermarks method in the program.
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSource(new ClickSourceWithWatermark()).print();
env.execute();
}
// 泛型是数据源中的类型
public static class ClickSourceWithWatermark implements SourceFunction<Event> {
private boolean running = true;
@Override
public void run(SourceContext<Event> sourceContext) throws Exception {
Random random = new Random();
String[] userArr = {
"Mary", "Bob", "Alice"};
String[] urlArr = {
"./home", "./cart", "./prod?id=1"};
while (running) {
long currTs = Calendar.getInstance().getTimeInMillis(); // 毫秒时间戳
String username = userArr[random.nextInt(userArr.length)];
String url = urlArr[random.nextInt(urlArr.length)];
Event event = new Event(username, url, currTs);
// 使用 collectWithTimestamp 方法将数据发送出去,并指明数据中的时间戳的字段
sourceContext.collectWithTimestamp(event, event.timestamp);
// 发送水位线
sourceContext.emitWatermark(new Watermark(event.timestamp - 1L));
Thread.sleep(1000L);
}
}
@Override
public void cancel() {
running = false;
}
}
6.2.4. Transfer of water level
We know that the watermark is a mark inserted in the data stream to indicate the progress of the event time, and it will be passed between tasks along with the data.
If it's just a forward transmission, it's very simple. The data and the water level are transmitted and processed sequentially in their own order; once the water level reaches the operator task, the task will switch its internal clock to Set to the timestamp of this watermark.
In practical applications, there are often multiple parallel subtasks upstream and downstream. In order to unify the progress of event time, we require the upstream task to send the current water level again after the water level is processed and the clock is changed, and broadcast to all downstream subtasks. Task. In this way, subsequent tasks do not
need to rely on the timestamp in the original data (the data may have changed after conversion), and can also know the current event time.
There is another problem, that is, in the "redistributing" transfer mode, a task may receive data from upstream subtasks in different partitions. The subtask clocks of different partitions are not synchronized, so the water levels sent to downstream tasks at the same time may be different. At this time, who should listen to the downstream tasks?
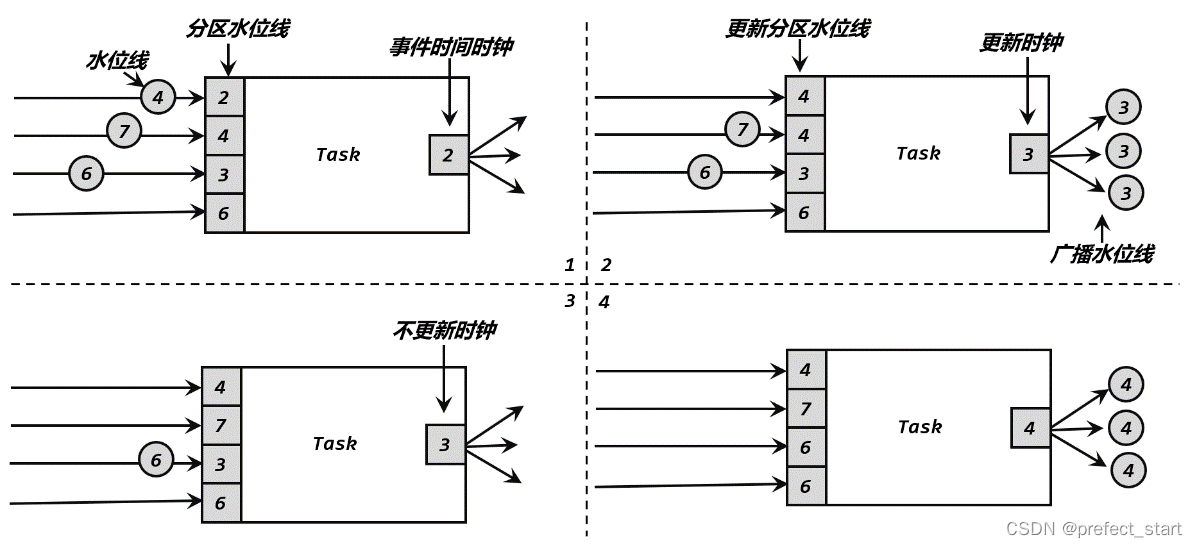
We can use a specific example to fully sort out the process of water level transfer between tasks. As shown in the figure above, there are four parallel subtasks upstream of the current task, so it will receive watermarks from four partitions; and there are three parallel subtasks downstream, so watermarks will be sent to three partitions. The specific process is as follows:
-
The upstream parallel subtasks send different watermarks, and the current task will set a "Partition Watermark" (Partition Watermark) for each partition, which is a partition clock; and the current task's own clock is the smallest of all partition clocks that.
-
When a new water level (4 of the first partition) comes from the upstream, the current task will first update the corresponding partition clock; then judge the minimum value of all partition clocks again, if it is larger than before, it means that the event time has Once the progress is made, the clock for the current task can be updated. It should be noted here that the updated task clock is not necessarily the water level of the new partition. For example, the clock of the first partition is changed here, but the smallest partition clock is 3 of the third partition, so the current task clock is Advance to 3. When the clock progresses, the current task will broadcast its own clock to all downstream subtasks in the form of a water mark.
-
After receiving the new water level (7 of the second partition) again, perform the same process. First update the second partition clock to 7, and then compare all partition clocks; if the minimum value is found to have no change, then the clock of the current task is also unchanged, and the watermark will not be sent to downstream tasks.
-
In the same way, when a new water level (6 of the third partition) is received again, the clock of the third partition is updated to 6, and at the same time the minimum value of all partition clocks becomes 4 of the first partition, so the clock of the current task Advance to 4, and send out the water level with a time stamp of 4, and broadcast it to each partition task downstream.
6.3. Window
6.3.1. The concept of window
Flink is a streaming computing engine, which is mainly used to process unbounded data flow, and the data is continuous and endless. One way to process unbounded streams more conveniently and efficiently is to cut unlimited data into limited "data blocks" for processing, which is the so-called "window".
In Flink, the window is the core used to handle unbounded streams. It is easy for us to imagine the window as a "box" with a fixed position, and the data flows in continuously. When the window should be closed at a certain point, it stops collecting data, triggering calculations and outputting results.
For example, if we define a time window and count data every 10 seconds, it is equivalent to putting the window there and collecting data from 0 seconds; when it reaches 10 seconds, process all the data in the current window, output a result, and then clear it The window continues to collect data; at 20 seconds, all the data in the window are calculated and processed, and the results are output; and so on, as shown in the figure below.
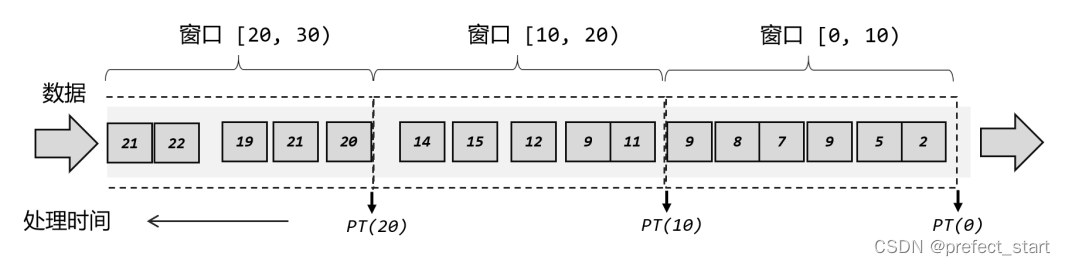
In Flink, the window can cut the stream into multiple "buckets" of limited size; each data will be distributed to the corresponding bucket, and when the end time of the window is reached, the data collected in each bucket Perform computational processing.
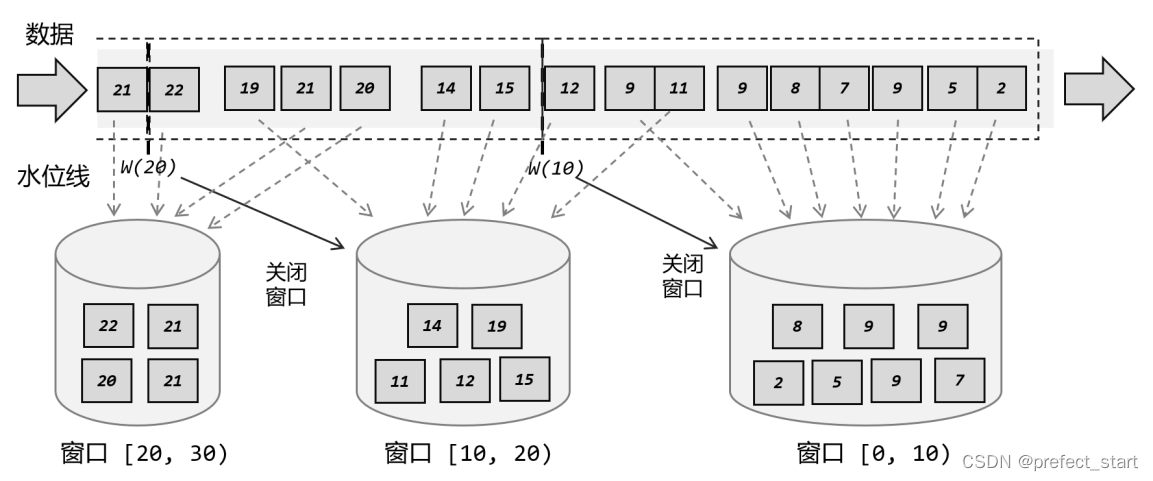
The processing of the window in the example:
- We can set the delay time to 2 seconds, the timestamp of the first data is 2, create the first window [0, 10) after the judgment, and save the 2-second data in it, and the subsequent data will come in sequence, and the timestamps are all in [0 , 10) within the range, so all are saved into the first window;
- The 11-second data arrives, and it is judged that it does not belong to the [0, 10) window, so a second window [10, 20) is created and the 11-second data is saved in it. Since the water level setting delay time is 2 seconds, the current clock is 9 seconds, and the first window has not reached the closing time; after another 9 seconds, the data arrives, and it also enters the [0, 10) window;
- When the data arrives in 12 seconds, it is determined that it belongs to the [10, 20) window and saved in it. The water level generated at this time has advanced to 10 seconds, so the [0, 10) window should be closed. The first window collects all 7 data, outputs the result after processing and calculation, and closes and destroys the window;
- Similarly, the subsequent data enters the second window in turn. When encountering 20-second data, a third window [20, 30) will be created and the data will be saved in it; when encountering 22-second data, the water level has reached 20 seconds , the second window triggers the calculation, outputs the result and closes.

6.3.2. Classification of windows
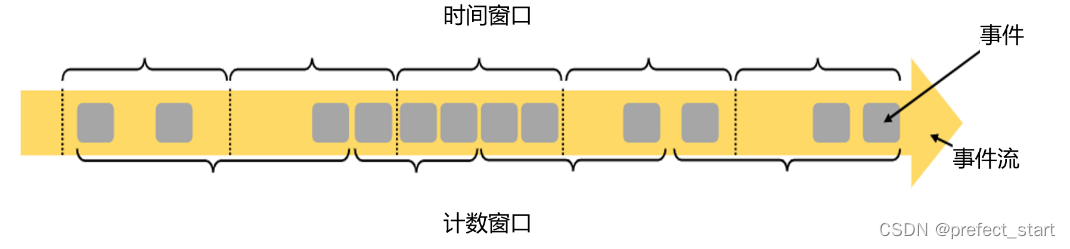
6.3.2.1. Classification by Driver Type
- The data is intercepted according to the time period. This kind of window is called "Time Window".
- According to a fixed number, to intercept a data set, this window is called "count window" (Count Window)
- Time Window
The time window defines the start (start) and end (end) of the window with time points, so the intercepted data is the data of a certain time period. When the end time is reached, the window no longer collects data, triggers the calculation output, and closes and destroys the window.
There is a special class in Flink to represent the time window, the name is called TimeWindow. This class has only two private properties: start and end, which represent the start and end timestamps of the window in milliseconds.
private final long start;
private final long end;
We can call the public getStart() and getEnd() methods to get these two timestamps directly. In addition, TimeWindow also provides a maxTimestamp() method to obtain the maximum timestamp that can contain data in the window.
public long maxTimestamp() {
return end - 1;
}
Obviously, for the data in the window, the maximum allowable timestamp is end - 1, which means that the time range of the window we defined is the interval [start, end) that is left closed and right open.
- Count Window
The counting window intercepts data based on the number of elements. When a fixed number is reached, the calculation is triggered and the window is closed. The number of intercepted data for each window is the size of the window.
The counting window is simpler than the time window. We only need to specify the window size, and then the data can be allocated to the corresponding window. There is no corresponding class in Flink to represent the counting window, and the bottom layer is realized through the "Global Window".
6.3.2.2. According to the rules of window allocation data classification
The time window and counting window are just a rough division of the window; in specific applications, more detailed rules need to be defined to control which window the data should be divided into. Different ways of allocating data can have different functions.
According to the rules for allocating data, the specific implementation of windows can be divided into 4 categories:
- Tumbling Window
- Sliding Window
- Session Window
- Global Window
6.3.2.2.1, Tumbling Windows
The rolling window has a fixed size and is a way to "slice evenly" the data. There is no overlap between the windows, and there will be no gaps, which is the state of "end to end". If we regard the creation of multiple windows as the movement of a window, it seems that it is constantly "rolling" forward.
The rolling window can be defined based on time or the number of data; only one parameter is required, which is the size of the window (window size). For example, we can define a rolling time window with a length of 1 hour, and statistics will be performed every hour; or define a rolling count window with a length of 10, and statistics will be performed every 10 numbers.
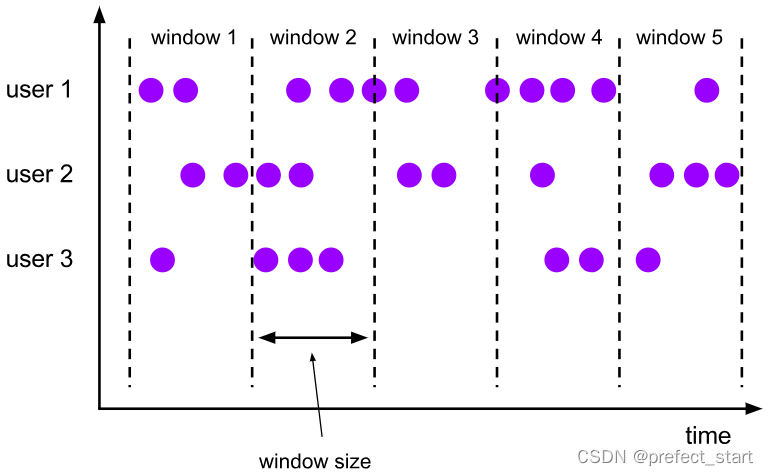
As shown in the figure above, the dots represent the data in the stream, and we partition the data according to userId. When the window size is fixed, the window division of all partitions is consistent; the windows do not overlap, and each data belongs to only one window.
6.3.2.2.2, sliding window (Sliding Windows)
Similar to rolling windows, sliding windows are also of fixed size. The difference is that the windows are not connected end to end, but can be "staggered" by a certain position. If you think of it as a window movement, it is like "sliding" forward with small steps. There are two parameters to define the sliding window: In addition to the window size (window size), there is also a "sliding step" ( window slide), which actually represents the frequency of window calculations. The sliding distance represents the time interval between the start of the next window, and the window size is fixed, so it is also the interval between the end times of the two windows; the window triggers the calculation output at the end time, so the sliding step represents the calculation frequency.
For example, if we define a sliding window with a length of 1 hour and a sliding step of 5 minutes, then the data within 1 hour will be counted every 5 minutes. Similarly, the sliding window can be defined based on time or the number of data.
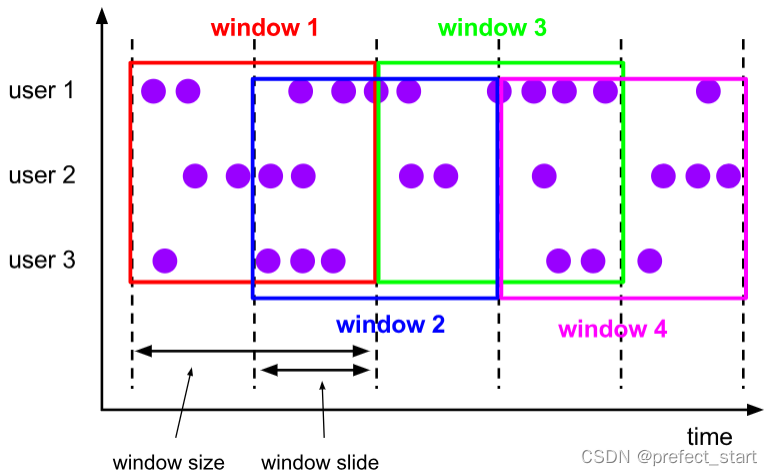
When the sliding step is smaller than the window size, the sliding windows will overlap, and the data may be allocated to multiple windows at the same time. The specific number is determined by the ratio of the window size to the sliding step (size/slide). As shown in the figure above, the sliding step is exactly half of the window size, then each data will be allocated to 2 windows.
For example, if we define a window length of 1 hour and a sliding step of 30 minutes, then the data at 8:55 should belong to two windows of [8:00, 9:00] and [8:30, 9:30) at the same time; As for the data at 8:10, it belongs to [8:00, 9:00) and [7:30, 8:30) at the same time.
Therefore, a sliding window is actually a more generalized form of a fixed-size window; in other words, a rolling window can also be regarded as a special sliding window—the window size is equal to the sliding step (size = slide).
Of course, we can also define the sliding step to be larger than the window size, so that the windows do not overlap, but there will be intervals; at this time, some data does not belong to any window, and missing statistics will appear. So in general, we will make the sliding step smaller than the window size, and try to set it to an integer multiple.
In some scenarios, it may be necessary to count indicators in a recent period of time, and the output frequency of the results is very high, and even real-time updates are required, such as the 24-hour rise and fall statistics of stock prices, or abnormalities detected based on behavior over a period of time Call the police. At this time, the sliding window is undoubtedly a good way to achieve it.
6.3.2.2.3, session window (Session Windows)
As the name suggests, the session window is based on the "session" to group data. In simple terms, a session window is opened after the data arrives. If there is more data coming one after another, the session is kept; If no data has been received for a period of time, it is considered that the session timeout expires and the window is automatically closed.
The session window can only be defined based on time. For the session window, the most important parameter is the length of this time (size), which represents the timeout period of the session, that is, the minimum distance between two session windows. In terms of specific implementation, we can set a static fixed size (size), or dynamically extract the value of the minimum interval gap through a custom extractor (gap extractor).
At the bottom of Flink, the processing of the session window will be special: every time a new data comes, a new session window will be created; then the distance between the existing windows will be judged, and if it is smaller than the given size, they will be merged (merge) operation. In the Window operator, there is separate processing logic for the session window.
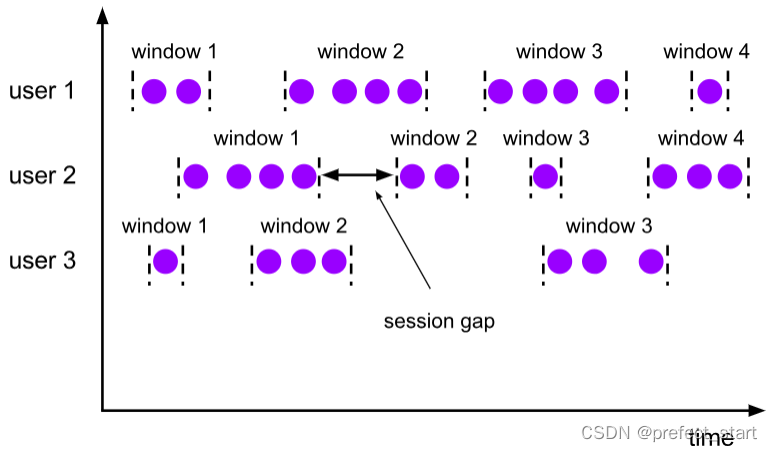
Different from the previous two types of windows, the length of the session window is not fixed, the start and end time are also uncertain, and there is no relationship between the windows of each partition. As shown in the figure above, the session windows must not overlap, and there will be an interval (session gap) of at least size.
6.3.2.2.4, Global Windows (Global Windows)
This kind of window is globally effective, and all the data of the same key will be allocated to the same window, just like there is no window. The data of the unbounded stream is endless, so when this kind of window is not over, the trigger calculation will not be performed by default. If you want it to be able to calculate and process data, you also need to customize the "trigger" (Trigger).
6.3.3. Window API overview
6.3.3.1, key partition (Keyed) and non-key partition (Non-Keyed)
Before defining the window operation, you first need to determine whether to open the window based on the keyed stream KeyedStream, or to open the window directly on the DataStream without the keyed partition. That is, whether there is a keyBy operation before calling the window operator.
- Keyed Windows (Keyed Windows)
After the keyBy operation, the data stream will be divided into multiple logical streams (logical streams) according to the key, which is KeyedStream. When performing window operations based on KeyedStream, window calculations will be executed simultaneously on multiple parallel subtasks. Data for the same key will be sent to the same parallel subtask, and window operations will be processed individually on a per-key basis. Therefore, it can be considered that a group of windows is defined on each key, and statistical calculations are performed independently.
In terms of code implementation, we need to call .keyBy() on the DataStream to partition by key, and then call .window() to define the window.
stream.keyBy(...).window(...)
- Keyed Windows (Keyed Windows)
If no keyBy is performed, the original DataStream will not be divided into multiple logical streams. At this time, the window logic can only be executed on one task, which means that the parallelism becomes 1. Therefore, it is generally not recommended to use this method in practical applications.
In code, define windows by calling .windowAll() directly on the DataStream.
stream.windowAll(...)
It should be noted here that for window operations that are not partitioned by key, manually increasing the parallelism of the window operator is also invalid, and windowAll itself is a non-parallel operation.
6.3.3.2. Window API call in the code
There are two main parts of window operation: Window Assigners and Window Functions.
stream.keyBy(<key selector>).window(<window assigner>).aggregate(<window function>)
Among them, the .window() method needs to pass in a window allocator, which specifies the type of window; and the latter .aggregate() method passes in a window function as a parameter, which is used to define the specific processing logic of the window.
6.3.4. Window Assigners
Defining a window assigner (Window Assigners) is the first step in building a window operator. Its function is to define which window data should be "assigned" to.
The most common way to define a window allocator is to call the .window() method. This method needs to pass in a WindowAssigner as a parameter and returns a WindowedStream. If it is a non-key partition window, then directly call the .windowAll() method, and also pass in a WindowAssigner, and return AllWindowedStream.
The window can be divided into time window and counting window according to the driving type, and according to the specific allocation rules, there are four types: rolling window, sliding window, session window, and global window.
6.3.4.1, time window
The standard declaration method is to directly call .window(), and pass in the window allocator under the corresponding time semantics. There is no need to specifically define time semantics, and the default is event time; if you want to use processing time, then pass in the processing time here The window allocator will do the trick.
- rolling processing time window
The window allocator is provided by the class TumblingProcessingTimeWindows, and its static method .of() needs to be called.
stream.keyBy(...).window(TumblingProcessingTimeWindows.of(Time.seconds(5))).aggregate(...)
Here, the .of() method needs to pass in a parameter size of type Time, indicating the size of the scrolling window. Here we create a scrolling window with a length of 5 seconds. In addition, .of() also has an overloaded method that can pass in two parameters of type Time: size and offset. The first parameter is of course the window size, and the second parameter represents the offset of the starting point of the window.
- sliding processing time window
The window allocator is provided by the class SlidingProcessingTimeWindows, and its static method .of() needs to be called as well.
stream.keyBy(...)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)
Here, the .of() method needs to pass in two parameters of type Time: size and slide. The former indicates the size of the sliding window, and the latter indicates the sliding step of the sliding window. Here we create a sliding window with a length of 10 seconds and a sliding step of 5 seconds.
- Processing Time Session Window
The window allocator is ProcessingTimeSessionWindowsprovided and needs to call its static method .withGap()or .withDynamicGap().
stream.keyBy(...)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)
Here, the .withGap() method needs to pass in a parameter size of the Time type, indicating the timeout period of the session, that is, the minimum session gap. Here we create a session window with a static session timeout of 10 seconds.
.window(ProcessingTimeSessionWindows.withDynamicGap(new
SessionWindowTimeGapExtractor<Tuple2<String, Long>>() {
@Override
public long extract(Tuple2<String, Long> element) {
// 提取 session gap 值返回, 单位毫秒
return element.f0.length() * 1000;
}
}))
Here, the .withDynamicGap() method needs to pass in a SessionWindowTimeGapExtractor as a parameter, which is used to define the dynamic extraction logic of the session gap. Here, we extract the first field of the data element and multiply its length by 1000 as the session timeout interval.
- Scroll event time window
The window allocator is provided by the class TumblingEventTimeWindows, and its usage is exactly the same as that of the scrolling processing event window. Here the .of() method can also pass in the second parameter offset, which is used to set the offset of the starting point of the window.
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.aggregate(...)
- Sliding Event Time Window
The window allocator is provided by the class SlidingEventTimeWindows, and its usage is exactly the same as that of the sliding processing event window.
stream.keyBy(...)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.aggregate(...)
- event time session window
The window allocator is provided by the class EventTimeSessionWindows, and its usage is exactly the same as that of handling event session windows.
stream.keyBy(...)
.window(EventTimeSessionWindows.withGap(Time.seconds(10)))
.aggregate(...)
6.3.4.2, counting window
The concept of the counting window is very simple, and the bottom layer itself is implemented based on the global window (Global Window). Flink provides us with a very convenient interface: directly call the .countWindow() method. According to different allocation rules, it can be divided into rolling counting window and sliding counting window.
- rolling count window
The rolling count window only needs to pass in a long integer parameter size, indicating the size of the window.
stream.keyBy(...).countWindow(10)
We define a rolling counting window with a length of 10. When the number of elements in the window reaches 10, the calculation will be executed and the window will be closed.
- sliding count window
Similar to the scrolling count window, but two parameters need to be passed in when .countWindow() is called: size and slide, the former indicates the window size, and the latter indicates the sliding step.
stream.keyBy(...).countWindow(10,3)
We define a sliding counting window of length 10 with a sliding step of 3. Count 10 data in each window, and output the result every 3 data.
- global window
The global window is the underlying implementation of the counting window, and is generally used when a custom window is required. Its definition is also to call .window() directly, and the allocator is provided by the GlobalWindows class.
stream.keyBy(...).window(GlobalWindows.create());
It should be noted that when using the global window, you must define the trigger yourself to realize the window calculation, otherwise it will have no effect.
6.3.5. Window Functions
After the window allocator, there must be another operation that defines how the window performs calculations. This is the so-called "window function" (window functions).
After being processed by the window allocator, the data can be allocated to the corresponding window, and the data type obtained by converting the data stream is WindowedStream. This type is not DataStream, so other conversions cannot be performed directly, but the window function must be further called to process and calculate the collected data before finally getting DataStream again, as shown in the figure below.
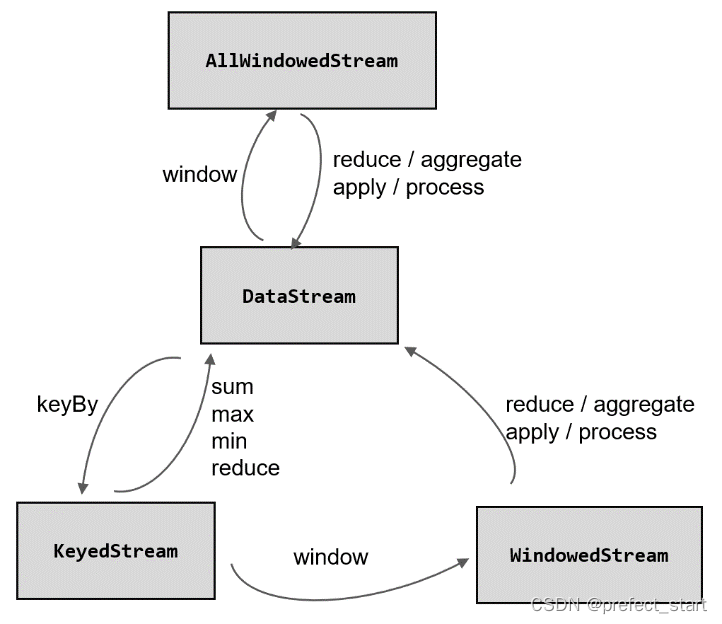
Window functions define the calculation operations to be performed on the data collected in the window, which can be divided into two categories according to the processing method:
- incremental aggregate function
- full window function
6.3.5.1, incremental aggregation functions (incremental aggregation functions)
Like the simple aggregation of DataStream, every piece of data is calculated immediately, and only a simple aggregation state is maintained in the middle; the difference is that the result is not output immediately, but waits until the end of the window. When the calculation results need to be output at the end of the window, we only need to output the previously aggregated state directly, which greatly improves the efficiency and real-time performance of the program.
There are two typical incremental aggregate functions: ReduceFunction and AggregateFunction.
6.3.5.1.1. Reduce function (ReduceFunction)
The most basic aggregation method is reduction (reduce), which reduces the data collected in the window in pairs. When we perform stream processing, we need to save a state; every time a new data comes, it is reduced with the previous aggregation state, thus realizing incremental aggregation.
The ReduceFunction is also provided in the window function: as long as the .reduce() method is called based on the WindowedStream, and then the ReduceFunction is passed in as a parameter, the data in the window can be aggregated by reducing two elements. The ReduceFunction here is actually the same function class interface as the ReduceFunction used in simple aggregation, so the usage is exactly the same.
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 从自定义数据源读取数据,并提取时间戳、生成水位线
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
stream.map(new MapFunction<Event, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(Event value) throws Exception {
// 将数据转换成二元组,方便计算
return Tuple2.of(value.user, 1L);
}
}).keyBy(r -> r.f0)
// 设置滚动事件时间窗口
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
// 定义累加规则,窗口闭合时,向下游发送累加结果
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
}).print();
env.execute();
}
In the code, we performed window statistics on the behavior data of each user. Similar to the word count logic, first convert the data into (user, count) two-tuple form (type is Tuple2<String, Long>), the initial count value corresponding to each piece of data is 1; then group by user id, Open the rolling window under the processing time, and count the number of user behaviors every 5 seconds. For the calculation of the window, we use ReduceFunction to perform incremental aggregation on the count value: the current total count value will be saved in a reduced state in the window, and each time a piece of data comes, the internal reduce method will be called to convert the new data into The count value is superimposed on the state, and the new state is saved. When the end time of the 5-second window is reached, the reduced state is output directly.
It should be noted here that the data type of the output data we converted through window aggregation is still a tuple of Tuple2<String, Long>.
6.3.5.1.2, aggregate function (AggregateFunction)
ReduceFunction can solve most reduction aggregation problems, but this interface has a limitation, that is, the type of the aggregation state and the type of the output result must be the same as the input data type.
For example, if we want to calculate the average value of a set of data, how should we do the aggregation? We need to calculate two state quantities: the sum of the data (sum) and the number of data (count), and the final output is the quotient of the two (sum/count). If you use ReduceFunction, then we should first convert the data into the form of a two-tuple (sum, count), then perform reduction aggregation, and finally divide and transform the two elements of the tuple to obtain the final average value. It should have been just one task, but we need a three-step operation of map-reduce-map, which is obviously not efficient enough.
aggregate in Flink's Window API provides such operations. By directly calling the .aggregate() method based on WindowedStream, you can define more flexible window aggregation operations. This method needs to pass in an implementation class of AggregateFunction as a parameter.
AggregateFunction is defined in the source code as follows:
public interface AggregateFunction<IN, ACC, OUT> extends Function, Serializable
{
ACC createAccumulator();
ACC add(IN value, ACC accumulator);
OUT getResult(ACC accumulator);
ACC merge(ACC a, ACC b);
}
AggregateFunction can be seen as a general version of ReduceFunction, there are three types here: input type (IN), accumulator type (ACC) and output type (OUT). The input type IN is the data type of the elements in the input stream; the accumulator type ACC is the intermediate state type for our aggregation; and the output type is of course the type of the final calculation result.
There are four methods in the interface:
- createAccumulator(): Create an accumulator, which is to create an initial state for the aggregation, and each aggregation task will only be called once.
- add(): Adds the input element to the accumulator. This is the process of further aggregating new incoming data based on the aggregation state. The method passes in two parameters: the current newly arrived data value, and the current accumulator; returns a new accumulator value, that is, updates the aggregation state. This method is called after each piece of data arrives.
- getResult(): Extract the aggregated output result from the accumulator. In other words, we can define multiple states, and then calculate a result based on these aggregated states for output. For example, when calculating the average value we mentioned before, you can put the sum and count as the state into the accumulator, and divide them to get the final result when calling this method. This method is only called when the window is about to output results.
- merge(): Merges two accumulators and returns the merged state as one accumulator. This method will only be called in the scene that needs to merge windows; the most common scene of merging windows (Merging Window) is the session window (Session Windows).
So you can see that the working principle of AggregateFunction is: first call createAccumulator() to initialize a state (accumulator) for the task; then call the add() method every time a piece of data comes in, aggregate the data, and save the result in the state middle; wait until the window needs output, and then call the getResult() method to get the calculation result. Obviously, like ReduceFunction, AggregateFunction is also an incremental aggregation; and because the types of input, intermediate state, and output can be different, the application is more flexible and convenient.
In e-commerce websites, PV (page views) and UV (number of unique visitors) are two very important traffic indicators. Generally speaking, PV counts all clicks; after deduplication of user id, UV is obtained. So sometimes we use the ratio of PV/UV to represent the "repeated visits per capita", that is, how many pages each user visits on average, which to a certain extent represents the viscosity of users.
The code is implemented as follows:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
// 所有数据设置相同的 key,发送到同一个分区统计 PV 和 UV,再相除
stream.keyBy(data -> true)
.window(SlidingEventTimeWindows.of(Time.seconds(10),
Time.seconds(2)))
.aggregate(new AvgPv())
.print();
env.execute();
}
public static class AvgPv implements AggregateFunction<Event, Tuple2<HashSet<String>, Long>, Double> {
@Override
public Tuple2<HashSet<String>, Long> createAccumulator() {
// 创建累加器
return Tuple2.of(new HashSet<String>(), 0L);
}
@Override
public Tuple2<HashSet<String>, Long> add(Event value, Tuple2<HashSet<String>, Long> accumulator) {
// 属于本窗口的数据来一条累加一次,并返回累加器
accumulator.f0.add(value.user);
return Tuple2.of(accumulator.f0, accumulator.f1 + 1L);
}
@Override
public Double getResult(Tuple2<HashSet<String>, Long> accumulator) {
// 窗口闭合时,增量聚合结束,将计算结果发送到下游
return (double) accumulator.f1 / accumulator.f0.size();
}
@Override
public Tuple2<HashSet<String>, Long> merge(Tuple2<HashSet<String>, Long> a, Tuple2<HashSet<String>, Long> b) {
return null;
}
}
In addition, Flink also provides a series of predefined simple aggregation methods for window aggregation, which can be called directly based on WindowedStream. It mainly includes .sum()/max()/maxBy()/min()/minBy(), which is very similar to the simple aggregation of KeyedStream. Their bottom layer is actually realized through AggregateFunction.
6.3.5.2, full window functions (full window functions)
Different from the incremental aggregation function, the full-window function needs to collect the data in the window first, and cache it internally, and then take out the data for calculation when the window is about to output the result. The typical batch processing idea is to save the data first and wait for a while. Once the batches are all in place, the processing process will be officially started.
Why do you need full window functions? This is because in some scenarios, the calculation we have to do must be based on all the data to be effective, and it is meaningless to do incremental aggregation at this time; in addition, the output result may contain some information in the context (such as the starting point of the window start time), which incremental aggregate functions cannot do. Therefore, we also need a richer window calculation method, which can be realized with the full window function.
In Flink, there are two types of full window functions: WindowFunction and ProcessWindowFunction.
6.3.5.2.1, window function (WindowFunction)
WindowFunction literally means "window function", which is actually an old version of the general window function interface. We can call the .apply() method based on WindowedStream and pass in a WindowFunction implementation class.
stream.keyBy(<key selector>)
.window(<window assigner>)
.apply(new MyWindowFunction());
In this class, you can get an iterable collection (Iterable) containing all the data of the window, and you can also get the information of the window (Window) itself. The WindowFunction interface is implemented in the source code as follows:
public interface WindowFunction<IN, OUT, KEY, W extends Window> extends Function, Serializable {
void apply(KEY key, W window, Iterable<IN> input, Collector<OUT> out) throws Exception;
}
When the window reaches the end time and needs to trigger the calculation, the apply method here will be called. We can take out the data collected by the window from the input collection, combine the key and window information, and output the result through the Collector.
The usage of Collector here is the same as in FlatMapFunction, but WindowFunction can provide less context information and no more advanced functions. In fact, its function can be fully covered by ProcessWindowFunction, so it may be gradually deprecated in the future. Generally, in practical applications, it is enough to directly use ProcessWindowFunction.
6.3.5.2.2, Process Window Function (ProcessWindowFunction)
ProcessWindowFunction is the lowest general window function interface in Window API. The reason why it is called "the bottom layer" is that in addition to getting all the data in the window, ProcessWindowFunction can also get a "context object" (Context). This context object is very powerful, not only can get window information, but also can access current time and state information. The time here includes processing time and event time watermark. This makes ProcessWindowFunction more flexible and feature-rich.
Of course, these benefits come at the expense of performance and resources. As a full-window function, ProcessWindowFunction also needs to cache all data and wait until the window triggers the calculation before using it. It is actually an enhanced version of WindowFunction.
The specific use is very similar to WindowFunction. We can call the .process() method based on WindowedStream and pass in an implementation class of ProcessWindowFunction. The following is an example of hourly UV statistics for an e-commerce website:
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long
recordTimestamp) {
return element.timestamp;
}
}));
// 将数据全部发往同一分区,按窗口统计 UV
stream.keyBy(data -> true)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new UvCountByWindow())
.print();
env.execute();
}
// 自定义窗口处理函数
public static class UvCountByWindow extends ProcessWindowFunction<Event, String, Boolean, TimeWindow> {
@Override
public void process(Boolean aBoolean, Context context, Iterable<Event> elements, Collector<String> out) throws Exception {
HashSet<String> userSet = new HashSet<>();
// 遍历所有数据,放到 Set 里去重
for (Event event : elements) {
userSet.add(event.user);
}
// 结合窗口信息,包装输出内容
Long start = context.window().getStart();
Long end = context.window().getEnd();
out.collect(" 窗 口 : " + new Timestamp(start) + " ~ " + new Timestamp(end) + " 的独立访客数量是:" + userSet.size());
}
}
6.3.5.2.3, Combination of incremental aggregation and full window function
Before calling the .reduce() and .aggregate() methods of WindowedStream, a ReduceFunction or AggregateFunction was simply directly passed in for incremental aggregation. In addition, the second parameter can actually be passed in: a full window function, which can be WindowFunction or ProcessWindowFunction.
// ReduceFunction 与 WindowFunction 结合
public <R> SingleOutputStreamOperator<R> reduce(ReduceFunction<T> reduceFunction, WindowFunction<T, R, K, W> function)
// ReduceFunction 与 ProcessWindowFunction 结合
public <R> SingleOutputStreamOperator<R> reduce(ReduceFunction<T> reduceFunction, ProcessWindowFunction<T, R, K, W> function)
// AggregateFunction 与 WindowFunction 结合
public <ACC, V, R> SingleOutputStreamOperator<R> aggregate(AggregateFunction<T, ACC, V> aggFunction, WindowFunction<V, R, K, W> windowFunction)
// AggregateFunction 与 ProcessWindowFunction 结合
public <ACC, V, R> SingleOutputStreamOperator<R> aggregate(AggregateFunction<T, ACC, V> aggFunction,ProcessWindowFunction<V, R, K, W> windowFunction)
The processing mechanism of this call is: process the window data based on the first parameter (incremental aggregation function), and do an aggregation every time a piece of data comes in; when the window needs to trigger calculation, call the second parameter (full window function) The output result of the processing logic. It should be noted that the full window function here no longer caches all data, but directly uses the result of the incremental aggregation function as the input of the Iterable type. Under normal circumstances, there is only one element in the iterable collection at this time.
For example: Among the various statistical indicators of the website, a very important statistical indicator is the popular link; to get the popular URL, the premise is to get the "popularity" of each link. In general, the popularity can be expressed by the number of views (clicks) of the url. Here we count the url browsing volume for 10 seconds, and update it every 5 seconds; in addition, for a clearer display, the start and end time of the window should also be output together. We can define sliding windows and combine incremental aggregation functions with full window functions to get statistical results.
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env =StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long
recordTimestamp) {
return element.timestamp;
}
}));
// 需要按照 url 分组,开滑动窗口统计
stream.keyBy(data -> data.url)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
// 同时传入增量聚合函数和全窗口函数
.aggregate(new UrlViewCountAgg(), new UrlViewCountResult())
.print();
env.execute();
}
// 自定义增量聚合函数,来一条数据就加一
public static class UrlViewCountAgg implements AggregateFunction<Event, Long, Long> {
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event value, Long accumulator) {
return accumulator + 1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return null;
}
}
// 自定义窗口处理函数,只需要包装窗口信息
public static class UrlViewCountResult extends ProcessWindowFunction<Long, UrlViewCount, String, TimeWindow> {
@Override
public void process(String url, Context context, Iterable<Long> elements,
Collector<UrlViewCount> out) throws Exception {
// 结合窗口信息,包装输出内容
Long start = context.window().getStart();
Long end = context.window().getEnd();
// 迭代器中只有一个元素,就是增量聚合函数的计算结果
out.collect(new UrlViewCount(url, elements.iterator().next(), start, end));
}
}
6.3.6. Other APIs
6.3.6.1, Trigger (Trigger)
Triggers are mainly used to control when the window triggers calculations. The so-called "triggered calculation" is essentially to execute the window function, so it can be considered as the process of calculating and outputting the result.
Call the .trigger() method based on WindowedStream to pass in a custom window trigger (Trigger).
stream.keyBy(...).window(...).trigger(new MyTrigger())
Trigger is an internal property of a window operator, and each window assigner (WindowAssigner) corresponds to a default trigger; for Flink's built-in window types, their triggers have already been implemented. For example, for all event time windows, the default trigger is EventTimeTrigger; similarly there are ProcessingTimeTrigger and CountTrigger.
Trigger is an abstract class, and the following four abstract methods must be implemented when customizing:
- onElement(): This method is called every time an element arrives in the window.
- onEventTime(): This method will be called when the registered event time timer fires.
- onProcessingTime (): This method will be called when the registered processing time timer fires.
- clear(): This method is called when the window is closed and destroyed. Generally used to clear the custom state.
It can be seen that except for clear(), which is more like a life cycle method, the other three methods are actually responses to certain events. onElement() responds to the arrival of data elements in the stream; the other two respond to events. There is a "trigger context" (TriggerContext) object among the parameters of these methods, which can be used to register the timer callback (callback). The "timer" mentioned here is actually an "alarm clock" we set, which represents an event that will be executed at a certain point in the future; when the time progresses to the set value, the defined operate. Obviously, for the time window (TimeWindow), a timer should be set at the end time of the window, so that the calculation output of the window can be triggered when the time comes.
TriggerResult, which is an enumeration type (enum), which defines four types of operations on the window.
- CONTINUE: do nothing
- FIRE (trigger): trigger calculation, output result
- PURGE (clear): clear all data in the window, destroy the window
- FIRE_AND_PURGE (trigger and clear): trigger the calculation output and clear the window
We can see that in addition to controlling the trigger calculation, Trigger can also define when the window is closed (destroyed). The above four types are actually the results of the cross-matching of these two operations. Generally, we think that when the end time of the window is reached, the calculation output will be triggered, and then the window will be closed-it seems that these two operations should happen at the same time; but the definition of TriggerResult tells us that the two can be separated.
6.3.6.2. Remover (Evictor)
The remover is mainly used to define the logic to remove some data. Call the .evictor() method based on WindowedStream to pass in a custom remover (Evictor). Evictor is an interface, and different window types have their own pre-implemented removers.
stream.keyBy(...).window(...).evictor(new MyEvictor())
The Evictor interface defines two methods:
- evictBefore(): Define the data removal operation before executing the window function
- evictAfter(): Define the data operation after executing the window function
By default, pre-implemented removers remove data before executing window functions.
6.3.6.3. Allowed Lateness
Under the event time semantics, data may be late in the window. Flink provides a special interface that can set an "allowed maximum delay" (Allowed Lateness) for the window operator. That is to say, we can set a period of delay allowed. During this
period, the window will not be destroyed, and the data that continues to come can still enter the window and trigger calculations. It is not until the water level advances to the window end time + delay time that the content of the window is actually emptied and the window is officially closed.
Call the .allowedLateness() method based on WindowedStream, and pass in a delay time of Time type, which can indicate that delayed data within this period is allowed.
stream.keyBy(...).window(TumblingEventTimeWindows.of(Time.hours(1)))
.allowedLateness(Time.minutes(1))
6.3.6.4, put late data into the side output stream
Flink also provides another way to handle late data. We can put the late data that has not been received into the window into the "side output stream" (side output) for additional processing. The so-called side output stream is equivalent to a "branch" of the data stream. In this stream, the data that missed the car that should have been boarded and should have been discarded is placed separately.
This function can be realized by calling the .sideOutputLateData() method based on WindowedStream. The method needs to pass in an "Output Tag" (OutputTag), which is used to mark the late arrival data stream of the branch. Because what is saved is the original data in the stream, the type of outputTag is the same as the data type in the stream.
DataStream<Event> stream = env.addSource(...);
OutputTag<Event> outputTag = new OutputTag<Event>("late") {
};
stream.keyBy(...).window(TumblingEventTimeWindows.of(Time.hours(1))).sideOutputLateData(outputTag)
After putting the late data into the side output stream, it should also be possible to extract it. Based on the DataStream after the window processing is completed, call the .getSideOutput() method and pass in the corresponding output label to get the stream where the late data is located.
SingleOutputStreamOperator<AggResult> winAggStream = stream.keyBy(...).window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)
.aggregate(new MyAggregateFunction())
DataStream<Event> lateStream = winAggStream.getSideOutput(outputTag);
Note here that getSideOutput() is a method of SingleOutputStreamOperator, and the obtained side output stream data type should be consistent with the type specified by OutputTag, which can be different from the data type in the stream after window aggregation.
6.3.7, the life cycle of the window
6.3.7.1, the creation of the window
The type and basic information of the window are specified by the window assigners (window assigners), but the window will not be created in advance, but created by data drive. When the first data element that should belong to this window arrives, the corresponding window is created.
6.3.7.2. Triggering of window calculation
In addition to the window allocator, each window will have its own window functions (window functions) and trigger (trigger). Window functions can be divided into incremental aggregate functions and full window functions, which mainly define the logic of calculation in the window; triggers specify the conditions for calling window functions.
For different window types, the conditions for triggering calculations will also be different. For example, a rolling event time window should trigger calculation when the water level reaches the end time of the window, which belongs to "scheduled departure"; while a counting window, which triggers calculation when the number of elements in the window reaches the defined size, belongs to "full people". Depart." So Flink's predefined window types have corresponding built-in triggers.
For the event time window, there is another situation except the "scheduled departure" when the end time is reached. When we set the allowable delay, if the water level exceeds the window end time but has not reached the set maximum delay time, the late data arriving during this period will also trigger the window calculation. This is similar to a person who did not catch up with the bus on time and caught up with the car. At this time, the car has to stop again, open the door, and integrate new data into the statistics.
6.3.7.3. Destruction of windows
In general, when the time reaches the end point, the calculation output will be directly triggered, and then the state destruction window will be cleared. At this time, the destruction of the window can be regarded as the same moment as the trigger calculation. It should be noted here that Flink only has a destruction mechanism for the time window (TimeWindow); since the count window (CountWindow) is implemented based on the global window (GlobalWindw), and the global window will not clear the state, it will not be destroyed.
In special scenarios, the destruction and trigger calculation of windows will be different. Under event time semantics, if the allowable delay is set, the window will not be destroyed when the water level reaches the end time of the window; the time point when the window is actually completely deleted is the end time of the window plus the allowable delay time specified by the user.
6.3.7.4 Summary of window API calls
The Window API is first divided into two categories according to the time key partition. For KeyedStream after keyBy, you can call the .window() method to declare keyed windows (Keyed Windows); and if you don’t do keyBy, DataStream can also directly call .windowAll() to declare non-keyed windows. Subsequent method calls are exactly the same.
Next, first define the window allocator through the .window()/.windowAll() method to obtain WindowedStream; then give the window function (ReduceFunction/AggregateFunction/ProcessWindowFunction) through various conversion methods (reduce/aggregate/apply/process), Define the specific calculation and processing logic of the window, and get the DataStream again after conversion. These two are essential and are the most important components of the WindowOperator.
In addition, between the two, you can also call .trigger() to customize the trigger based on WindowedStream, call .evictor() to define the remover, call .allowedLateness() to specify the allowed delay time, and call .sideOutputLateData() to be late Data is written to the side output stream, these are optional APIs, and generally do not need to be implemented. And if the side output stream is defined, you can call .getSideOutput() to get the side output stream based on the DataStream after window aggregation.
Generally used for testing