During the development process, it is required PDFto provide preview and download functions for invoices of type , and PDFthe sources of type files include H5 移动端and PC 端, and the processing for these two different ends will be slightly different, which will be mentioned below.
PDF 预览There are many articles for , but none of them seem to mention the possible problems, or how to choose the corresponding specific demand scenarios. Therefore, the core of this article is to combine the actual demand scenarios to see the current various implementation solutions. Which one is more suitable, of course, I hope that everyone can correct the content of the article in the comment area, or provide a better solution.
basic requirements:
pdf 文件Supports full preview of content多页 pdf 文件support分页查看PC 端and移动端both need to support download and preview
product requirement:
- The preview on the PC side should support previewing on the current page
pdf 文件The font in the preview should be consistent with the font
PDF preview
Putting aside the various requirements above, let's first summarize several common ways to implement PDFpreview :
- With the help of various class libraries, the preview is realized based on the code , such as the package based
pdfjs-diston - Directly based on the built-in
PDFpreview , such as<iframe src="xxx">、<embed src="xxx" > - The server converts
PDFthe file into an image
Next, let's take a look at how the above solutions are implemented and whether they meet the requirements provided above!
<embed> / <iframe>implement preview
<embed>Label
<embed>Element Embeds external content at a specified location in a document , provided by an external application or other source of interactive content such as a browser plug-in.
To put it simply, the resource displayed <embed>using is a display function provided by the environment in which it is located, that is, if the current application environment supports the display of this resource, it can be displayed normally, and if it does not support it, it cannot be displayed.
It is also very simple to use:
<embed type="application/pdf" :src="pdfUrl" width="800" height="600" />
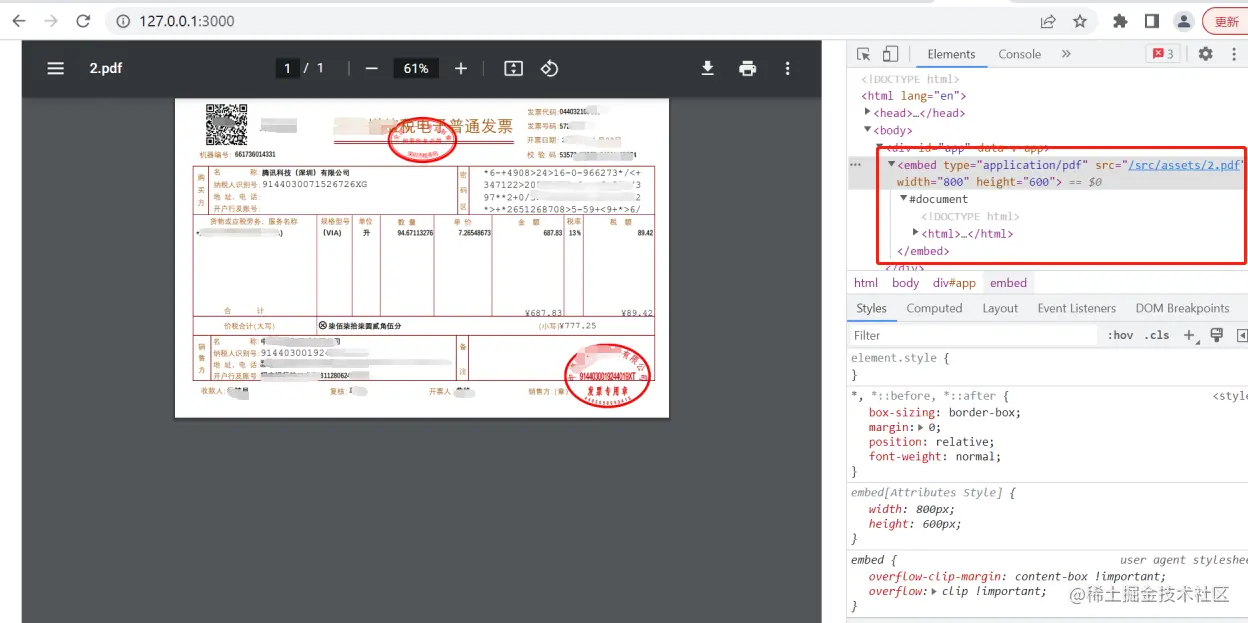
Most modern browsers have deprecated and canceled the support for browser plug-ins. It is no longer recommended to use
<embed>tags , but<img>、<iframe>、<video>、<audio>tags such as can be used instead.
<iframe>Label
The method based <iframe>on is similar to the above, and the overall effect is also the same, which is not shown here:
<iframe :src="pdfUrl" width="800" height="600" />
It is worth noting that even if you use <iframe>but after actually expanding its inner structure, you will find:

Is it inside or <embed>a tag ? What's going on here, doesn't it mean that it's best not to recommend <embed>using ?
First, let's caniusecheck the compatibility, as follows:

Let's find another browser <embed>that , for example IE, to try the effect:

<iframe>Try it instead , as follows:

Obviously, <embed>it cannot be displayed directly in an incompatible environment, <iframe>but can be recognized normally, but <iframe>the resource loaded by can not be processed by IEthe browser , that is, the essential reason is that IEthe browser does not support the preview of PDFsimilar , for example, when trying to directly http://127.0.0.1:3000/src/assets/2.pdfWhen typing in the address bar you get:

Therefore, under normal circumstances, PDFwhen , it should provide PDFa fallback link, which is realized by downloading, and this is what pdfobject does. In fact, its source code content is relatively simple, and the core is PDFObject Will detect the browser's support for inline/embedded PDF, if it supports embedding, it will embed the PDF, if the browser does not support embedding, it will not embed the PDF, and provide a fallback link to the PDF, such as in the performance ofIE :

In fact, this is just to help us write less compatible code, and it does not necessarily meet most people's scenarios. It is mentioned here only because of its connection <embed>with .
vue3-pdfjs implementation preview
Why not use it directly pdfjs-dist?
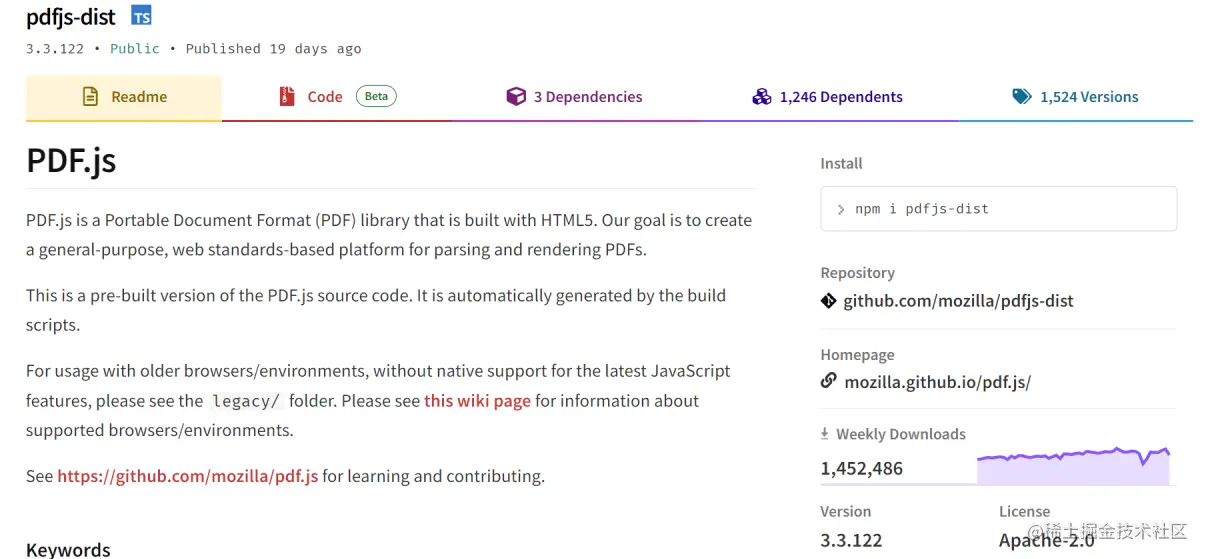
Several obvious points that can be complained about in pdf.js :
- The package name is not uniform,
npmthe package name on the website is calledpdfjs-dist, but it is also calledReadmeinpdf.js - There is no clear document as a guide, only the content of
examplesthe directory as a reference - The official examples are not friendly enough, for example, no related examples
vue/reactare - Direct use needs to introduce a lot of content that is not specified in the document
- Sometimes the
pdftext is blurry or missing parts, etc. - …
Therefore, since there is already a package based on vue/reactencapsulation , it is directly used as a demonstration here.
Specific use
The installation and use process can be referred to vue3-pdfjs, the specific Vue3sample code is as follows:
js
copy code
<script setup lang="ts">
import {
onMounted, ref } from 'vue'
import {
VuePdf, createLoadingTask } from 'vue3-pdfjs/esm'
import type {
VuePdfPropsType } from 'vue3-pdfjs/components/vue-pdf/vue-pdf-props'
// Prop type definitions can also be imported
import type {
PDFDocumentProxy } from 'pdfjs-dist/types/src/display/api'
import pdfUrl from './assets/You-Dont-Know-JS.pdf'
const pdfSrc = ref<VuePdfPropsType['src']>(pdfUrl)
const numOfPages = ref(0) onMounted(() => {
const loadingTask = createLoadingTask(pdfSrc.value)
loadingTask.promise.then((pdf: PDFDocumentProxy) => {
numOfPages.value = pdf.numPages }) }) </script>
<template>
<VuePdf v-for="page in numOfPages" :key="page" :src="pdfSrc" :page="page" />
</template>
<style> @import '@/assets/base.css';
</style>
The effect is as follows:

There is a problem
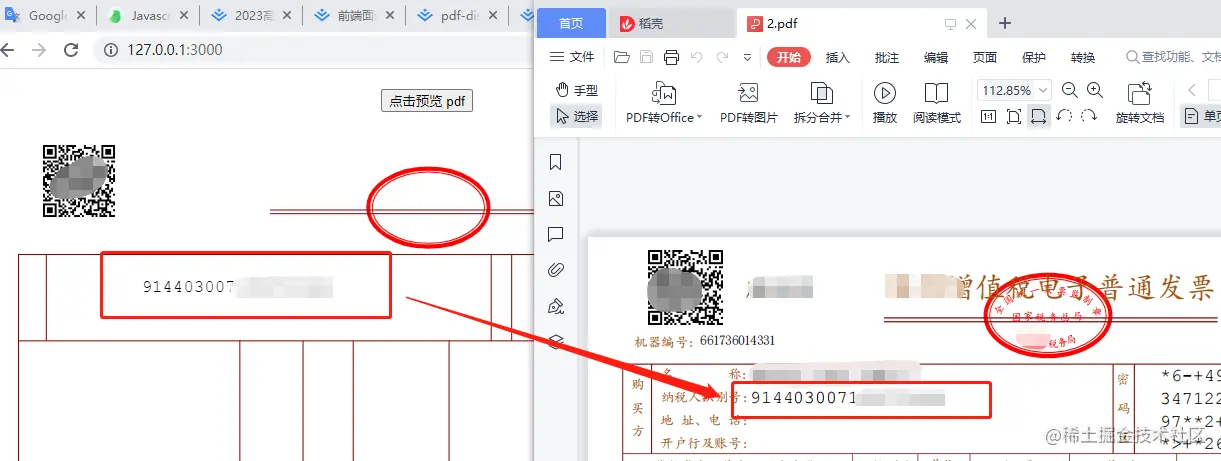
It pdf 文档seems that the loading is normal . It seems that there is no big problem. Let’s try pdf 发票to load it. However, because the actual invoice has more sensitive information, the original invoice content will not be posted here, and we will directly look at the previewed invoice content:
-
Obviously, the content is missing a lot . Although most of some invoices can be displayed, the parts such as invoice header and seal may not be displayed normally.


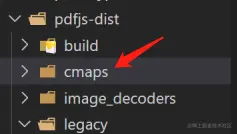
[ Note ] The complete content cannot be displayed because
pdf.jsit needs the support of some font libraries. If原 PDF 文件some fonts in do not match the font library, they will not be displayedpdf.jsin , and the font library is placedcmapsunder the folder
- In addition, the previewed font is inconsistent with the actual font, and due to the particularity of the invoice, there is a greater requirement for the consistency of the font. After all, if the font of the same invoice is inconsistent, it will lack standardization and legality (` Required The statement when the font is consistent` )
Common solution: Solve the problem that pdf.js cannot fully display the content of the pdf file . In fact, it is still analyzed according to the error information of the execution environment, and the source code content needs to be forcibly modified.
Mozilla Firefox (Firefox browser)
The built-in PDF reader of Mozilla Firefox actually means that pdf.jsyou can preview pdfthe file , as follows:
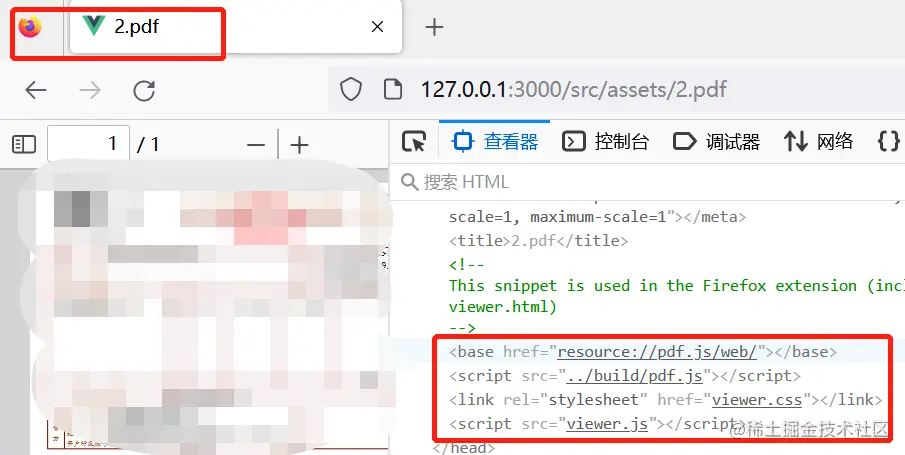
And most of the libraries based on pdf.jssecondary packaging usually cannot display the complete content when vue-pdf、vue3-pdfjspreviewing the invoice of pdfthe file , and need more or less changes to the source code, but theFirefox built-in in can completely display the content of the corresponding file.pdf.jspdf

PDFGo 图片to realize the preview
This method should go without saying. The core is that when the server responds to pdfa file , it first converts it into an image type and then returns it. The front end can directly display the specific image content.
Implementation
The following is simulated nodeby :
const pdf = require('pdf-poppler')
const path = require('path')
const Koa = require('koa')
const koaStatic = require('koa-static')
const cors = require('koa-cors')
const app = new Koa()
// 跨域
app.use(cors())
// 静态资源
app.use(koaStatic('./server'))
function getFileName(filePath) {
return filePath.split('/').pop().replace(/\.[^/.]+$/, '')
}
function pdf2png(filePath) {
// 获取文件名
const fileName = getFileName(filePath);
const dir = path.dirname(filePath);
// 配置参数
const options = {
format: 'png',
out_dir: dir,
out_prefix: fileName,
page: null,
}
// pdf 转换 png
return pdf.convert(filePath, options).then((res) => {
console.log('Successfully converted !')
return `http://127.0.0.1:4000${
dir.replace('./server','')}/${
fileName}-1.png` }).catch((error) => {
console.error(error) }) }
// 响应
app.use(async (ctx) => {
if(ctx.path.endsWith('/getPdf')){
const url = await pdf2png('./server/pdf/2.pdf')
ctx.body = {
url }
}else{
ctx.body = 'hello world!' } })
app.listen(4000)
avoid stepping on some pits
Pit 1: pdf-image is not recommended
When the server converts pdffiles into images, it needs to rely on some third-party packages. At the beginning pdf-image, this package was used, but many abnormal errors occurred during the actual conversion. After checking the source code along with the errors, it was found that it needed to rely on some additional packages internally. The tool, because it needs to use pdfinfo xxxrelated commands, and issuethere are some similar problems in its corresponding , but after trying all of them, it still fails!

Therefore, it is more recommended to pdf-poppleruse a pdftocairoprogram that comes with it to realize the ability to convert pdffrom to pictures, but its current version supports Windows and Mac OS , as follows:

Pit 2: path.basename not a function
In the above code content, we need to get the name of the file. In fact, we can simply useNode Api中path.basename(path[, suffix])to achieve the goal:

However, the following exception , and the corresponding code content and running results are as follows:
js
copy code
// 配置参数 const options = { format: 'png', out_dir: dir, out_prefix: path.baseName(filePath, path.extname(filePath)), // 发生异常 page: null, }

I haven't found the reason for this yet. I can only simply implement a getFileNamemethod to get the name of the file.
Reason for error : too dependent on the automatic prompt of the editor, output basename as baseName, yes, it is the difference between n and N.
Pit 3: Details
The above content is koastarted simulating business services. Since the ports between business services ( http://127.0.0.1:4000) and application services ( http://127.0.0.1:3000) are inconsistent, cross-domain will occur , which can be solved by . It is worth noting that sometimes when the business server restarts, it may not be kick in.koa-corskoa-cors
Since the content of the response is directly returned in koathe general middleware, if you need to support business services to provide access to static resources , you can do koa-staticso through . It is worth noting that when you koa-staticspecify static file resources through , such as app.use(koaStatic('./static'))this If you directly http://127.0.0.1:4000/static/pdf/xxx.pngpass , you will get a 404 Not Found error. The reason is koa-staticthat you directly set /static/ as the root path , so the correct access path is: http://127.0.0.1:4000/pdf/xxx.png.
Effect demonstration
The content of the invoice is inconvenient to display and will not be displayed directly here. You only need to pay attention to the generated pictures and paths:

PDF download
The download here actually refers not only to the download pdfof , but to the download methods supported by the client side. The most common ones are as follows:
- a tag , e.g.
<a href="xxxx" download="xxx">下载</a> - location.href , e.g.
window.location.href = xxx - window.open , for example
window.open(xxx) - Content-disposition , such as
Content-disposition:attachment;filename="xxx"
<a>Realize download
<a>The downloadattribute is used to instruct the browser to download the URL specified by href instead of navigating to the resource, and usually prompts the user to save it as a local file. If downloadthe attribute has specified content, this value will be used as a pre-populated value during the download and save process filename , mainly because of the following reasons:
- This value may be
JavaScriptdynamically Content-Dispositionordownloadthe attribute specified in takes precedence overa.download
This should be the most familiar method for everyone, but familiarity is familiar, and there are some points worth noting:
downloadAttributes only apply to same-origin URLs- If a different file name is specified in the attribute in the HTTP response header, the content in will be used first
Content-DispositionContent-Disposition - HTTP If the HTTP response header
Content-Dispositionis set to , then the attribute ofContent-Disposition='inline'will be used first in FirefoxContent-Dispositiondownload
Static way:
<a href="http://127.0.0.1:4000/pdf/2-1.png" download="2.pdf">下载</a>
Dynamic way:
function download(url, filename){
const a = document.createElement("a");
// 创建 a 标签
a.href = url;
// 下载路径
a.download = filename;
// 下载属性,文件名
a.style.display = "none"; // 不可见
document.body.appendChild(a); // 挂载
a.click(); // 触发点击事件
document.body.removeChild(a); // 移除
}
blob method
if (reqConf.responseType == 'blob') {
// 返回文件名
let contentDisposition = config.headers['content-disposition'];
if (!contentDisposition) {
contentDisposition = `;filename=${
decodeURI(config.headers.filename)}`;
}
const fileName = window.decodeURI(contentDisposition.split(`filename=`)[1]);
// 文件类型
const suffix = fileName.split('.')[1];
// 创建 blob 对象
const blob = new Blob([config.data], {
type: FileType[suffix], });
const link = document.createElement('a');
link.style.display = 'none';
link.href = URL.createObjectURL(blob);
// 创建 url 对象
link.download = fileName;
// 下载后文件名
document.body.appendChild(link);
link.click();
document.body.removeChild(link);
// 移除隐藏的 a 标签
URL.revokeObjectURL(link.href);
// 销毁 url 对象
}
Content-dispositionand location.href/window.openimplement the download
This seems to be three downloading methods, but it is actually one, and it is still Content-dispositionbased on .
Content-DispositionThe response header indicates in what form the content of the reply should be displayed , whether it should be displayed inline (that is, a part of a webpage or a page), or downloaded and saved locally as an attachment, as follows:
-
inline: is the default value , indicating that the message in the reply will be displayed in the form of a part of the page or the entire pageContent-Disposition: inline -
attachment: Setting this value means that the message body should be downloaded locally, and most browsers will present a "save as" dialog box and pre-fillfilenamethe value of as the downloaded file nameContent-Disposition: attachment; filename="filename.jpg"
Therefore location.href='xxx', window.open(xxx)the way of downloading based on and is based on the form Content-Disposition: attachment; filename="filename.jpg"of , or it triggers the download behavior of the browser itself, which meets this condition, whether it is through atag jump , location.href navigation , window.open to open a new page , Directly enter the URL on the address bar, etc. can be downloaded.
H5 mobile terminal download
H5For the preview all of the above methods can be implemented, but the download operation is different, because this is to distinguish the scenarios:
- Based on mobile browser
- Based on WeChat built-in browser
The download method based on the mobile browser is roughly the same as the content mentioned above. In essence, as long as the client supports downloading, there is no problem. However, in the built-in browser of WeChat you may not be able to use the conventional download method. expected:
AndroidUsing the normal download method in , a dialog box will pop up, asking if you need to wake up the mobile browser to download the corresponding resources, but some models will not- None of the above methods can be downloaded
IOSin , so usually a new one will be opened to provide a preview. Some models support the save operation by long pressing the screen in the new page , but not all models support it.webview
The essential reason is to block any download links in the WeChat built-in browser , such as APP download links , ordinary file download links , and so on.
How else can I download the H5 mobile terminal?
Since this is the shielding of the download function by the built-in browser environment of WeChat, there is no need to consider ( `I dare not even think about` ) to realize the download function based on the built-in browser of WeChat. Instead, we should consider how to realize the indirect download :
- Determine whether the current browser belongs to the built-in browser of WeChat , and if so, help the user to automatically wake up the mobile browser to download, but not all models support the wake up operation, so it is best to prompt the user to download directly through the mobile browser, for convenience Users can realize the function of one-key copy to assist
- The other is to directly prompt that only
PCthe terminal , and give up the download operation on the mobile terminal
at last
To sum up, there may be no way to achieve a perfect way in the actual pdfpreview process, especially for files like invoices , there are still the following problems:pdf
- There is no guarantee that all
h5mobile terminals have the download function - There is no
pdfguarantee that the previewed font will be consistent with the actual invoice font
Most of the existing preview methods are implemented based pdf.json the method, and the method pdf.jsis PDFJs.getDocument(url/buffer)used to obtain content based on the file address or data stream, and then process and render the file through the method. If you are interested, you can study the source code .canvaspdfpdf.js
pdf.jsThe related problem is that if the corresponding pdffile contains pdf.jsa font that does not exist in , then it cannot be completely rendered, and the rendered font will be different from the original pdffile font.
For these two points, it is found that Google's built-in pdfplug-ins seem to provide good support, which means that if other browsers include Google-related plug-ins (such as: Edge, QQ Browser), they can directly <iframe>implement preview based on the method, and Or for more stringent font consistency, you can only view the source file by downloading.
What if the product requirements cannot be met?
For example, the solutions discussed above cannot actually meet some of the requirements mentioned at the beginning of the article. The purpose of product requirements is also to provide a better user experience ( `under normal circumstances` ), but these requirements still need to be implemented in technology, and the degree of technical support needs our timely feedback (` Unless your product is technical experience` ), so as a developer, you need to provide sufficient content to prove to the product, and then give some indirect implementation solutions (
又或者产品自己就给出新的方案) to see if it meets the second expectation . The core is reasonable communication + other solutions (每个人的处境不同,实际情况也许 ... 懂得都懂).

The above are some personal opinions and understandings. If there is something inappropriate, you can correct it in the comment area! ! !
Hope this article helps you! ! !