1. Simple understanding of HTTP
The HTTP protocol generally refers to HTTP (Hyper Text Transfer Protocol).
HTTP is a simple request/response protocol that runs on top of TCP.
HTTP is a communication protocol based on TCP/IP to transfer data (HTML files, image files, query results, etc.).
HTTP is a transmission protocol for transmitting hypertext from a World Wide Web (WWW: World Wide Web) server to a local browser.
HTTP specifies what kind of messages a client may send to a server and what kind of responses it may get.
The headers of HTTP request and response messages are given in ASCII.
HTTP message content has a MIME-like format.
HTTP is based on the architectural model of client/server ( Client/Server ), which exchanges information through a reliable link and is a stateless request/response protocol.
An HTTP "client" is an application (web browser or any other client) that connects to a server for the purpose of sending one or more HTTP requests to the server.
An HTTP "server" is also an application (usually a web service, such as Nodejs, Apache web server or IIS server, etc.), by receiving client requests and sending HTTP response data to the client.
HTTP uses Uniform Resource Identifiers (Uniform Resource Identifiers, URI) to transfer data and establish connections.
Once the connection is established, data messages are sent in a format similar to that used by Internet mail [RFC5322] and Multipurpose Internet Mail Extensions (MIME) [RFC2045].
2. HTTP message structure
2.1. Client request message
The request message that the client sends an HTTP request to the server includes the following format: request line (request line), request header (header), blank line and request data. The following figure shows the general format of the request message .

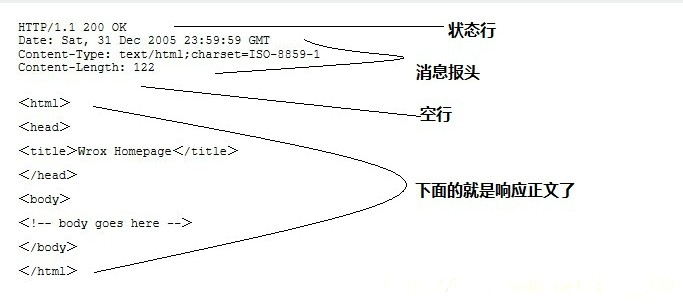
2.2. Server response message
The HTTP response also consists of four parts, namely: status line, message header, blank line, and response body .
3. HTTP status code
When a viewer visits a web page, the viewer's browser will send a request to the server where the web page is located. Before the browser receives and displays the webpage, the server where the webpage is located will return an information header (server header) containing the HTTP status code in response to the browser's request.
HTTP status codes consist of three decimal digits, the first decimal digit defines the type of status code.
| Classification | status code range | Category description |
|---|---|---|
| 1** | 100 -- 199 | Information, the server receives the request and needs the requester to continue to perform the operation |
| 2** | 200 -- 299 | Success, the operation was successfully received and processed |
| 3** | 300 -- 399 | Redirected, further action is required to complete the request |
| 4** | 400 -- 499 | Client error, the request contained syntax errors or could not be completed |
| 5** | 500 -- 599 | Server error, the server encountered an error while processing the request |
List of HTTP status codes
| status code | English name of status code | Chinese description |
|---|---|---|
| information | ||
| 100 | Continue | continue. The client should proceed with its request |
| 101 | Switching Protocols | Switch protocols. The server switches protocols at the client's request. Can only switch to a higher-level protocol, for example, switch to a new version of the HTTP protocol |
| success | ||
| 200 | OK | The request was successful. Generally used for GET and POST requests |
| 201 | Created | created. Successfully requested and created a new resource |
| 202 | Accepted | accepted. The request has been accepted but not completed |
| 203 | Non-Authoritative Information | Unauthorized information. The request was successful. But the returned meta information is not in the original server, but a copy |
| 204 | No Content | no content. The server processed successfully, but no content was returned. Ensures that the browser continues to display the current document if the web page is not updated |
| 205 | Reset Content | Reset content. The server processing is successful, and the user terminal (eg: browser) should reset the document view. The browser's form field can be cleared by this return code |
| 206 | Partial Content | Part. The server successfully processed a partial GET request |
| redirect | ||
| 300 | Multiple Choices | multiple choices. The requested resource can include multiple locations, and a list of resource characteristics and addresses can be returned for user terminal (eg: browser) selection |
| 301 | Moved Permanently | Move permanently. The requested resource has been permanently moved to the new URI, the returned information will include the new URI, and the browser will automatically be directed to the new URI. Any future requests should use the new URI instead |
| 302 | Found | Temporary move. Similar to 301. But the resources are only moved temporarily. Clients should continue to use the original URI |
| 303 | See Other | View other addresses. Similar to 301. View using GET and POST requests |
| 304 | Not Modified | unmodified. The requested resource has not been modified. When the server returns this status code, no resource will be returned. Clients usually cache accessed resources by providing a header indicating that the client wishes to return only resources modified after a specified date |
| 305 | Use Proxy | Use a proxy. The requested resource must be accessed through a proxy |
| 306 | Unused | Deprecated HTTP status codes |
| 307 | Temporary Redirect | Temporary redirection. Similar to 302. Redirect with GET request |
| client error | ||
| 400 | Bad Request | The syntax of the client's request is incorrect and the server cannot understand it |
| 401 | Unauthorized | The request requires user authentication |
| 402 | Payment Required | reserved for future use |
| 403 | Forbidden | The server understands the client's request, but refuses to fulfill it |
| 404 | Not Found | The server was unable to find the resource (web page) requested by the client. This code allows website designers to set up a "The resource you requested could not be found" personality page |
| 405 | Method Not Allowed | Method forbidden in client request |
| 406 | Not Acceptable | The server was unable to complete the request based on the content characteristics requested by the client |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed | 服务器无法满足Expect的请求头信息 |
| 服务端错误 | ||
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
四、根据 HTTP 标准,HTTP 请求可以使用多种请求方法。
HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD 方法。
HTTP1.1 新增了六种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法。
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回实体主体。 |
| 2 | HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| 5 | DELETE | 请求服务器删除指定的页面。 |
| 6 | CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 |
| 7 | OPTIONS | 允许客户端查看服务器的性能。 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| 9 | PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新 。 |
虽然 HTTP 的请求方式有这么多种,但是我们在实际应用中常用的也就是 get 和 post,其他请求方式也都可以通过这两种方式间接的来实现。
GET请求和POST请求是HTTP协议中常用的两种请求方法,它们有以下区别:
| GET请求的数据在URL中传输 请求的数据会被附加到URL的末尾,可以在浏览器地址栏中看到 GET请求不应该被用于传递敏感信息,因为URL参数可以被其他人看到 |
POST请求的数据在请求体中传输 请求的数据会被放在HTTP请求消息体中,不会出现在URL中 POST请求比GET请求更安全,因为请求参数不会被暴露在URL中 |
| GET请求的数据量较小 一般不超过2048个字符,适合用于请求少量的数据 |
POST请求可以传输大量数据 适合用于请求大量或敏感的数据 |
| GET请求的数据有长度限制 | POST请求没有长度限制 |
| GET请求可被缓存 | POST请求不能被缓存 |
| GET请求一般用于获取数据 比如搜索、查看博客文章、获取图片等 |
POST请求一般用于提交数据 通常用于提交数据,比如注册、登录、提交表单等 |
| GET请求只能使用ASCII字符 | POST请求没有限制 |
五、HTTP 响应头信息
HTTP请求头提供了关于请求,响应或者其他的发送实体的信息。
在本章节中我们将具体来介绍HTTP响应头信息。
| 应答头 | 说明 |
|---|---|
| Allow | 服务器支持哪些请求方法(如GET、POST等)。 |
| Content-Encoding | 文档的编码(Encode)方法。只有在解码之后才可以得到Content-Type头指定的内容类型。利用gzip压缩文档能够显著地减少HTML文档的下载时间。Java的GZIPOutputStream可以很方便地进行gzip压缩,但只有Unix上的Netscape和Windows上的IE 4、IE 5才支持它。因此,Servlet应该通过查看Accept-Encoding头(即request.getHeader("Accept-Encoding"))检查浏览器是否支持gzip,为支持gzip的浏览器返回经gzip压缩的HTML页面,为其他浏览器返回普通页面。 |
| Content-Length | 表示内容长度。只有当浏览器使用持久HTTP连接时才需要这个数据。如果你想要利用持久连接的优势,可以把输出文档写入 ByteArrayOutputStream,完成后查看其大小,然后把该值放入Content-Length头,最后通过byteArrayStream.writeTo(response.getOutputStream()发送内容。 |
| Content-Type | 表示后面的文档属于什么MIME类型。Servlet默认为text/plain,但通常需要显式地指定为text/html。由于经常要设置Content-Type,因此HttpServletResponse提供了一个专用的方法setContentType。 |
| Date | 当前的GMT时间。你可以用setDateHeader来设置这个头以避免转换时间格式的麻烦。 |
| Expires | 应该在什么时候认为文档已经过期,从而不再缓存它? |
| Last-Modified | 文档的最后改动时间。客户可以通过If-Modified-Since请求头提供一个日期,该请求将被视为一个条件GET,只有改动时间迟于指定时间的文档才会返回,否则返回一个304(Not Modified)状态。Last-Modified也可用setDateHeader方法来设置。 |
| Location | 表示客户应当到哪里去提取文档。Location通常不是直接设置的,而是通过HttpServletResponse的sendRedirect方法,该方法同时设置状态代码为302。 |
| Refresh | 表示浏览器应该在多少时间之后刷新文档,以秒计。除了刷新当前文档之外,你还可以通过setHeader("Refresh", "5; URL=http://host/path")让浏览器读取指定的页面。 |
| Server | 服务器名字。Servlet一般不设置这个值,而是由Web服务器自己设置。 |
| Set-Cookie | 设置和页面关联的Cookie。Servlet不应使用response.setHeader("Set-Cookie", ...),而是应使用HttpServletResponse提供的专用方法addCookie。参见下文有关Cookie设置的讨论。 |
| WWW-Authenticate | 客户应该在Authorization头中提供什么类型的授权信息?在包含401(Unauthorized)状态行的应答中这个头是必需的。例如,response.setHeader("WWW-Authenticate", "BASIC realm=\"executives\"")。 |
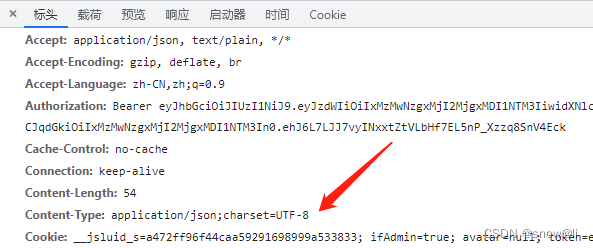
六、HTTP content-type
Content-Type 标头告诉客户端实际返回的内容的内容类型。
Content-Type(内容类型),一般是指网页中存在的 Content-Type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件,这就是经常看到一些网页点击的结果却是下载一个文件或一张图片的原因。
语法格式:
Content-Type: text/html; charset=utf-8
Content-Type: multipart/form-data; boundary=something
实例:
| 常见的媒体格式类型如下 | |
| text/html | HTML格式 |
| text/plain | 纯文本格式 |
| text/xml | XML格式 |
| image/gif | gif图片格式 |
| image/jpeg | jpg图片格式 |
| image/png | png图片格式 |
| 以application开头的媒体格式类型 | |
| application/xhtml+xml | XHTML格式 |
| application/xml | XML数据格式 |
| application/atom+xml | Atom XML聚合格式 |
| application/json | JSON数据格式 |
| application/pdf | pdf格式 |
| application/msword | Word文档格式 |
| application/octet-stream | 二进制流数据(如常见的文件下载) |
| application/x-www-form-urlencoded | <form encType=””>中默认的encType,form表单数据被编码为key/value格式发送到服务器(表单默认的提交数据的格式) |
| 另外一种常见的媒体格式是上传文件之时使用的 | |
| multipart/form-data | 需要在表单中进行文件上传时,就需要使用该格式 |
小程序:播放视频_微信小程序ios无法播放视频_snow@li的博客-CSDN博客
七、HTTP缓存
《四》HTTP 缓存_http缓存_花铛的博客-CSDN博客
八、HTTPS - SSL加密
HTTPS 四大安全通信原则:机密性、完整性、身份认证、不可否认。
九、HTTP不同版本的区别
9.1、HTTP 0.9版本
0.9协议是适用于各种数据信息的简洁快速协议,但是远不能满足日益发展的各种应用的需要。0.9协议就是一个交换信息的无序协议,仅仅限于文字。由于无法进行内容的协商,在双发的握手和协议中,并有规定双发的内容是什么,也就是图片是无法显示和处理的。
9.2、HTTP 1.0版本
到了1.0协议阶段,也就是在1982年,Tim Berners-Lee提出了HTTP/1.0。在此后的不断丰富和发展中,HTTP/1.0成为最重要的面向事务的应用层协议。该协议对每一次请求/响应建立并拆除一次连接。其特点是简单、易于管理,所以它符合了大家的需要,得到了广泛的应用。
9.3、HTTP 1.1版本
在1.0协议中,双方规定了连接方式和连接类型,这已经极大扩展了HTTP的领域,但对于互联网最重要的速度和效率,并没有太多的考虑。毕竟,作为协议的制定者,当时也没有想到HTTP会有那么快的普及速度。
浏览器阻塞(HOL blocking)
浏览器对于同一个域名,一般PC端浏览器会针对单个域名的server同时建立6~8个连接,手机端的连接数则一般控制在4~6个(这个根据浏览器内核不同可能会有所差异),超过浏览器最大连接数限制,后续请求就会被阻塞。比如我们经常会使用到雪碧图就是这个原因。
9.4、HTTP 1.x 缺点
1、HTTP/1.0一次只允许在一个TCP连接上发起一个请求,HTTP/1.1使用的流水线技术也只能部分处理请求并发,仍然会存在队列头阻塞问题,因此客户端在需要发起多次请求时,通常会采用建立多连接来减少延迟。
2、单向请求,只能由客户端发起。
3、请求报文与响应报文首部信息冗余量大。
4、数据未压缩,导致数据的传输量大。
9.5、HTTP2.0版本
HTTP2.0的前身是HTTP1.0和HTTP1.1。虽然之前仅仅只有两个版本,但这两个版本所包含的协议规范之庞大,足以让任何一个有经验的工程师为之头疼。网络协议新版本并不会马上取代旧版本。实际上,1.0和1.1在之后很长的一段时间内一直并存,这是由于网络基础设施更新缓慢所决定的。
9.5.1、二进制分帧
在不改变HTTP1.x的语义、方法、状态码、URL以及首部字段的情况下,HTTP2.0是突破HTTP1.1的性能限制,改进传输性能,实现低延迟高吞吐量关键之一就是在应用层(HTTP)和传输层(TCP)之间增加一个二进制分帧层。
9.5.2、首部压缩
HTTP1.1并不支持HTTP首部压缩,为此SPDY和HTTP2.0出现了。SPDY是用的是DEFLATE算法,而HTTP2.0则使用了专门为首部压缩设计的HPACK算法。HPACK算法减少了header的大小。并在两端维护了索引表,用于记录出现过的header,后面在传输过程中就可以传输已经记录过的header的键名,对端收到数据后就可以通过键名找到对应的值。
9.5.3、多路复用(Multiplexing)/ 连接共享
在HTTP1.x中,我们经常会使用到雪碧图、使用多个域名等方式来进行优化,都是因为浏览器限制了同一个域名下的请求数量,当页面需要请求很多资源的时候,队头阻塞(Head of line blocking)会导致在达到最大请求时,资源需要等待其他资源请求完成后才能继续发送。
有了新的分帧机制后,http/2 不再依赖多个TCP连接去实现多流并行。
每个数据流(请求或响应)都拆分成很多互不依赖的帧,因为具有标识字段(Stream id、flags)。因此帧可以无序发送(即多个请求分解成帧可以通过一个TCP连接交错发送),最后当帧到达服务端之后,就可以根据 Stream Identifier 来重新组合得到完整的请求。
http 2.0 的TCP连接都是持久化的,而且客户端与服务器之间也只需要一个连接(每个域名一个连接)即可。此连接可以承载数十或数百个流的复用。多路复用意味着来自很多流的数据包能够混合在一起通过同样连接传输。当到达终点时,再根据不同帧首部的流标识符重新连接将不同的数据流进行组装。
9.5.4、请求优先
把HTTP消息分为很多独立帧之后,就可以通过优化这些帧的交错和传输顺序进一步优化性能。
9.5.5、服务器推送
HTTP2.0新增的一个强大的新功能,就是服务器可以对一个客户端请求发送多个响应。服务器向客户端推送资源无需客户端明确的请求。
服务端推送是一种在客户端请求之前发送数据的机制。在HTTP2.0中,服务器可以对一个客户端的请求发送多个响应。如果一个请求是由你的主页发送的,服务器可能会响应主页内容、logo以及样式表,因为他知道客户端会用到这些东西。这样不但减轻了数据传送冗余步骤,也加快了页面响应的速度,提高了用户体验。
推送的安全限制:所有推送的资源都必须遵守同源策略。换句话说,服务器不能随便将第三方资源推送给客户端,而必须是经过双方的确认才行。
9.6、HTTP 3.0版本
HTTP 3.0 is a new web protocol designed to speed up the speed and performance of websites. This is an upgraded version of HTTP/2, which uses the QUIC protocol, which is a protocol based on UDP (QUIC protocol is based on the UDP protocol), designed to provide faster connections and better security performance. HTTP 3.0 is designed to reduce latency and increase speed to meet the requirements of modern web applications.
HTTP/3.0_Code cash out ability blog-CSDN blog
10. Welcome to exchange and correct, follow me, and learn together.
reference link
Network: TCP protocol three-way handshake and four-way handshake - snow@li's blog - CSDN blog
What is http2.0? -Tencent Cloud Developer Community-Tencent Cloud