Hello everyone, I am Yi An, and today we will study the core principles of RPC together.
What are RPCs?
The full name of RPC is Remote Procedure Call, that is, remote procedure call. Simple interpretation of the literal meaning, remote must refer to cross-machine rather than local, so it needs to use network programming to achieve, but not just access to another machine's application through network communication, it can be called RPC called? Obviously not enough.
The RPC I understand is to help us shield the details of network programming, and achieve the same experience as calling a local method (a method in the same project) when calling a remote method. We don't need to write a lot of code that has nothing to do with the business because this method is a remote call. .
This is like a bridge built on a small river connecting the two banks of the river. If there is no small bridge, we need to go boating, detour and other ways to reach the opposite side, but with the small bridge, we can walk on the same road Get to the opposite side, and experience no difference from walking on the road. So I think that the role of RPC is reflected in the following two aspects:
-
Shielding the difference between remote calls and local calls makes us feel like calling methods in the project; -
Hiding the complexity of the underlying network communication allows us to focus more on business logic.
RPC communication process
After understanding what RPC is, let's talk about the communication process of the RPC framework, so that we can further understand RPC.
As mentioned earlier, RPC can help our application complete remote calls transparently. The party that initiates the call request is called the caller, and the called party is called the service provider. In order to achieve this goal, we need to encapsulate the entire communication details in the RPC framework. What steps will a complete RPC involve?
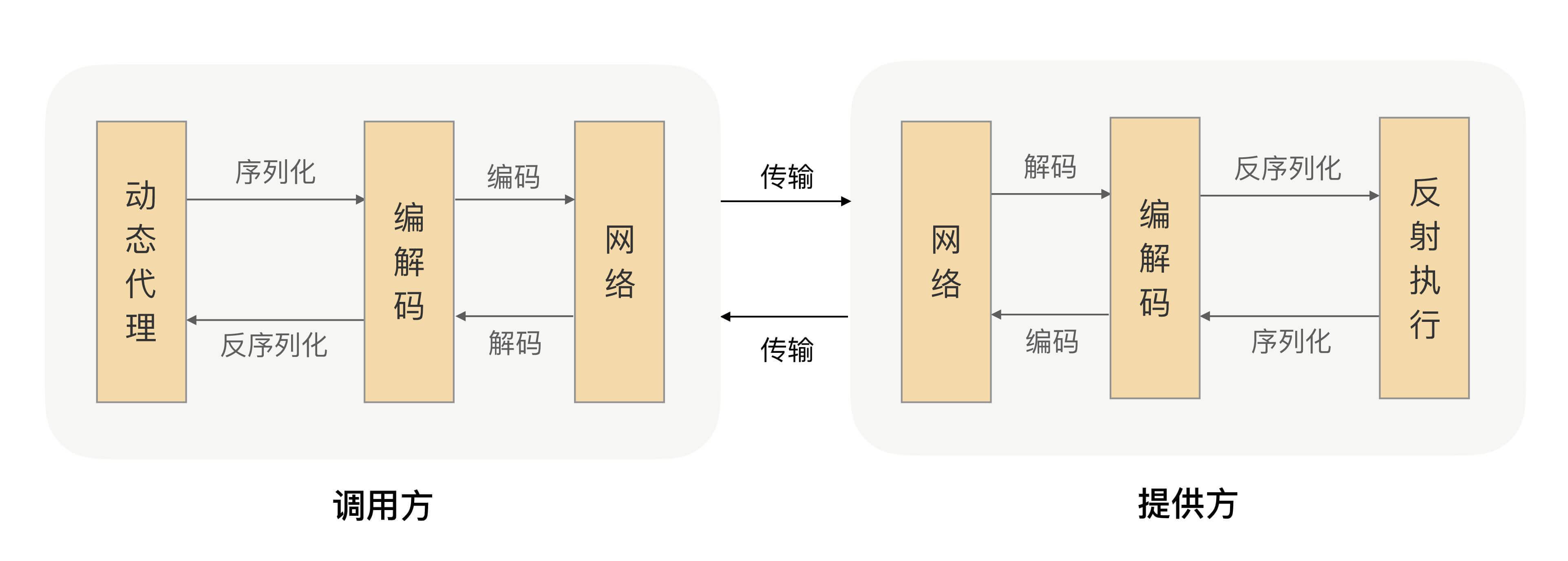
We already know that RPC is a remote call, so data must be transmitted through the network, and RPC is often used for data interaction between business systems, and its reliability needs to be guaranteed, so RPC generally uses TCP for transmission by default. Our commonly used HTTP protocol is also based on TCP.
The data transmitted over the network must be binary data, but the incoming and outgoing parameters requested by the caller are all objects. Objects cannot be directly transmitted on the network. It needs to be converted into a transmissible binary in advance, and the conversion algorithm is required to be reversible. This process is generally called "serialization".
After the caller continuously serializes the request parameters into binary, it transmits it to the service provider through TCP. The service provider receives binary data from the TCP channel, so how does it know where the data of a request ends and what type of request it is?
Here we can think of a highway, which has many exits. In order to let the driver know where to go, the management department will set up many signs on the road, and indicate on the signs where the next exit is and how many exits there are. Far. Back to the scene of data packet identification, can we also create some "signposts" and mark the type and length of the data packet on it, so that the data can be parsed correctly. It is indeed possible, and we call the agreed content of the data format a "protocol". Most protocols are divided into two parts, the data header and the message body. The data header is generally used for identification, including protocol identification, data size, request type, serialization type and other information; the message body is mainly the requested business parameter information and extended attributes.
According to the protocol format, the service provider can correctly separate different requests from the binary data, and reversely restore the binary message body to the request object according to the request type and serialization type. This process is called "deserialization".
The service provider then finds the corresponding implementation class based on the deserialized request object, completes the real method call, and then serializes the execution result and writes it back to the corresponding TCP channel. After the caller obtains the response packet, it deserializes it into a response object, so that the caller completes an RPC call.
Do the above processes form a complete RPC?
It seems that there is still something missing. Because for R&D personnel, it is necessary to master too many underlying details of RPC. It is necessary to manually write code to construct requests, call serialization, and make network calls. The entire API is very unfriendly.
So what can we do to simplify the API, shield RPC details, so that the user only needs to pay attention to the business interface, and call the remote as if calling the local?
If you know Spring, you must admire its AOP technology. Its core is to use dynamic proxy technology to intercept and enhance methods through bytecode enhancement, so as to add additional processing logic as needed. In fact, this technology can also be applied to RPC scenarios to solve the problems we just faced.
由服务提供者给出业务接口声明,在调用方的程序里面,RPC框架根据调用的服务接口提前生成动态代理实现类,并通过依赖注入等技术注入到声明了该接口的相关业务逻辑里面。该代理实现类会拦截所有的方法调用,在提供的方法处理逻辑里面完成一整套的远程调用,并把远程调用结果返回给调用方,这样调用方在调用远程方法的时候就获得了像调用本地接口一样的体验。
到这里,一个简单版本的RPC框架就实现了:
RPC在架构中的位置
围绕RPC我们讲了这么多,那RPC在架构中究竟处于什么位置呢?
如刚才所讲,RPC是解决应用间通信的一种方式,而无论是在一个大型的分布式应用系统还是中小型系统中,应用架构最终都会从“单体”演进成“微服务化”,整个应用系统会被拆分为多个不同功能的应用,并将它们部署在不同的服务器中,而应用之间会通过RPC进行通信,可以说RPC对应的是整个分布式应用系统,就像是“经络”一样的存在。
那么如果没有RPC,我们现实中的开发过程是怎样的一个体验呢?
所有的功能代码都会被我们堆砌在一个大项目中,开发过程中你可能要改一行代码,但改完后编译会花掉你2分钟,编译完想运行起来验证下结果可能要5分钟,是不是很酸爽?更难受的是在人数比较多的团队里面,多人协同开发的时候,如果团队其他人把接口定义改了,你连编译通过的机会都没有,系统直接报错,从而导致整个团队的开发效率都会非常低下。而且当我们准备要上线发版本的时候,QA也很难评估这次的测试范围,为了保险起见我们只能把所有的功能进行回归测试,这样会导致我们上线新功能的整体周期都特别长。
无论你是研发还是架构师,我相信这种系统架构我们肯定都不能接受,那怎么才能解决这个问题呢?
我们首先都会想到可以采用“分而治之”的思想来进行拆分,但是拆分完的系统怎么保持跟未拆分前的调用方式一样呢?我们总不能因为架构升级,就把所有的代码都推倒重写一遍吧。
RPC框架能够帮助我们解决系统拆分后的通信问题,并且能让我们像调用本地一样去调用远程方法。 利用RPC我们不仅可以很方便地将应用架构从“单体”演进成“微服务化”,而且还能解决实际开发过程中的效率低下、系统耦合等问题,这样可以使得我们的系统架构整体清晰、健壮,应用可运维度增强。
当然RPC不仅可以用来解决通信问题,它还被用在了很多其他场景,比如:发MQ、分布式缓存、数据库等。比如下面这个应用示例:
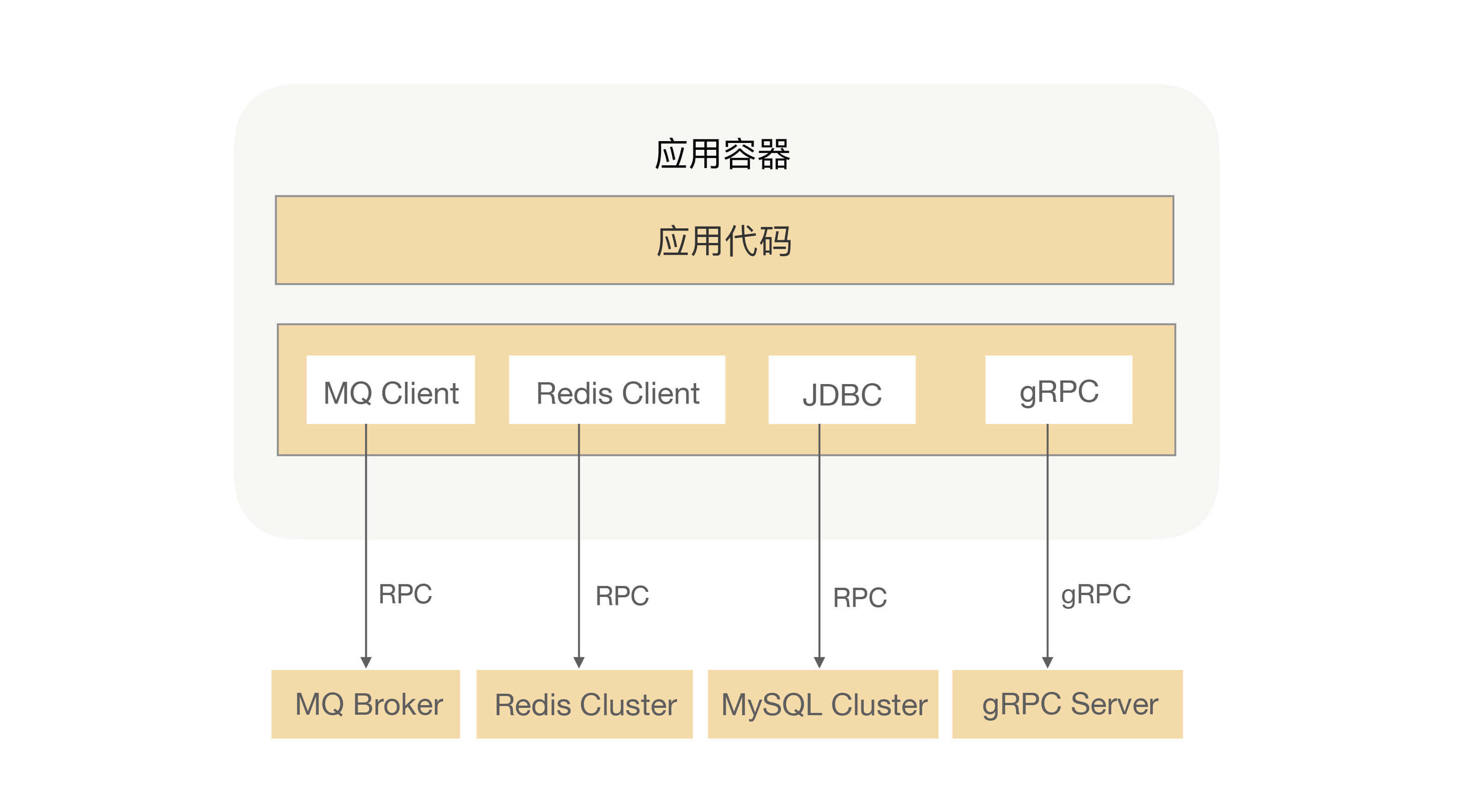
这个应用中,使用了MQ来处理异步流程、Redis缓存热点数据、MySQL持久化数据,还有就是在系统中调用另外一个业务系统的接口,对我的应用来说这些都是属于RPC调用,而MQ、MySQL持久化的数据也会存在于一个分布式文件系统中,他们之间的调用也是需要用RPC来完成数据交互的。
由此可见,RPC确实是我们日常开发中经常接触的东西,只是被包装成了各种框架,导致我们很少意识到这就是RPC,让RPC变成了我们最“熟悉的陌生人”。现在,回过头想想,我说RPC是整个应用系统的“经络”,这不为过吧?我们真的很有必要学好RPC,不仅因为RPC是构建复杂系统的基石,还是提升自身认知的利器。
总结
本文主要讲了下RPC的原理,RPC就是提供一种透明调用机制,让使用者不必显式地区分本地调用和远程调用。RPC虽然可以帮助开发者屏蔽远程调用跟本地调用的区别,但毕竟涉及到远程网络通信,所以这里还是有很多使用上的区别,比如:
-
调用过程中超时了怎么处理业务? -
什么场景下最适合使用RPC? -
什么时候才需要考虑开启压缩?
无论你是一个初级开发者还是高级开发者,RPC都应该是你日常开发过程中绕不开的一个话题,所以作为软件开发者的我们,真的很有必要详细地了解RPC实现细节。只有这样,才能帮助我们更好地在日常工作中使用RPC。
本文由 mdnice 多平台发布