1. Definition
The unit of measurement for computing power is FLOPS (Floating-point operations per second), and FLOPS represents the number of floating-point operations per second. In specific use, there will be a letter constant in front of FLOPS, such as TFLOPS, PFLOPS. The letters T and P represent the number of times, T stands for one trillion times per second, and P stands for one trillion times per second.
In addition to the number of calculations, the accuracy of computing power is also considered when measuring the level of computing power. For example, the computing power provided by the 1000FLOPS AI computing center is the same as the computing power provided by the 1000FLOPS supercomputer, but due to the difference in precision, the actual computing power level is also very different.
According to the different accuracy of the data involved in the operation, the computing power can be divided into
- double-precision floating point (64-bit, FP64)
- Single-precision floating-point number (32 bits, FP32) , occupying 4 bytes, a total of 32 bits, of which 1 bit is a sign bit, 8 bits are an exponent bit, and 23 bits are a decimal place
- Half-precision floating-point number (16 bits, FP16), occupying 2 bytes, a total of 16 bits, of which 1 bit is a sign bit, 5 bits are an exponent bit, and 10 bits are significant digits (decimals). Compared with FP32, the access of FP16 The memory consumption is only 1/2, so FP16 is a data format more suitable for AI calculation on the mobile terminal side.
- Use 5bit to represent the exponent, 10bit to represent the decimal, occupying 2 bytes;
- 8-bit integer numbers (INT8, INT4), occupying 1 byte, INT8 is a fixed-point calculation method, representing integer operations, generally quantified by floating-point operations. In binary, a "0" or "1" is a bit, and INT8 means that 8 bits are used to represent a number. Therefore, although INT8 has lower precision than FP16, it has small data volume, low energy consumption, and relatively faster calculation speed, which is more in line with the characteristics of end-side computing;
- Mixed precision: Simply speaking, use fp16 for multiplication and storage, and only use fp32 for addition to avoid accumulation errors;
In terms of the range of data representation, the integer ranges represented by FP32 and FP16 are the same, and the decimal parts are represented differently, and there are rounding errors; the data ranges represented by FP32 and FP16 are different, and FP16 has the risk of overflow in big data calculations.

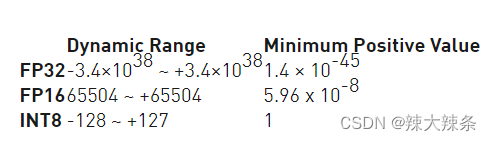
Here is an explanation of why the int8 range is -128 to 127 :
int8 occupies 1 byte, 1 byte (byte) occupies 8 bits (bit), and the highest bit represents the sign bit 1-negative sign; 0-positive sign Then the binary value of the maximum value is: 0 1 1 1 1 1
1
1
Converting to decimal is calculated from low to high
0 1 1 1 1 1 1 1
0*2^7 + 1*2^6 + 1*2^5 + 1*2^4 + 1*2^3 + 1*2^2 + 1*2^1 + 1*2^0
0 + 64 + 32 + 16 + 8 + 4 + 2 + 1
= 127
The binary value of the minimum value should be opposite to that of the maximum value.
Converting 10000000 into decimal is calculated from low to high digits
1 0 0 0 0 0 0 0
1*2^7 + 0*2^6 + 0*2^5 + 0 *2^4 + 0*2^3 + 0*2^2 + 0*2^1 + 0*2^0
128 + 0 + 0 + 0 + 0 + 0 + 0 + 0
= 128
In fact, there is another very Easy to understand explanation
1. int8 occupies 1 byte (byte), that is, 8 binary bits (bit)
2. Each binary bit can store two numbers of 0 and 1, and 8 binary bits have 2^8 = 256 A combination (can store 256 numbers)
3.int8 is signed, so positive and negative numbers will divide 256 numbers equally. 256 / 2 = 128
4. Negative numbers are 128 numbers, the minimum value is -128
5. Positive numbers are 128 numbers, 0 accounts for one number, and the maximum value is +127.
If it is uint8 (8bit unsigned - no negative number) 2^8 = 256
0 occupies a number, so the maximum is 255
2. Compare
Low precision technology (high speed reduced precision). In the training stage, the update of the gradient is often very small, requiring relatively high precision, generally using FP32 or more. In inference, the accuracy requirements are not so high, generally F16 (half-precision) is fine, and even INT8 (8-bit integer) can be used, and the accuracy will not be greatly affected. At the same time, the low-precision model takes up less space, which is conducive to deployment in the embedded model.
Advantages of using fp16 instead of fp32 :
1) TensorRT's FP16 can nearly double the speed compared to FP32, provided that the GPU supports FP16 (such as the latest 2070, 2080, 2080ti, etc.)
2) Reduce video memory.
Disadvantages:
1) It will cause overflow
3. Test
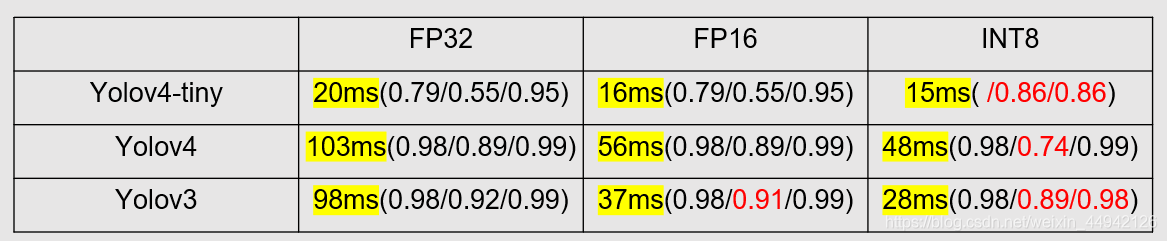
Reference article: TensorRT model conversion and deployment, FP32/FP16/INT8 precision distinction_BourneA's blog-CSDN blog_tensorrt half precision