Detailed Attention Mechanism in Images
-
- I. Introduction
- 2. SENet - Channel Attention Mechanism
- 3. ECANet - channel attention mechanism (one-dimensional convolution replaces MLP in SENet)
- 4. CBAMBlock - mixed use of channel attention mechanism and spatial attention mechanism (SEBlock or ECABlock followed by spatial attention mechanism)
At present, there are two main attention mechanisms: channel attention mechanism and spatial attention mechanism.
I. Introduction
We know that when a picture is input, the neural network will extract image features, and each layer has feature maps of different sizes. As shown in Figure 1, it shows the size change of the feature map when the VGG network extracts image features.
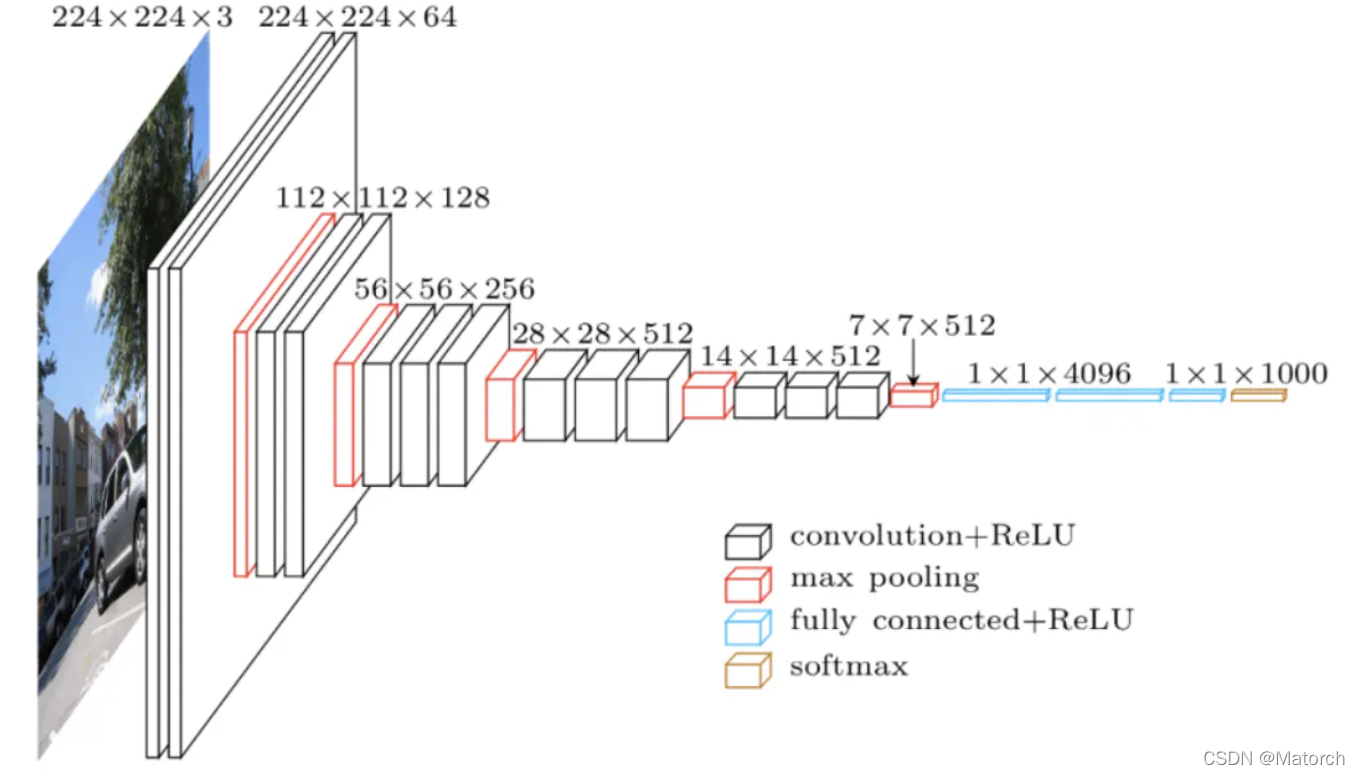
Among them, the common matrix shape of the feature map is [ C , H , W ] {[C,H,W]}[C,H,W ] (numbers in Figure 1 are[ H , W , C ] {[H,W,C]}[H,W,C ] format). Whenthe model is training, the matrix shape of the feature map is[ B , C , H , W ] {[B,C,H,W]}[B,C,H,W ] . Among them, B is expressed as batch size (batch size), C is expressed as channels (number of channels), H is expressed as high (height) of feature map, and W is expressed as weight (width) of feature map
Question: Why is the dimension of the feature map [ B , C , H , W ] {[B,C,H,W]}[B,C,H,W ] instead of some other dimension format?
Answer: When pytorch processes images, the read-in image processing is [ C , H , W ] {[C,H,W]}[C,H,W ] format, if batch size is added during training, then there will be multiple feature maps, and batch size is placed in the first dimension, which is naturally[ B , C , H , W ] {[B,C,H,W] }[B,C,H,W ] . This is how pytorch handles
When the network extracts the image feature layer, the ability of the network to extract images can be enhanced by adding a channel attention mechanism and a spatial attention mechanism between the convolutional layers . When writing code, consider the attention mechanism between feature maps, so the code input is [ B , C , H , W ] {[B,C,H,W]}[B,C,H,W ] feature map, the output is still[ B , C , H , W ] {[B,C,H,W]}[B,C,H,W ] -dimensional feature map. Let's go through three papers to see how these two attention mechanisms work.
2. SENet - Channel Attention Mechanism
1. Introduction to the paper
Paper Title: Squeeze-and-Excitation Networks
Paper link: https://arxiv.org/pdf/1709.01507.pdf
Paper code: https://github.com/hujie-frank/SENet
SEBlock structure diagram:
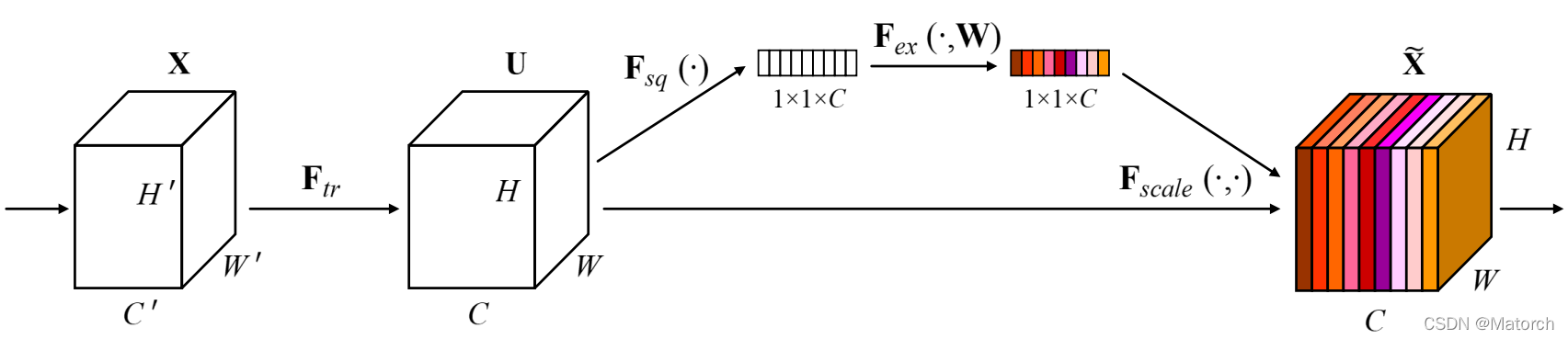
Abstract: The central building block of convolutional neural networks (CNNs) is the convolution operator, which enables networks to construct informative features by fusing both spatial and channel-wise information within local receptive fields at each layer. A broad range of prior research has investigated the spatial component of this relationship, seeking to strengthen the representational power of a CNN by enhancing the quality of spatial encodings throughout its feature hierarchy. In this work, we focus instead on the channel relationship and propose a novel architectural unit, which we term the “Squeeze-and-Excitation” (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels. We show that these blocks can be stacked together to form SENet architectures that generalise extremely effectively across different datasets. We further demonstrate that SE blocks bring significant improvements in performance for existing state-of-the-art CNNs at slight additional computational cost. Squeeze-and-Excitation Networks formed the foundation of our ILSVRC 2017 classification submission which won first place and reduced the top-5 error to 2.251%, surpassing the winning entry of 2016 by a relative improvement of ∼25%. Models and code are available at https://github.com/hujie-frank/SENet.
Summary highlights:
The core component of convolutional neural network (CNN) is the convolution operator, which enables the network to construct informative features by fusing spatial and channel information in the local receptive field of each layer. Numerous previous studies have investigated the spatial component of this relationship and attempted to enhance CNNs by improving the quality of spatial encoding in their feature hierarchy. In this work, we focus on channel-wise relationships and propose a new architectural unit named SE module, which automatically Adaptively recalibrates the channel characteristic response. These modules can be stacked together to form a SENet network structure and generalize very effectively on multiple datasets.
SEBlock innovation points:
- SEBlock will give each channel a weight, so that different channels have different forces on the result.
- This SE module can be easily added to the current mainstream neural network.
2. Algorithm Interpretation
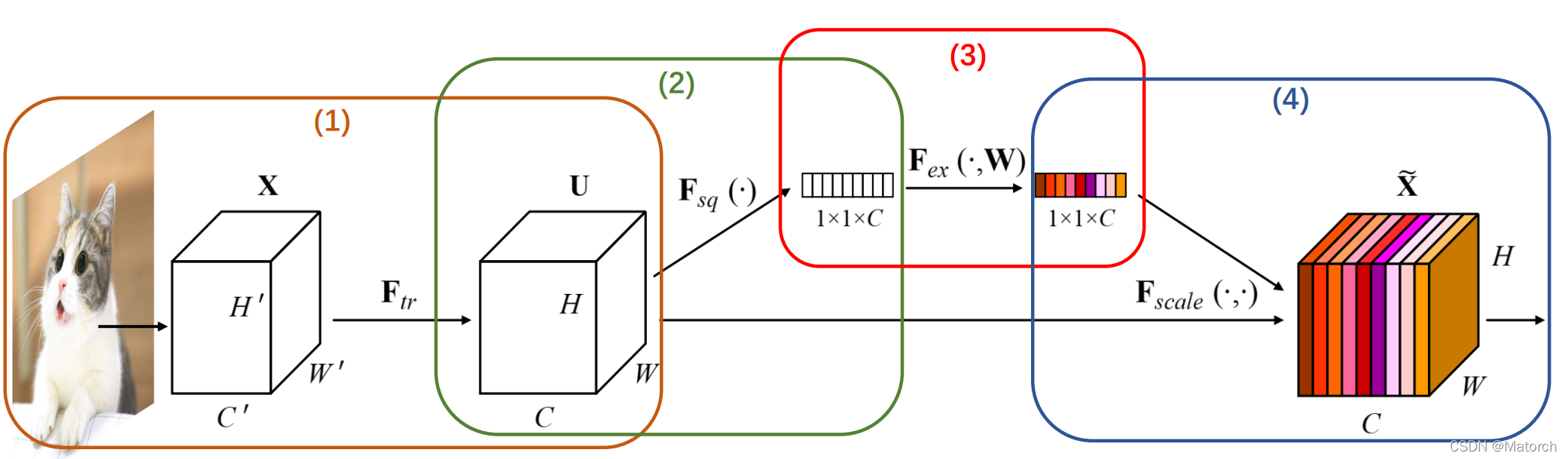
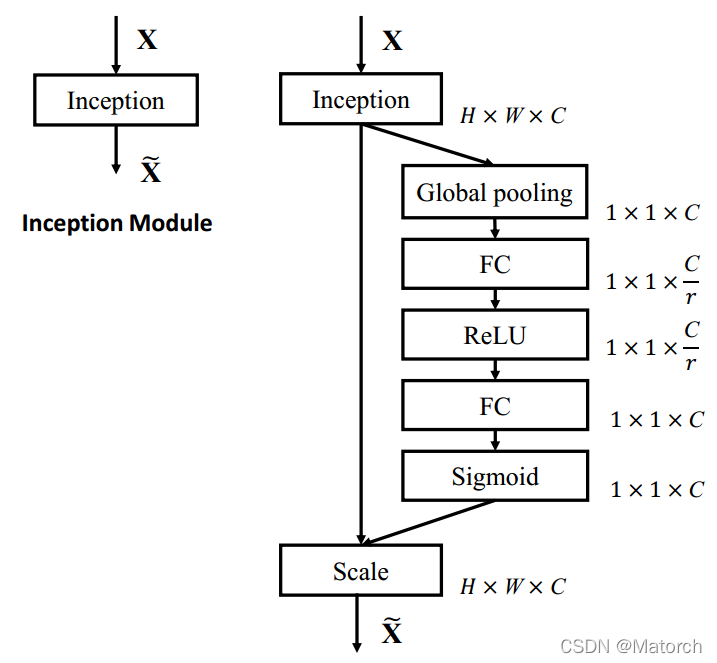
Figure 3 shows the four steps of the channel attention mechanism, as follows:
-
Starting from a single image, image features are extracted. The feature map dimension of the current feature layer U is [ C , H , W ] {[C,H,W]}[C,H,W]。
-
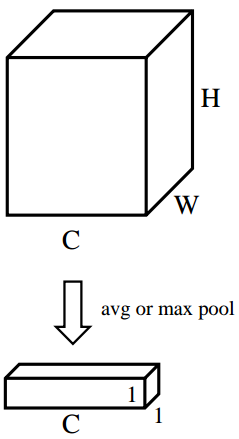
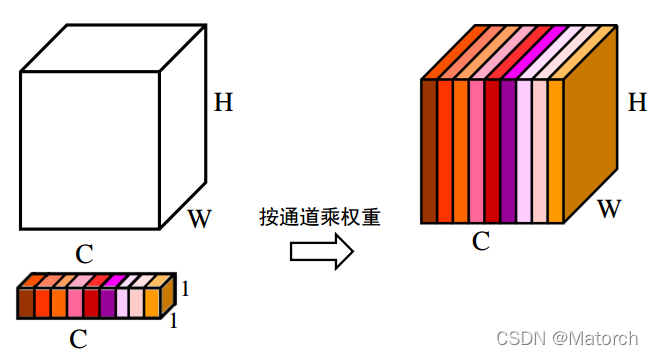
[ H , W ] {[H,W]} of the feature map[H,W ] dimension for average pooling or maximum pooling, the size of the feature map after pooling is from[ C , H , W ] {[C,H,W]}[C,H,W]-> [ C , 1 , 1 ] {[C,1,1]} [C,1,1]。 [ C , 1 , 1 ] {[C,1,1]} [C,1,1 ] It can be understood that for each channel C, there is a number corresponding to it. Fig. 4 corresponds to the specific operation of step (2).
- For [ C , 1 , 1 ] {[C,1,1]}[C,1,1 ] The feature can be understood as the weight extracted from each channel itself. Theweight represents the influence of each channel on feature extraction. After the global pooled vector passes through the MLP network, its meaning is to get each channel. weight. Fig. 5 corresponds to the specific operation of step (3).

- The above steps get the weight of each channel C [ C , 1 , 1 ] {[C,1,1]}[C,1,1 ] , apply the weight to the feature map U[ C , H , W ] {[C,H,W]}[C,H,W ] , that is, each channel is multiplied by its own weight. It can be understood thatwhen the weight is large, the value of the channel feature map will increase accordingly, and the impact on the final output will also increase; when the weight is small, the value of the channel feature map will be smaller, and the impact on the final output will also be greater. will get smaller. Fig. 6 corresponds to the specific operation of step (4).
The details of the channel attention network are given in the original paper, which are shown here, as shown in Figure 7.
Note: Through comparative experiments in this paper, it is found that rrThe effect is best when r is 16, so the general defaultr = 16 r=16r=1 6 , but when the number of channels is small, you need to adjust it yourself
3. Pytorch code implementation
import torch
import torch.nn as nn
class SEBlock(nn.Module):
def __init__(self, mode, channels, ratio):
super(SEBlock, self).__init__()
self.avg_pooling = nn.AdaptiveAvgPool2d(1)
self.max_pooling = nn.AdaptiveMaxPool2d(1)
if mode == "max":
self.global_pooling = self.max_pooling
elif mode == "avg":
self.global_pooling = self.avg_pooling
self.fc_layers = nn.Sequential(
nn.Linear(in_features = channels, out_features = channels // ratio, bias = False),
nn.ReLU(),
nn.Linear(in_features = channels // ratio, out_features = channels, bias = False),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, _, _ = x.shape
v = self.global_pooling(x).view(b, c)
v = self.fc_layers(v).view(b, c, 1, 1)
v = self.sigmoid(v)
return x * v
if __name__ == "__main__":
model = SEBlock("max", 54, 9)
feature_maps = torch.randn((8, 54, 32, 32))
model(feature_maps)
4. Personal understanding
The reason why the channel attention mechanism is effective: In the process of extracting image features from feature maps, it is inevitable that some feature layers will be more effective, while some feature layers will be less effective. Therefore, the weight extracted by the channel itself is applied to the feature map, which ensures that the channel weight is given adaptively on the basis of the features extracted from the feature map, so that the feature map with a greater effect has a greater impact on the result. Therefore, in the final result, it is more effective to extract features than ordinary convolutional layers.
3. ECANet - channel attention mechanism (one-dimensional convolution replaces MLP in SENet)
1. Introduction to the paper
Paper name: ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
Paper link: https://arxiv.org/pdf/1910.03151.pdf
Paper code: https://github.com/BangguWu/ECANet
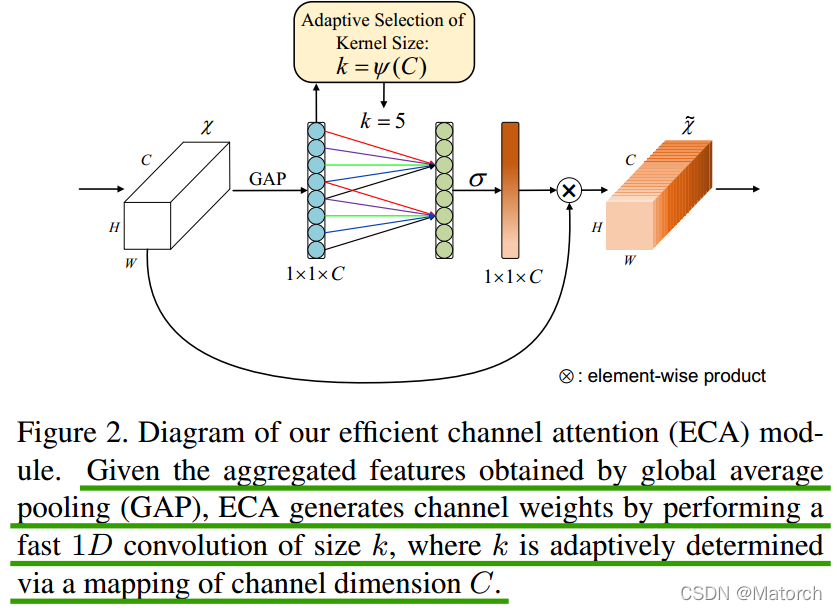
ECABlock main structure diagram
Abstract: Recently, channel attention mechanism has demonstrated to offer great potential in improving the performance of deep convolutional neural networks (CNNs). However, most existing methods dedicate to developing more sophisticated attention modules for achieving better performance, which inevitably increase model complexity. To overcome the paradox of performance and complexity trade-off, this paper proposes an Efficient Channel Attention (ECA) module, which only involves a handful of parameters while bringing clear performance gain. By dissecting the channel attention module in SENet, we empirically show avoiding dimensionality reduction is important for learning channel attention, and appropriate cross-channel interaction can preserve performance while significantly decreasing model complexity. Therefore, we propose a local crosschannel interaction strategy without dimensionality reduction, which can be efficiently implemented via 1D convolution. Furthermore, we develop a method to adaptively select kernel size of 1D convolution, determining coverage of local cross-channel interaction. The proposed ECA module is efficient yet effective, e.g., the parameters and computations of our modules against backbone of ResNet50 are 80 vs. 24.37M and 4.7e-4 GFLOPs vs. 3.86 GFLOPs, respectively, and the performance boost is more than 2% in terms of Top-1 accuracy. We extensively evaluate our ECA module on image classification, object detection and instance segmentation with backbones of ResNets and MobileNetV2. The experimental results show our module is more efficient while performing favorably against its counterparts.
Summary highlights:
In recent years, the channel attention mechanism has shown great potential in improving the performance of deep convolutional neural networks (CNN). However, most existing methods focus on developing more complex attention modules for better performance, which inevitably increases the complexity of the model. To overcome the tradeoff between performance and complexity , this paper proposes an Efficient Channel Attention (ECA) module, which involves only a small number of parameters while bringing significant performance gain. By dissecting the channel attention module in SENet, we empirically show that avoiding dimensionality reduction is important for learning channel attention, and proper cross-channel interaction can significantly reduce model complexity while maintaining performance. Therefore, we propose a local cross-channel interaction strategy without dimensionality reduction, which can be efficiently implemented by 1D convolutions.
Innovations of ECABlock
-
For step (3) of SEBlock, the MLP module (FC->ReLU>FC->Sigmoid) is transformed into a one-dimensional convolution form, which effectively reduces the amount of parameter calculations (we all know that in CNN networks, often connected layers is a huge amount of parameters, so the fully connected layer is changed to a one-dimensional convolution form)
-
The effect of one-dimensional convolution is that it is not fully connected. Each convolution process only works with some channels , that is, it realizes appropriate cross-channel interaction instead of full-channel interaction like a fully connected layer.
2. Interpretation of the paper
Given aggregated features [ C , 1 , 1 ] {[C,1,1]} obtained by average pooling[C,1,1 ] , the ECA module generates channel weights by performing a one-dimensional convolution with a kernel size k, where k is adaptively determined by a mapping of the channel dimension C.
The difference from SEBlock in the figure is only in step (3) of SEBlock, which replaces the fully connected layer with one-dimensional convolution, where the size of the one-dimensional convolution kernel is adaptively determined by the number of channels C.
The formula for adaptively determining the size of the convolution kernel: k = ∣ log 2 C + b γ ∣ odd {k=|\cfrac{log_2{C}+b}{\gamma}|_{odd}}k=∣clog2C+b∣odd
Where k represents the size of the convolution kernel, C represents the number of channels, ∣ ∣ odd {| |_{odd}}∣∣oddIndicates that k can only take odd numbers, γ {\gamma}gamma andb{b}b is set to 2 and 1 in the paper to change the ratio between the number of channels C and the size of the convolution kernel.
(How to understand channel C adaptively determines the size of the convolution kernel: when the number of channels is large, I need the convolution kernel k to be slightly larger; when the number of channels is small, I need the convolution kernel k to be slightly smaller, so that it can fully Fusion interaction between some channels)
3. Pytorch code implementation
import math
import torch
import torch.nn as nn
class ECABlock(nn.Module):
def __init__(self, channels, gamma = 2, b = 1):
super(ECABlock, self).__init__()
kernel_size = int(abs((math.log(channels, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size = kernel_size, padding = (kernel_size - 1) // 2, bias = False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
v = self.avg_pool(x)
v = self.conv(v.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
v = self.sigmoid(v)
return x * v
if __name__ == "__main__":
features_maps = torch.randn((8, 54, 32, 32))
model = ECABlock(54, gamma = 2, b = 1)
model(features_maps)
Here is a comparison of the code implementations of the two papers. It can be seen that the MLP is only replaced by a one-dimensional convolution.
# SEBlock 采用全连接层方式
def forward(self, x):
b, c, _, _ = x.shape
v = self.global_pooling(x).view(b, c)
v = self.fc_layers(v).view(b, c, 1, 1)
v = self.sigmoid(v)
return x * v
# ECABlock 采用一维卷积方式
def forward(self, x):
v = self.avg_pool(x)
v = self.conv(v.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
v = self.sigmoid(v)
return x * v
4. Personal understanding
ECABlock itself has no major content changes, it just replaces the fully connected layer and reduces the amount of data (sometimes subtraction is better than addition)
4. CBAMBlock - mixed use of channel attention mechanism and spatial attention mechanism (SEBlock or ECABlock followed by spatial attention mechanism)
1. Introduction to the paper
Paper name: CBAM: Convolutional Block Attention Module
Paper link: https://arxiv.org/pdf/1807.06521v2.pdf
Paper code: https://github.com/luuuyi/CBAM.PyTorch (reproduced version)
CBAMBlock structure diagram

Abstract: We propose Convolutional Block Attention Module (CBAM), a simple yet effective attention module for feed-forward convolutional neural networks. Given an intermediate feature map, our module sequentially infers attention maps along two separate dimensions, channel and spatial, then the attention maps are multiplied to the input feature map for adaptive feature refinement. Because CBAM is a lightweight and general module, it can be integrated into any CNN architectures seamlessly with negligible overheads and is end-to-end trainable along with base CNNs. We validate our CBAM through extensive experiments on ImageNet-1K, MS COCO detection, and VOC 2007 detection datasets. Our experiments show consistent improvements in classification and detection performances with various models, demonstrating the wide applicability of CBAM. The code and models will be publicly available.
Summary highlights:
We propose Convolutional Block Attention Module (CBAM), a simple yet effective attention module for feedforward convolutional neural networks. Given an intermediate feature map, our module adopts two independent attention mechanisms, channel attention and spatial attention, and then multiplies the weights obtained by the attention mechanism with the input feature map for adaptive feature refinement . Because CBAM is a lightweight general-purpose module, it can be seamlessly integrated into any CNN architecture with negligible overhead and can be trained end-to-end together with the base CNN. We validate our CBAM through extensive experiments on ImageNet-1K, MS COCO detection and VOC 2007 detection datasets. Our experiments show that various models achieve consistent improvements in both classification and detection performance, demonstrating the broad applicability of CBAM. Code and models will be publicly available.
Innovation of CBAM
- On the basis of SENet or ECANet, after the channel attention module, the spatial attention module is connected to realize the dual mechanism of channel attention and spatial attention
- The choice of SENet or ECANet mainly depends on whether the connection of channel attention is MLP or one-dimensional convolution
- The attention module no longer uses a single maximum pooling or average pooling, but uses the addition or stacking of maximum pooling and average pooling . The channel attention module uses addition, and the spatial attention module uses stacking.
2. Interpretation of the paper
In the above two papers, the full connection (SENet) or convolution (ECANet) implementation of the channel attention method has been implemented. The biggest difference between this paper and the above is that the spatial attention mechanism is added.
1) Channel attention mechanism

- The feature maps pass through MaxPool and AvgPool respectively to form two [ C , 1 , 1 ] {[C,1,1]}[C,1,1 ] weight vector
- The two weight vectors pass through the same MLP network (because it is the same network, it can also be regarded as an MLP with network parameter sharing), and are mapped to the weight of each channel
- Add the mapped weights, followed by Sigmoid output
- The resulting channel weights [ C , 1 , 1 ] {[C,1,1]}[C,1,1 ] and the original feature map[ C , H , W ] {[C,H,W]}[C,H,W ] Multiply by channel
On the whole, it is basically the same as SENet, except that the single average pooling is changed to the maximum pooling and average pooling methods at the same time . Afterwards, if the MLP is slightly modified and changed to one-dimensional convolution, it will become a deformed version of ECANet
2) Spatial attention mechanism
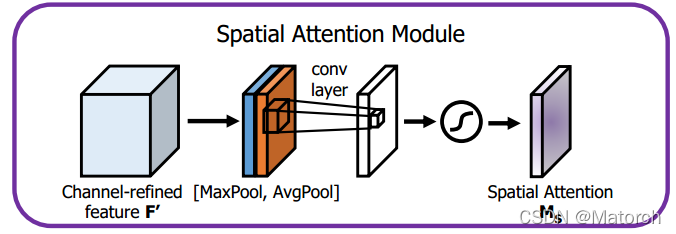
- The feature maps pass through MaxPool and AvgPool respectively to form two [ 1 , H , W ] {[1,H,W]}[1,H,W ] weight vector, i.e. channel-wise max pooling and average pooling. Number of channels from[ C , H , W ] {[C,H,W]}[C,H,W ] becomes[ 1 , H , W ] {[1,H,W]}[1,H,W ] , pooling all channels of the same feature point.
- The obtained two feature maps are stacked to form [ 2 , H , W ] {[2,H,W]}[2,H,W ] feature map spatial weights
- After a convolutional layer, the feature map dimension is from [ 2 , H , W ] {[2,H,W]}[2,H,W ] becomes[ 1 , H , W ] {[1,H,W]}[1,H,W ],This[ 1 , H , W ] {[1,H,W]}[1,H,The feature map of W ] represents the importance of each point on the feature map, and the larger the value is, the more important it is
- The resulting spatial weights [ 1 , H , W ] {[1,H,W]}[1,H,W ] and the original feature map[ C , H , W ] {[C,H,W]}[C,H,W ] multiplied, that is, [ H , W ] {[H,W]}on the feature map[H,W ] each point is assigned a weight
We can see the size as [ H , W ] {[H,W]}[H,W ] feature map, at each point( x , y ) , x ∈ ( 0 , H ) , y ∈ ( 0 , W ) {(x,y),x\in(0,H),y\in (0,W)}(x,y),x∈(0,H),y∈(0,On W ) , there are C values, which represent the importance of the point in the feature map, and the original image is deduced through the receptive field, which indicates the importance of the area. We need to let the network adaptively focus on the places that need to be paid attention to (places with large values are more likely to be paid attention to), and the spatial attention mechanism came into being.
3. Pytorch code implementation
Channel Attention Mechanism - Fully Connected Layer Version
import math
import torch
import torch.nn as nn
class Channel_Attention_Module_FC(nn.Module):
def __init__(self, channels, ratio):
super(Channel_Attention_Module_FC, self).__init__()
self.avg_pooling = nn.AdaptiveAvgPool2d(1)
self.max_pooling = nn.AdaptiveMaxPool2d(1)
self.fc_layers = nn.Sequential(
nn.Linear(in_features = channels, out_features = channels // ratio, bias = False),
nn.ReLU(),
nn.Linear(in_features = channels // ratio, out_features = channels, bias = False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
b, c, h, w = x.shape
avg_x = self.avg_pooling(x).view(b, c)
max_x = self.max_pooling(x).view(b, c)
v = self.fc_layers(avg_x) + self.fc_layers(max_x)
v = self.sigmoid(v).view(b, c, 1, 1)
return x * v
Channel Attention Mechanism - 1D Convolutional Version
class Channel_Attention_Module_Conv(nn.Module):
def __init__(self, channels, gamma = 2, b = 1):
super(Channel_Attention_Module_Conv, self).__init__()
kernel_size = int(abs((math.log(channels, 2) + b) / gamma))
kernel_size = kernel_size if kernel_size % 2 else kernel_size + 1
self.avg_pooling = nn.AdaptiveAvgPool2d(1)
self.max_pooling = nn.AdaptiveMaxPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size = kernel_size, padding = (kernel_size - 1) // 2, bias = False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_x = self.avg_pooling(x)
max_x = self.max_pooling(x)
avg_out = self.conv(avg_x.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
max_out = self.conv(max_x.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
v = self.sigmoid(avg_out + max_out)
return x * v
spatial attention mechanism
class Spatial_Attention_Module(nn.Module):
def __init__(self, k: int):
super(Spatial_Attention_Module, self).__init__()
self.avg_pooling = torch.mean
self.max_pooling = torch.max
# In order to keep the size of the front and rear images consistent
# with calculate, k = 1 + 2p, k denote kernel_size, and p denote padding number
# so, when p = 1 -> k = 3; p = 2 -> k = 5; p = 3 -> k = 7, it works. when p = 4 -> k = 9, it is too big to use in network
assert k in [3, 5, 7], "kernel size = 1 + 2 * padding, so kernel size must be 3, 5, 7"
self.conv = nn.Conv2d(2, 1, kernel_size = (k, k), stride = (1, 1), padding = ((k - 1) // 2, (k - 1) // 2),
bias = False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# compress the C channel to 1 and keep the dimensions
avg_x = self.avg_pooling(x, dim = 1, keepdim = True)
max_x, _ = self.max_pooling(x, dim = 1, keepdim = True)
v = self.conv(torch.cat((max_x, avg_x), dim = 1))
v = self.sigmoid(v)
return x * v
CBAM module (combination of spatial attention and channel attention)
class CBAMBlock(nn.Module):
def __init__(self, channel_attention_mode: str, spatial_attention_kernel_size: int, channels: int = None,
ratio: int = None, gamma: int = None, b: int = None):
super(CBAMBlock, self).__init__()
if channel_attention_mode == "FC":
assert channels != None and ratio != None and channel_attention_mode == "FC", \
"FC channel attention block need feature maps' channels, ratio"
self.channel_attention_block = Channel_Attention_Module_FC(channels = channels, ratio = ratio)
elif channel_attention_mode == "Conv":
assert channels != None and gamma != None and b != None and channel_attention_mode == "Conv", \
"Conv channel attention block need feature maps' channels, gamma, b"
self.channel_attention_block = Channel_Attention_Module_Conv(channels = channels, gamma = gamma, b = b)
else:
assert channel_attention_mode in ["FC", "Conv"], \
"channel attention block must be 'FC' or 'Conv'"
self.spatial_attention_block = Spatial_Attention_Module(k = spatial_attention_kernel_size)
def forward(self, x):
x = self.channel_attention_block(x)
x = self.spatial_attention_block(x)
return x
if __name__ == "__main__":
feature_maps = torch.randn((8, 54, 32, 32))
model = CBAMBlock("FC", 5, channels = 54, ratio = 9)
model(feature_maps)
model = CBAMBlock("Conv", 5, channels = 54, gamma = 2, b = 1)
model(feature_maps)
4. Personal understanding
The spatial attention mechanism and the channel attention mechanism have the same effect. They both extract weights and act on the original feature map, except that one is in [ H , W ] {[H,W]}[H,W ] dimension, one is in[C] {[C]}In the [ C ] dimension, such a method can raise some points without increasing the amount of calculation too much, which is a good trick.
Attention is all you need!