
Job scheduling problems are common linear programming (integer programming) problems in which multiple jobs are processed on multiple machines. Each job consists of a sequence of tasks that must be executed in a given order, and each task must be processed on a specific machine. How to effectively use all the machines to complete all the tasks in the shortest time is a big problem before us.
Before we analyzed the job shop scheduling algorithm officially provided by or-tools , friends who are not very familiar with the job shop scheduling problem, please check my previous blog:
or-tools Integer Programming Case Study: Job Shop Scheduling Problem
define requirements
Today, we still add some difficulty to the problem on this basis. Our business requirements are roughly as follows:
- There are multiple 【Work Orders】
- Each [work order] contains multiple [processes]
- Each [process] contains multiple [equipment] that is allowed to process (that is to say, [this process] only allows one of these equipment to process)
- Each [process] has a processing duration such as 2H
- Each [equipment] includes multiple periods of maintenance time, within the [maintenance time] [equipment] is not allowed to process
- The final [goal] is to minimize the total time to complete these [processes under the work order], and output the total time, the processing [equipment] number of each process, the start and end time of each process.
In order to facilitate modeling, we change Chinese words such as "work order", "process", "equipment" and "objective" in business requirements into English words such as job, task, machine, objective, so that it is easy to understand the following Code logic:
- There are multiple [jobs]
- Each [job] contains multiple [task]
- Each [task] contains multiple [machines] that allow processing (that is to say, this [task] only allows one of these machines to process)
- Each [task] has a processing duration such as 2H
- Each [machine] includes multiple maintenance periods. During the [maintenance period] [machine] is not allowed to process
- The final [object] minimizes the total time to complete these [tasks under the job], and outputs the total time, the processing machineid of each [task], and the start and end time of each [task].
define initialization variables
In view of the above business requirements, we need to create two initial variables Jobs and machine_maintenance_time, where the jobs variable contains 3 jobs, each job contains 3 tasks, and each task contains 3 optional machines and their processing time . The structure of jobs just matches the definition of work order structure in business requirements. The machine_maintenance_time variable is used to store the maintenance time period of each machine, and each machine may have 1 to 2 time periods for maintenance.
import collections
from ortools.sat.python import cp_model
jobs = [ # task = (加工时间, 机器id)
[ # Job 0
[(3, 0), (1, 1), (5, 2)], # task0 有3个可选的加工设备
[(2, 0), (4, 1), (6, 2)], # task1 有3个可选的加工设备
[(2, 0), (3, 1), (1, 2)], # task2 有3个可选的加工设备
],
[ # Job 1
[(2, 0), (3, 1), (4, 2)],
[(1, 0), (5, 1), (4, 2)],
[(2, 0), (1, 1), (4, 2)],
],
[ # Job 2
[(2, 0), (1, 1), (4, 2)],
[(2, 0), (3, 1), (4, 2)],
[(3, 0), (1, 1), (5, 2)],
],
]
#机器维护时间
machine_maintenance_time=[
[(1,3),(6,8)],
[(0,2)],
[(1,3),(7,9)]
]It should be noted that the subscripts of the initial data variable List or array here all start from 0, and the 0th we will talk about later means the actual first.
The jobs here is a List containing multiple jobs, each job consists of 3 tasks, and each task has 3 optional processing equipment, such as: jobs[0][0][0] is equal to ( 3,0) means to process 3 time units on the 0th machine. The format of task is: task = (processing time, machine id). What we need to figure out here is that each task has 3 optional machines, and one of the machines must be selected for processing.
machine_maintenance_time is the initial data of machine maintenance time, machine_maintenance_time is a List containing 3 elements, each element represents a machine and its maintenance time period, such as machine_maintenance_time[0]=[(1,3),(6, 8)] means that the 0th machine needs to be maintained during the two time periods of time 1 to 3 and time 6 to 8, so processing is not allowed during these two time periods. By analogy, here we record the time period for each device to be maintained, among which the 0th and 2nd devices each have 2 time periods to be maintained, and the 1st device only needs to be maintained for one time period.
Next we create the cpmode model and then define a set of working variables:
- num_machines : number of machines.
- num_jobs: the number of jobs.
- horizon: The theoretical maximum time to complete all jobs.
- intervals_per_resources: This variable stores all interval variables on each machine.
- starts: This variable stores the start time of all (job_id, task_id).
- presences: This variable stores all (job_id, task_id, alt_id) corresponding interval variables are valid flags.
model = cp_model.CpModel()
#定义机器数量变量
num_machines = len(machine_maintenance_time)
#定义job数量变量
num_jobs = len(jobs)
#定义完成所有job的理论最大时间
horizon = 0
for job in jobs:
for task in job:
max_task_duration = 0
for alternative in task:
max_task_duration = max(max_task_duration, alternative[0])
horizon += max_task_duration
machine_rest_time=0
for m in machine_maintenance_time:
for t in m:
horizon+=t[1]-t[0]
# 定义一组全局变量
intervals_per_resources = collections.defaultdict(list)
starts = {} # indexed by (job_id, task_id).
presences = {} # indexed by (job_id, task_id, alt_id).
job_ends = []What needs to be explained here is that the value of the horizon variable is the sum of the maximum completion time of each task in each job plus the sum of the maintenance time of all machines.
Add constraints
Next, we need to add constraints to the model. Since our jobs are a triple structure, job->task->alternatives, we need to add major constraints while traversing the triple structure.
# 遍历jobs,创建相关遍历,添加约束条件
for job_id in range(num_jobs):
job = jobs[job_id]
num_tasks = len(job)
previous_end = None
for task_id in range(num_tasks):
task = job[task_id]
min_duration = task[0][0]
max_duration = task[0][0]
num_alternatives = len(task)
all_alternatives = range(num_alternatives)
for alt_id in range(1, num_alternatives):
alt_duration = task[alt_id][0]
min_duration = min(min_duration, alt_duration)
max_duration = max(max_duration, alt_duration)
# 为每个task创建间隔变量
suffix_name = '_j%i_t%i' % (job_id, task_id)
start = model.NewIntVar(0, horizon, 'start' + suffix_name)
duration = model.NewIntVar(min_duration, max_duration,
'duration' + suffix_name)
end = model.NewIntVar(0, horizon, 'end' + suffix_name)
interval = model.NewIntervalVar(start, duration, end,
'interval' + suffix_name)
# 存储每个(job_id, task_id)的开始时间
starts[(job_id, task_id)] = start
# 添加任务的先后顺序约束
if previous_end is not None:
model.Add(start >= previous_end)
previous_end = end
# 为每个task的可选择的机器创建间隔变量
if num_alternatives > 1:
l_presences = []
for alt_id in all_alternatives:
alt_suffix = '_j%i_t%i_a%i' % (job_id, task_id, alt_id)
l_presence = model.NewBoolVar('presence' + alt_suffix)
l_start = model.NewIntVar(0, horizon, 'start' + alt_suffix)
l_duration = task[alt_id][0]
l_end = model.NewIntVar(0, horizon, 'end' + alt_suffix)
l_interval = model.NewOptionalIntervalVar(
l_start, l_duration, l_end, l_presence,
'interval' + alt_suffix)
l_presences.append(l_presence)
#强且仅当间隔变量的标志位为True时对start,duration,end进行赋值
model.Add(start == l_start).OnlyEnforceIf(l_presence)
model.Add(duration == l_duration).OnlyEnforceIf(l_presence)
model.Add(end == l_end).OnlyEnforceIf(l_presence)
# 添加每台机器上的所有间隔变量
intervals_per_resources[task[alt_id][1]].append(l_interval)
# 存放每个间隔变量是否有效的标志位
presences[(job_id, task_id, alt_id)] = l_presence
# 每个task任选一台机器的约束
model.AddExactlyOne(l_presences)
else:
intervals_per_resources[task[0][1]].append(interval)
presences[(job_id, task_id, 0)] = model.NewConstant(1)
job_ends.append(previous_end)
# 添加机器的约束.
for machine_id in range(num_machines):
#添加机器维护时间的约束
for t in machine_maintenance_time[machine_id]:
maintenance_interval=model.NewIntervalVar(t[0],t[1]-t[0],t[1], 'maintenance_time')
intervals_per_resources[machine_id].append(maintenance_interval)
#添加每台机器上的间隔变量不重叠的约束
intervals = intervals_per_resources[machine_id]
if len(intervals) > 1:
model.AddNoOverlap(intervals)What we need to explain here is that when realizing the constraint condition that "each task can be processed on one of the three machines", what we create is the NewOptionalIntervalVar interval variable. The difference between this variable and the NewIntervalVar variable is one more Whether the valid flag is_present, according to the official documentation, the interval variable is valid only when is_present is True, otherwise it is invalid:
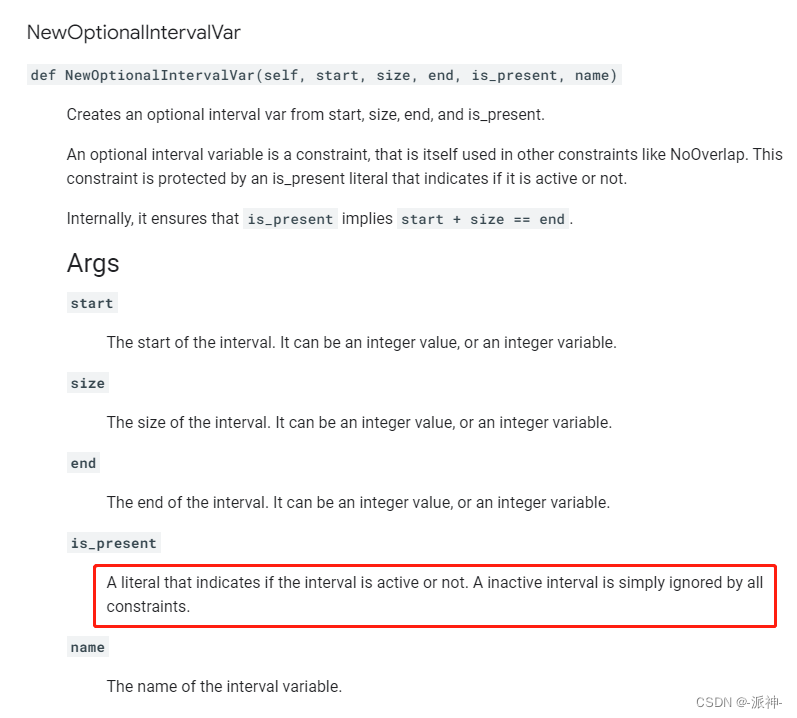
Here we also use the OnlyEnforceIf method, which means "if and only if", because we want to record the start, duration, and end of the machine selected by each task, so in the 3 optional 3 machines In the interval variable, only the is_present flag of the interval variable of one machine is allowed to be True, so OnlyEnforceIf can force the start, duration, and end values of the machine whose is_present is True to be recorded.
We used the AddExactlyOne method when implementing the constraint of choosing one of the three units, which is equivalent to the previous model.Add(sum([x,x,x,x])==1), that is, only one array variable is allowed There can only be one 1 in , and all other elements must be 0. In this way, the effect of choosing one of the three can be guaranteed.
When adding the constraint of machine maintenance time, we added the interval variable of each machine maintenance time to the intervals_per_resources variable. The intervals_per_resources variable originally stored the interval variables of all tasks on each machine. On this basis, we added The machine adds the interval variable of the maintenance time, and then uses the AddNoOverlap method to ensure that the interval variable on each machine does not overlap, thus ensuring that each machine will not be occupied by any task during the maintenance time .
Set optimization goals
Our optimization goal is to minimize the time to complete all jobs, but we first need to find the maximum end time of all jobs (realized by AddMaxEquality), and then minimize this maximum time to achieve our optimization goal.
# 设定优化目标为:完成所有job的时间最短
makespan = model.NewIntVar(0, horizon, 'makespan')
model.AddMaxEquality(makespan, job_ends)
model.Minimize(makespan)model solving
We print out the start time and duration of all job tasks on each machine, and which of the 3 machines is selected for each task.
# Solve model.
solver = cp_model.CpSolver()
solution_printer = SolutionPrinter()
status = solver.Solve(model, solution_printer)
# Print final solution.
for job_id in range(num_jobs):
print('Job %i:' % job_id)
for task_id in range(len(jobs[job_id])):
start_value = solver.Value(starts[(job_id, task_id)])
machine = -1
duration = -1
selected = -1
for alt_id in range(len(jobs[job_id][task_id])):
if solver.Value(presences[(job_id, task_id, alt_id)]):
duration = jobs[job_id][task_id][alt_id][0]
machine = jobs[job_id][task_id][alt_id][1]
selected = alt_id
print(
' task_%i_%i starts at %i (alt %i, machine %i, duration %i)' %
(job_id, task_id, start_value, selected, machine, duration))
print('Solve status: %s' % solver.StatusName(status))
print('Optimal objective value: %i' % solver.ObjectiveValue())
print('Statistics')
print(' - conflicts : %i' % solver.NumConflicts())
print(' - branches : %i' % solver.NumBranches())
print(' - wall time : %f s' % solver.WallTime())
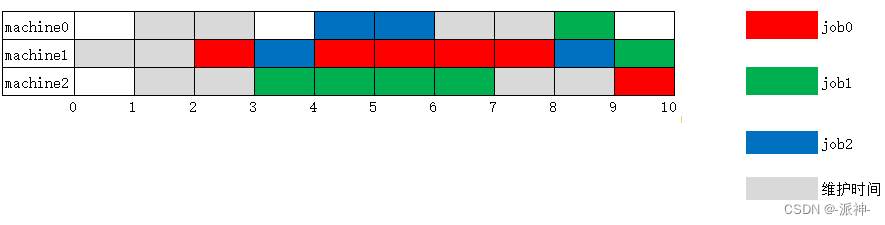
Here we can clearly see that the maintenance time of each machine is not occupied by tasks, and we also get that the shortest time to complete all jobs is 10, and the solution of the model is the optimal solution: OPTIMAL, but this is just a simple example, because we use the simplest initialization data, but in formal commercial projects, it is often difficult for us to obtain the optimal solution, and generally we can only obtain a feasible solution. Whether an optimal solution can be obtained depends on the complexity of the business and the hardware resources of the machine, especially the number of CPU cores and their frequency.