Article directory
1. How time is measured
time.time()
time.perf_counter()
time.process_time()
time.time() and time.perf_counter() include sleep() time can be used as a general time measurement, time.perf_counter() is more accurate and
time.process_time() is the sum of the system and user CPU time of the current process
Test code:
def show_time():
print('我是time()方法:{}'.format(time.time()))
print('我是perf_counter()方法:{}'.format(time.perf_counter()))
print('我是process_time()方法:{}'.format(time.process_time()))
t0 = time.time()
c0 = time.perf_counter()
p0 = time.process_time()
r = 0
for i in range(10000000):
r += i
time.sleep(2)
print(r)
t1 = time.time()
c1 = time.perf_counter()
p1 = time.process_time()
spend1 = t1 - t0
spend2 = c1 - c0
spend3 = p1 - p0
print("time()方法用时:{}s".format(spend1))
print("perf_counter()用时:{}s".format(spend2))
print("process_time()用时:{}s".format(spend3))
print("测试完毕")
Test results:
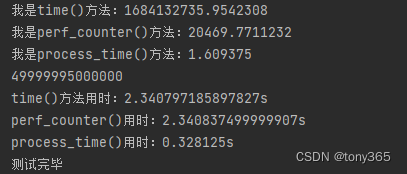
For a more detailed explanation, refer to
the difference between time(), perf_counter() and process_time() of the time module in Python3.7
2. Model.eval(), model.train(), torch.no_grad() method introduction
2.1 model.train()和model.eval()
We know that in pytorch, the model has two modes that can be set, one is train mode and the other is eval mode.
The role of model.train() is to enable Batch Normalization and Dropout. In the train mode, the Dropout layer will set the probability of retaining the activation unit according to the set parameter p, such as keep_prob=0.8, and the Batch Normalization layer will continue to calculate the mean and var of the data and update them.
The function of model.eval() is not to enable Batch Normalization and Dropout. In eval mode, the Dropout layer will pass all activation units, while the Batch Normalization layer will stop calculating and updating mean and var, and directly use the mean and var values that have been learned during the training phase.
When using model.eval(), it is to switch the model to the test mode. Here, the model will not update the weights like in the training mode. However, it should be noted that model.eval() will not affect the gradient calculation behavior of each layer, that is, it will perform gradient calculation and storage in the same way as the training mode, but it will not perform backpropagation.
2.2 model.eval()和torch.no_grad()
When talking about model.eval(), torch.no_grad() is actually mentioned.
torch.no_grad() is used to stop the calculation of autograd, which can speed up and save video memory, but it will not affect the behavior of the Dropout layer and the Batch Normalization layer.
If you don't care about the memory size and calculation time, just using model.eval() is enough to get the correct validation result; and with torch.zero_grad() is to further accelerate and save gpu space. Because there is no need to calculate and store gradients, it can be calculated faster and use larger batches to run the model.
3. Model inference time mode
When measuring time, it is different from general tests, such as the following code is incorrect:
start = time.time()
result = model(input)
end = time.time()
Instead, use:
torch.cuda.synchronize()
start = time.time()
result = model(input)
torch.cuda.synchronize()
end = time.time()
Because in pytorch, the execution of the program is asynchronous.
If code 1 is used, the test time will be very short, because the program exits after executing end=time.time(), and the cu in the background also exits because of the exit of python.
If code 2 is used, the code will synchronize the operation of cu, and wait for the operations on the gpu to complete before continuing to shape end = time.time()
4. A complete code for testing model inference time
Generally, first model.eval() does not enable Batch Normalization and Dropout, does not enable gradient update,
then uses mode to create a model, and initializes the input data (single image)
def measure_inference_speed(model, data, max_iter=200, log_interval=50):
model.eval()
# the first several iterations may be very slow so skip them
num_warmup = 5
pure_inf_time = 0
fps = 0
# benchmark with 2000 image and take the average
for i in range(max_iter):
torch.cuda.synchronize()
start_time = time.perf_counter()
with torch.no_grad():
model(*data)
torch.cuda.synchronize()
elapsed = time.perf_counter() - start_time
if i >= num_warmup:
pure_inf_time += elapsed
if (i + 1) % log_interval == 0:
fps = (i + 1 - num_warmup) / pure_inf_time
print(
f'Done image [{
i + 1:<3}/ {
max_iter}], '
f'fps: {
fps:.1f} img / s, '
f'times per image: {
1000 / fps:.1f} ms / img',
flush=True)
if (i + 1) == max_iter:
fps = (i + 1 - num_warmup) / pure_inf_time
print(
f'Overall fps: {
fps:.1f} img / s, '
f'times per image: {
1000 / fps:.1f} ms / img',
flush=True)
break
return fps
if __name__ == "__main__":
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# device = 'cpu'
print(device)
img_channel = 3
width = 32
enc_blks = [2, 2, 4, 8]
middle_blk_num = 12
dec_blks = [2, 2, 2, 2]
width = 16
enc_blks = [1, 1, 1]
middle_blk_num = 1
dec_blks = [1, 1, 1]
net = NAFNet(img_channel=img_channel, width=width, middle_blk_num=middle_blk_num,
enc_blk_nums=enc_blks, dec_blk_nums=dec_blks)
net = net.to(device)
data = [torch.rand(1, 3, 256, 256).to(device)]
fps = measure_inference_speed(net, data)
print('fps:', fps)
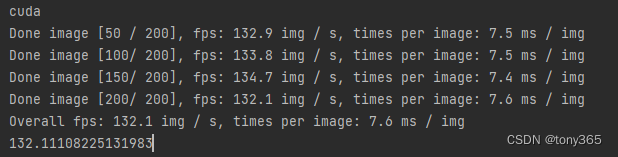
5. Reference:
https://blog.csdn.net/weixin_44317740/article/details/104651434
https://zhuanlan.zhihu.com/p/547033884
https://deci.ai/blog/measure-inference-time-deep-neural-networks/
https://github.com/xinntao/BasicSR