Article directory
Hello everyone, I am Beishan, long time no see, Nice to meet you, this article will record and learn about the Hadoop ecosystem.
Big Data Era
Big data refers to a collection of data that cannot be captured, managed and processed by commonly used software tools within a certain period of time. It is a mass and high growth rate that requires a new processing model to have stronger decision-making power, insight discovery and process optimization capabilities. and diverse information assets

Characteristics of 5V in the era of big data
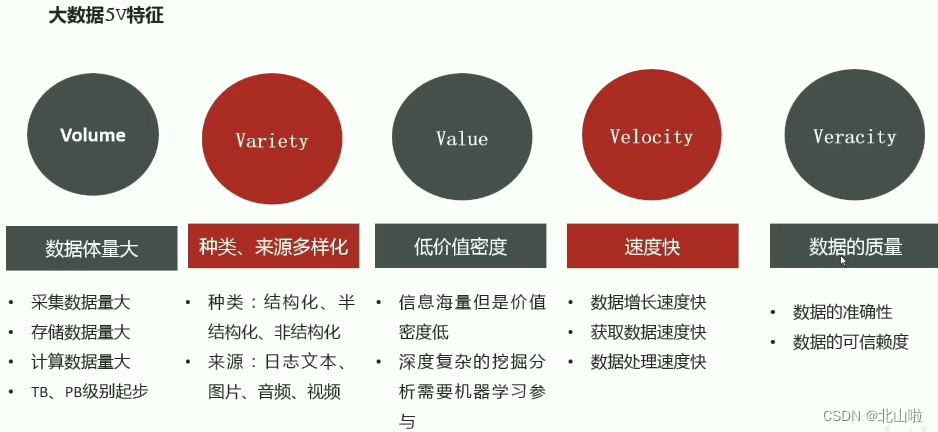
Application scenarios, including recommendations in the e-commerce field, personal credit evaluation in finance, congestion prediction in the traffic field, optimal navigation planning, etc., https://beishan.blog.csdn.net/


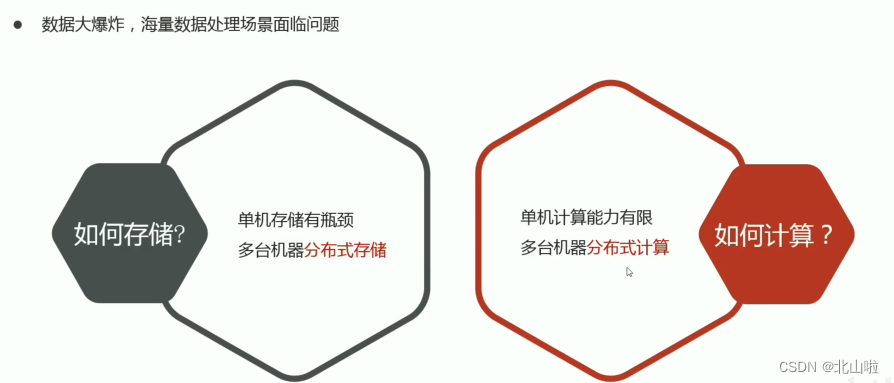
In the big data scenario: how to store massive data and how to calculate massive data?
This involves the concept of distributed and cluster
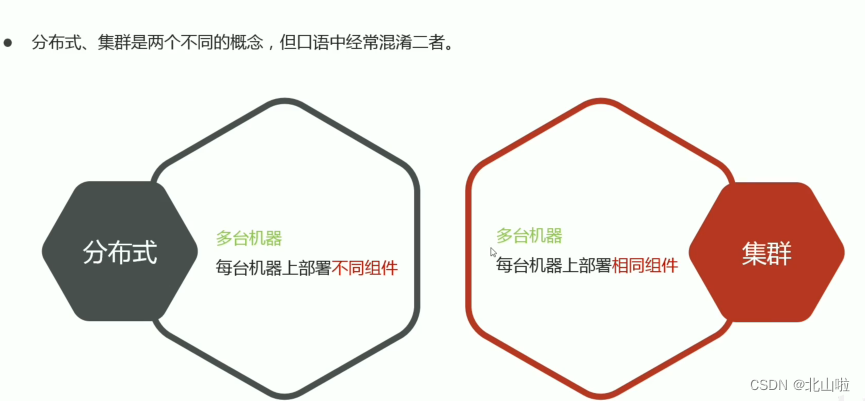
How to store massive data and how to calculate massive data
Hadoop
Hadoop overview

Official website: https://hadoop.apache.org/
In chivalry, Hadoop refers to an open source software of the Apache Software Foundation
Allows users to use a simple programming model to implement distributed computing processing of massive data across machine clusters
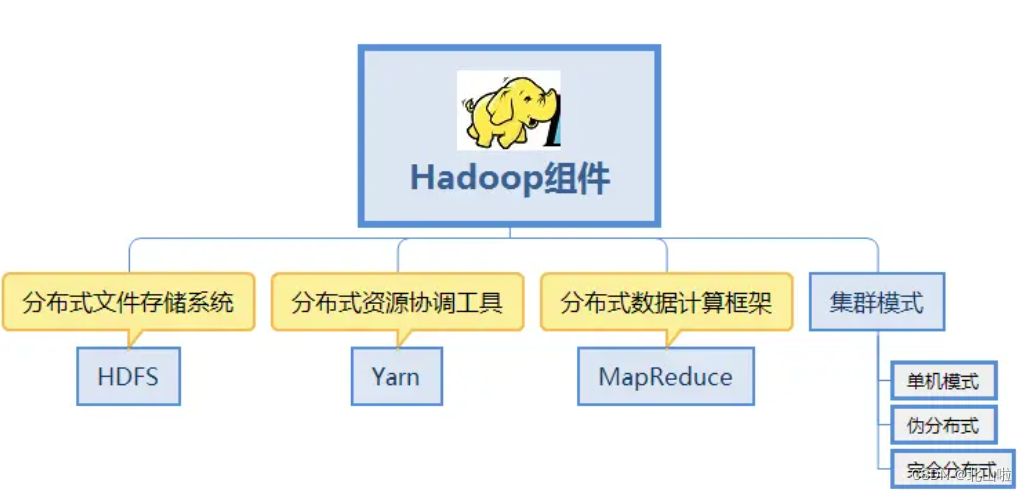
Hadoop core components
HDFS: Distributed file storage system, solving massive data storage
YARN: Cluster resource management and task scheduling framework, solving resource task scheduling
MapReduce: Distributed computing framework, solving massive computing

In a broad sense, Hadoop refers to the big data ecosystem built around Hadoop

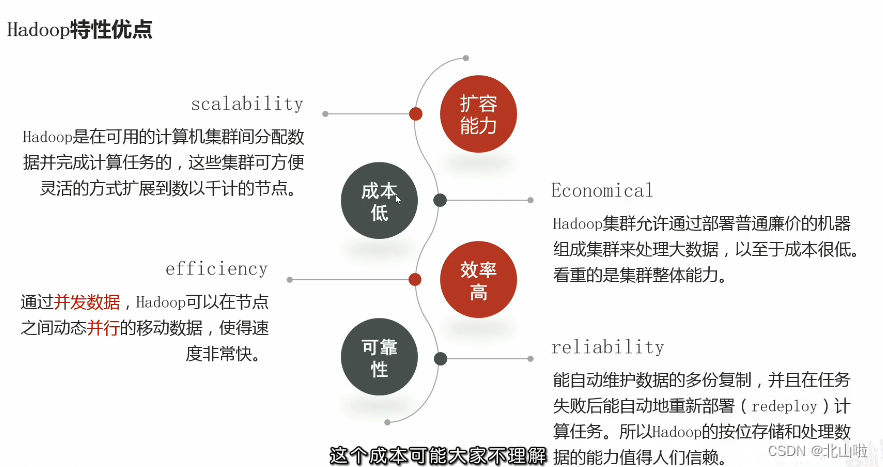
Advantages of Hadoop features
Hadoop application at home and abroad
Hadoop was first applied to Internet companies at home and abroad, such as Yahoo, Facebook, and IBM in foreign countries. Domestic examples: BAT and Huawei


Hadoop's success lies in its versatility and simplicity
Precisely distinguish what to do and how to do it. What to do is a business issue, and how to do it is a technical issue. Users are responsible for business, and Hadoop is responsible for technology.
Hadoop distribution
Divided into open source community version and commercial release

version Open source community version: https://hadoop.apache.org/Commercial
release version: https://www.cloudera.com/products/open-source/apache-hadoop.html
Up to now, Hadoop has developed to version 3.x, Hadoop 1.0 includes HDFS (distributed file storage) and MapReduce (resource management and distributed data processing), and to 2.0, MapReduce (distributed data processing) is disassembled. points, introducing a new component YARN (cluster resource management, task scheduling)
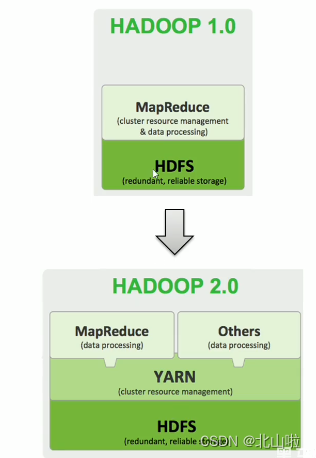
Hadoop3.0 architecture components are similar to Hadoop2.0, and 3.0 focuses on performance optimization

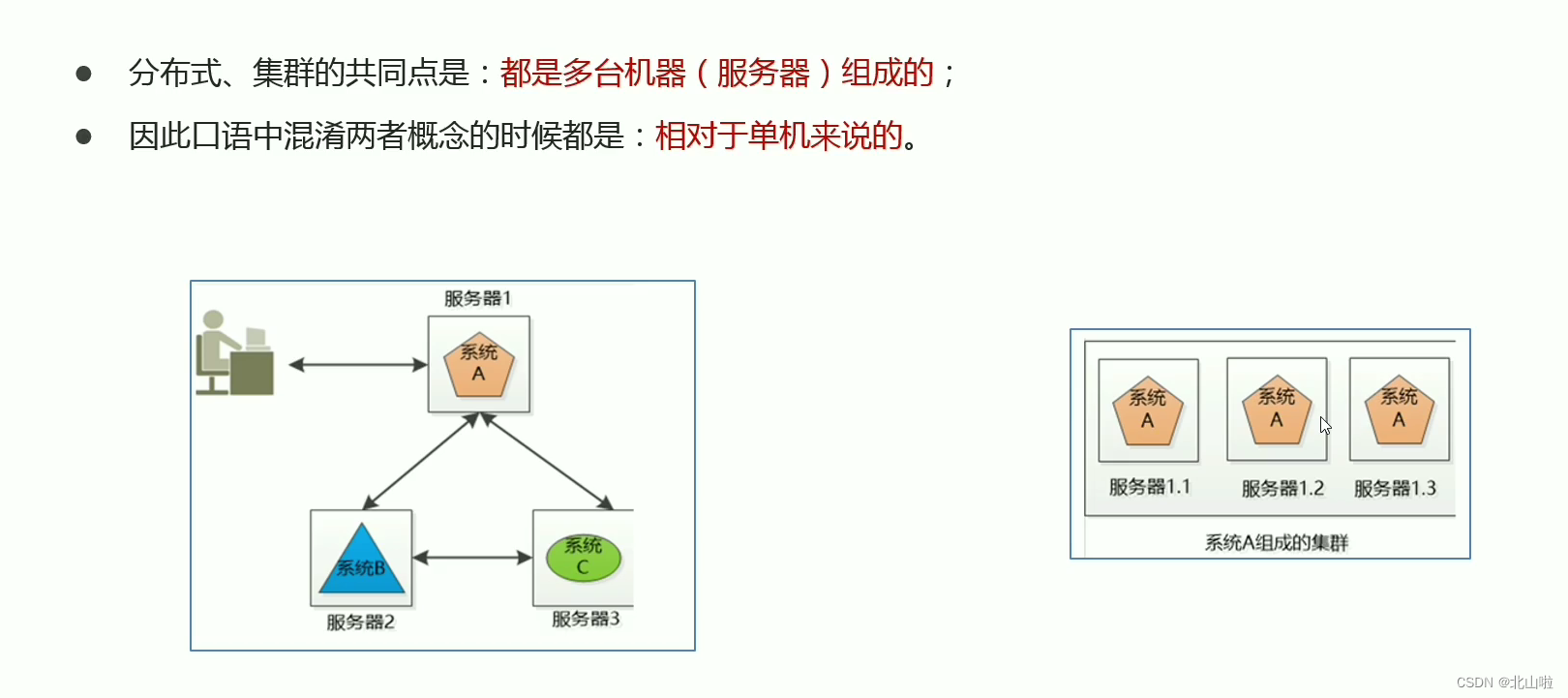
Overall overview of Hadoop cluster
- Hadoop cluster includes two clusters: HDFS cluster and YARN cluster
- Two clusters are logically separated and usually physically together
- Both clusters are standard master-slave architecture clusters
MapReduce是计算框架、代码层面的组件 没有集群之说
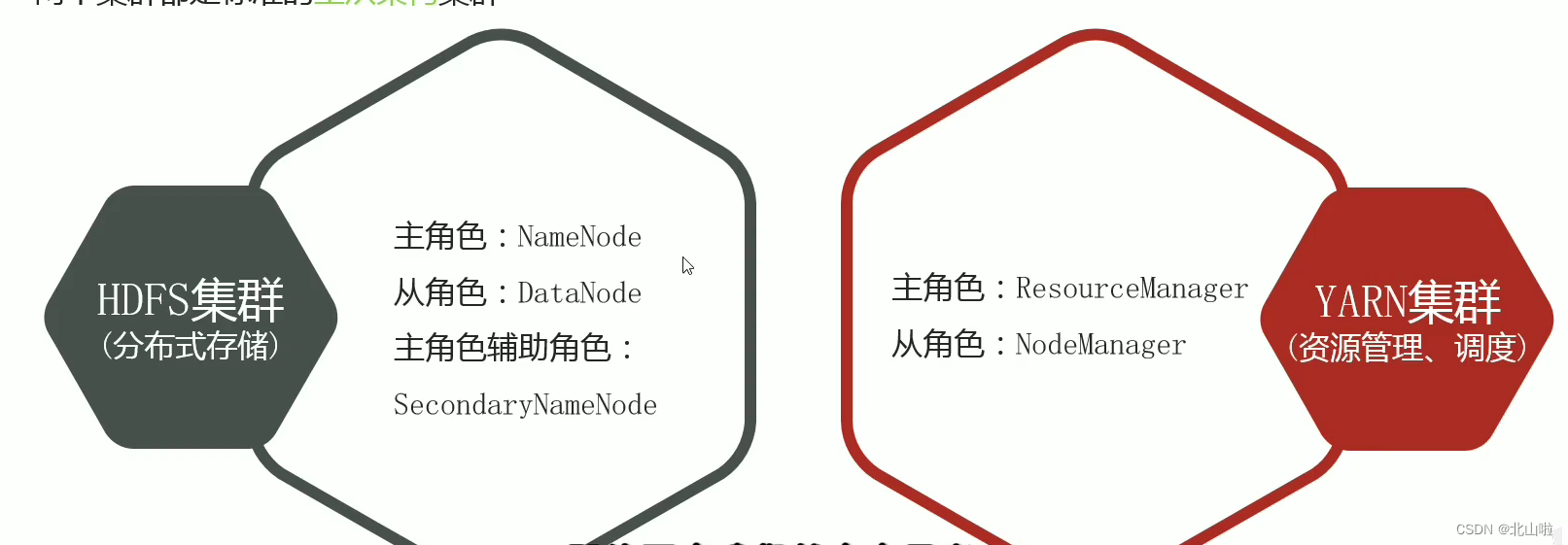
The two clusters are logically separated and usually physically together. It can be understood from the figure below that
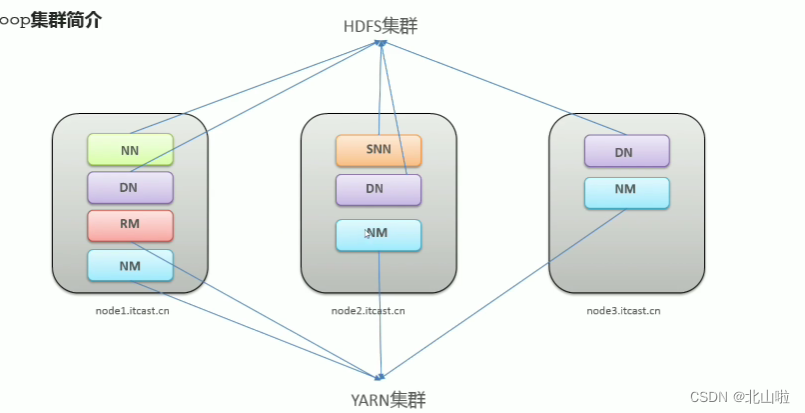
the HDFS cluster consists of a master (NN is NameNode) and three slaves (DN is DataNode) + a secretary (SNN is Secondary NameNode).
The YARN cluster consists of RM (Resource Manager) and NM (Node Manager)
Hadoop集群 = HDFS集群 + YARN集群
- Logically separated, meaning that they are not dependent on each other
- Physically together, means that the process is deployed on the same machine
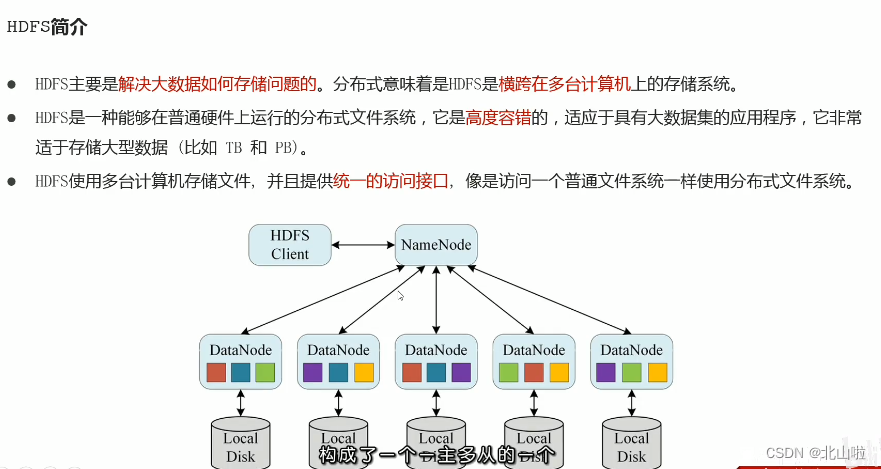
HDFS Distributed File System
The file system is a method of storing and organizing data. It realizes operations such as data storage, hierarchical organization, access, and acquisition, making it easy for users to access and search. The file system uses data blocks instead of physical devices such as hard disks 树形目录. 逻辑抽象The concept, the user does not need to know where the bottom layer of the data exists on the hard disk, just remember the directory and file name to which the file belongs
Traditional common file system

Difficulties encountered in mass data storage:
- The versatility of traditional storage hardware is poor, and the cost of equipment investment plus later maintenance, upgrade and expansion is very high
- The traditional storage method means: store when storing, calculate when calculating, and move the data when it needs to be processed
- Low performance, single-node I/O performance bottleneck cannot be overcome, and it is difficult to support high concurrency and high throughput of massive data
- poor scalability
Data and Metadata

HDFS Core Properties
- distributed storage
- metadata record
- block storage
- copy mechanism
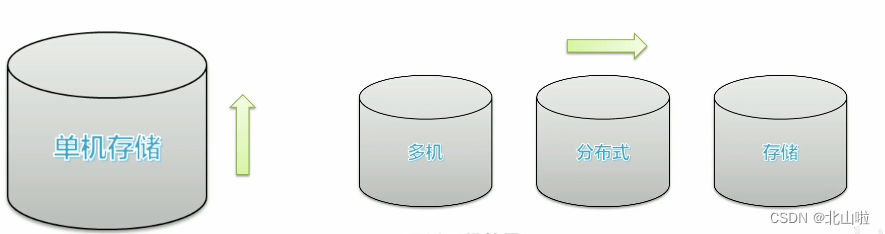
distributed storage
The amount of data is large, and stand-alone storage encounters bottlenecks. Distributed storage solves data storage problems through horizontal expansion
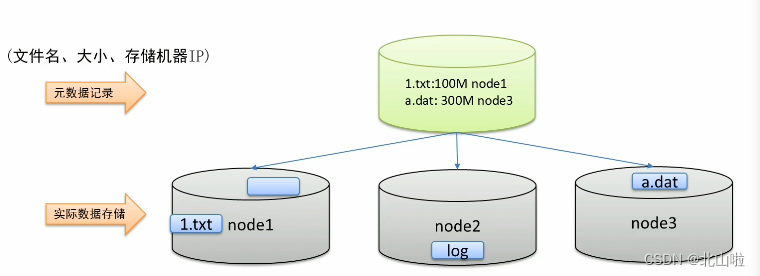
metadata record
In view of the fact that files distributed on different machines are not conducive to searching, the metadata records the storage location information of the file machine to quickly locate the file location
block storage
The file is too large to be stored on a single machine, and the upload and download efficiency is low. Stored in different machines through file blocks, for blocks并行操作提高效率
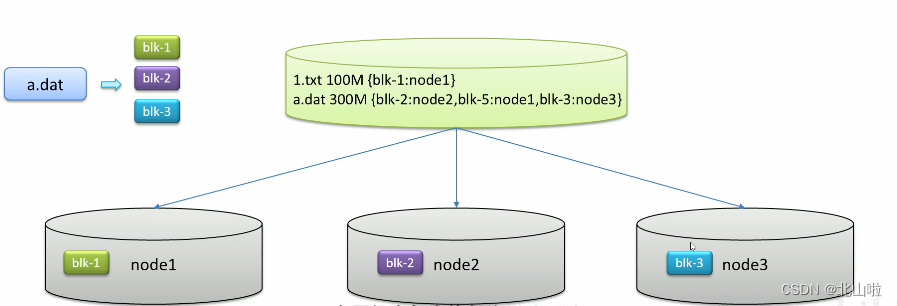
copy mechanism
Backup of different machine settings, redundant storage, and data security
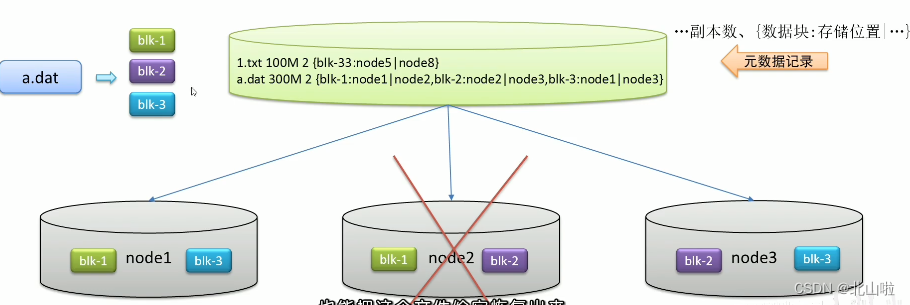
are summarized as follows:

Introduction to HDFS
- HDFS (Hadoop Distributed File System), Hadoop distributed file system, is one of the core components of Apache Hadoop. It exists as the bottom distributed storage service of the big data ecosystem. It can also be said that the primary solution of big data is The storage problem of massive data
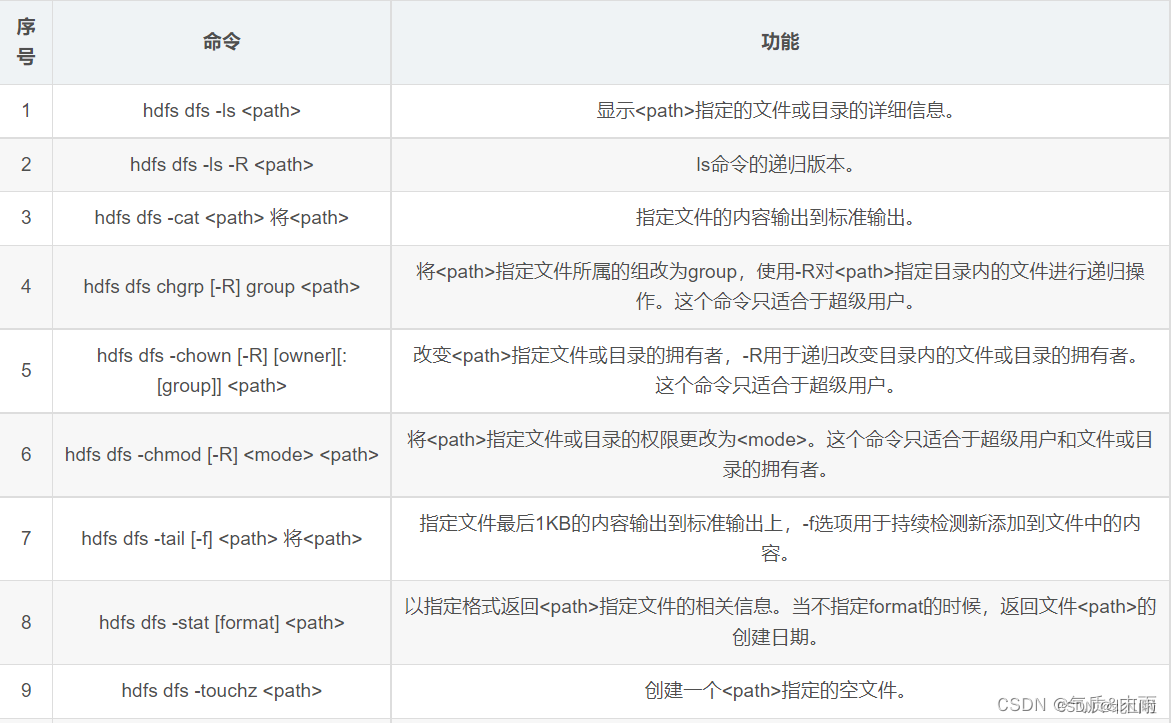
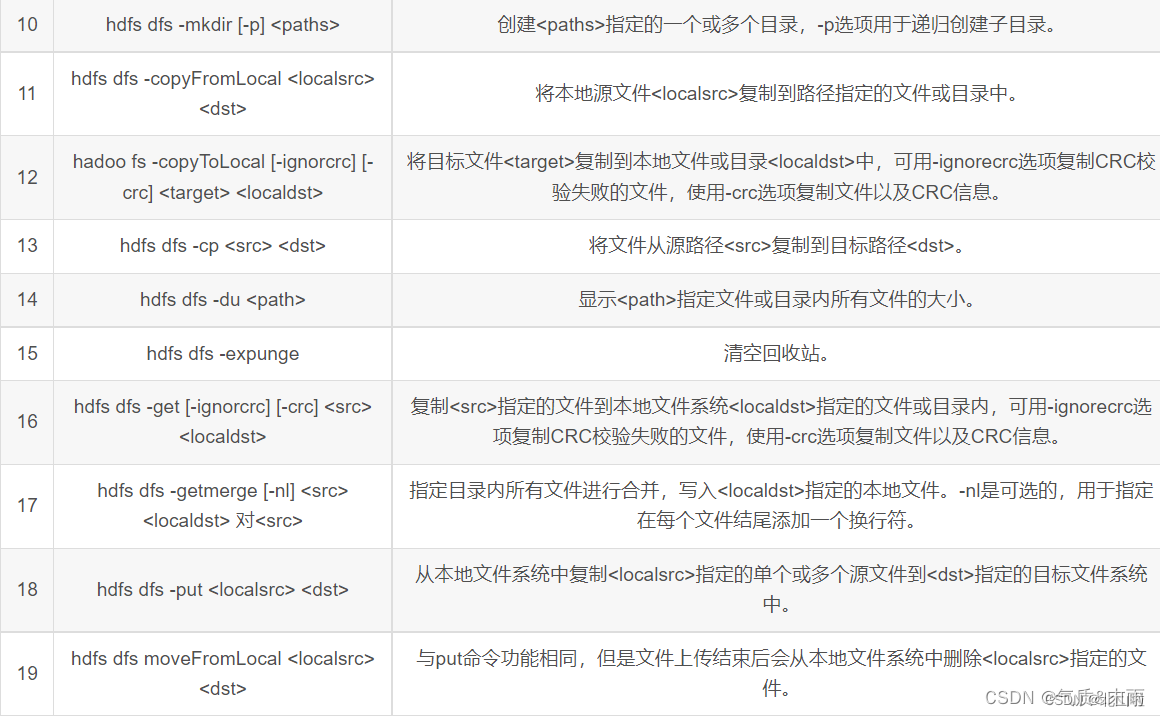
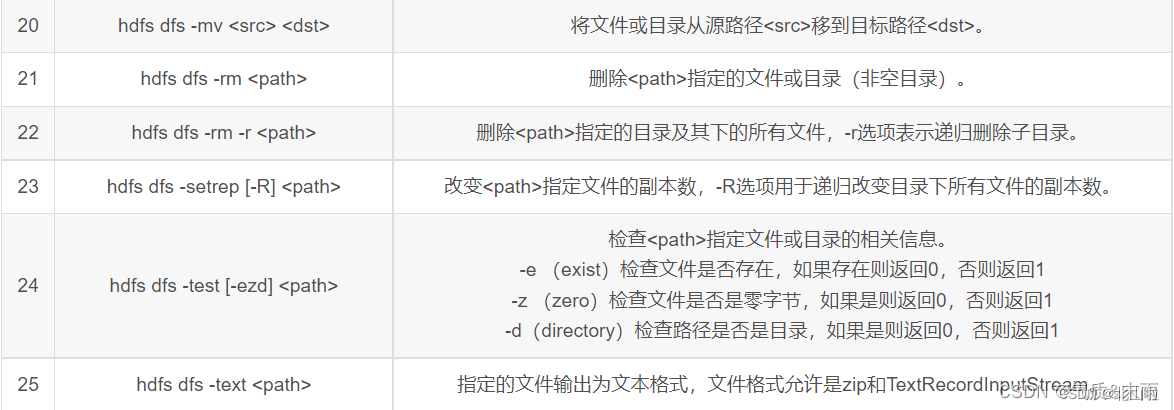
HDFS shell operation
HDFS Shell contains various shell-like commands, which can directly interact with Hadoop distributed file system and other file systems. The commonly used commands are as follows: here is the summary
of CSDN temperament & Mo Yu , thank you
Map Reduce
Hadoop primary key MapReduce
Divide and conquer ideas, design concepts, official examples, execution process
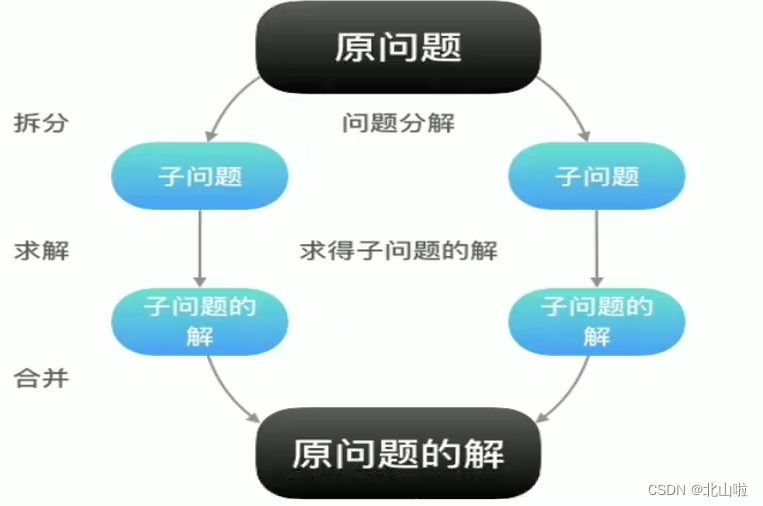
divide and conquer
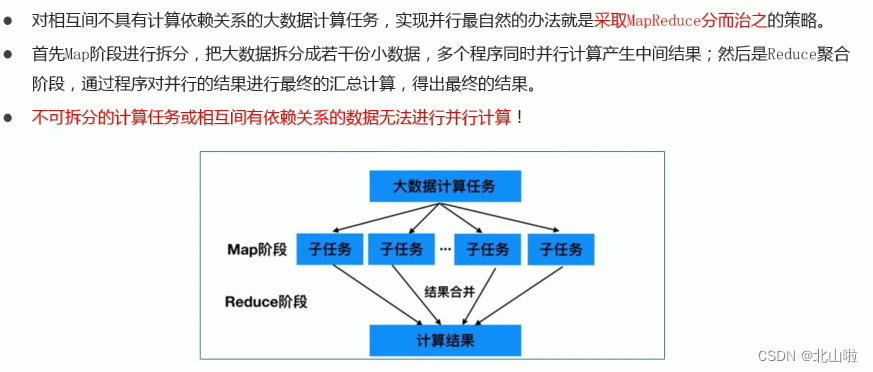
The core idea of MapReduce is: divide and conquer,

split the original problem into several sub-problems, solve the sub-problems, and finally combine them to obtain the solution of the original problem.
After splitting the original problem into several small problems, they can be processed in parallel and calculated at the same time. Of course, if it cannot be split or there is a dependency relationship between small problems after split, then the idea of divide and conquer cannot be used.
- Can it be split
- Is there a dependency
Example: To count the total number of all parked cars in the parking lot
Map: You count one column, I count one column... This is the Map stage, the more people there are, the more people can pass and count the cars at the same time, and the faster the speed will be.
Reudece: After counting, get together and add all the statistics together, this is the reduce merge summary stage

Understand the idea of MapReduce
- The idea of MapReduce is easy to understand, the key lies in how to design a distributed computing program based on this idea
- Follow-up to explain the Hadoop team's design concept for MapReduce
- How to deal with big data scenarios
- Build an abstract programming model
MapReduce draws on 函数式the ideas in the language, and then provides a high-level parallel programming abstraction model Mapwith two functions.Reduce
Map: perform some repetitive processing on a set of data elements
Reduce: Perform some further result sorting on the intermediate results of the Map

MapReduce defines the following two abstract programming interfaces of Map and Reduce, which are implemented by user programming:
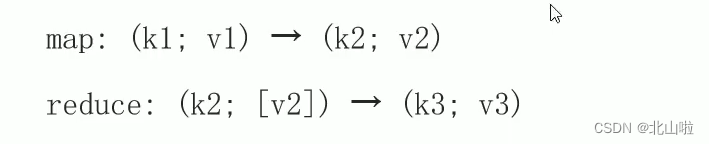
Through the above two programming interfaces, you can see that the data type processed by MapReduce is <key, value> key-value pair
- Unified architecture, hidden underlying details

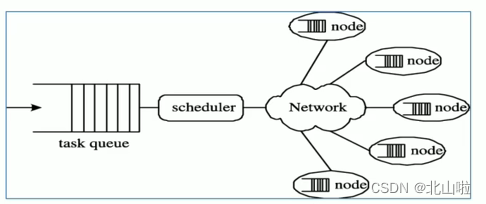
Distributed Computing Concepts
- Distributed computing is a computing method, which is relative to centralized computing
- With the development of computer technology, some applications require huge computing power to complete. If centralized computing is used, it will take a long time to complete
- Distributed computing decomposes the application into many small parts and distributes them to the abortion computer for processing, which can save the overall computing time and greatly improve the computing efficiency
Introduction to MapReduce

- Hadoop MapReduce is a distributed computing framework for easily writing distributed applications that process large amounts of data (multi-TB datasets) in parallel on large hardware clusters (thousands of nodes) in a reliable, fault-tolerant manner
- Map Reduce is a guiding ideology for massive data processing and a programming model for distributed computing of large-scale data
MapReduce generation background
Proposed by Google in the 2004 paper "MapReduce: Simplified Data Processing on Large Cluster"

Features of MapReduce
易于编程: MapReduce provides an interface for secondary development. Simply implement some interfaces to complete a distributed program. The task calculation is handed over to the computing framework for processing. The distributed program is deployed to run on the Hadoop cluster, and the cluster nodes can be expanded. to hundreds of thousands
良好的扩展性: When computer resources cannot be satisfied, computing power can be expanded by adding machines. The characteristics of distributed computing based on MapReduce can maintain a nearly linear growth with the number of nodes. This is also the key to MapReduce processing massive data. When computing nodes increase to hundreds or thousands, offline data of several terabytes or even petabytes can be easily processed
高容错性: Hadoop cluster-style distributed construction and deployment, if any machine node is down, it can transfer the above computing tasks to another node to run, without affecting the completion of the entire job task, the process is completely completed within Hadoop
适合海量数据的离线处理: Can handle data volumes of GB, TB and PB levels
Limitations of MapReduce
Although MapReduce has many advantages, it also has relative limitations. The limitations do not mean that it cannot be done, but that the implementation effect is relatively poor in some scenarios, and it is not suitable for MapReduce.
实时计算性能差: MapReduce is mainly used for offline operations, and cannot achieve second-level data response
不能进行流式计算: The characteristic of streaming computing is that data is continuously calculated, and the data is dynamic. As an offline computing framework, MapReduce is mainly for static data sets, and the data cannot be changed dynamically.
MapReduce instance process
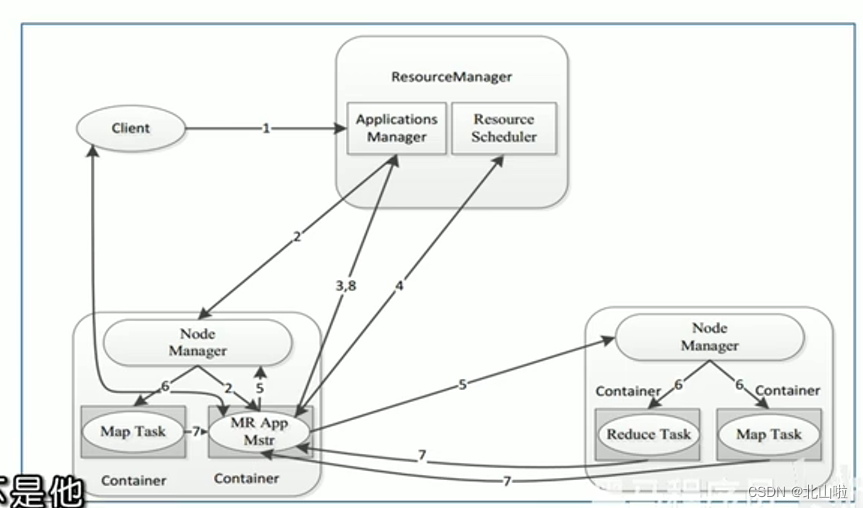
A complete MapReduce program has three types of distributed runtime
- MRAppMaster: responsible for the process scheduling and state coordination of the entire MR program
- MapTask: Responsible for the entire data processing process of map sister u order
- ReduceTask: Responsible for the entire data processing process of the reduce phase
MapReduce phase composition
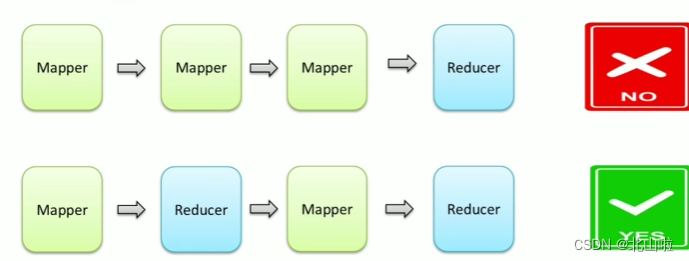
- A MapReduce programming model contains only one Map stage and Reduce stage, or only the Map stage
- There cannot be many map stages, and the emergence of multiple reduce stages
- If the user's business logic is very complex, only multiple MapReduce programs can be run serially
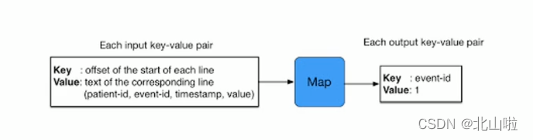
MapReduce data types
- In the entire MapReduce program, data
kv键值对flows in the form of - In actual programming to solve various business problems, it is necessary to consider what is the input and output kv of each stage
- MapReduce has many built-in default attributes, such as sorting, grouping, etc., which are related to the k of the data, so it is extremely important to determine the type of kv data
MapReduce official example
Overview:

Example Description:

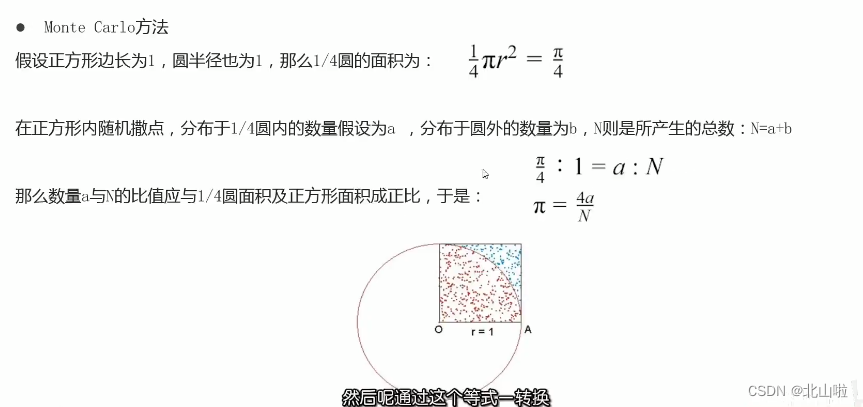
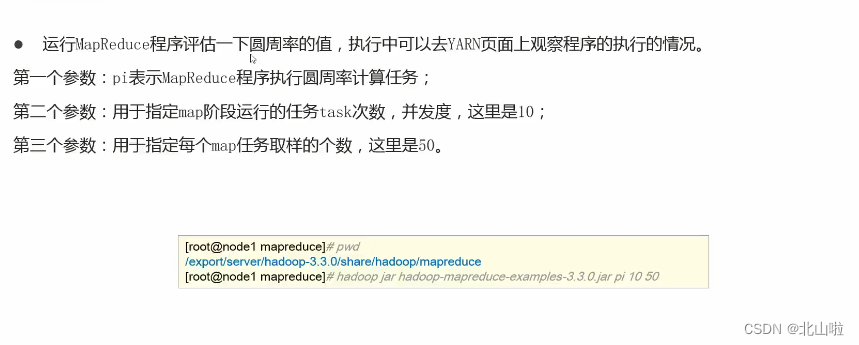
Calculate the value of pi
WordCount word frequency statistics
- WordCount is a classic entry case in the field of big data computing, which is equivalent to hello world
- Through WordCount, you can feel the execution process and default behavior mechanism of MapReduce behind
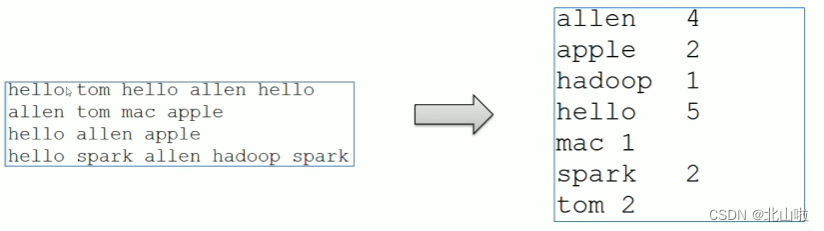
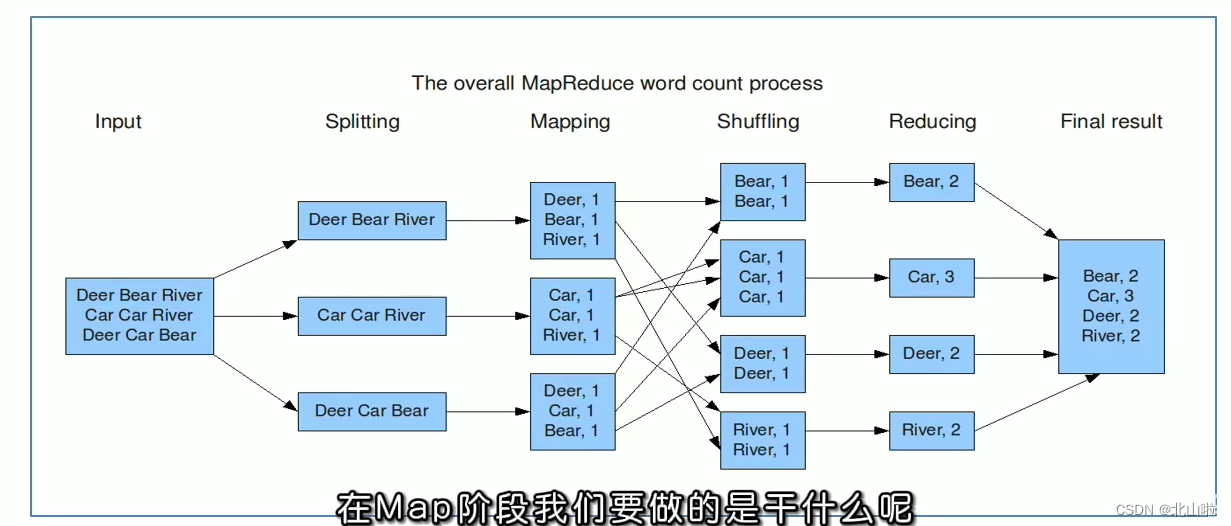
WordCount programming ideas
-
The core of the map stage: cut the input data and mark them all, so the output is <word, 1>
-
The core of the shuffle stage: through the default sorting and grouping functions in the MR program, the words with the same key will be used as a set of data to form a new kv pair
-
The core of the reduce phase: process a set of data completed by shuffle. This set of data is all the key-value pairs of the pronoun, and the cumulative sum of all 1s is the total number of words.
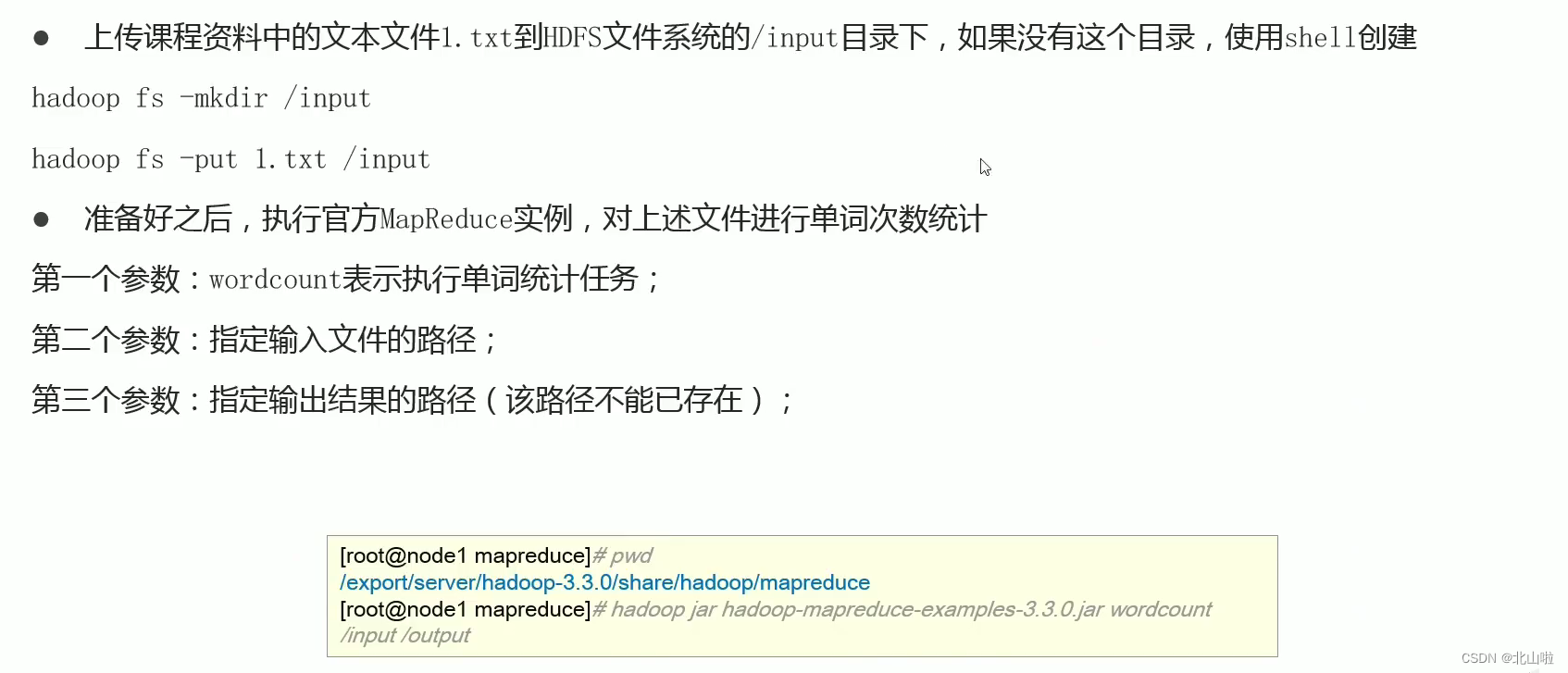
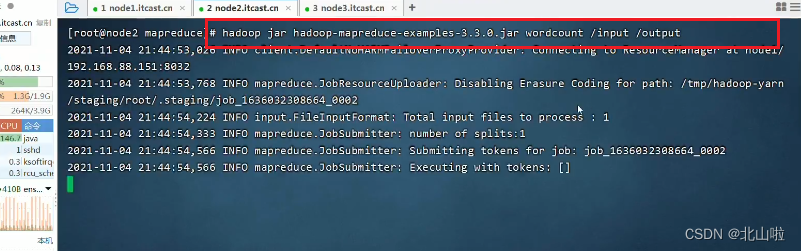
Word program submission
Map phase execution process
Relying on the WordCount program
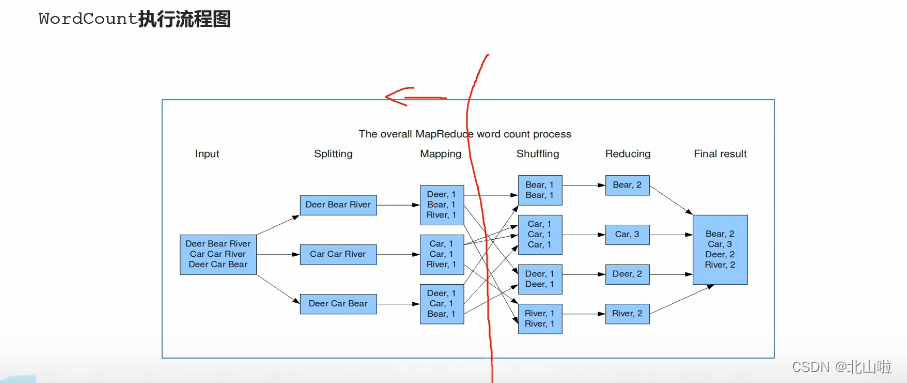
MapReduce overall execution flow chart
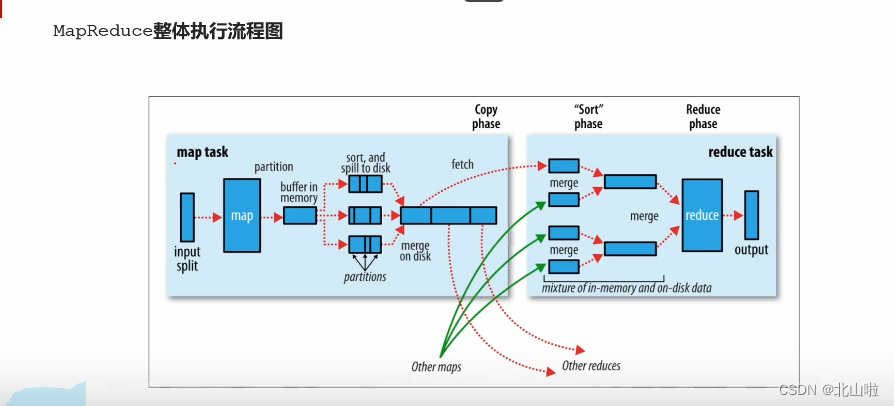
Map stage execution process



Reduce phase execution process

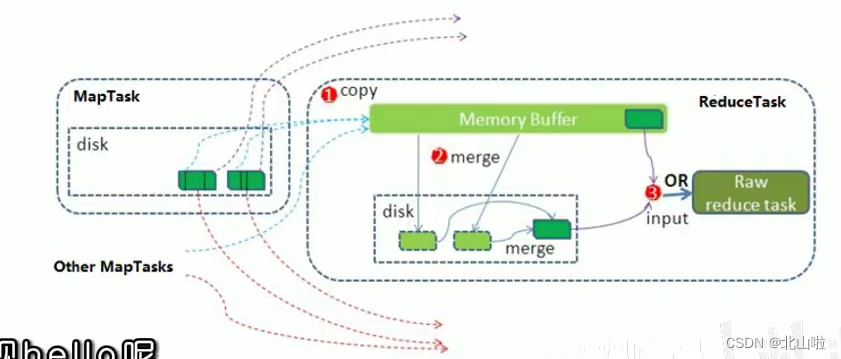
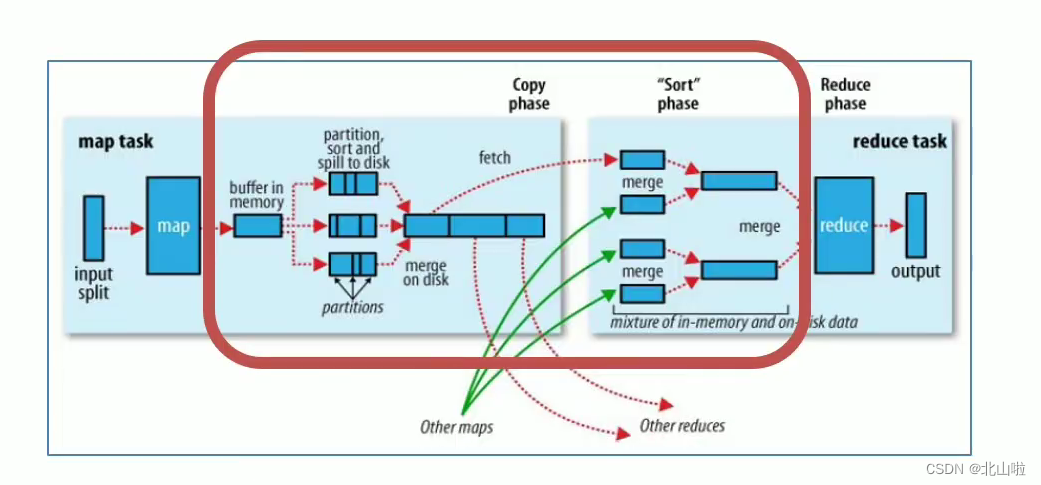
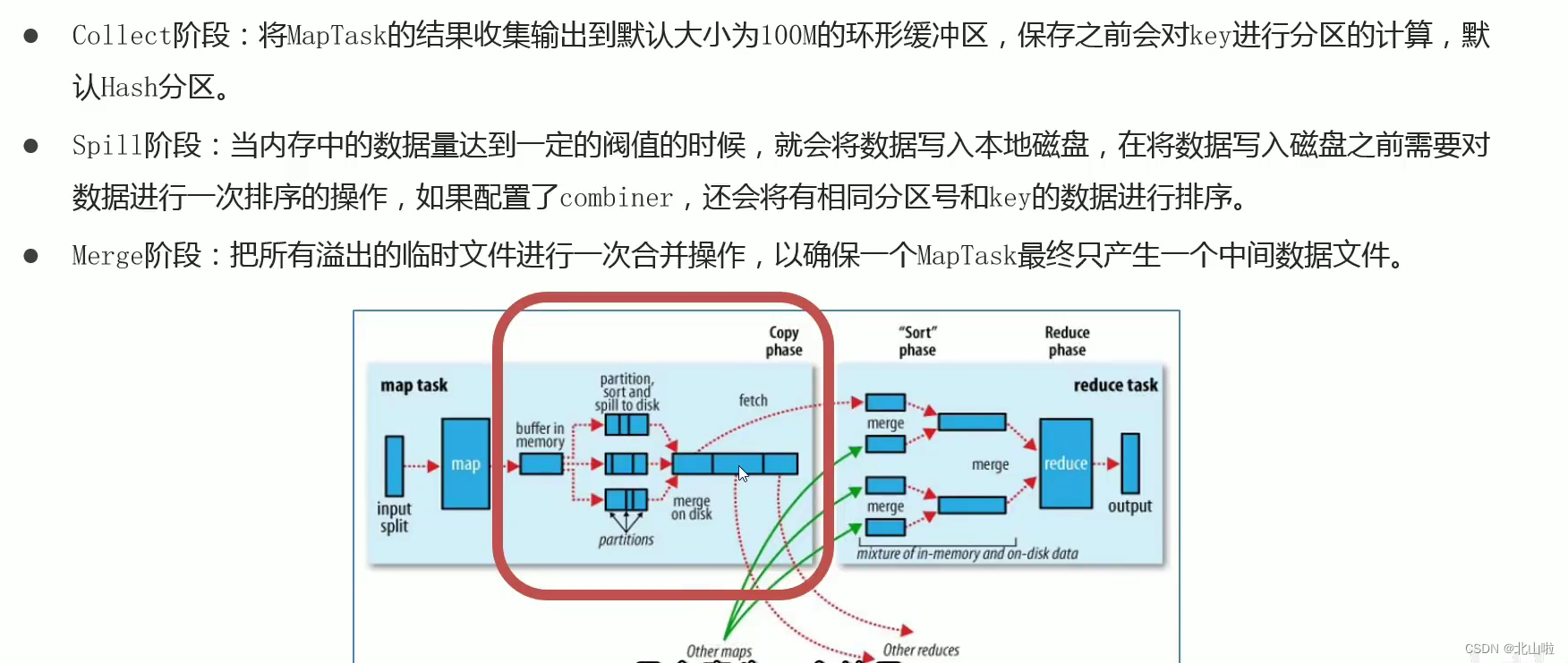
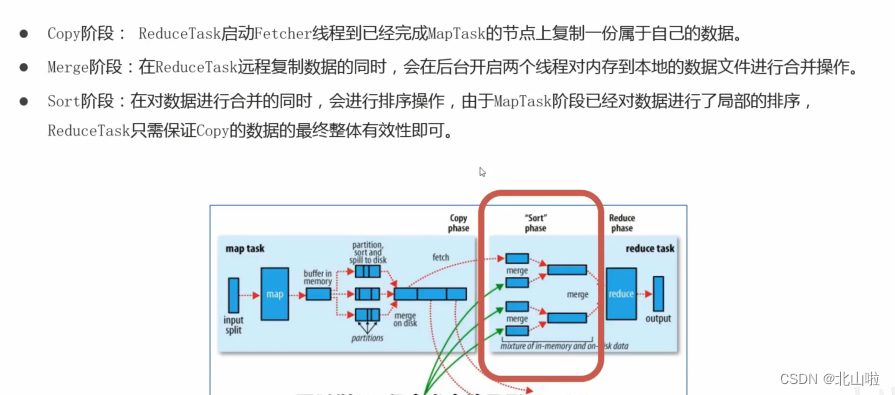
Shuffle mechanism
- The original meaning of Shuffle is to shuffle the cards, to scramble a set of regular data into irregular data as much as possible
- In MR, Shuffle is more like the inverse process of shuffling, which refers to "scrambling" the irregular output of the map end into data with certain rules according to the specified rules, so that the reduce end can receive and process it.
- Generally speaking, the operation from Map generating output to Reduce getting data as input is called shuffle
Shuffle on the Map side
Shuffle on the Reduce side
Disadvantages of the shuffle mechanism
- Shuffle is the core and essence of MapReduce program
- Shuffle is also the place where MapReduce is criticized the most. The reason why MapReduce is slower than Spark and Flink computing engines has a lot to do with the Shuffle mechanism.
- During Shuffle
频繁涉及数据在内存,磁盘之间的多次往复
YARN
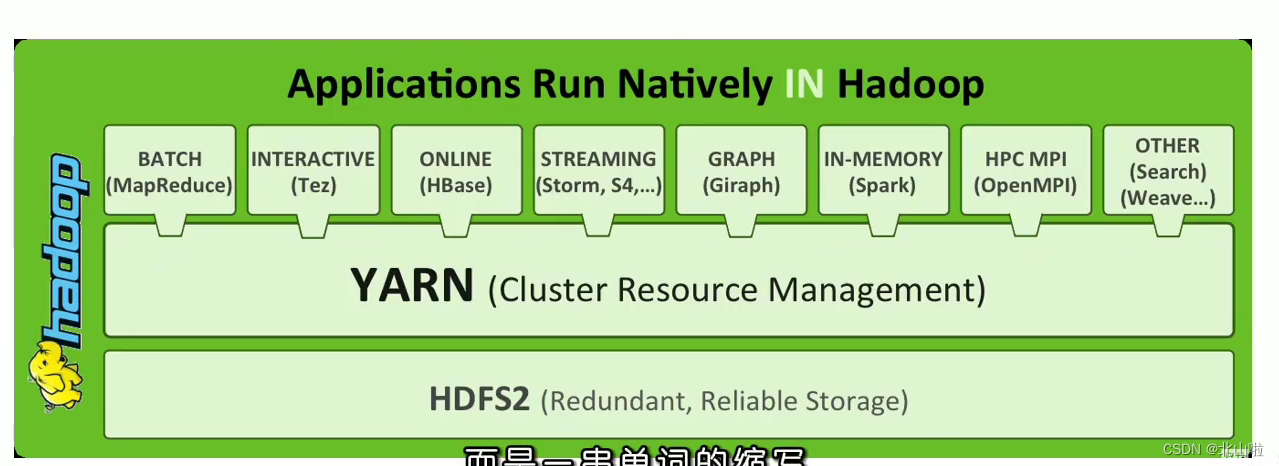
Introduction, Architecture Components, Program Submission Interaction Process, Scheduler
Introduction to YARN
- Apache Hadoop Yarn (Yet Another Resource Negotiatot, Another Resource Coordinator) is a new Hadoop resource manager
- YARN is a general-purpose
资源管理系统and调度平台can provide unified resource management and scheduling for upper-layer applications - Its introduction has brought huge benefits to the cluster in terms of utilization, resource consent management, and data sharing.
YANR is a general
资源管理系统and调度平台
YARN function description

Overview of YARN
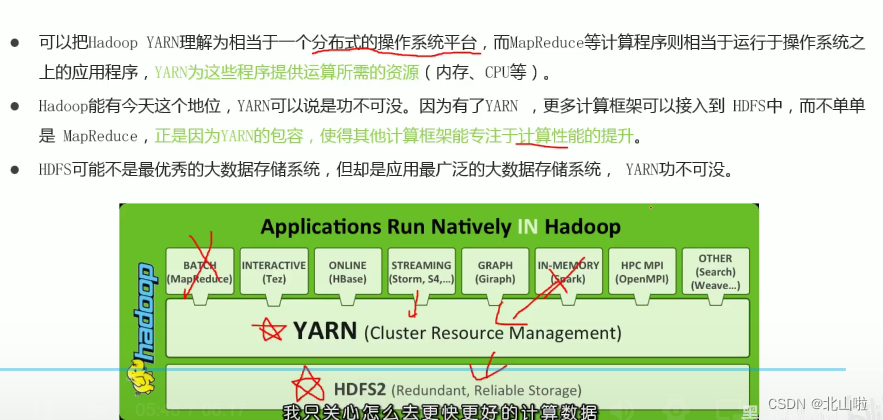
YARN architecture, components
YARN official architecture diagram
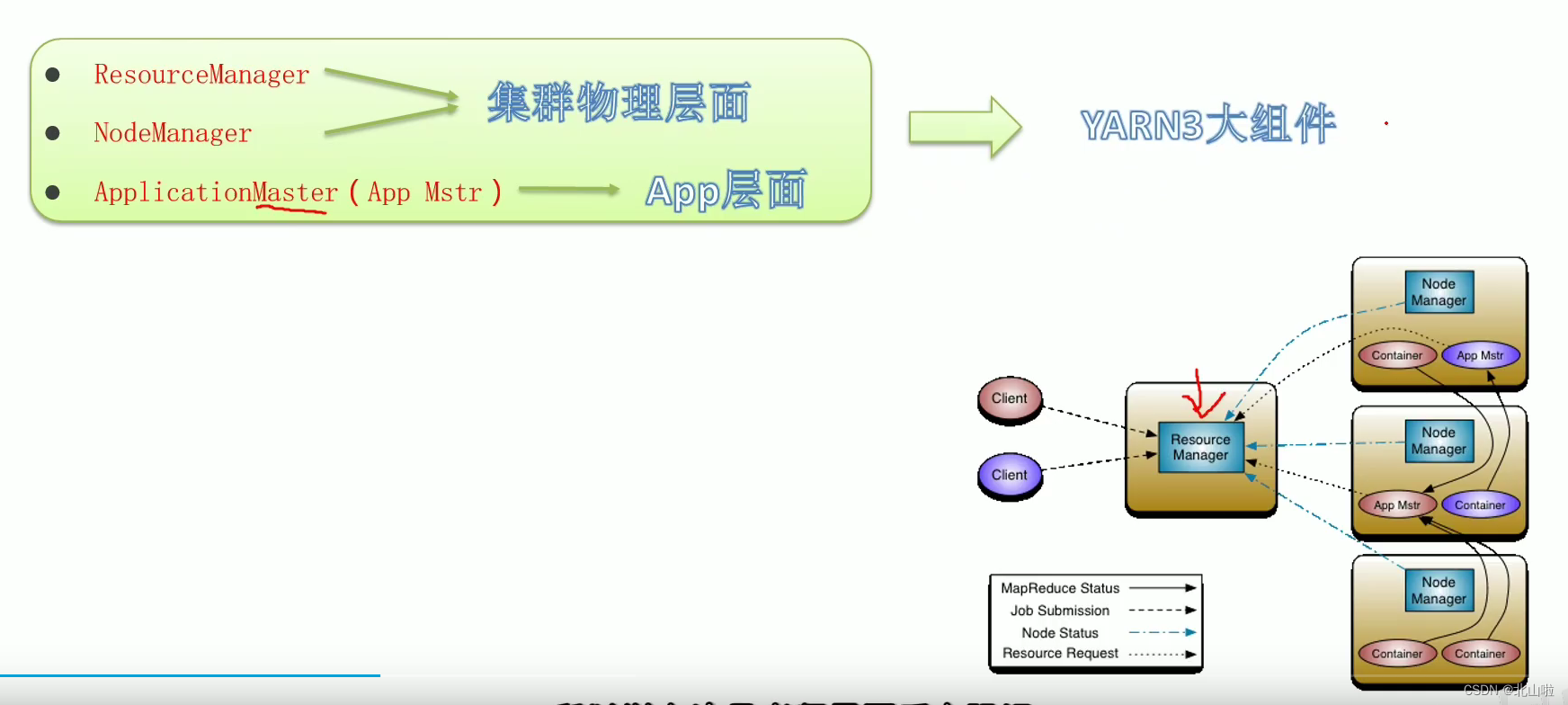

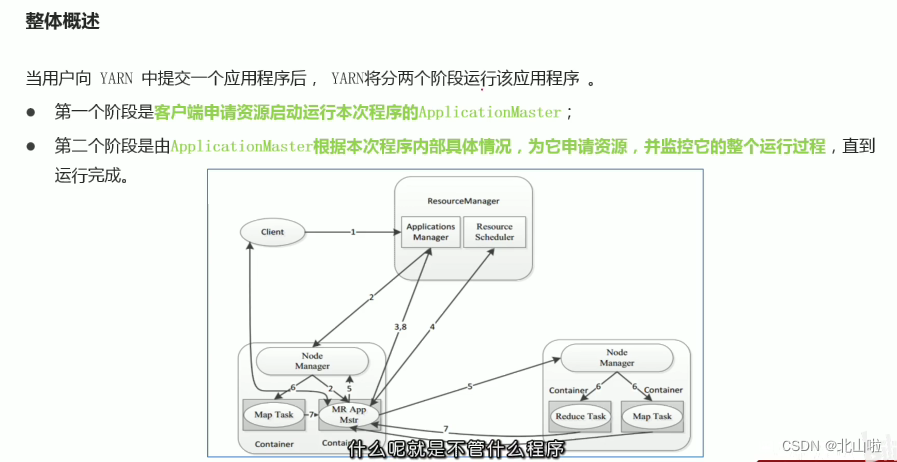
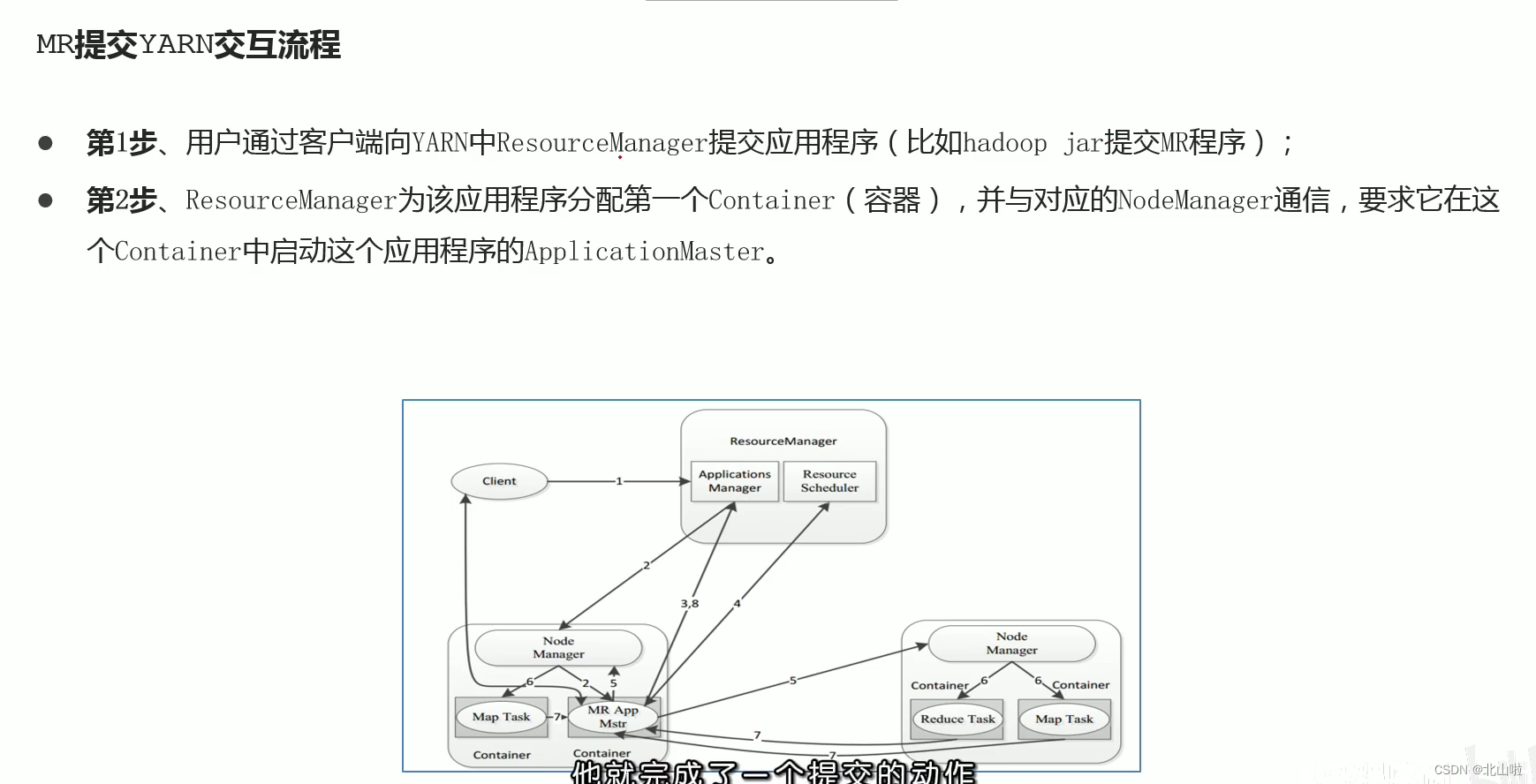
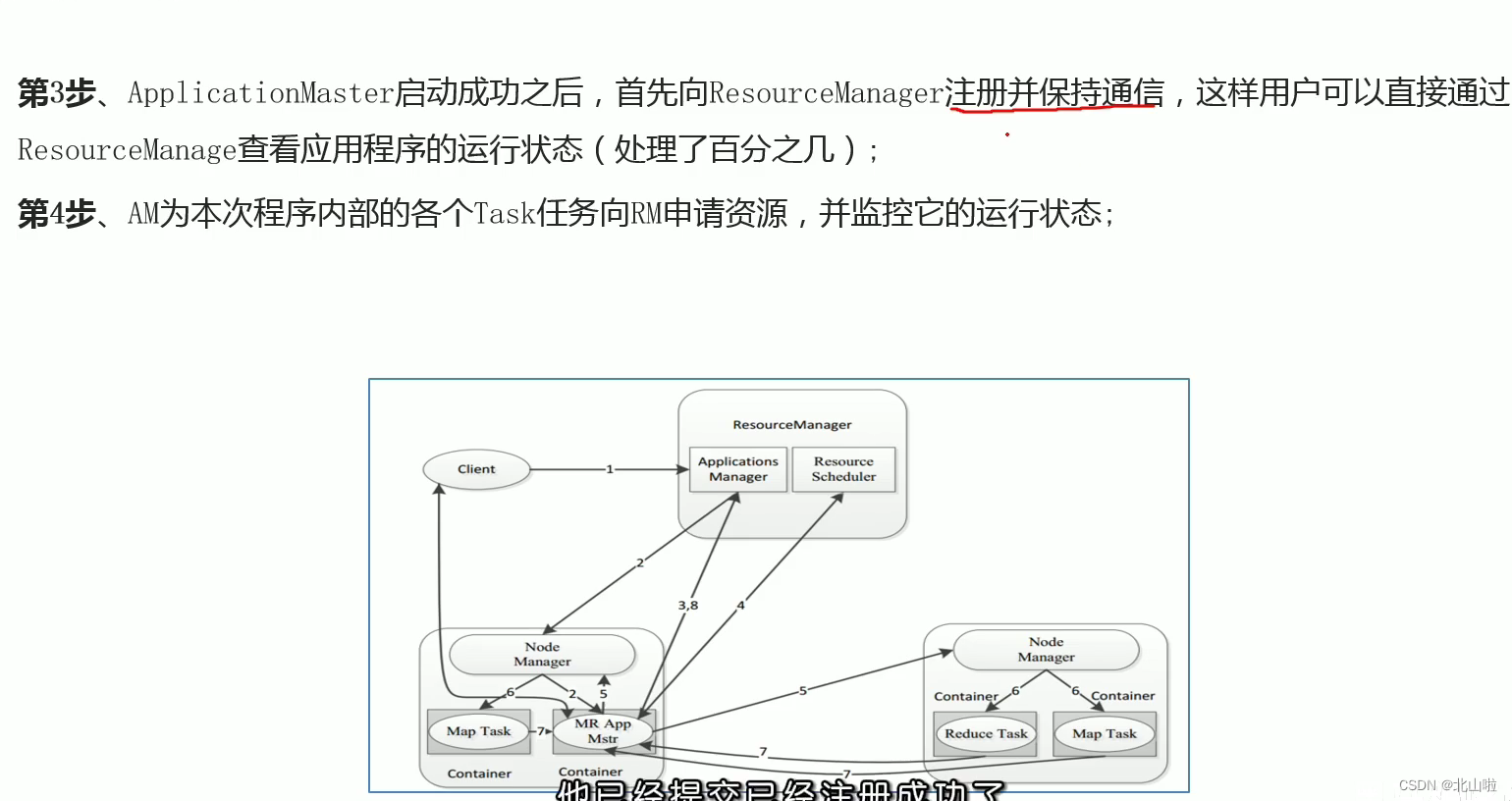
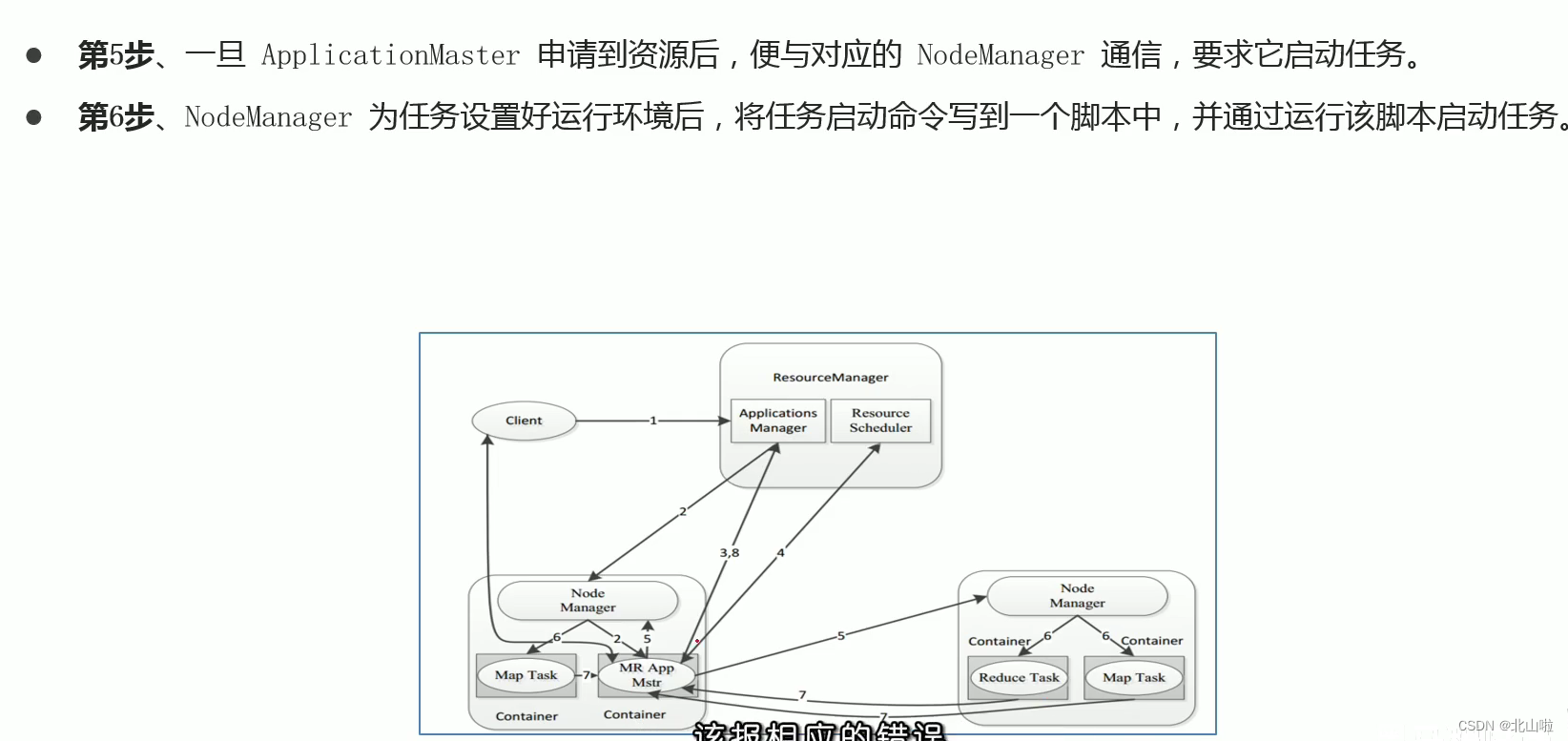
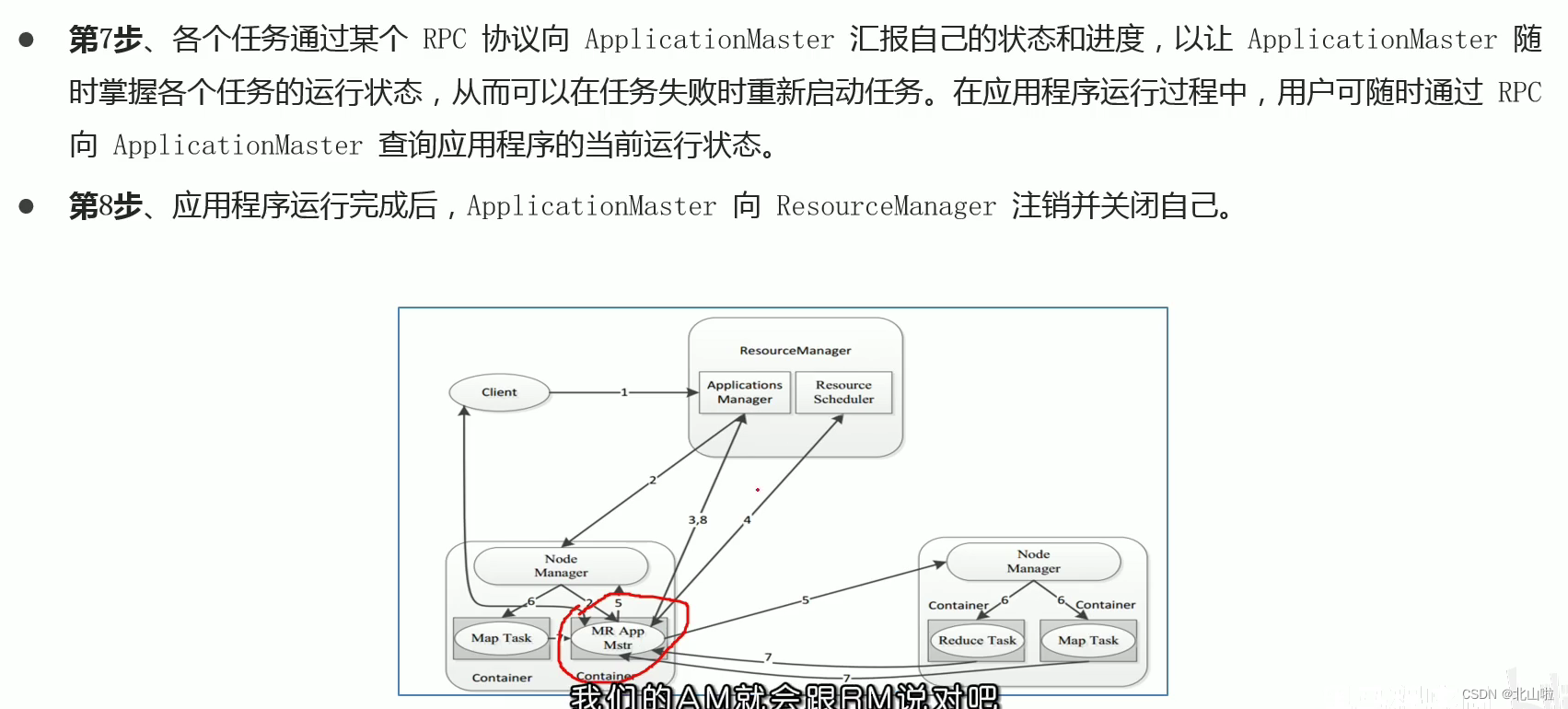
Program submission YARN interaction process
- MR job submission, Client → RM
- Resource application MrAppMaster → RM
- MR job status report Container(Map|Reduce task) → Container(MrAppMaster)
- Node status report NM → RM
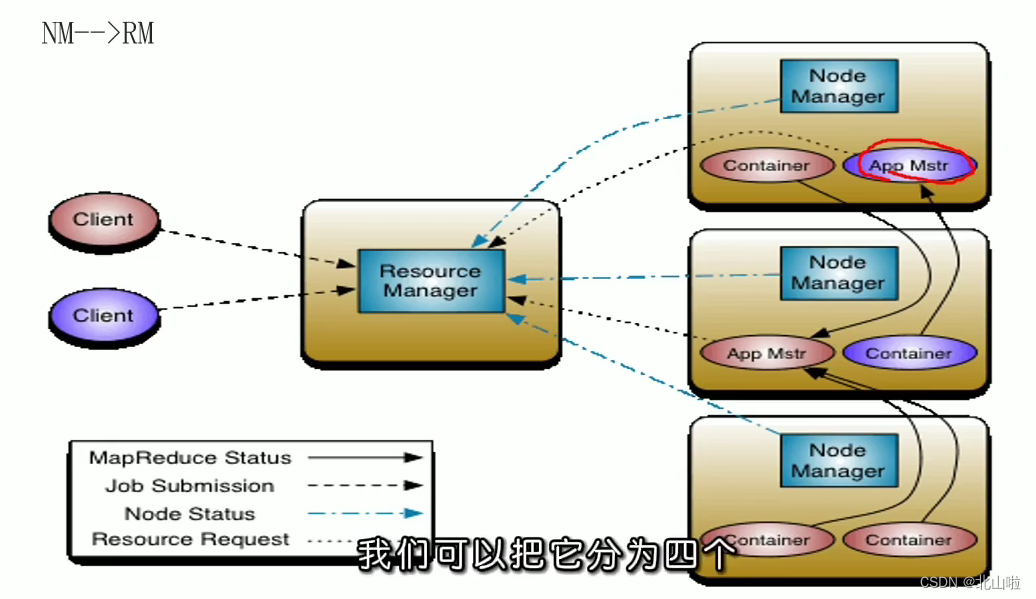
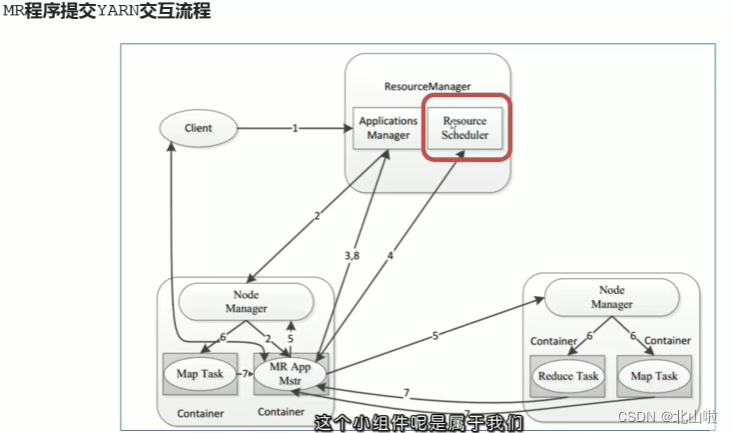
YARN resource scheduler Scheduler
How to understand resource scheduling
- In an ideal world, requests made by applications would be approved by YARN, but in reality, resources are limited, and in busy clusters, applications will often need to wait for their subsequent write requests to be satisfied. The YARN scheduler works according to some
定义的策略为应用程序分配资源 - In YARN, it is responsible for allocating resources to applications
Scheduler. It is one of the core components of ResourceManager. Scheduler is completely dedicated to scheduling jobs. It cannot track the status of applications. - Generally speaking, scheduling is a difficult problem, and there is no optimal strategy. For this reason, YARN provides a variety of schedulers and configuration strategies to choose from
scheduler strategy
According to the needs, choose the appropriate scheduler
- FIFO Schedule
- Capacity Schedule
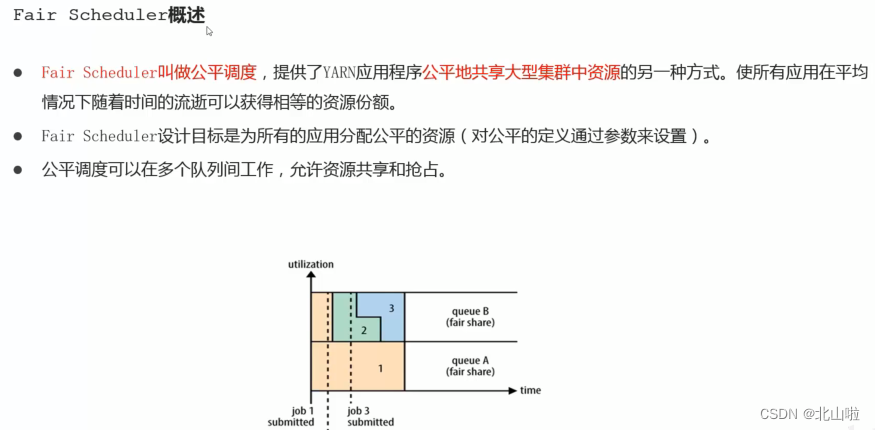
- Fair Schedule
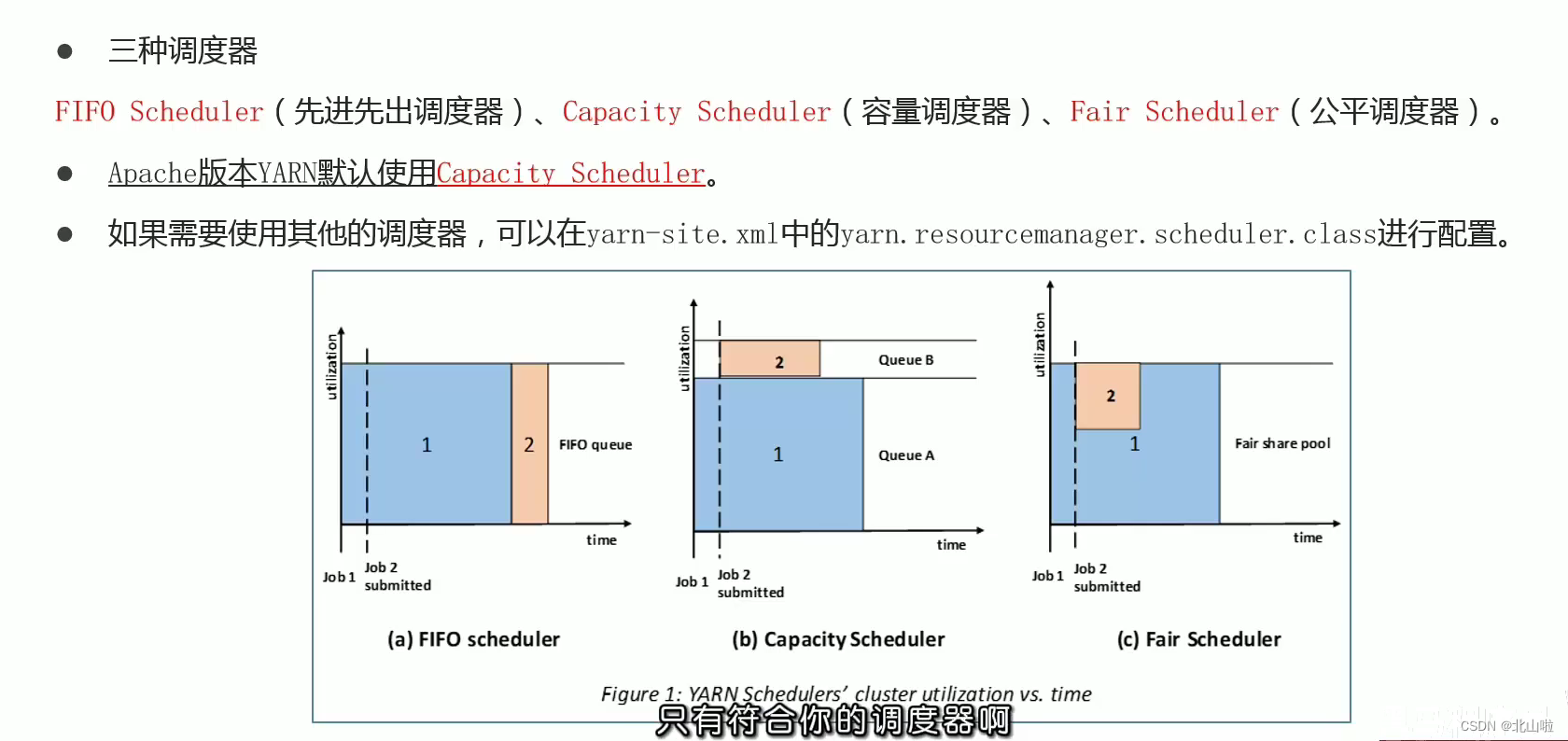
- FIFO Scheduler

- Capacity Schedule



- Fair Schedule
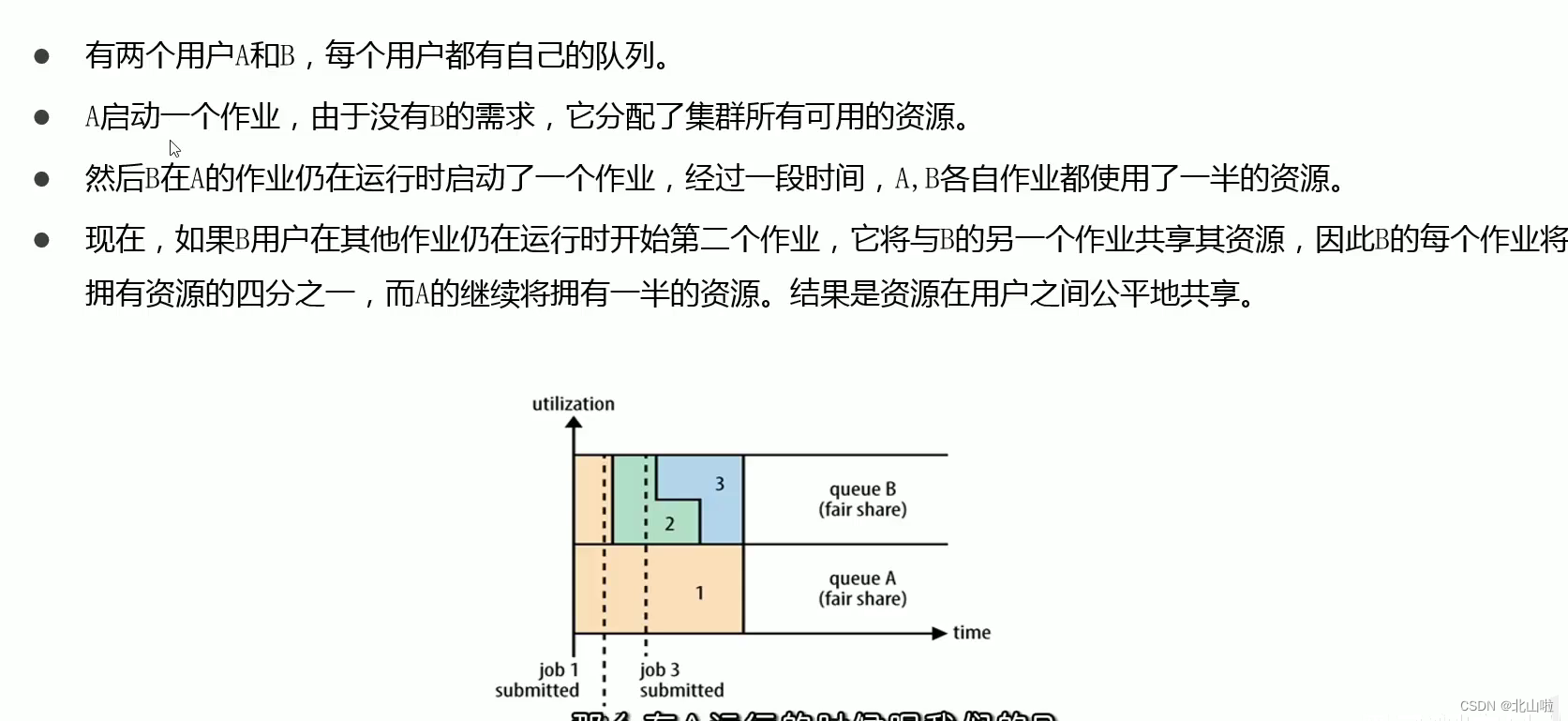

https://beishan.blog.csdn.net/, I am Beishan, welcome to comment and exchange